
Hyperchain Solution
Table of Contents
- [Solution description](#Solution description) - [Concept description](#Concept Description) - [Solution positioning](#Solution positioning) - [Solution architecture](#Solution architecture) - [Solution advantages](#Solution advantages) - [Solution application scenarios](#Solution application scenarios)
- [Guide](#Operation guide) - [Environment preparation](#Environment preparation) - [Parameter Configuration](#Parameter configuration) - [View Xuper Chain Console](#View Xuper Chain Console)
Solution description
Introduction to concept
Xuper Chain Baidu Xuper Chain is a self-developed blockchain 3.0 solution by Baidu, featuring powerful network throughput capacity, high-concurrency validity verification capability and scalable storage capacity.
Super Node/Supervisory Node Super nodes are special nodes in Xuper Chain. The distributed computing technology is adopted to ensure that the storage and computing of each node can be scaled, thus providing continuous storage and computing support for the blockchain network. Under the non-POW consensus mechanism, super nodes calculate transactions submitted on the chain and execute contracts. Super nodes improve computing efficiency by combining multi-core parallel computing with distributed computing. Supervisory nodes are mainly used for transaction verification.
- Smart contracts Since the UTXO (Unspent Transaction Output) model has better concurrency than the account balance model, the underlying layer of Xuper Chain is based on the UTXO model, which extends support for smart contracts and can load different contract virtual machines.
Three-dimensional Network Xuper Chain implements a three-dimensional network on the blockchain using in-chain parallel technology, returnable sidechain technology and parallel chain technology Xuper Chain implements a three-dimensional network on the blockchain using in-chain parallel technology, returnable sidechain technology and parallel chain technology.
- In-chain parallelism: Xuper Chain uses transaction mining to form a Directed Acyclic Graph (DAG), enabling concurrent transaction execution.
- Returnable sidechain: Xuper Chain offloads complex smart contracts to sidechains, utilizing parallel resources without consuming mainchain resources. When sidechain return conditions are fulfilled, sidechain merging is triggered proactively.
- Parallel chain: Xuper Chain allows the creation of independent and authentic blockchain systems using the root chain.
- In-chain parallel technology: Xuper Chain mines transactions to generate a Directed Acyclic Graph (DAG), managing transaction execution concurrently.
- Returnable sidechain: Xuper Chain offloads complex smart contracts to sidechains, utilizing parallel resources without consuming mainchain resources. When sidechain return conditions are fulfilled, sidechain merging is triggered proactively.
- Parallel chain: Xuper Chain allows the creation of independent and authentic blockchain systems using the root chain.
Lightweight Node Light nodes can complete data access and verification by synchronizing only a small amount of data. They are suitable for ordinary PCs, mobile phones and embedded devices, and can effectively access blockchain network data without powerful computing and storage capabilities.
Solution positioning
Baidu AI Cloud has a comprehensive strategy in the blockchain sector. We offer extensive technical capabilities covering applications, service implementations, and a unified cloud framework, along with abundant experience in alliance chain, public chain, and private chain use cases. Utilizing Baidu’s proprietary blockchain 3.0 technology framework, Baidu Xuper Chain delivers advanced, one-stop blockchain technology and product capabilities to users and partners.
Baidu AI Cloud blockchain solution positioning:
A cloud-native blockchain "empowerment center" integrates advanced cloud technologies with blockchain frameworks, offering features like containerized development models, one-click deployment, secure cloud application hosting, graphical operation interfaces, extensive OpenAPIs, pluggable blockchain scenario parameters, and customizable, optimized blockchain components. It empowers partners by leveraging Baidu’s superior blockchain practices to advance the industry's ecosystem growth and development.
Baidu AI Cloud blockchain solutions are available in two categories: technology solutions and industry solutions.
The BaaS solution leverages an advanced "cloud + chain" technical architecture. It supports one-click deployment, operation, and maintenance of mainstream blockchain technologies such as Baidu Xuper Chain, Ethereum, and Fabric on the cloud, and offers cloud-based development, deployment, operation, maintenance, and template services for smart contracts and DApps, thus lowering the technical barriers for blockchain users.
Among them, Xuper Chain is a self-developed and soon-to-be-open-sourced blockchain 3.0 solution by Baidu. It is characterized by strong network throughput, high-concurrency performance and universal smart contract processing capabilities; meanwhile, based on pluggable consensus mechanisms, parallel computing networks and three-dimensional networks, it truly breaks through the current technical bottlenecks of blockchains and paves the way for the widespread application of blockchains. Baidu AI Cloud’s Xuper Chain solution perfectly integrates the advanced cloud capabilities of AI+BigData+Cloud with Xuper Chain. Through cloud product capabilities such as one-click deployment of Xuper Chain and cloud operation and maintenance of Xuper Chain, it helps users better utilize Xuper Chain’s capabilities, accelerates the technical implementation of Xuper Chain in enterprise environments, and empowers the development and prosperity of the trusted blockchain ecosystem.
Solutions for the Internet of Things, financial transactions, and asset securitization (ABS) combine industry-specific features with tailored blockchain capabilities. Baidu AI Cloud integrates its extensive practical experience in blockchain commercialization and technical expertise to deliver solutions and product services that empower industry-specific blockchain scenarios. These templates expedite blockchain implementation across niche sectors while fostering collaboration with partners to develop benchmark "blockchain + X" practices in the industry.
Baidu AI Cloud continues to make advancements in areas such as three-dimensional chain network architecture, single-chain performance, multi-chain trusted interaction, consensus mechanism optimization, secure blockchain sandbox environments, node security, blockchain+AI, and blockchain+Internet of Things. These efforts aim to build a high-performance, stable, and technologically sophisticated blockchain platform.
Solution architecture
For the overall architecture of the blockchain solution, please click for details: https://cloud.baidu.com/solution/blockchain.html
Among them, the architecture of the Xuper Chain solution is as follows:
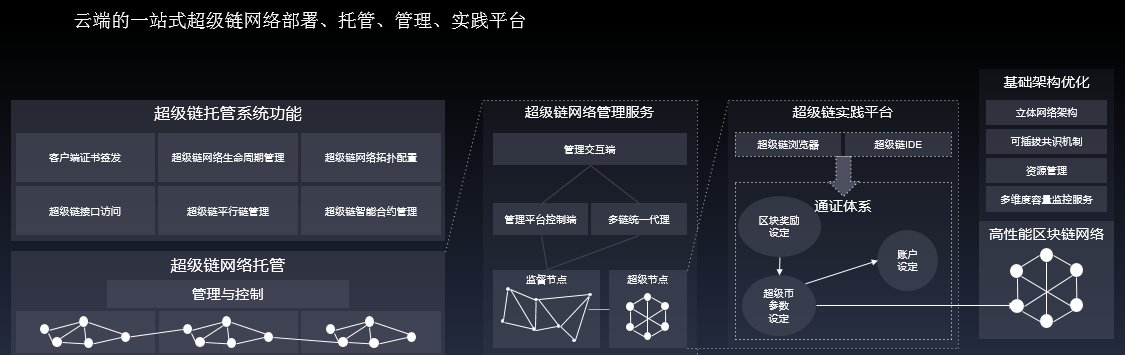
Solution advantages
Advantages of the Xuper Chain solution:
- One-click deployment
- Elastic hosting of application containers
- Cloud SLA
- Unified architecture for public and private chains
- High performance
- Super nodes
- Three-dimensional chain network
- Pluggable consensus mechanism
- Universal smart contracts
- One-stop practice platform
- Compliant token incentives
Solution application scenarios
Application scenarios of the Xuper Chain solution: Xuper Chain is an advanced solution in the era of blockchain 3.0, which builds standardized, modular and high-performance blockchain infrastructure. It has matured practical applications in fields such as traceability, certification, copyright, games, finance, security and communities. Xuper Chain is perfectly integrated with Baidu AI Cloud, which provides a one-stop platform for Xuper Chain deployment, hosting, operation and maintenance and practice on the cloud for developers and enterprise users, thus helping users implement Xuper Chain in industry scenarios.
Operation guide
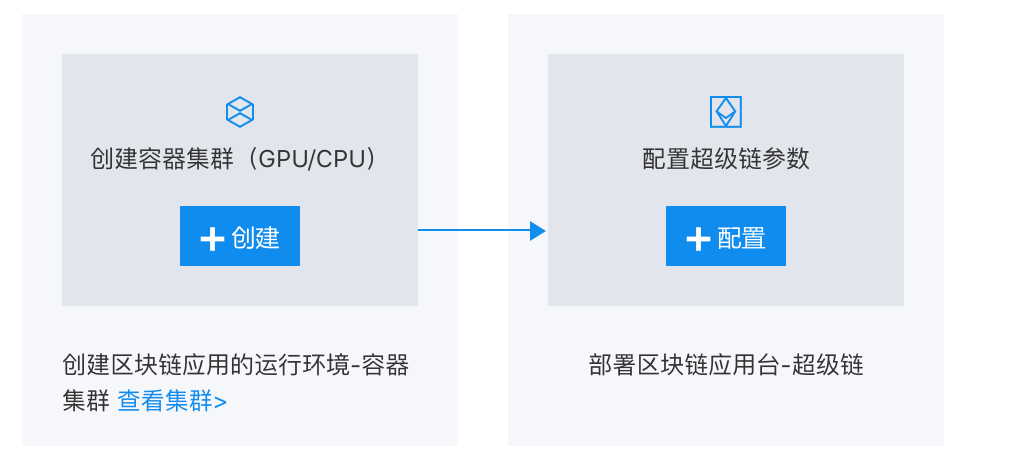
This document will introduce how to build your private Xuper Chain network based on Baidu AI Cloud container clusters, with specific steps as follows:
Step I: [Environment Preparation](#Environment preparation); it mainly creates the operating environment for blockchain applications - container clusters;
Step II: [Parameter Configuration](#Parameter configuration); it mainly configures the network parameters of Xuper Chain;
Step III: [View Xuper Chain Console](#View Xuper Chain Console); it mainly provides functions for user wallets and viewing network information;
Environment preparation
Apply for blockchain solution permissions
- Sign in to the official website of Baidu AI Cloud Blockchain Solution.
- Click Apply Now to enter Application for the Use of Blockchain Solutions, fill in the application as required, and then click Submit.
Warm Reminder: Once we receive your application, it will enter the review stage. Upon successful review, a dedicated representative will contact you based on the provided contact details and your requirements to discuss further. If you’ve been notified that your blockchain solution access has been activated, log in to the console, navigate to Computing - Cloud Container Engine (CCE) - Solutions - Xuper Chain Solution, and begin creating your application.
Create a container cluster
Create the operating environment for blockchain applications - container clusters. For specific operation steps, please refer to Create Cluster
Parameter configuration
After the container cluster is created successfully, start deploying the Xuper Chain network. Parameters support one-click configuration. Users only need to select and configure parameters as prompted on the Xuper Chain deployment page:
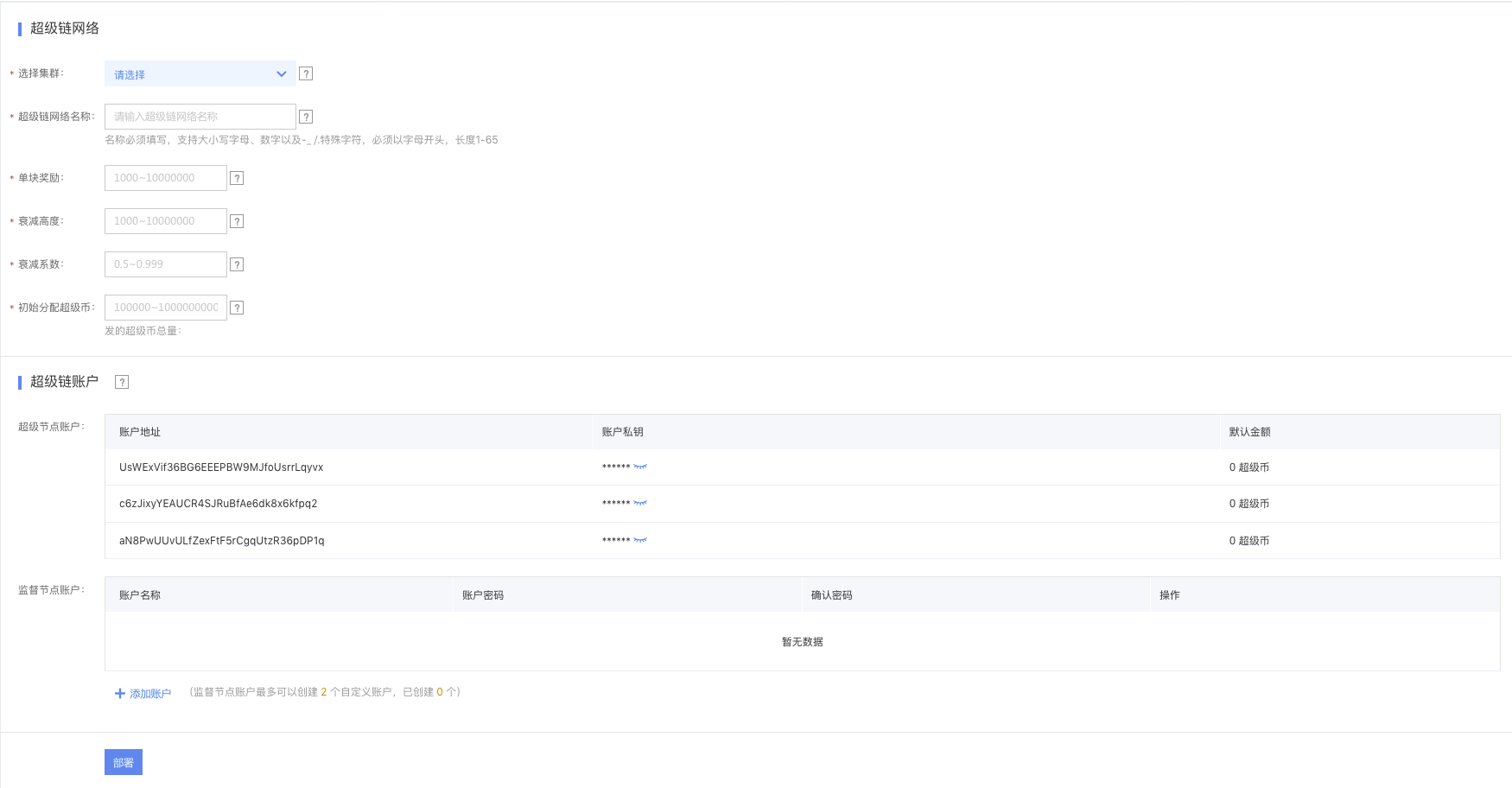
- Select cluster: Select the cluster used to deploy the Xuper Chain. If no cluster has been created, click Create Now to redirect to the container cluster creation page
- Xuper Chain network name: Customize your Xuper Chain network name to identify your network information
- Single block reward: The reward amount for each block when the super node generates a block
- Decay height: The number of blocks after which the reward starts to decay during block generation
- Decay factor: After generating a certain height of blocks during block generation, the new reward equals the current reward multiplied by the decay factor
- Initial allocation of super bitcoins: When creating a network, a pre-allocated number of super bitcoins is given to the management account, which defaults to the account of the first super node
- Super node account: Nodes with bookkeeping and block-generating rights, with account information randomly generated
- Supervisory node account: Nodes with only supervisory rights, used for transaction verification
For example, if the block reward is 100, the decay height is 100, and the decay coefficient is 0.5 The reward for each block from block 1~ to 100 is 100; the reward for each block from block 101~ to 200 is 50; the reward for each block from block 201 to 300 is 25, and so on, with the reward gradually converging.
View Xuper Chain Console
After Xuper Chain deployment is completed, you can access the Xuper Chain list to view existing networks.

Click "Console" to enter the network console. The Xuper Chain console comprises three sections: wallet, network node information, and network transaction information.
- Wallet
Users can view their address and private key and perform super bitcoin transactions with other node users.
- Network node information
In the network node information list, users can view basic information of the root chain, including root block, latest block, chain length and total amount of super bitcoins. Meanwhile, users can view the status information of existing super nodes and supervisory nodes in this module.
- Network transaction information
It documents recent transaction details across the Xuper Chain network and its various nodes.
Operation step
-
Obtain the account private key
- Click the Download Network Parameters entry

- Enter the mobile phone verification code
- Obtain the user’s private key from the downloaded file
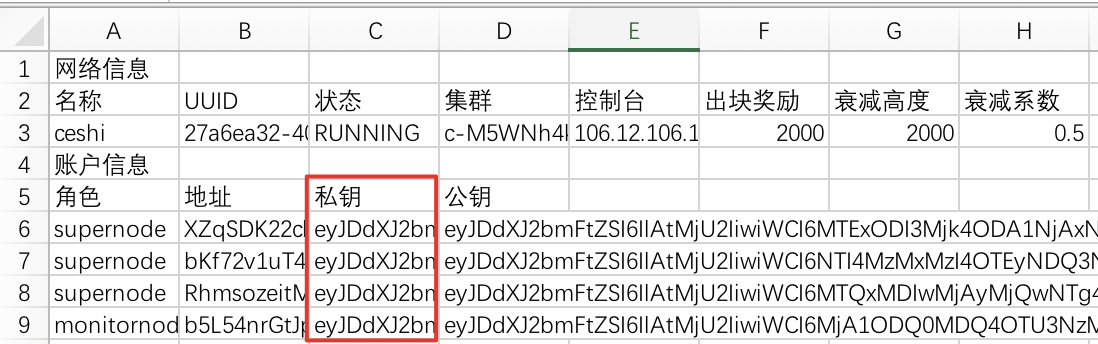
- Click the Download Network Parameters entry
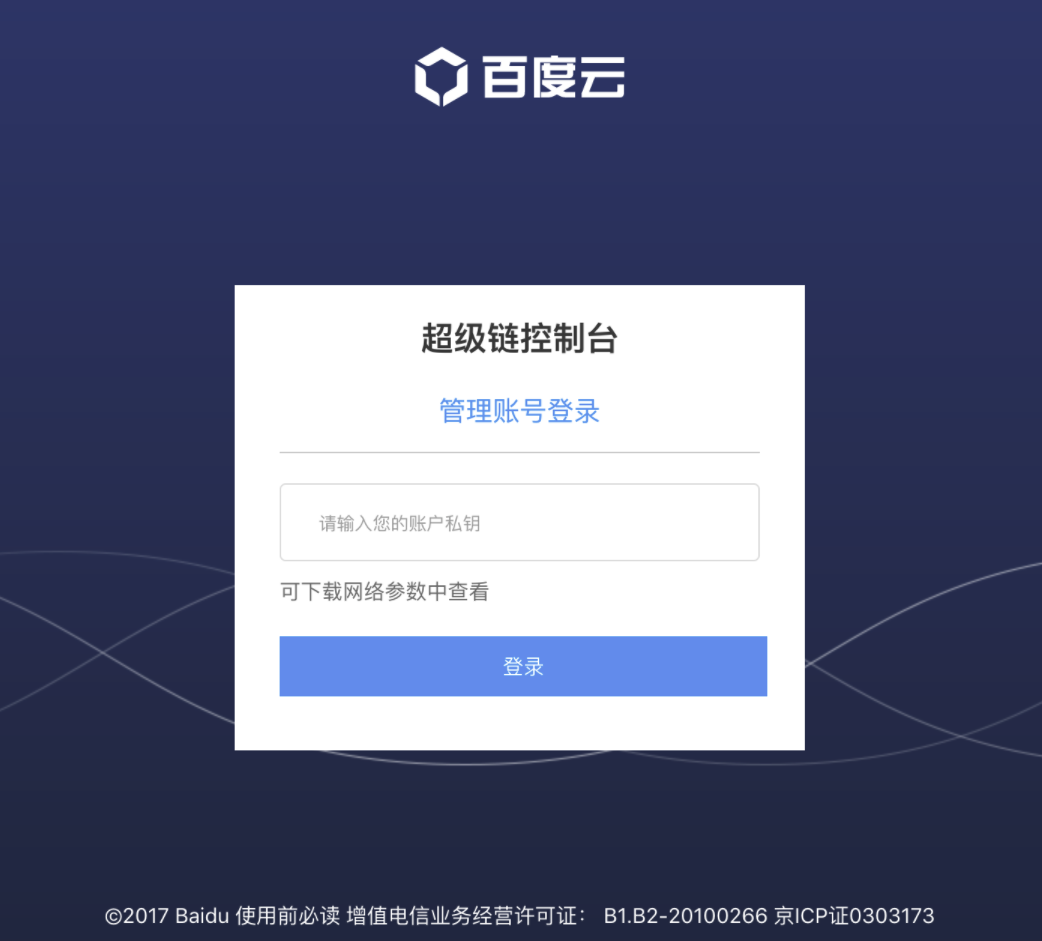
-
Sign in to the Xuper Chain console and enter the account private key
-
After signing in, you can view the wallet, network node information and network transaction information
- Wallet
- View your own balance
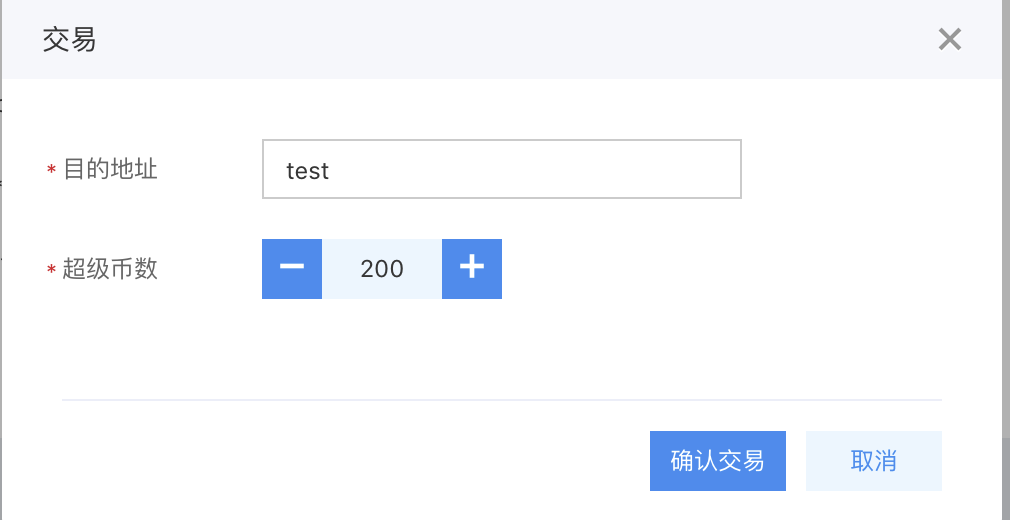
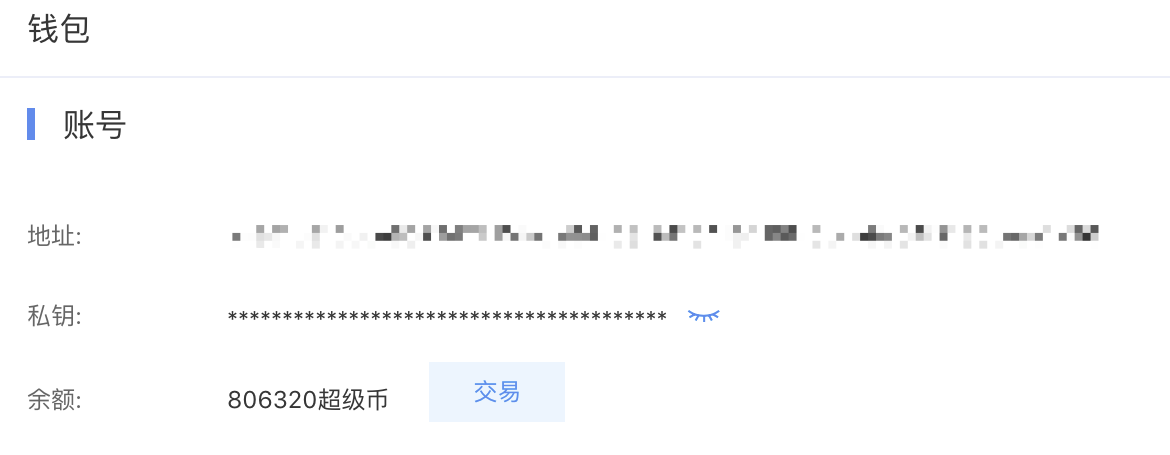 - Click Transaction to initiate a transfer to the destination address.
- Click Transaction to initiate a transfer to the destination address.
- Network node information
The network node information section includes the root chain's basic details, a list of super nodes, and a list of supervisory nodes.
Plain Text1 2 3 4 5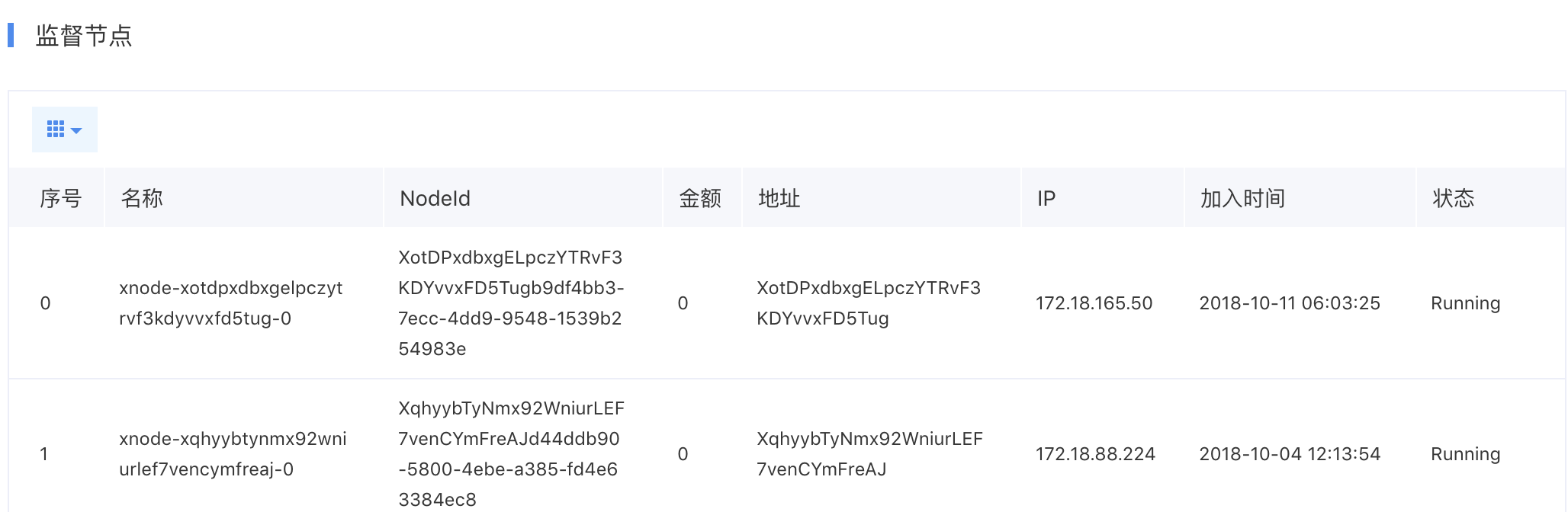Note: Supervisory nodes neither generate blocks nor receive rewards. Hence, their default balance is 0.
- Network transaction information
The network transaction information section provides details on the 50 most recent transactions in the Xuper Chain network.
Plain Text1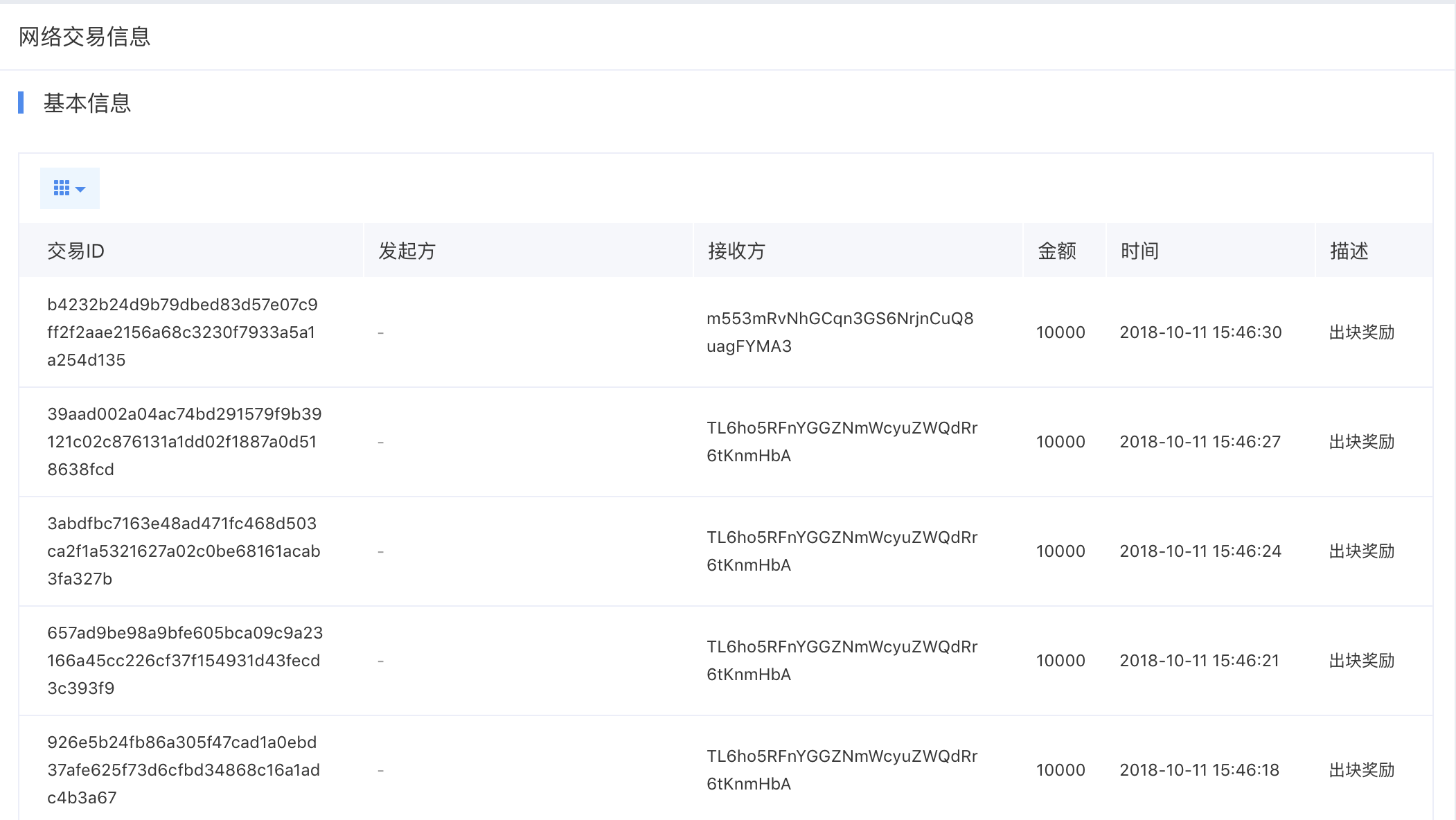Note: The most recent transaction in the figure above is a block reward, so there is no initiator.
- Wallet
- View your own balance