
GPU Exclusive and Shared Usage Instructions
If the cluster supports GPU computing power and memory sharing and isolation, you can configure whether to exclusively occupy or share GPU resources through console settings or the YAML file submitted during the creation of a task or workload.
Prerequisites
- The CCE GPU Manager and CCE AI Job Scheduler components have been successfully installed. You can find them in Cluster - Component Management - Cloud-Native AI.
- Memory sharing has been enabled for the node. You can configure this in Cluster - Node Management - Worker - Memory Sharing Configuration.
Resource names corresponding to GPU card models
To ensure proper use of GPU resources, ensure the specified resource name matches the GPU card model. For instance, if this document uses the number of GPU cards as an example, add “_core” (for computing power) or “_memory” (for memory) after the resource name to specify computing or memory resources.
| GPU model | Resource name |
|---|---|
| NVIDIA V100 16GB | baidu.com/v100_16g_cgpu |
| NVIDIA V100 32GB | baidu.com/v100_32g_cgpu |
| NVIDIA T4 | baidu.com/t4_16g_cgpu |
| NVIDIA A100 80GB | baidu.com/a100_80g_cgpu |
| NVIDIA A100 40GB | baidu.com/a100_40g_cgpu |
| NVIDIA A800 80GB | baidu.com/a800_80g_cgpu |
| NVIDIA A30 | baidu.com/a30_24g_cgpu |
| NVIDIA A10 | baidu.com/a10_24g_cgpu |
Resource description
| Resource name | Types | Unit | Description |
|---|---|---|---|
| baidu.com/v100_32g_cgpu | int64 | 1 | Number of GPU cards: Enter 1 for the shared scenario |
| baidu.com/v100_32g_cgpu_core | int64 | 5% | GPU computing power: E.g., “100” = total computing power of single GPU; “10” = 10% of the computing power of single GPU. The minimum requirement is 5% |
| baidu.com/v100_32g_cgpu_memory | int64 | GiB | GPU memory |
| baidu.com/v100_32g_cgpu_memory_percent | int64 | 1% | GPU memory (applied by percentage): E.g., “100” = total memory of single GPU; “10” = 10% of the memory of single GPU |
Example of creating a task via console
If you create a task through the CCE console (for operation steps, refer to Cloud-Native AI Task Management), you can specify the GPU type as “Exclusive” or “Shared” in the task’s pod group configuration.
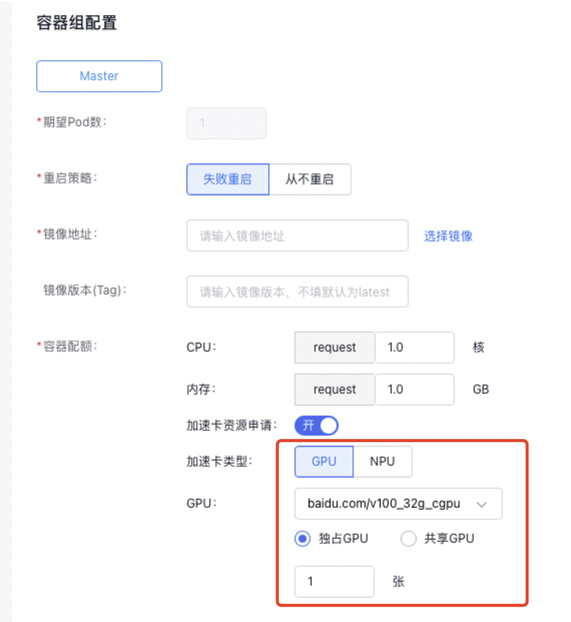
Exclusive occupation example(single-GPU/multi-GPU)
- When specifying the GPU type as exclusive GPU, to use the full resources of a GPU card for the task:
- Choose the GPU model.
- Enter the number of GPU cards. The number must be a positive integer, ranging from [1 to the maximum number of GPU cards per node in the current cluster].
- To use only CPU and memory resources (no GPU resources):
Leave the GPU Model field blank and only input the required CPU and memory resources.
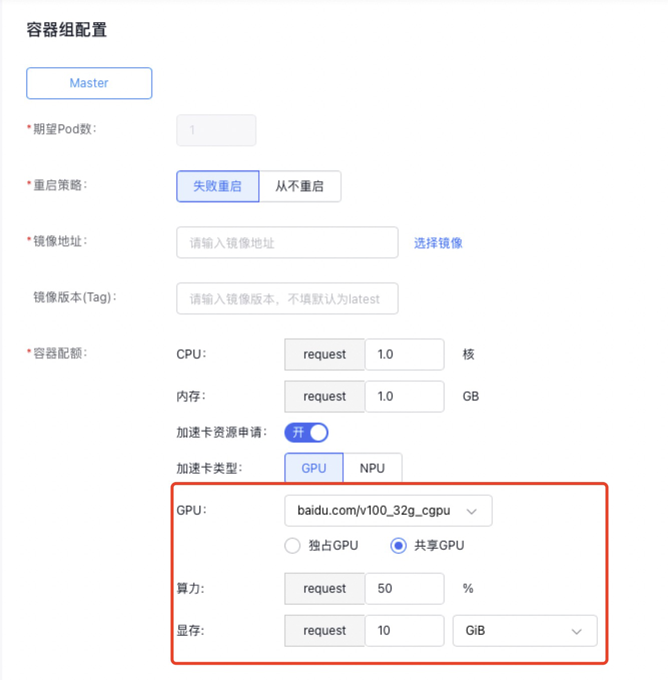
Single-GPU sharing example [isolation for memory only, no isolation for computing power]
When specifying the GPU type as shared GPU, to isolate only memory (no computing power isolation), follow steps below:
- Choose the GPU model.
- Do not fill in the computing power value.
- Enter the required GPU memory. The memory size must be a positive integer, ranging from [1 to the memory size of the selected GPU card].
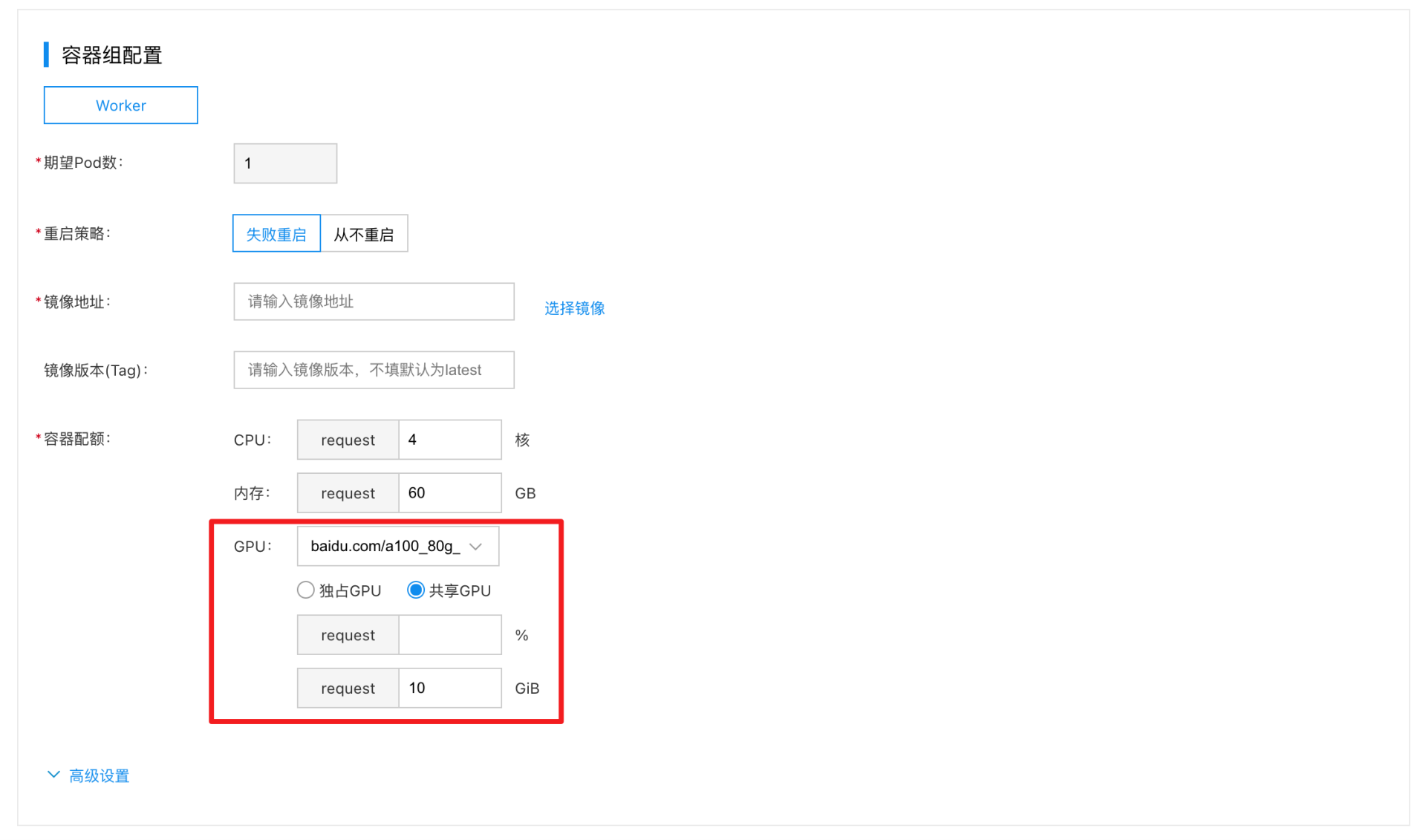
Single-GPU sharing example [isolation for both memory and computing power]
When specifying the GPU type as shared GPU, to isolate memory and computing power, follow steps below:
- Choose the GPU model.
- Enter the required computing power percentage. The percentage must be a positive integer between [5 and 100].
- Enter the required GPU memory. The memory size must be a positive integer, ranging from [1 to the memory size of the selected GPU card].
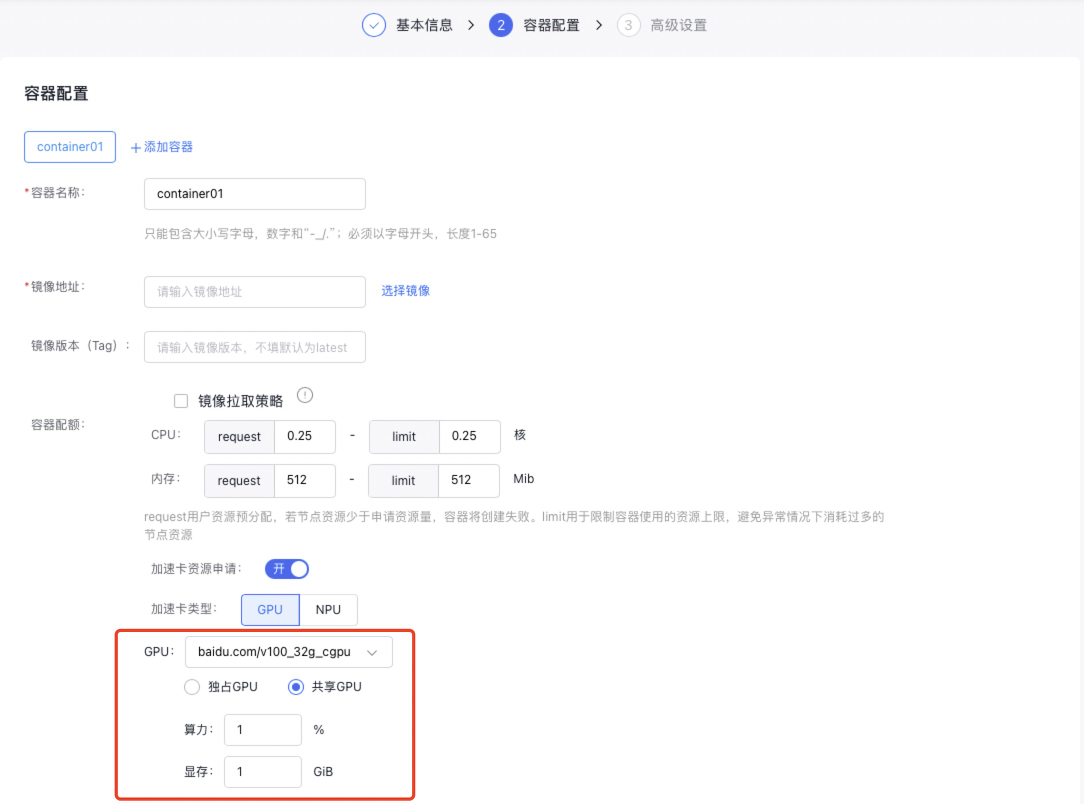
Example of creating a workload via console
If you create a workload through the CCE console (for operation steps, refer to Workloads), you can specify the GPU type as “Exclusive” or “Shared” in the workload’s container configuration. The resource input restrictions for exclusive and shared modes are the same as those for creating AI tasks.
Example of creating a task/workload via YAML
If you create a task or workload via YAML (for detailed configurations, refer to Cloud-Native AI Task Management and Workloads), you can specify the required GPU card resources as “Exclusive” or “Shared” in the YAML configuration. Specific examples are as follows:
Note:
1. When creating a task via YAML, the scheduler must be specified as:schedulerName: volcano
2. GPU memory resources must be applied for. Additionally, only one ofbaidu.com/v100_32g_cgpu_memoryandbaidu.com/v100_32g_cgpu_memory_percentcan be filled in; they cannot be filled in simultaneously
Exclusive occupation example (single-GPU)
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu: 1 // 1 GPU card
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/v100_32g_cgpu: 1 // Limit and request must be the same
8 cpu: "4"
9 memory: 60GiExclusive occupation example (multi-GPU)
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu: 2 // 2 GPU card
4 cpu: "4"
5 memory: 60Gi
6 limits:
7 baidu.com/v100_32g_cgpu: 2 // Limit and request must be the same
8 cpu: "4"
9 memory: 60GiSingle-GPU sharing example [isolation for memory only, no isolation for computing power]:
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu: 1
4 baidu.com/v100_32g_cgpu_memory: 10 // 10GB
5 cpu: "4"
6 memory: 60Gi
7 limits:
8 baidu.com/v100_32g_cgpu: 1
9 baidu.com/v100_32g_cgpu_memory: 10
10 cpu: "4"
11 memory: 60GiSingle-GPU sharing example [isolation for both memory and computing power]:
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu: 1
4 baidu.com/v100_32g_cgpu_core: 50 // 50% (i.e., 0.5 of a card’s computing power)
5 baidu.com/v100_32g_cgpu_memory: 10 // 10GB
6 cpu: "4"
7 memory: 60Gi
8 limits:
9 baidu.com/v100_32g_cgpu: 1
10 baidu.com/v100_32g_cgpu_core: 50 //
11 baidu.com/v100_32g_cgpu_memory: 10
12 cpu: "4"
13 memory: 60GiExample of using encoding/decoding function (only supported by performance-optimized components):
1resources:
2 requests:
3 baidu.com/v100_32g_cgpu: 1
4 baidu.com/v100_32g_cgpu_core: “20” // 20% (i.e., 0.2 of a card’s computing power)
5 baidu.com/v100_32g_cgpu_memory: "2" // 2
6 baidu.com/v100_32g_cgpu_encode: 100 // Enable encoding function
7 baidu.com/v100_32g_cgpu_decode: 100 // Enable decoding function
8 memory: "2Gi"
9 cpu: "1"
10 limits:
11 baidu.com/v100_32g_cgpu: 1
12 baidu.com/v100_32g_cgpu_core: "20"
13 baidu.com/v100_32g_cgpu_memory: "2"
14 baidu.com/v100_32g_cgpu_encode: 100
15 baidu.com/v100_32g_cgpu_decode: 100