AIAK Introduction
What is AIAK?
The AI Accelerate Kit (referred to as AIAK) is a high-performance AI acceleration solution built on Baidu AI Cloud IaaS resources. It is designed to enhance AI applications leveraging deep learning frameworks like PyTorch and TensorFlow, significantly boosting the efficiency of distributed training and inference. The diagram below illustrates the overall architecture of the AIAK solution.

Application scenarios
The AI Acceleration Kit (AIAK) supports, but is not limited to, the following scenarios:
- Natural Language Processing tasks (e.g., BERT, Transformer).
- Image recognition tasks (e.g., ResNet).
Advantages
- Multi-framework compatibility: Offers acceleration and optimization capabilities for several AI frameworks, including TensorFlow and PyTorch.
- Lightweight and user-friendly: Requires only minimal adjustments to algorithm or model code developed using open-source frameworks.
AIAK-Training
AIAK-Training is a distributed training framework specifically tailored and optimized based on Horovod. It retains Horovod's original functionality while introducing new communication optimization features to further enhance distributed training throughput. AIAK-Training is entirely compatible with the original Horovod APIs, meaning users already employing native Horovod for training can continue using their existing code without any modifications. The diagram below elaborates on the architecture of AIAK-Training.

New acceleration features (vs. native Horovod):
- Incorporates an enhanced hierarchical Allreduce implementation, delivering a 10% performance boost compared to Horovod's native hierarchical Allreduce approach.
- Supports deep gradient compression (DGC) communication technology, effectively reducing communication volume and improving transmission efficiency. Currently, this feature is available for PyTorch only.
- Enables overlapping of parameter update computation with gradient communication, eliminating the need to wait for global communication to complete before conducting parameter updates. This approach further minimizes communication delays. This feature is currently available for PyTorch only.
- Supports fused optimizers by combining parameter update computation kernels, leading to reduced overheads such as memory access latency and kernel launch time. Currently, this feature is available for PyTorch only.
Performance
In a TCP-30Gbps-1NIC environment: Achieves an 85.5% performance improvement with 2 servers (8 GPUs per server) and a 43.7% performance improvement with 4 servers (8 GPUs per server).
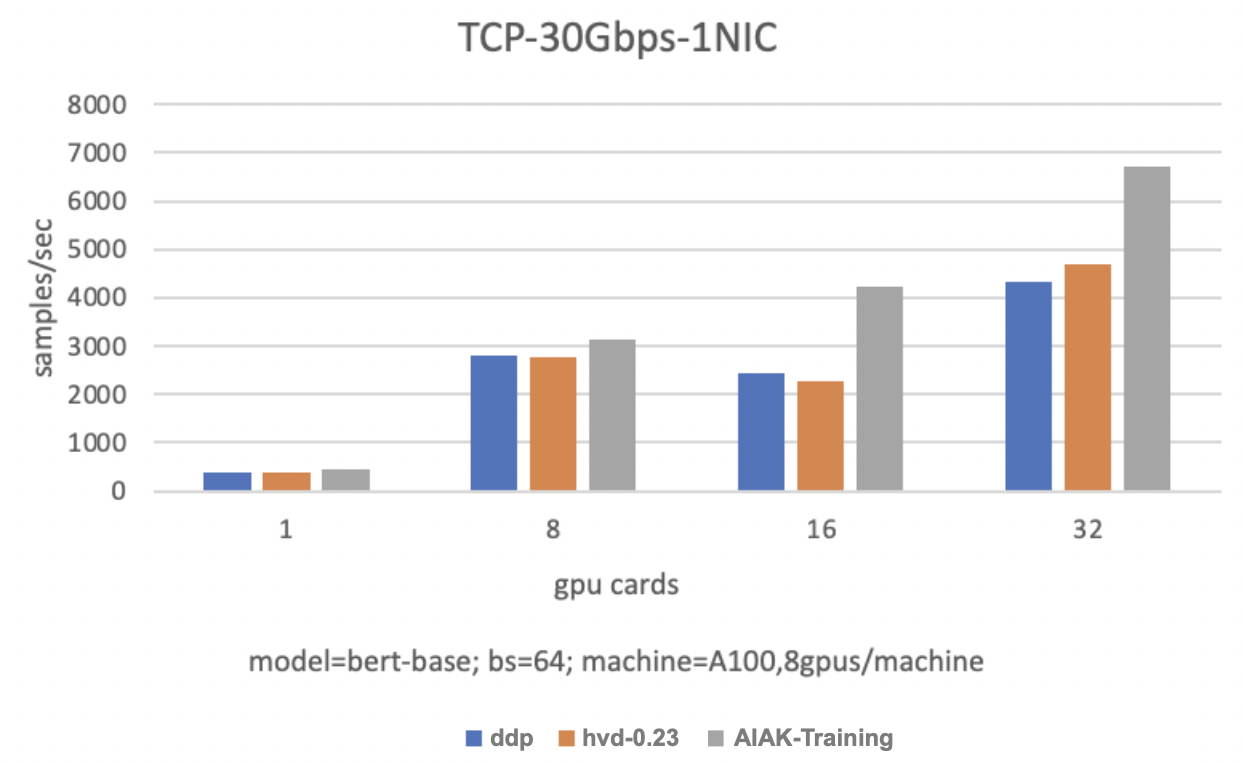
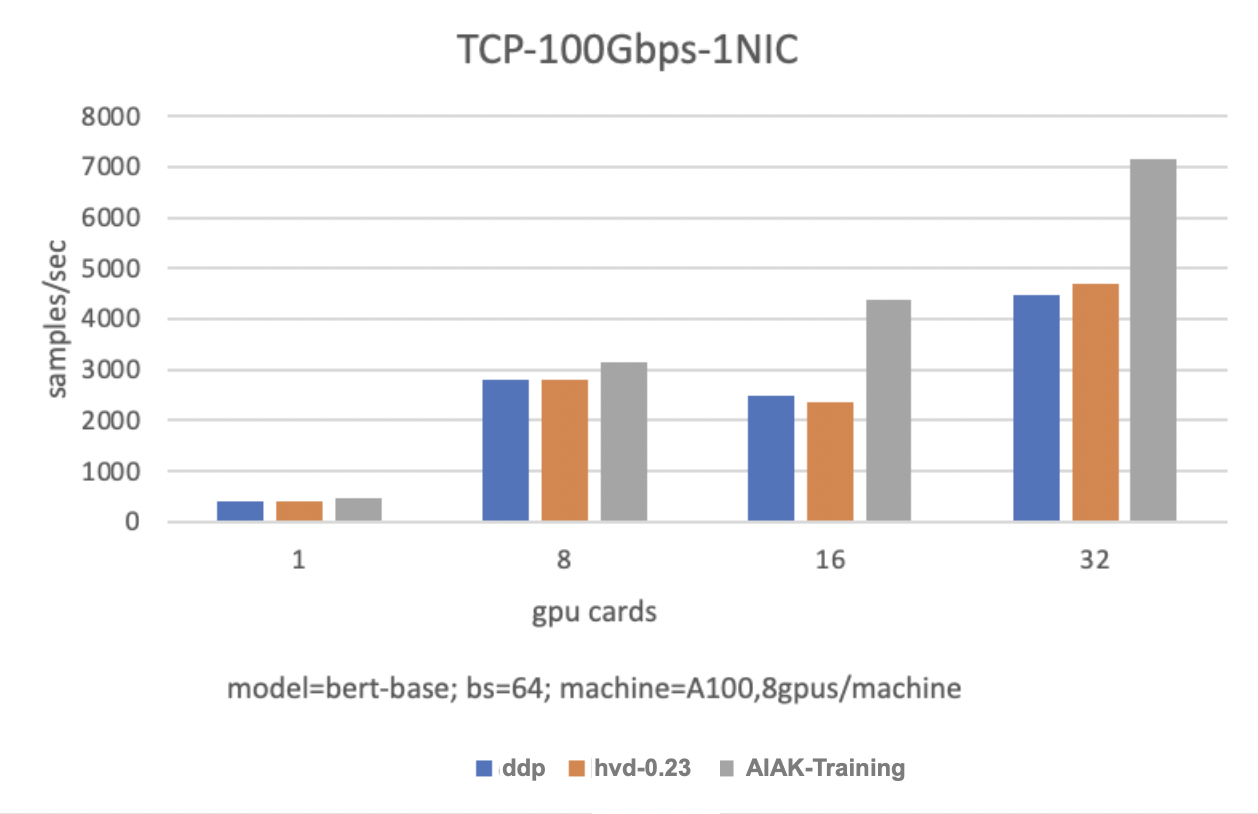
In a TCP-100Gbps-1NIC environment: Achieves an 85.5% performance improvement with 2 servers (8 GPUs per server) and a 52.1% performance improvement with 4 servers (8 GPUs per server).
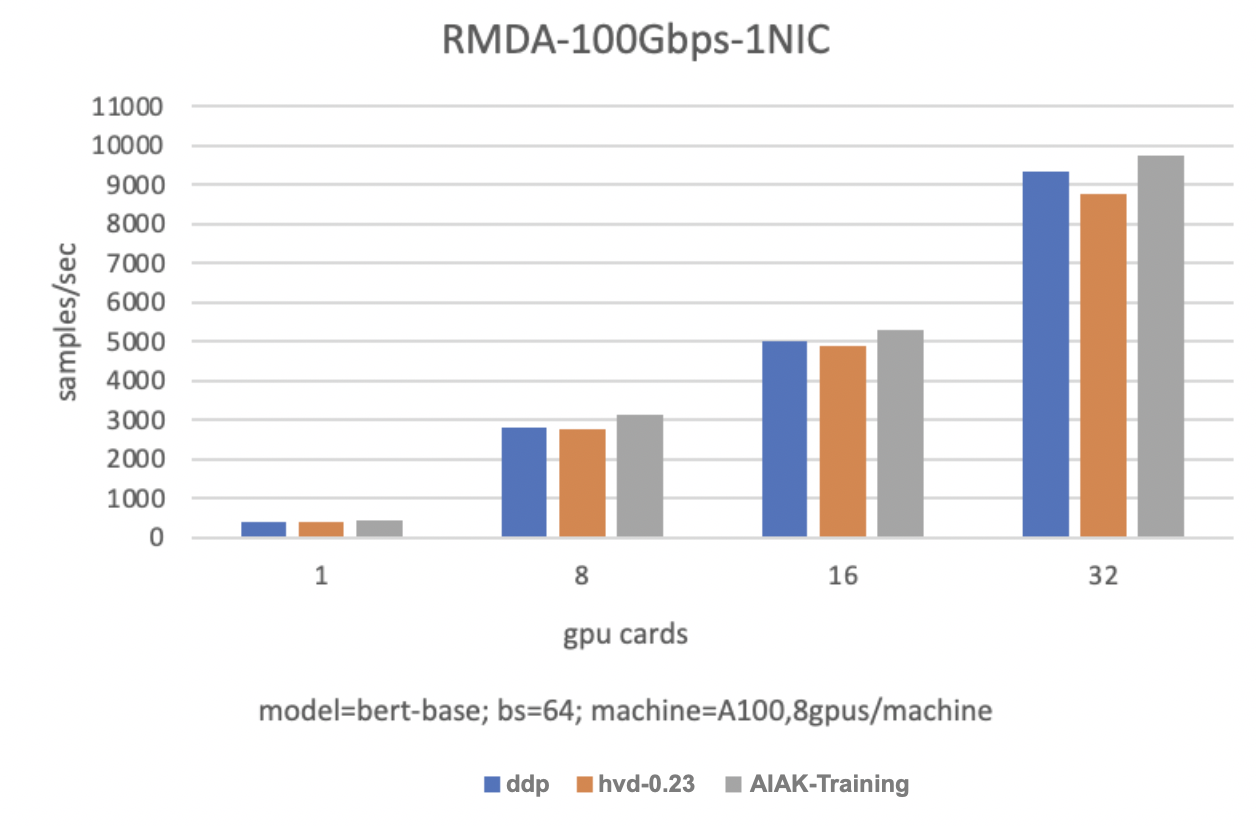
In an RDMA-100Gbps-1NIC environment: Achieves an 8.5% performance improvement with 2 servers (8 GPUs per server) and an 11.4% performance improvement with 4 servers (8 GPUs per server).
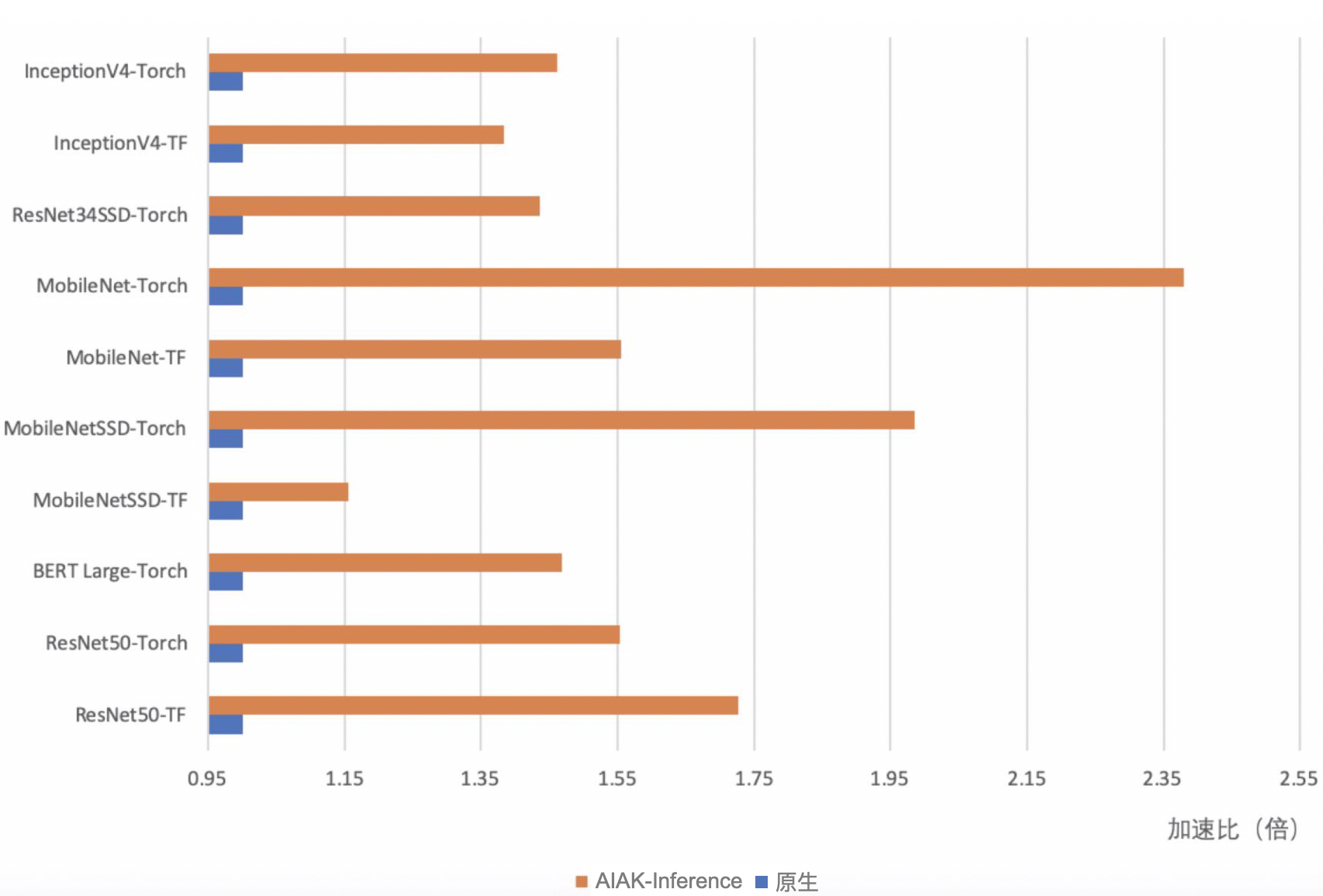
AIAK-Inference
AIAK-Inference offers model optimizations for frameworks like TensorFlow and PyTorch, reducing online inference latency, increasing service throughput, and significantly improving the utilization of heterogeneous resources. The diagram below depicts the architecture of AIAK-Inference.
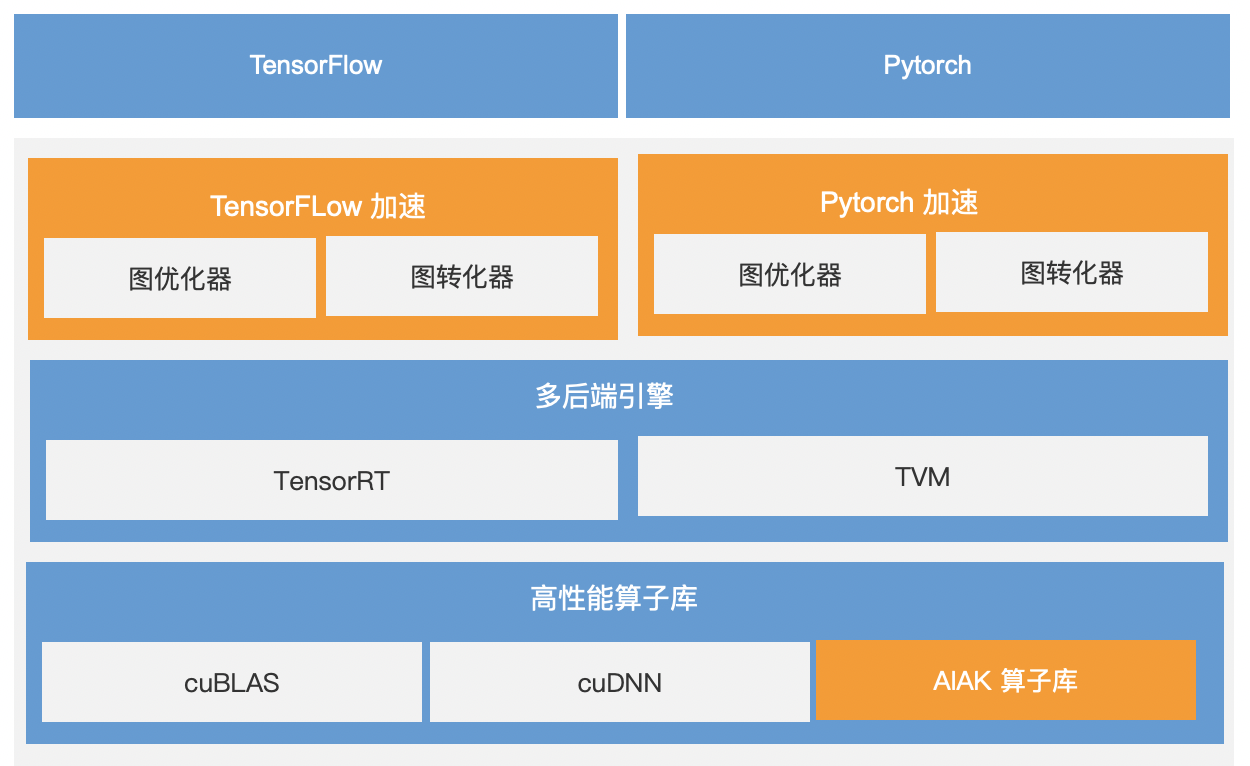
The overall inference acceleration is divided into 5 modules, with their functional briefings as follows:
- Framework Integration: Seamlessly integrates with mainstream deep learning frameworks like TensorFlow and PyTorch, utilizing their native capabilities directly without requiring inter-framework graph conversions. This approach minimizes unnecessary performance loss.
- Graph Optimizer: Analyzes model information comprehensively and automatically partitions the model based on hardware chip characteristics, facilitating subgraph fusion and minimizing redundant memory access.
- Graph Transformer: Converts optimized subgraphs into formats compatible with multi-backend engines for efficient backend inference.
- Multi-backend engine: Distributes tasks across different types of inference engines based on various model structures. It also optimizes for both popular and less common models, achieving a balance between performance and flexibility.
- High-performance operator library: Combines standard operator libraries from hardware vendors with advanced customizations for typical architectures (e.g., Transformer) in common models and compute-intensive operators (GEMM, Conv). This ensures the model maximizes hardware performance during inference.
Performance
Graph optimization and operator fusion enhance acceleration efficiency. For classic models like ResNet, speed enhancements range between 15% and 135%.