Accelerating Inference Business Using AIAK-Inference
Prerequisites
- Choose the AIAK-Inference acceleration image from CCR as the base image.
Operation process
TensorFlow model optimization
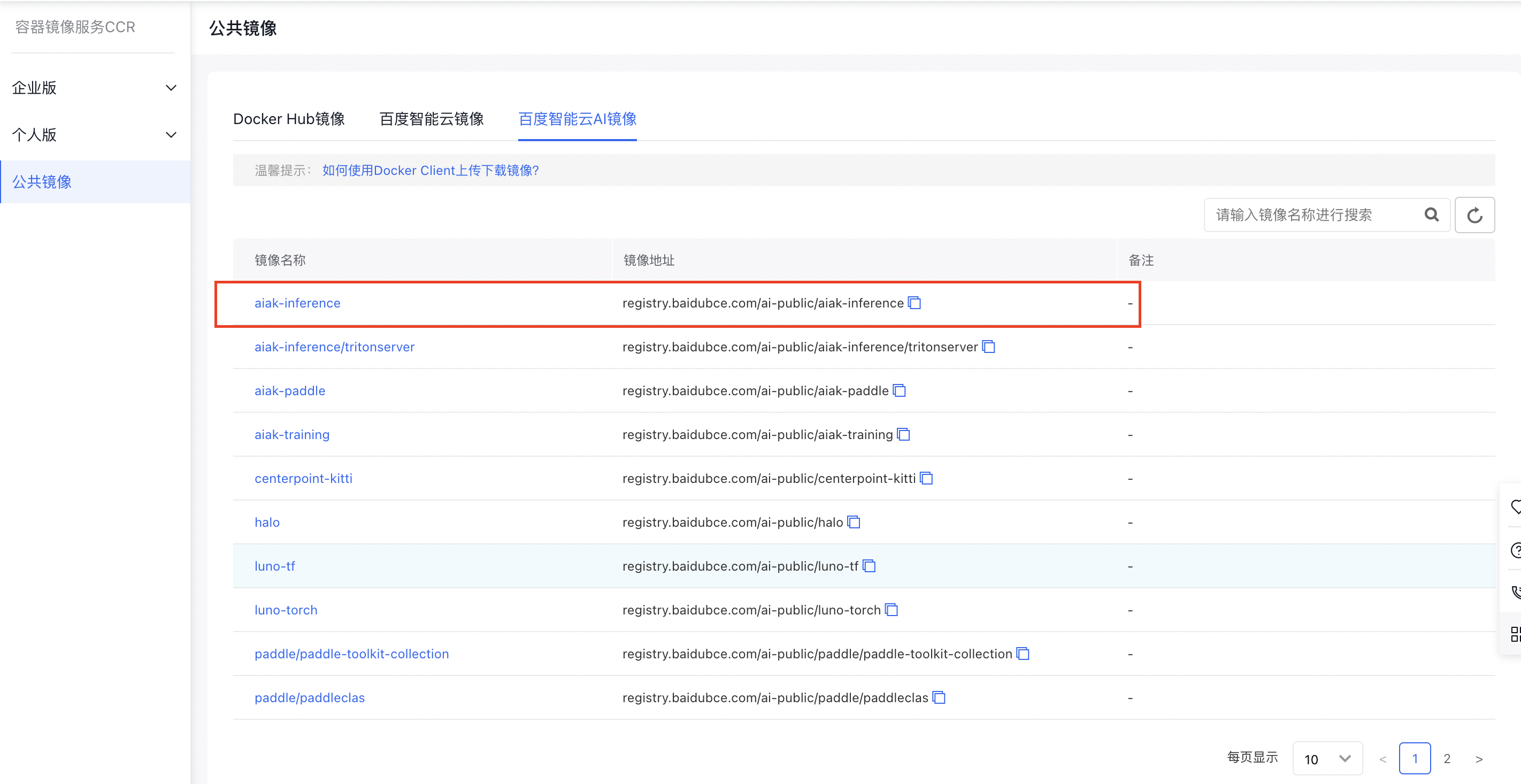
In the "Baidu AI Cloud AI Images" section of CCR public images, select the aiak-inference:ubuntu18.04-cu11.2-tf2.4.1-py3.6-aiak1.1-latest tag (or use the command docker pull registry.baidubce.com/ai-public/aiak-inference:ubuntu18.04-cu11.2-tf2.4.1-py3.6-aiak1.1-latest to pull the image). The image includes pre-installed libraries such as CUDA and TensorFlow 2.4.1.
Prepare the ResNet50 model in the container:
1import os
2import numpy as np
3import tensorflow.compat.v1 as tf
4tf.compat.v1.disable_eager_execution()
5
6def _wget_demo_tgz():
7# Download a public ResNet50 model.
8 url = 'http://url/to/your/model/YOUR_MODEL.tar.gz'
9 local_tgz = os.path.basename(url)
10 local_dir = local_tgz.split('.')[0]
11 if not os.path.exists(local_dir):
12 luno.util.wget(url, local_tgz)
13 luno.util.unpack(local_tgz)
14 model_path = os.path.abspath(os.path.join(local_dir, "frozen_inference_graph.pb"))
15 graph_def = tf.GraphDef()
16 with open(model_path, 'rb') as f:
17 graph_def.ParseFromString(f.read())
18# Use random numbers as test data.
19 test_data = np.random.rand(1, 800, 1000, 3)
20 return graph_def, {'image_tensor:0': test_data}
21
22graph_def, test_data = _wget_demo_tgz()
23
24input_nodes=['image_tensor']
25output_nodes = ['detection_boxes', 'detection_scores', 'detection_classes', 'num_detections', 'detection_masks']Then attempt to run inference on this model:
1import time
2
3def benchmark(model):
4 tf.reset_default_graph()
5 with tf.Session() as sess:
6 sess.graph.as_default()
7 tf.import_graph_def(model, name="")
8 # Warmup!
9 for i in range(0, 1000):
10 sess.run(['image_tensor:0'], test_data)
11 # Benchmark!
12 num_runs = 1000
13 start = time.time()
14 for i in range(0, num_runs):
15 sess.run(['image_tensor:0'], test_data)
16 elapsed = time.time() - start
17 rt_ms = elapsed / num_runs * 1000.0
18 # Show the result!
19 print("Latency of model: {:.2f} ms.".format(rt_ms))
20
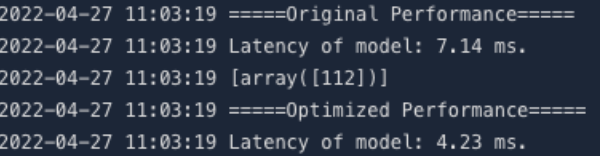
21# original graph
22print("before compile:")
23benchmark(graph_def)Next, introduce AIAK-Inference optimization:
1import aiak_inference
2optimized_model = aiak_inference.optimize(
3graph_def,
4'gpu',
5outputs=['detection_boxes', 'detection_scores', 'detection_classes', 'num_detections', 'detection_masks']
6)The optimized model remains a GraphDef model, and the same code can be used for inference:
1# optimized graph
2print("after compile:")
3benchmark(optimized_model)Through comparison, performance improvement can be observed:
PyTorch model optimization
In the "AI Acceleration Images" section of CCR public images, choose the aiak-inference:cuda11.2_cudnn8_trt8.4_torch1.11-aiak_1.1.1_latest tag (or use the command docker pull registry.baidubce.com/ai-public/aiak-inference:cuda11.2_cudnn8_trt8.4_torch1.11-aiak_1.1.1_latest to pull the image). The image comes with pre-installed CUDA and PyTorch 1.11 libraries.
Prepare PyTorch-related models in the container (taking ResNet50 as an example):
1import os
2import time
3import torch
4import torchvision.models as models
5model = models.resnet50().float().cuda()
6 model = torch.jit.script(model).eval() # Convert to a static graph using JIT
7dummy = torch.rand(1, 3, 224, 224).cuda()Attempt to run inference:
1@torch.no_grad()
2def benchmark(model, inp):
3 for i in range(100):
4 model(inp)
5 start = time.time()
6 for i in range(200):
7 model(inp)
8 elapsed_ms = (time.time() - start) * 1000
9 print("Latency: {:.2f}".format(elapsed_ms / 200))
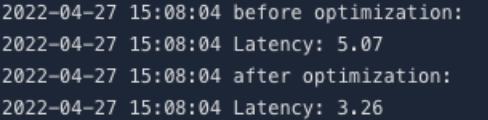
10# benchmark before optimization
11print("before optimization:")
12benchmark(model, dummy)Then use AIAK-Inference to optimize the model and obtain the optimized model:
1import aiak_inference
2optimized_model = aiak_inference.optimize(
3model,
4'gpu',
5test_data=[dummy],
6)Run inference again:
1# benchmark after optimization
2print("after optimization:")
3benchmark(optimized_model, dummy)Compare the performance of the two; a significant reduction in single-inference latency can be observed, which confirms the acceleration capability of AIAK-Inference: