
CCE Node Resource Reservation Instructions
In a Kubernetes (K8S) Cluster CCE, during the initialization of a node, certain essential system and Kubernetes components must run to ensure the node integrates seamlessly into the cluster and functions properly. Therefore, part of the system's resources are reserved for these components. This is why there is a difference between a node's total resources and its allocatable resources in Kubernetes. The greater the node's capacity, the more containers it can host and the more resources need to be reserved.
To maintain node stability, some resources on CCE nodes in a K8S Cluster are reserved for Kubernetes-related components (such as kubelet, kube-proxy, and Docker) based on the machine specifications. CCE has a default resource reservation policy and also allows for custom reservations via kubelet configuration.
The formula for calculating the final allocatable resources of a node is as follows:
Allocatable resources = total resource capacity (capacity) - reserved resources (reserved) - eviction threshold (eviction-threshold). For memory resources, the eviction threshold is fixed at 100 MiB.
Description:
The capacity here refers to the available memory of the elastic cloud server, excluding the consumption of system components, so the capacity will be slightly less than the memory value specified in the node specification. For details, please refer to Why the available system memory in the system is less than the nominal value.
When the memory consumption of all Pods on a node increases, there may be two possible behaviors:
- When the available memory of the node is lower than the eviction threshold, kubelet will trigger Pod eviction. For information about eviction thresholds in Kubernetes, please refer to Node Pressure Eviction.
- If an OS out-of-memory (OOM) event occurs before kubelet reclaims memory on the node, the system will terminate the container. However, unlike Pod eviction, kubelet will restart the container based on the Pod's RestartPolicy.
Scope of impact
Custom resource reservation and its impact scope
You can modify the resource reservation values by referring to Customize Node Group Kubelet Configuration. After modification, existing nodes in the node group will take effect immediately, and new nodes (such as new nodes for scaling or BCC instances added by adding existing nodes) will also use this configuration.
Note:
- Modifying the kubelet configuration file manually via a black screen is not supported, as it may lead to configuration conflicts or unexpected issues during the maintenance of subsequent node groups.
- Adjusting the resource reservation value may reduce the node’s allocatable resources. Nodes with high resource utilization might trigger eviction. Please set the value thoughtfully.
Default resource reservation and its impact scope
CCE may iterate on the default values of node resource reservation. After the iteration, if you update the node configuration in the node group dimension (such as node group upgrade or modification of custom kubelet parameters for the node group), the nodes will automatically use the new resource reservation policy. If you have no relevant operation and maintenance actions, existing nodes in the node group will not automatically apply the new resource reservation policy for stability reasons.
Query allocatable node resources
Run the command below to check a node's total resource capacity and allocatable resources.
1kubectl describe node 192.168.102.106 | grep Allocatable -B 9 -A 8Expected output:
1Capacity:
2 cce.baidubce.com/eni: 0
3 cce.baidubce.com/ip: 7
4 cpu: 2
5 ephemeral-storage: 103145380Ki
6 hugepages-1Gi: 0
7 hugepages-2Mi: 0
8 memory: 8139584Ki
9 pods: 128
10Allocatable:
11 cce.baidubce.com/eni: 0
12 cce.baidubce.com/ip: 7
13 cpu: 1900m
14 ephemeral-storage: 98227408251
15 hugepages-1Gi: 0
16 hugepages-2Mi: 0
17 memory: 7832384Ki
18 pods: 128Custom resource reservation
You can configure resource reservation for new nodes by referring to Customize Kubelet Parameters; or modify the resource reservation in the node group configuration, and newly scaled-up nodes will use this configuration.
Important: If you need to modify a custom resource reservation, configure the value reasonably. Unreasonable settings may reduce the allocatable resources of the node; for nodes with high resource utilization, node eviction may be triggered.
Default resource reservation strategy
If kubelet resource reservation parameters are not specified, CCE will automatically apply resource reservations based on the following policies.
Memory reservation value:

Example:
- Taking a node with 256 GiB memory as an example, the total memory reservation is calculated as follows:
4×25%+(8-4)×20%+(16-8)×10%+(128-16)×6%+(256-128)×2% = 11.88 GiB
- Taking a node with 198 GiB memory as an example, the total memory reservation is calculated as follows:
4×25%+(8-4)×20%+(16-8)×10%+(128-16)×6%+(198-128)×2% = 10.72 GiB
Note:
- Node memory resources are set based on the system's actual available memory. Units are in MiB.
- The memory size defined in the instance specification refers to all available memory, including the portion occupied by the system. Therefore, the real-time available memory of the system will be less than the value defined in the instance specification. For details, please refer to Why the available system memory in the system is less than the nominal value.
CPU reservation value:
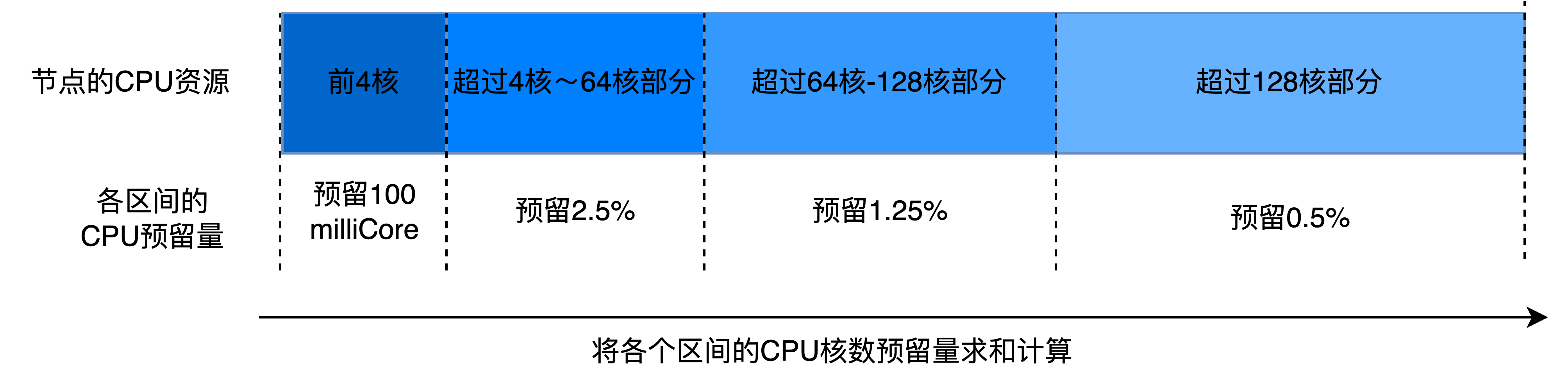
Example:
- For a 32-core node, the reserved resources are calculated as: 100 + (32000 - 4000) × 2.5% = 800 milliCore
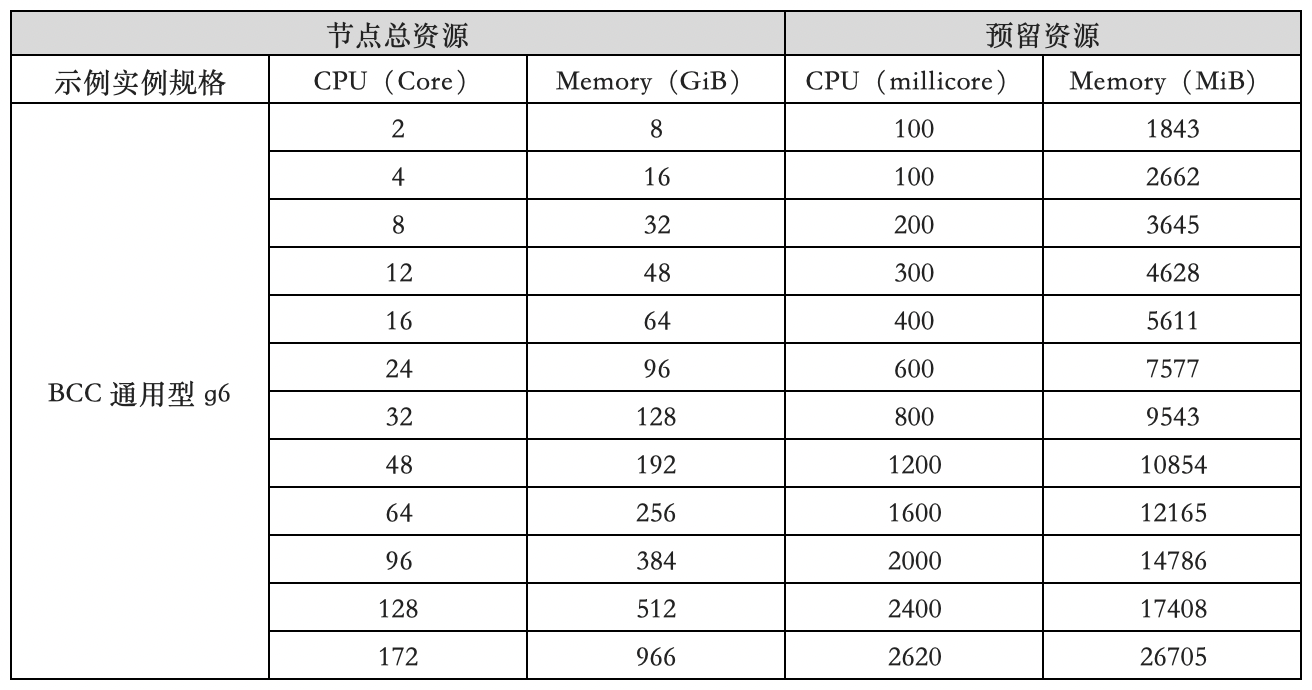
Example of default resource reservation for CCE nodes
For specific information about BCC instance specifications, please refer to Instance Specifications.
In the following examples, 1 GiB = 1024 MiB.
How to view the total CPU and memory of a node?
CPU
Execute the following command to query the total CPU of a node.
1cat /proc/cpuinfo | grep processorExpected output:
1processor : 0
2processor : 1
3processor : 2
4processor : 3Memory
Execute the following command to query the total memory of a node.
1cat /proc/meminfo | grep MemTotalExpected output:
1MemTotal: 7660952 kB