
Operate Cluster
Cluster scale-up
In the container service, you can scale up a cluster by adding new Worker nodes or integrating existing Baidu Cloud Compute (BCC) instances into the cluster.
Usage restrictions
- When adding new nodes or existing nodes, both pay-as-you-go and subscription types of nodes are supported.
- Please scale up within the cluster's quota limits. If the quota is insufficient, you can apply for quota expansion. For detailed operations and instructions, please refer to Usage Limits.
Operation steps
- Sign in to Baidu AI Cloud Management Console, navigate to Product Services - Cloud Native - Cloud Container Engine (CCE), and click Cluster Management - Cluster List to enter the cluster list page.
- Select the target cluster to be scaled up, click Add Node in the operation bar or click the Cluster Name to access the cluster details page, then select Node List - Add Node:
- In the node addition page, configure the specifications for the new node. For details, refer to Add Node.
- After reviewing the chosen configuration and associated costs, click on Complete to finalize the addition of new nodes following payment.
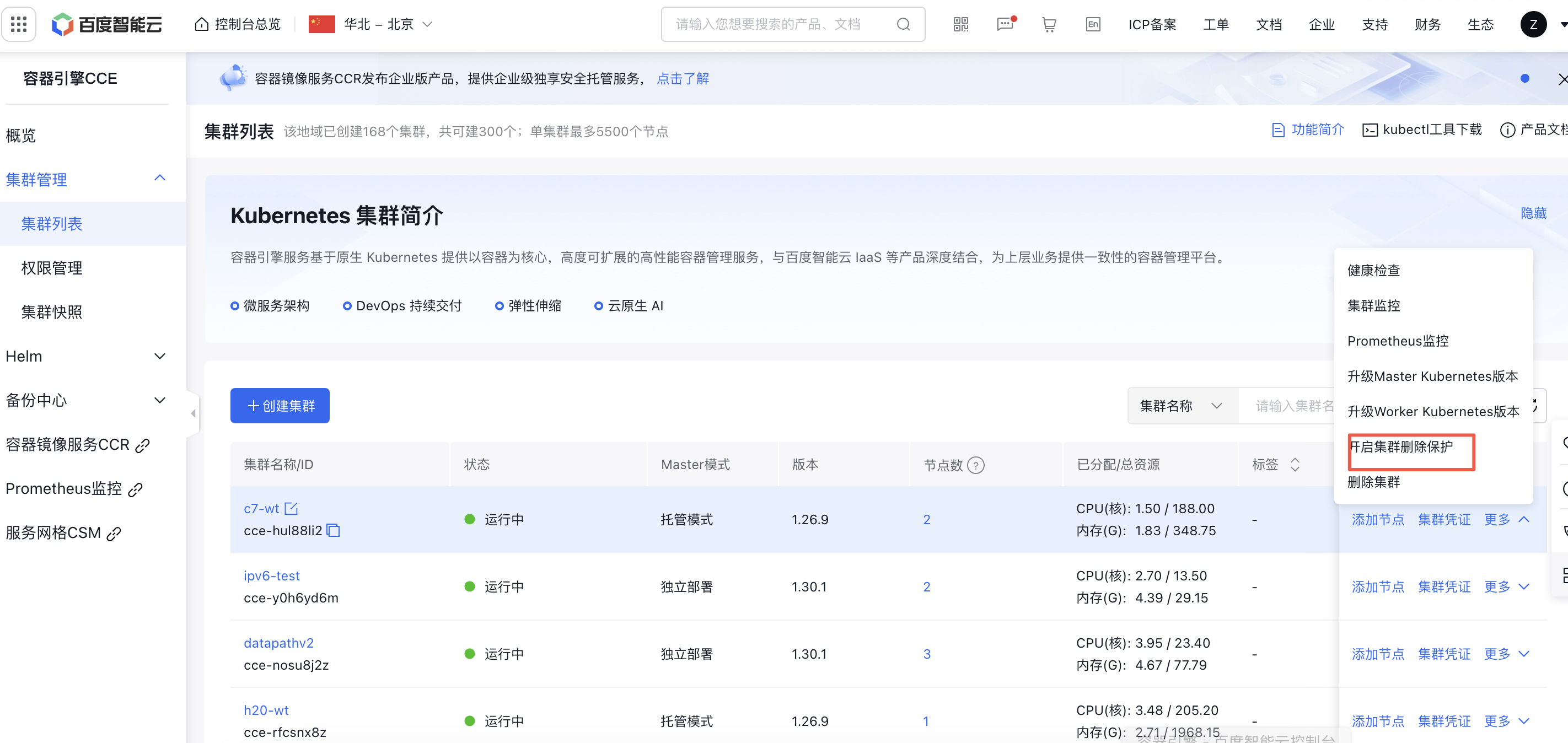
Cluster deletion protection
In practice, there are many scenarios where clusters may be accidentally deleted. For instance, if your account is accessed by multiple collaborators, other users might unintentionally delete clusters that do not belong to them. To address this, you can enable deletion protection measures for critical clusters through the console or API, preventing accidental deletions and safeguarding important data.
Operation steps
- Sign in to the Baidu AI Cloud Management Console and select the Cluster List from the navigation bar at the left side.
- In the Cluster list page, select the desired cluster and click More - Enable Deletion Protection on the right, or modify the deletion protection configuration in the cluster details page.
Delete cluster
Deleting a cluster will impact the resources created within it. This is a high-risk operation, so please ensure that the cluster is no longer in use before proceeding.
Prerequisites
- Ensure the existing cluster is confirmed to be no longer in use before proceeding.
- Ensure the deletion protection is not enabled for the cluster. If the deletion protection is enabled, you must disable deletion protection before deleting the cluster.
Note
Cluster deletion affects both billing and the resources within the cluster. Please proceed with caution. The detailed rules are as follows:
- During cluster deletion, nodes, disks, public IPs, and other resources will either be automatically deleted or retained based on the options you select below.
- If a resource is being used by other clusters or cloud services, it will be automatically retained. Retained resources will remain billable. Please review and manage them in the appropriate console.
- Deleted cluster cannot be recovered. Please operate carefully!
Operation steps
- Sign in to the Baidu AI Cloud Management Console and select the Cluster List from the navigation bar at the left side.
- In the cluster list page, select the desired cluster and click More - Delete Cluster on the right.
-
On the cluster deletion panel, confirm the resources that will be automatically deleted (e.g., nodes, disks, public IPs, etc.), select the resources to be retained as needed, carefully read the notes on resource deletion in the page, and complete the deletion operation as prompted.
Plain Text1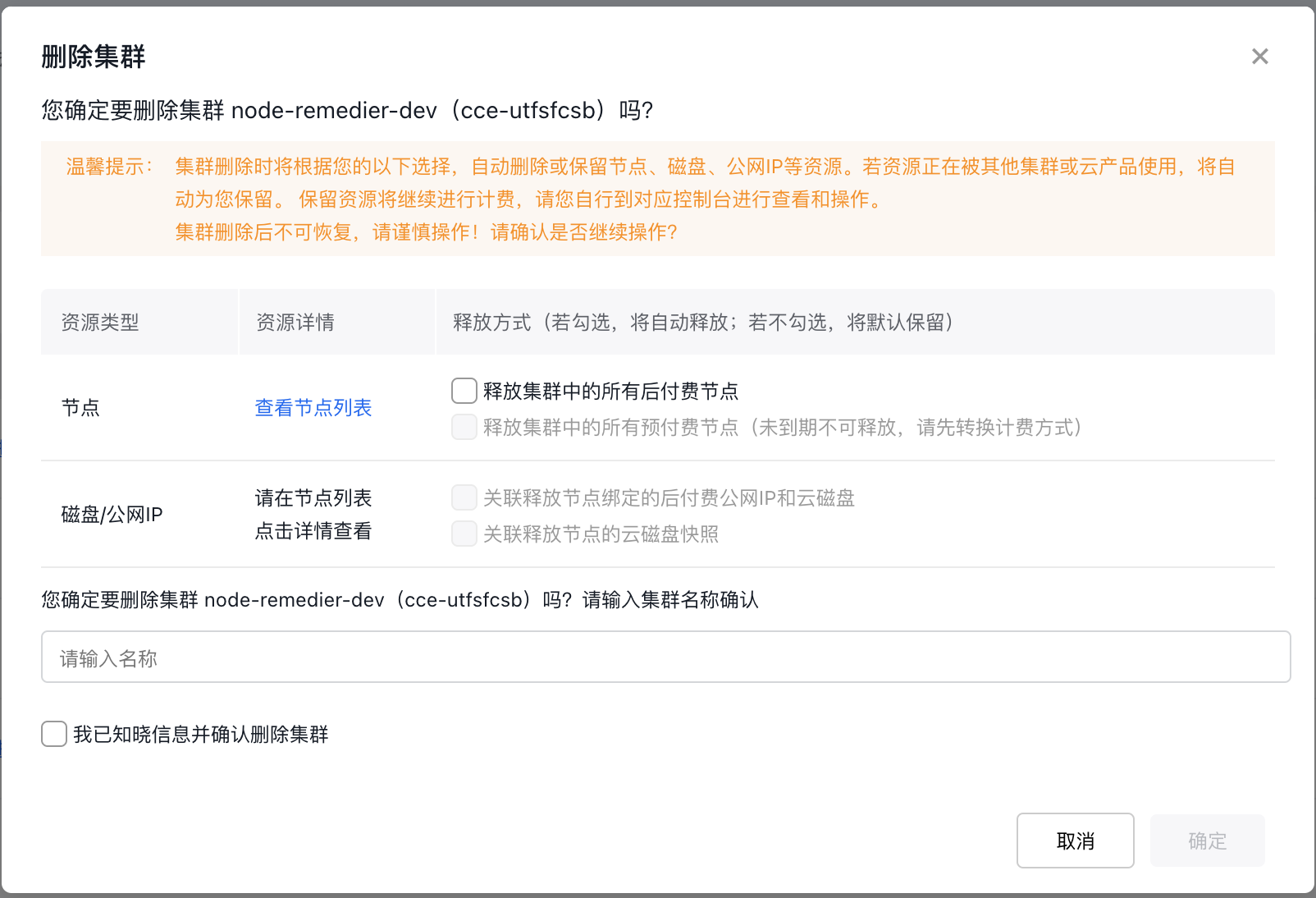
Description:
- If cluster deletion fails, you follow the prompts on the console to handle the issue and then re-execute this operation. You may also review operation logs to troubleshoot. If repeated attempts to delete the cluster fail, please submit a ticket for technical support.
- If you select "Retain Resources" on the cluster deletion prompt page, these resources will not be automatically deleted and will instead need to be manually released.
- Cluster deletion takes approximately 5-10 minutes. Please wait patiently. Once the cluster disappears from the cluster list, the deletion is complete.