
Kubernetes Version Overview and Mechanism
Kubernetes community releases a minor version every 4 months approximately. CCE clusters in Kubernetes version will realize the Kubernetes version iterations according to the version release schedule of the community, including version creation, maintenance and end-of-life.
This document introduces CCE Kubernetes version support mechanism, including version release and support status, version lifecycle description, version support strategy, etc.
Version release
The detailed information about the Kubernetes versions supported by CCE managed clusters and CCE standalone clusters is as follows.
| Version | Status | CCE Release Time | CCE End-of-Life Time |
|---|---|---|---|
| 1.31 | Released | July 2025 | July 2026 Important: Since Version 1.31, CCE has expanded the Kubernetes version support scope from only supporting even minor versions (e.g., 1.28, 1.30, etc.) to supporting all minor versions. Additionally, for minor versions 1.31 and later, the CCE support cycle has been adjusted to 1 year. |
| 1.30 | Released | August 2024 | March 2026 |
| 1.28 | Released | June 2024 | November 2025 |
End-of-Life versions
Important: Outdated version clusters pose security and stability risks. Please refer to Manual Cluster Upgrade to promptly upgrade clusters to versions in maintenance.
| Version | Status | CCE Release Time | CCE End-of-Life Time |
|---|---|---|---|
| 1.26 | End-of-Life | February 2024 | February 2025 |
| 1.24 | End-of-Life | April 2023 | April 2023 |
| 1.22 | End-of-Life | November 2022 | November 2023 |
| 1.20 | End-of-Life | June 2022 | June 2023 |
| 1.18 | End-of-Life | November 2021 | November 2022 |
| 1.16 | End-of-Life | June 2021 | June 2022 |
| 1.14 | End-of-Life | October 2020 | October 2021 |
| 1.12 | End-of-Life | July 2020 | July 2021 |
Version No. description
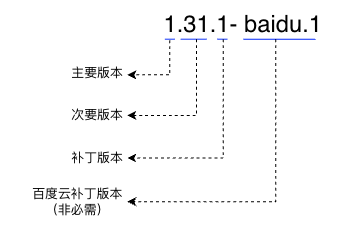
The CCE cluster follows the expression format of community Kubernetes version, which is x.y.z-baiduyun.n.
Where, x indicates the major version, y indicates the minor version, and z indicates the patch version.
baidu.n indicates the Baidu AI Cloud Patch Version (CCE patch version), which is optional and may or may not be present depending on the situation.
Version lifecycle
After the Kubernetes community releases a new minor version, CCE will conduct risk assessment and conformance testing for this version. Once completed, it will open up the creation and upgrade for the new version.
After the Kubernetes community releases a new patch version for a minor version, CCE will determine whether to release an upgrade for that patch version based on the risk level of the issues it fixes. For patch versions addressing high-risk security vulnerabilities, CCE typically completes evaluation and verification within 24 hours, after which it will open up the creation and upgrade operations for the new version.
Version support strategy
- Cluster Creation: CCE supports creating clusters for the three most recent Kubernetes minor versions. For example, the three most recent minor versions are 1.31, 1.30, and 1.28. After CCE supports version 1.31, version 1.26 will no longer be available for creation, and the outdated patch versions will also no longer be available for creation. When a new patch version is released for a minor version, the older patch versions of that minor version will no longer be available for creation. For example, after version 1.30.7 is released, version 1.30.1 will no longer support new creations.
- Cluster Upgrade: The version upgrade function currently only supports upgrading version step by step, does not support upgrading across multiple versions, and does not support version rollback. For example, if your CCE cluster Kubernetes version is 1.28 and you want to upgrade it to 1.31, you will need to perform two cluster upgrades, namely first to 1.30 and then to 1.31. For patch versions, the cluster upgrades only support upgrading to the latest patch version and do not support upgrading to outdated patch versions.
- Technical Support: For versions still maintained by CCE, the technical support provided by CCE includes answering questions, online guidance, troubleshooting, and debugging.
Risks of outdated versions
New CCE cluster versions are typically maintained for one year after release. Versions beyond the maintenance period are considered outdated.
The outdated version clusters pose security risks and stability issues. After a cluster version becomes outdated, it will no longer benefit from the functional features and bug fixes supported by new Kubernetes versions, and will not receive timely and effective technical support, facing the risk of unfixed security vulnerabilities.
You need to upgrade the cluster to a secure and stable version.
- Manual Cluster Upgrade: Upgrade versions step by step to the latest version. You can control the upgrade pace by specifying nodes to be upgraded, setting the maximum count of nodes that can be upgraded per batch, configuring upgrade intervals, and pause policies.
- Automatic Cluster Upgrade: Enable the automatic cluster upgrade function and choose a reasonable upgrade frequency to keep the cluster periodically upgraded. Coming soon, stay tuned.
Forced upgrade of outdated versions
Kubernetes community does not disclose CVE risks or provide patch fixes for versions beyond their maintenance period (usually 1 year), and the potential security risks in outdated versions may not be detected and fixed in time. Since CCE clusters primarily adopt a managed architecture, these security risks may not only affect your cluster but also the overall security of Baidu AI Cloud. Therefore, CCE does not allow clusters to remain in an outdated state for an extended period and will enforce upgrades to bring clusters to a secure and stable version.
After a cluster version is outdated, CCE will not immediately enforce an upgrade. It is recommended to manually upgrade the cluster to a secure and stable version. Before performing a forced upgrade, CCE will notify you at least one month in advance via SMS, email, or in-site messages.
When forcing a cluster version upgrade, the following contents will be upgraded:
- Upgrade the cluster components (only components with compatibility issues with higher cluster versions will be upgraded).
- Upgrade the cluster control plane.
- Upgrade the node pools and nodes.
FAQs
Can I choose not to upgrade the cluster version and stay on one version forever?
No. The potential security risks in outdated versions may not only affect your cluster but also the overall security of Baidu AI Cloud. CCE does not allow clusters to remain in an outdated state for an extended period and will enforce upgrades to bring clusters to a secure and stable version.
Please upgrade your cluster version promptly (Manual Cluster Upgrade) to enjoy the latest functional features and better technical support provided by CCE.
My cluster version is very old. How can I quickly upgrade my cluster version?
You can achieve this through the following two solutions.
- Solution I: Upgrade versions step by step. After each upgrade, observe whether the cluster services continue to run stably before proceeding with the next upgrade. For specific operations, refer to Manual Cluster Upgrade.
- Solution II: Create a new cluster with the latest version, gradually migrate the cluster applications to the new cluster, and then decommission the old cluster. For instructions on how to create and configure a cluster, refer to Create a CCE Managed Cluster.
Does CCE support upgrading across multiple versions?
CCE does not support upgrading across minor versions. You need to upgrade versions step by step. Additionally, before upgrading the cluster control plane, ensure that the versions of the cluster nodes match the control plane version.
How does CCE ensure the stability of cluster upgrades?
A CCE cluster consists of two parts: the control plane and the node pool.
- Control Plane Upgrade: CCE provides a pre-check function before upgrade to check the deprecated APIs, component compatibility, function configuration compatibility, and control plane components. The check results do not affect the normal operation of services in the cluster. If the check results are abnormal, refer to the console for repair suggestions. For more information, refer to Manual Cluster Upgrade.
- Node Pool Upgrade: The node pool upgrades include upgrading kubelet and containerd. CCE provides a pre-check function before upgrade to check the node status, system resources, disk status, and network environment. The check results do not affect the normal operation of services in the cluster. If the check results are abnormal, refer to the console for repair suggestions. You can also configure upgrade policies, such as specifying nodes to be upgraded, setting the maximum count of nodes that can be upgraded per batch, or configuring upgrade pause policies to control the upgrade pace. If there is critical business data on the node system disk, you can create snapshots for the nodes before upgrading the node pool.
What are the considerations for cluster upgrades?
- Cluster upgrades do not support rollback. It is recommended to upgrade the test environment first and verify its stability before upgrading the production environment.
- Each Kubernetes version supports different component versions, functional features, and functional deprecations. Refer to the release notes for different versions.