
Creating VPC-ENI Mode Cluster
VPC-ENI mode description
VPC-ENI mode is an advanced network mode supported by the Cloud Container Engine (CCE). This mode utilizes the elastic network interface product of Baidu AI Cloud to assign VPC IP addresses to pods in the cluster. The Virtual Private Cloud (VPC) enables routing and connectivity for the container network, ensuring the control plane and data plane of pods and nodes are on the same network level. With this mode, pods can fully leverage all product features of the Baidu AI Cloud VPC.
Once you create a cluster in VPC-ENI mode, it cannot be altered. Plan your network carefully in advance.
Given the limitations of VPC-ENI mode, it's advisable to assess beforehand whether it suits your specific service needs.
VPC-ENI mode application scenarios
Clusters using VPC-ENI mode offer the following advantages:
- Native Virtual Private Cloud (VPC) performance;
- Integrate Virtual Private Cloud (VPC) product features, such as binding a dedicated security group to pods for packet filtering;
VPC-ENI mode instructions for use
- VPC-ENI mode supports nodes distributed across different availability zones and subnets;
- VPC-ENI mode supports elastic network interfaces distributed across different availability zones and subnets, but elastic network interfaces can only be bound to nodes within the same availability zone;
- VPC-ENI mode requires elastic network interfaces and nodes distributed across different subnets;
- VPC-ENI mode dynamically binds multiple elastic network interfaces to each node;
VPC-ENI container scale limitations
In VPC-ENI mode, the maximum count of IPs assignable to containers on each node is determined by the node specifications (CPU core count and memory). Mountable elastic network interface count per node = min (host core count, 8). The corresponding relationship between memory and secondary IP address count per elastic network interface is shown in the table below.
| Node memory | Maximum count of secondary IP addresses per elastic network interface |
|---|---|
| 1G | 1 |
| (1-8]G | 7 |
| (8-32]G | 15 |
| (32-64]G | 29 |
| Greater than 64G | 39 |
Count of IPs assignable to containers on a single node = mountable elastic network interface count * maximum count of secondary IP addresses per elastic network interface
For BBC machines or BBC machines without elastic network interface support, in the secondary IP address mode of the primary network interface card, the minimum IP allocation per network interface card is 1, and the maximum is 39.
For example:
- The specification of Node1 is 4C8G, so the maximum count of IPs that can be allocated to the container on Node1 is 28;
- The specification of Node2 is 12C32G, so the maximum count of IPs that can be allocated to the container on Node2 is 120;
Create a VPC-ENI mode cluster
- Click Create Cluster in the Cloud Container Engine (CCE) console to enter the Cluster Creation page;
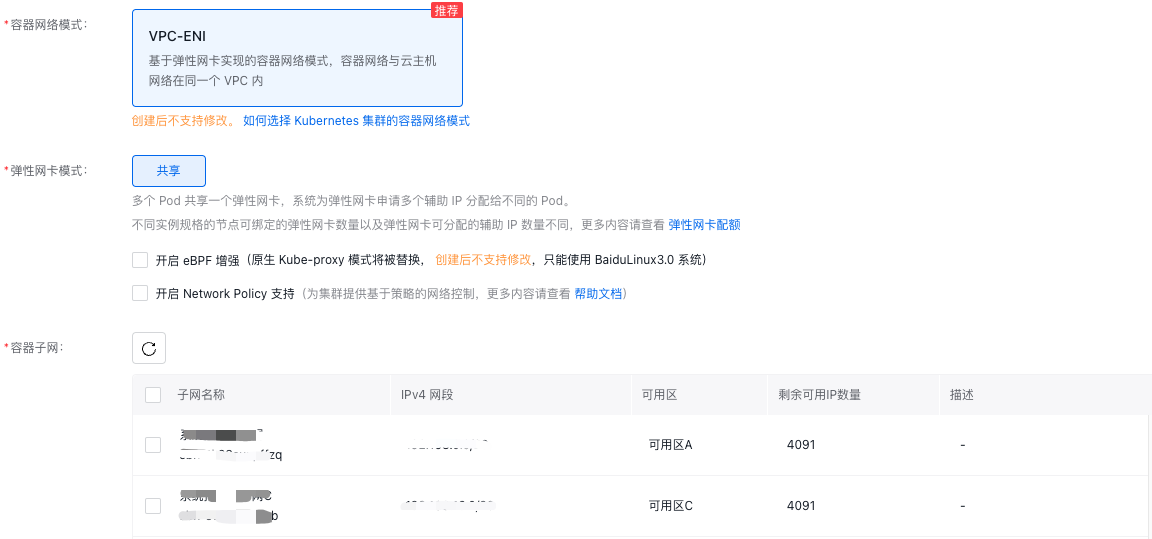
- In the Network Configuration options, set the Container Network Mode configuration to VPC-ENI as shown in the figure below;
-
After configuring the relevant options, click Next to proceed with other cluster configurations.
| ConfigMap | Required/Optional | Configuration |
|---|---|---|
| Elastic network interface mode | Required | Support both exclusive and shared modes. Exclusive: Multiple pods share one elastic network interface, and the system applies for multiple secondary IPs for the elastic network interface to allocate to different pods. Shared: Each pod exclusively occupies one elastic network interface, and the system applies for one secondary IP for the elastic network interface to allocate to the pod. The exclusive elastic network interface mode is currently available only to the allow-list users. To use it, submit a ticket. |
| Container subnet | Required | Assign a subnet within the Virtual Private Cloud (VPC) as the container subnet. Pods created by the cluster will obtain IP addresses from this subnet. Ensure the selected subnet is in the same availability zone as the node you selected for the container subnet. |
| ClusterIP network segment | Required | Define a dedicated network address range for allocating IP addresses to services within the cluster. This network segment must not overlap with the VPC or any segments utilized by existing clusters in the VPC, nor should the service address range overlap with the container address range. |
| LB Service subnet | Required | Choose the default subnet for creating load balancer-type services and ingress. Note that NAT subnets cannot be selected. |
| Elastic network interface security group | Required | Specify the security group bound to the elastic network interface, supporting automatic creation or selection of existing regular security groups and enterprise security groups. For more information, refer to CCE Security Group Description. |
| Kube-proxy mode | Required | Support both IPVS and IPTABLES modes. |
| NodePort range | Required | Define the service port range for the cluster. The default is 30000-32767. |
Note:
- The current quota only supports the creation of 500 elastic network interfaces by default for each VPC. If you need to increase the quota, please submit a ticket to CCE;
- Before deleting k8s namespace resources, customers must first delete all pods under that namespace to avoid possible secondary IP address resource leakage;