
Create AI Training Task
Updated at:2025-10-27
Create a new task of the AITraining type. An AITrainingJob is an optimized AI training task that enhances computing efficiency, resource utilization, fault tolerance, and flexible scheduling.
Prerequisites
- You have successfully installed the CCE AI Job Scheduler and CCE Deep Learning Frameworks Operator components; without these, the cloud-native AI features will be unavailable.
- As an IAM user, you can only use a queue to create new tasks if you are part of the users linked to that queue.
- When you install the CCE Deep Learning Frameworks Operator component, the PyTorch deep learning framework is installed automatically.
Operation steps
- Sign in to the Baidu AI Cloud official website and enter the management console.
- Go to Product Services - Cloud Native - Cloud Container Engine (CCE) to access the CCE management console.
- Click Cluster Management - Cluster List in the left navigation pane.
- Click on the target cluster name in the Cluster List page to navigate to the cluster management page.
- On the Cluster Management page, click Cloud-Native AI - Task Management.
- Click Create Task on the Task Management page.
- On the Create Task page, configure basic task information:
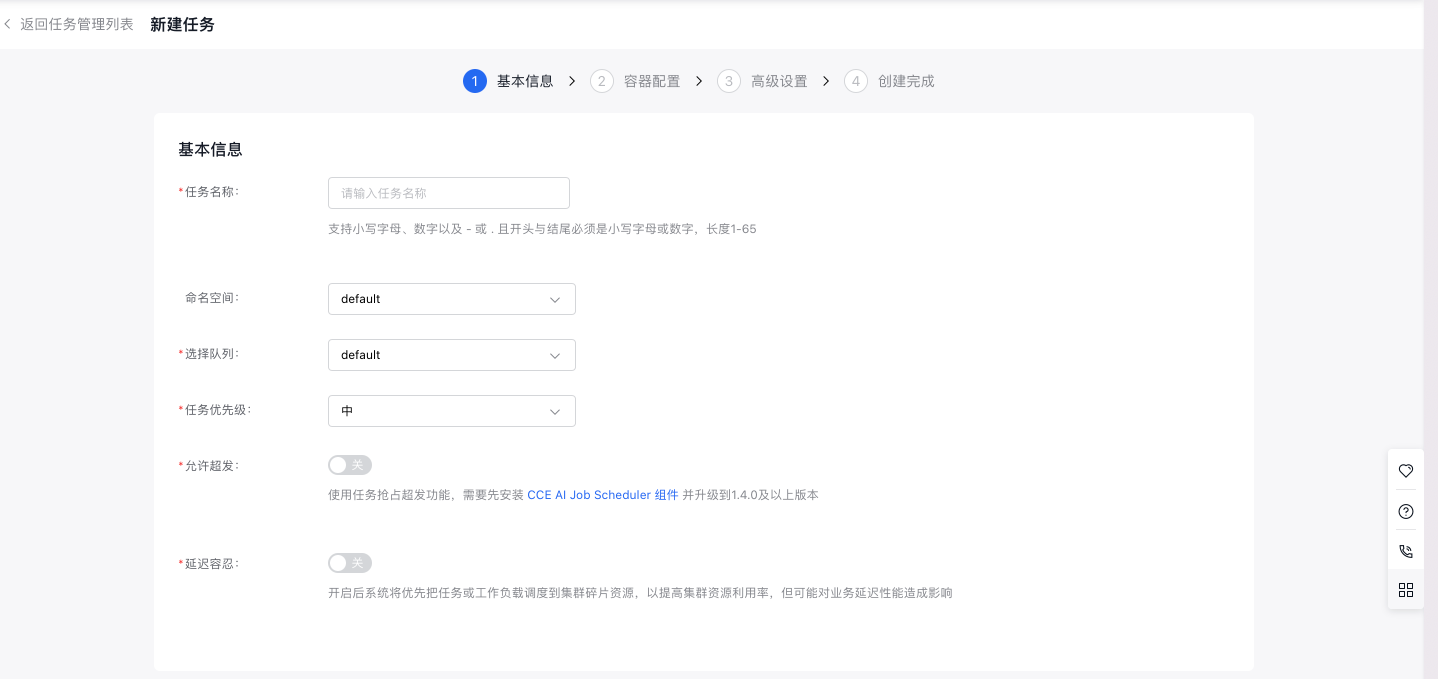
- The task name supports uppercase and lowercase letters, numbers, and special characters (-_/), must start with a letter or Chinese character, and should be 1 to 65 characters long.
- Namespace: Choose the namespace for the new task.
- Select queue: Choose the queue associated with the new task.
- Task priority: Set the priority level for the task.
- Allow overcommitment: Enable this option to use task preemption for overcommitment. The CCE AI Job Scheduler component must be installed and updated to version 1.4.0 or higher.
- Tolerance for delay: The system will prioritize scheduling tasks or workloads to fragmented cluster resources to enhance cluster resource utilization, though this might impact business latency performance.
- Configure basic code information:
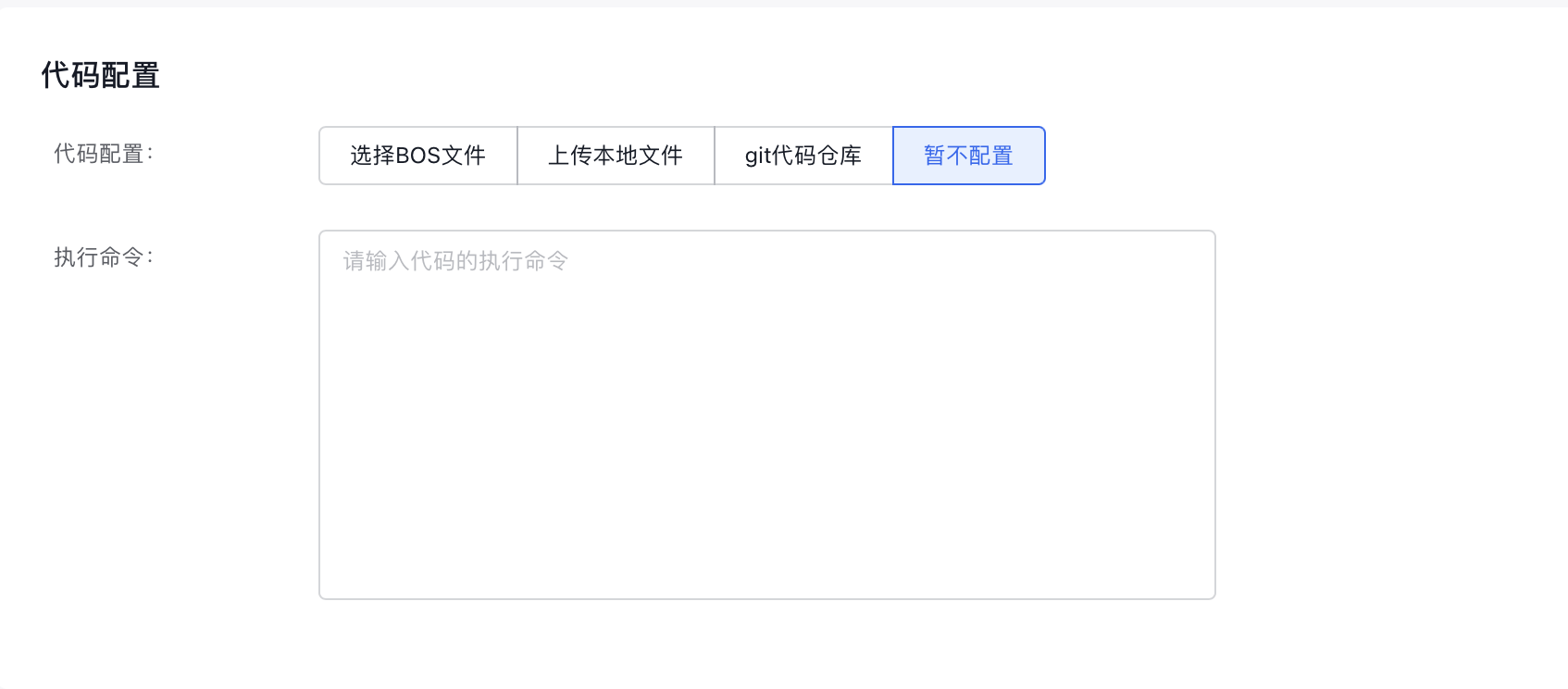
- Code configuration type: Specify the code configuration method. Current options include “BOS File,” “Local File Upload,” and “Not Configured Temporarily.”
- Execution command: Define the command to execute the code.
- Configure data-related information:

- Set data source: Currently supports datasets, persistent volume claims, temporary paths, and host paths. For datasets: All available datasets are listed; selecting a dataset automatically matches the PVC with the same name. For persistent volume claims: Choose the persistent volume claim directly.
- Click "Next" to proceed to container-related configurations.
- Configure task type information:
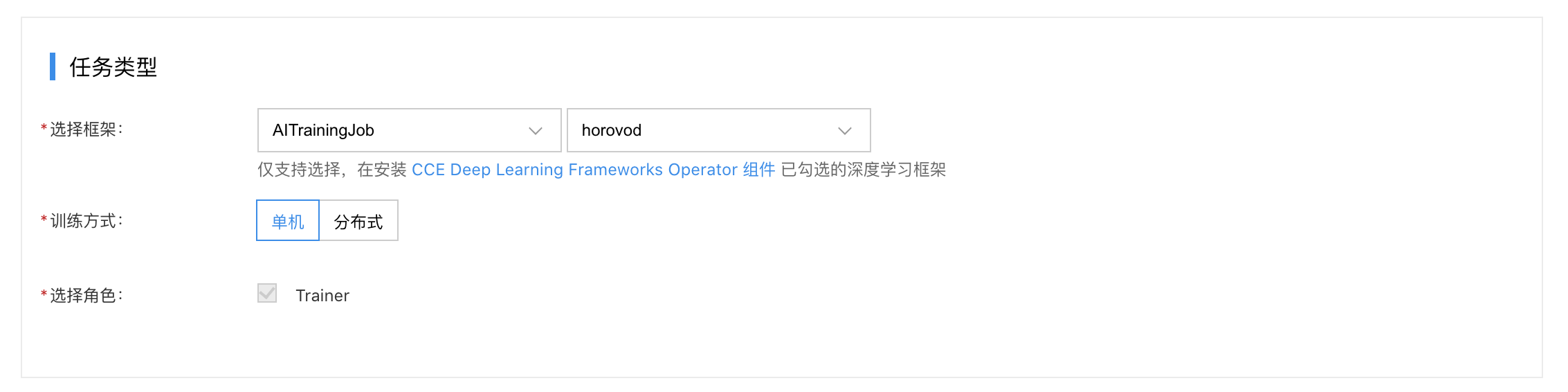
- Select framework: Choose “AITrainingJob”, and specify the training mechanism. Currently, you can select “horovod” or “paddle”.
- Training method: Select either Single-Machine or Distributed training.
- Select role: For the "Single-machine" training method, only the "Trainer" role is available. For the "Distributed" method, both "Launcher" and "Trainer" roles are available, and the elastic range of pods must be defined.
- Configure pod information (advanced settings are optional).
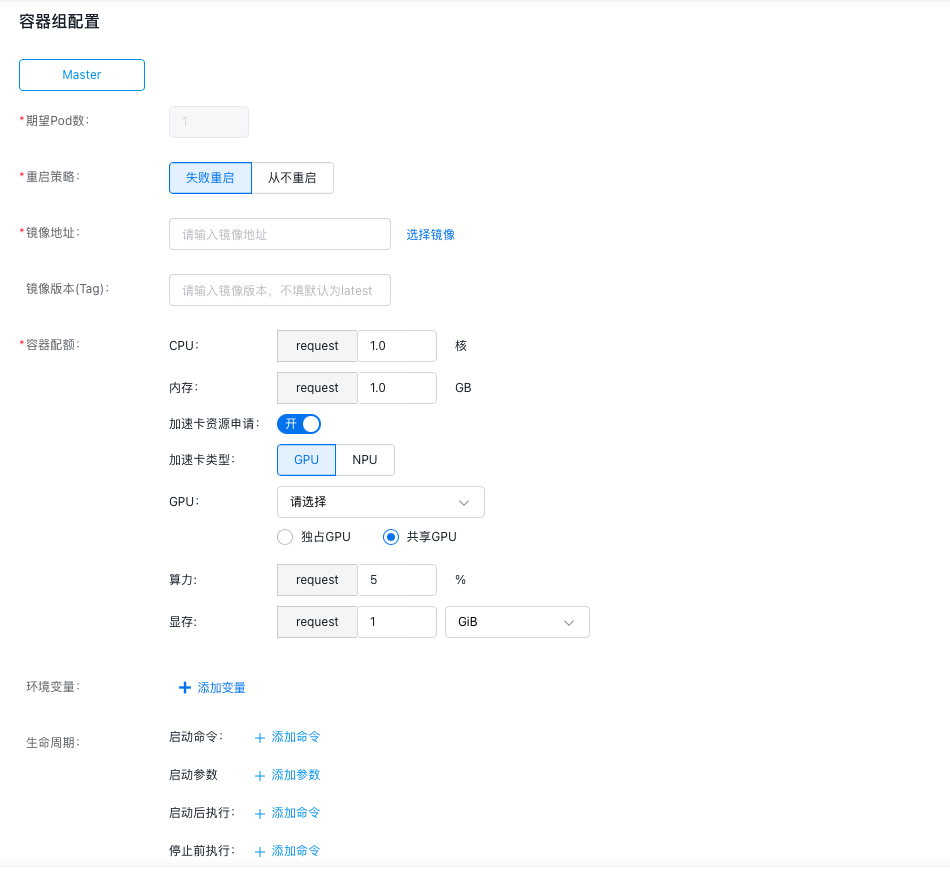
- Specify the number of pods desired in the pod.
- Define the restart policy for the pod. Options: “Restart on Failure” or “Never Restart”.
- Provide the address for pulling the container image. Alternatively, click Select Image to choose the desired image.
- Enter the image version. If left unspecified, the latest version will be used by default.
- Set the CPU, memory, and GPU resource requirements for the container.
- Configure the advanced task settings.
- Set the maximum allowable training duration (leave blank for unlimited duration).
- Add credentials to access the private image registry if using a private image.
- Tensorboard: If task visualization is required, the Tensorboard function can be enabled. After enabling, you need to specify the “Service Type” and “ Training Log Reading Path”.
- Assign K8s labels to the task.
- Provide annotations for the task.
- Click the Finish button to finalize task creation.
Example of creating a task with YAML
Plain Text
1apiVersion: kongming.cce.baiudbce.com/v1
2kind: AITrainingJob
3metadata:
4 name: job-horovod-test
5 namespace: default
6spec:
7# Cleanup policy for pods when the task ends. “All” means all pods, “none” means no cleanup
8 cleanPodPolicy: All
9# Completion policy. “All” means the task is completed when all pods are completed, “Any” means the task is completed when any pod is completed
10 completePolicy: Any
11# Failure policy. “All” means the task failed when all pods failed, “Any” means the task is completed when any pod is completed
12 failPolicy: Any
13# Support horovod and paddle frameworks
14 frameworkType: horovod
15# Elastic option. “true” means enabling elasticity, “false” means not enabling. When enabling, the fault tolerance option of the trainer container needs to be enabled
16 faultTolerant: true
17 plugin:
18 ssh:
19 - ""
20 discovery:
21 - ""
22 priority: normal
23 replicaSpecs:
24 launcher:
25 completePolicy: Any
26 failPolicy: Any
27 maxReplicas: 1
28 minReplicas: 1
29 replicaType: master
30 replicas: 1
31 restartLimit: 100
32 restartPolicy: OnNodeFailWithExitCode
33 restartTimeLimit: 60
34 restartTimeout: 864000
35 template:
36 metadata:
37 creationTimestamp: null
38 spec:
39 initContainers:
40 - args:
41 - --barrier_roles=trainer
42 - --incluster
43 - --name=$(TRAININGJOB_NAME)
44 - --namespace=$(TRAININGJOB_NAMESPACE)
45 image: registry.baidubce.com/cce-plugin-dev/jobbarrier:v0.9
46 imagePullPolicy: IfNotPresent
47 name: job-barrier
48 resources:
49 limits:
50 cpu: "1"
51 memory: 1Gi
52 requests:
53 cpu: "1"
54 memory: 1Gi
55 restartPolicy: Never
56 schedulerName: volcano
57 terminationMessagePath: /dev/termination-log
58 terminationMessagePolicy: File
59 securityContext: {}
60 containers:
61 - command:
62 - /bin/bash
63 - -c
64 - horovodrun -np 3 --min-np=1 --max-np=5 --verbose --log-level=DEBUG --host-discovery-script /etc/edl/discover_hosts.sh python /horovod/examples/elastic/pytorch/pytorch_synthetic_benchmark_elastic.py
65 env:
66 image: registry.baidubce.com/cce-plugin-dev/horovod:v0.1.0
67 imagePullPolicy: Always
68 name: aitj-0
69 resources:
70 securityContext:
71 capabilities:
72 add:
73 - SYS_ADMIN
74 volumeMounts:
75 - mountPath: /dev/shm
76 name: cache-volume
77 dnsPolicy: ClusterFirstWithHostNet
78 terminationGracePeriodSeconds: 30
79 volumes:
80 - emptyDir:
81 medium: Memory
82 sizeLimit: 1449Gi
83 name: cache-volume
84 trainer:
85 completePolicy: None
86 failPolicy: None
87# Fault tolerance configuration. The controller will use the following configuration as the fault tolerance judgment condition for fault tolerance
88 faultTolerantPolicy:
89# Program exit code
90 - exitCodes: 129,10001,127,137,143,129
91 restartPolicy: ExitCode
92 restartScope: Pod
93# Cluster exception events
94 - exceptionalEvent: "nodeNotReady,PodForceDeleted"
95 restartPolicy: OnNodeFail
96 restartScope: Pod
97# Maximum number of replicas when elasticity is enabled
98 maxReplicas: 5
99# Minimum number of replicas when elasticity is enabled
100 minReplicas: 1
101 replicaType: worker
102 replicas: 3
103 restartLimit: 100
104 restartPolicy: OnNodeFailWithExitCode
105 restartTimeLimit: 60
106 restartTimeout: 864000
107 template:
108 metadata:
109 creationTimestamp: null
110 spec:
111 containers:
112 - command:
113 - /bin/bash
114 - -c
115 - /usr/sbin/sshd && sleep 40000
116 image: registry.baidubce.com/cce-plugin-dev/horovod:v0.1.0
117 imagePullPolicy: Always
118 name: aitj-0
119 resources:
120# Limit and request must be consistent
121 limits:
122 baidu/gpu_p40_8: "1"
123 requests:
124 baidu/gpu_p40_8: "1"
125 securityContext:
126 capabilities:
127 add:
128 - SYS_ADMIN
129 volumeMounts:
130 - mountPath: /dev/shm
131 name: cache-volume
132 dnsPolicy: ClusterFirstWithHostNet
133 terminationGracePeriodSeconds: 300
134 volumes:
135 - emptyDir:
136 medium: Memory
137 sizeLimit: 1449Gi
138 name: cache-volume
139 schedulerName: volcano