
CCE Supports GPUSharing Cluster
Introduction to K8S GPUSharing
K8S GPU scheduling based on the nvidia-device-plugin typically uses a "GPU card" as the minimum granularity, where each Pod is bound to at least one card. While this approach provides excellent isolation, it has limitations in the following scenarios:
- In AI development and inference scenarios, GPU utilization is relatively low. By allowing multiple Pods to share a single card, GPU utilization can be improved;
- K8S clusters may include a mix of different GPU card types with varying computing power; scheduling decisions consider these card types.
For these reasons, CCE is making its internal KongMing GPUSharing solution available, offering the GPUSharing feature to support both multi-Pod sharing on a single GPU card and scheduling based on card type.
Use GPUSharing in CCE
New cluster
CCE supports directly creating a GPUSharing cluster. First, follow the normal cluster creation process to select parameters, then switch to "Custom Cluster Configuration" mode before submission:
Modify clusterType to gpuShare and initiate cluster creation directly:
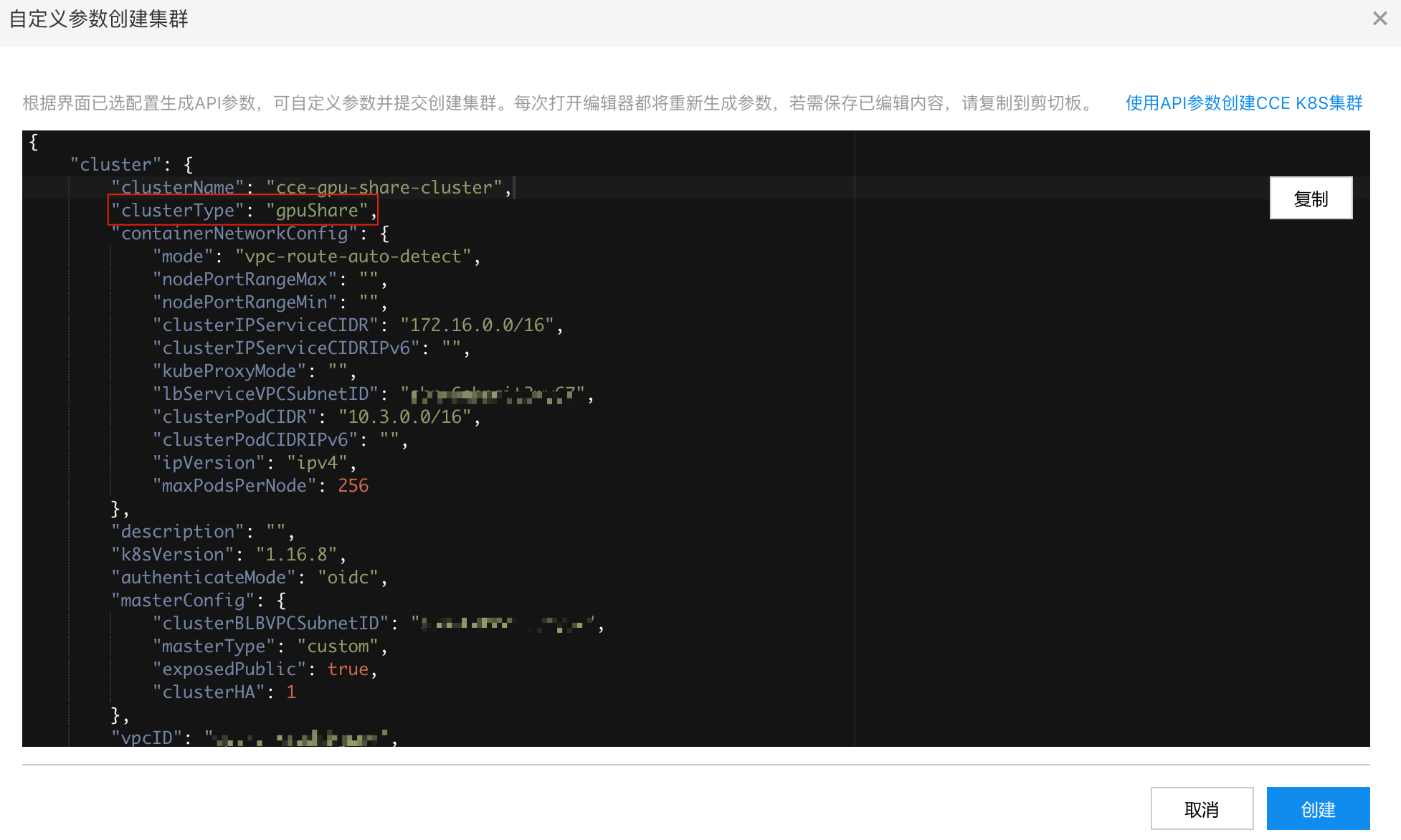
Note: In the future, GPUSharing clusters will be directly supported for enhanced convenience.
Existing cluster
For existing clusters, you can modify component configurations yourself as described in the following document. It is recommended to back up configurations before making modifications. All operations below are performed on the master node and only support custom clusters.
Deploy extender-scheduler
Modify the /etc/kubernetes/scheduler-policy.json configuration
Back up the existing configuration:
1$cp /etc/kubernetes/scheduler-policy.json /etc/kubernetes/scheduler-policy.json.bakModify scheduler-policy.json. The following configuration supports common GPU card types such as v100, k40, p40 and p4; adjust it according to actual needs:
1{
2 "kind": "Policy",
3 "apiVersion": "v1",
4 "predicates": [{"name":"PodFitsHostPorts"},{"name":"PodFitsResources"},{"name":"NoDiskConflict"},{"name":"CheckVolumeBinding"},{"name":"NoVolumeZoneConflict"},{"name":"MatchNodeSelector"},{"name":"HostName"}],
5 "priorities": [{"name":"ServiceSpreadingPriority","weight":1},{"name":"EqualPriority","weight":1},{"name":"LeastRequestedPriority","weight":1},{"name":"BalancedResourceAllocation","weight":1}],
6 "extenders":[
7 {
8 "urlPrefix":"http://127.0.0.1:39999/gpushare-scheduler",
9 "filterVerb":"filter",
10 "bindVerb":"bind",
11 "enableHttps":false,
12 "nodeCacheCapable":true,
13 "ignorable":false,
14 "managedResources":[
15 {
16 "name":"baidu.com/v100_cgpu_memory",
17 "ignoredByScheduler":false
18 },
19 {
20 "name":"baidu.com/v100_cgpu_core",
21 "ignoredByScheduler":false
22 },
23 {
24 "name":"baidu.com/k40_cgpu_memory",
25 "ignoredByScheduler":false
26 },
27 {
28 "name":"baidu.com/k40_cgpu_core",
29 "ignoredByScheduler":false
30 },
31 {
32 "name":"baidu.com/p40_cgpu_memory",
33 "ignoredByScheduler":false
34 },
35 {
36 "name":"baidu.com/p40_cgpu_core",
37 "ignoredByScheduler":false
38 },
39 {
40 "name":"baidu.com/p4_cgpu_memory",
41 "ignoredByScheduler":false
42 },
43 {
44 "name":"baidu.com/p4_cgpu_core",
45 "ignoredByScheduler":false
46 }
47 ]
48 }
49 ],
50 "hardPodAffinitySymmetricWeight": 10
51}Modify the /etc/systemd/system/kube-extender-scheduler.service configuration
1[Unit]
2Description=Kubernetes Extender Scheduler
3After=network.target
4After=kube-apiserver.service
5After=kube-scheduler.service
6[Service]
7Environment=KUBECONFIG=/etc/kubernetes/admin.conf
8ExecStart=/opt/kube/bin/kube-extender-scheduler \
9--logtostderr \
10--policy-config-file=/etc/kubernetes/scheduler-policy.json \
11--mps=false \
12--core=100 \
13--health-check=true \
14--memory-unit=GiB \
15--mem-quota-env-name=GPU_MEMORY \
16--compute-quota-env-name=GPU_COMPUTATION \
17--v=6
18Restart=always
19Type=simple
20LimitNOFILE=65536
21[Install]
22WantedBy=multi-user.targetDeploy extender-scheduler
Binary addresses for different regions:
- Beijing: http://baidu-container.bj.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- Guangzhou: http://baidu-container-gz.gz.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- Suzhou: http://baidu-container-su.su.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- Baoding: http://baidu-container-bd.bd.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- Hong Kong: http://baidu-container-hk.hkg.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
- Wuhan: http://baidu-container-whgg.fwh.bcebos.com/packages/gpu-extender/nvidia-share-extender-scheduler
Download binary:
1$wget -q -O /opt/kube/bin/kube-extender-scheduler http://baidu-container.bj.bcebos.com/packages/gpu-extender/nvidia-share-extender-schedulerStart the extender-scheduler service:
1$chmod +x /opt/kube/bin/kube-extender-scheduler
2$systemctl daemon-reload
3$systemctl enable kube-extender-scheduler.service
4$systemctl restart kube-extender-scheduler.serviceRestart the scheduler
1$systemctl restart kube-scheduler.serviceTypically, there are three master replicas. Execute the above operations for each one sequentially.
Deploy device-plugin
Back up the nvidia-device-plugin, then delete it (it can coexist with nvidia-device-plugin):
1$ kubectl get ds nvidia-device-plugin-daemonset -n kube-system -o yaml > nvidia-device-plugin.yaml
2$ kubectl delete ds nvidia-device-plugin-daemonset -n kube-systemDeploy kongming-device-plugin using the following all-in-one YAML:
1# RBAC authn and authz
2apiVersion: v1
3kind: ServiceAccount
4metadata:
5 name: cce-gpushare-device-plugin
6 namespace: kube-system
7 labels:
8 k8s-app: cce-gpushare-device-plugin
9 kubernetes.io/cluster-service: "true"
10 addonmanager.kubernetes.io/mode: Reconcile
11---
12kind: ClusterRole
13apiVersion: rbac.authorization.k8s.io/v1
14metadata:
15 name: cce-gpushare-device-plugin
16 labels:
17 k8s-app: cce-gpushare-device-plugin
18 kubernetes.io/cluster-service: "true"
19 addonmanager.kubernetes.io/mode: Reconcile
20rules:
21 - apiGroups:
22 - ""
23 resources:
24 - nodes
25 verbs:
26 - get
27 - list
28 - watch
29 - apiGroups:
30 - ""
31 resources:
32 - events
33 verbs:
34 - create
35 - patch
36 - apiGroups:
37 - ""
38 resources:
39 - pods
40 verbs:
41 - update
42 - patch
43 - get
44 - list
45 - watch
46 - apiGroups:
47 - ""
48 resources:
49 - nodes/status
50 verbs:
51 - patch
52 - update
53---
54kind: ClusterRoleBinding
55apiVersion: rbac.authorization.k8s.io/v1
56metadata:
57 namespace: kube-system
58 name: cce-gpushare-device-plugin
59 labels:
60 k8s-app: cce-gpushare-device-plugin
61 kubernetes.io/cluster-service: "true"
62 addonmanager.kubernetes.io/mode: Reconcile
63subjects:
64 - kind: ServiceAccount
65 name: cce-gpushare-device-plugin
66 namespace: kube-system
67 apiGroup: ""
68roleRef:
69 kind: ClusterRole
70 name: cce-gpushare-device-plugin
71 apiGroup: ""
72---
73apiVersion: apps/v1
74kind: DaemonSet
75metadata:
76 namespace: kube-system
77 name: cce-gpushare-device-plugin
78 labels:
79 app: cce-gpushare-device-plugin
80spec:
81 updateStrategy:
82 type: RollingUpdate
83 selector:
84 matchLabels:
85 app: cce-gpushare-device-plugin
86 template:
87 metadata:
88 labels:
89 app: cce-gpushare-device-plugin
90 spec:
91 serviceAccountName: cce-gpushare-device-plugin
92 nodeSelector:
93 beta.kubernetes.io/instance-type: GPU
94 containers:
95 - name: cce-gpushare-device-plugin
96 image: hub.baidubce.com/jpaas-public/cce-nvidia-share-device-plugin:v0
97 imagePullPolicy: Always
98 args:
99 - --logtostderr
100 - --mps=false
101 - --core=100
102 - --health-check=true
103 - --memory-unit=GiB
104 - --mem-quota-env-name=GPU_MEMORY
105 - --compute-quota-env-name=GPU_COMPUTATION
106 - --gpu-type=baidu.com/gpu_k40_4,baidu.com/gpu_k40_16,baidu.com/gpu_p40_8,baidu.com/gpu_v100_8,baidu.com/gpu_p4_4
107 - --v=1
108 resources:
109 limits:
110 memory: "300Mi"
111 cpu: "1"
112 requests:
113 memory: "300Mi"
114 cpu: "1"
115 env:
116 - name: NODE_NAME
117 valueFrom:
118 fieldRef:
119 fieldPath: spec.nodeName
120 securityContext:
121 allowPrivilegeEscalation: false
122 capabilities:
123 drop: ["ALL"]
124 volumeMounts:
125 - name: device-plugin
126 mountPath: /var/lib/kubelet/device-plugins
127 volumes:
128 - name: device-plugin
129 hostPath:
130 path: /var/lib/kubelet/device-plugins
131 dnsPolicy: ClusterFirst
132 hostNetwork: true
133 restartPolicy: AlwaysCheck node resources
Run kubectl get node -o yaml to view new GPU resources on the node:
1 allocatable:
2 baidu.com/gpu-count: "1"
3 baidu.com/t4_cgpu_core: "100"
4 baidu.com/t4_cgpu_memory: "14"
5 cpu: 23870m
6 ephemeral-storage: "631750310891"
7 hugepages-1Gi: "0"
8 hugepages-2Mi: "0"
9 memory: "65813636449"
10 pods: "256"
11 capacity:
12 baidu.com/gpu-count: "1"
13 baidu.com/t4_cgpu_core: "100"
14 baidu.com/t4_cgpu_memory: "14"
15 cpu: "24"
16 ephemeral-storage: 685492960Ki
17 hugepages-1Gi: "0"
18 hugepages-2Mi: "0"
19 memory: 74232212Ki
20 pods: "256"Submit test tasks
Submit test tasks:
1apiVersion: v1
2kind: ReplicationController
3metadata:
4 name: paddlebook
5spec:
6 replicas: 1
7 selector:
8 app: paddlebook
9 template:
10 metadata:
11 name: paddlebook
12 labels:
13 app: paddlebook
14 spec:
15 containers:
16 - name: paddlebook
17 image: hub.baidubce.com/cce/tensorflow:gpu-benckmarks
18 command: ["/bin/sh", "-c", "sleep 3600"]
19 #command: ["/bin/sh", "-c", "python /root/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py --num_gpus=1 --batch_size=32 --model=resnet50 --variable_update=parameter_server"]
20 resources:
21 requests:
22 baidu.com/t4_cgpu_core: 10
23 baidu.com/t4_cgpu_memory: 2
24 limits:
25 baidu.com/t4_cgpu_core: 10
26 baidu.com/t4_cgpu_memory: 2