
CCE GPU Manager Description
Updated at:2025-10-27
Component introduction
A bundle of GPU device plugins, paired with a compatible scheduler, delivers GPU resource scheduling capabilities in complex scenarios. The CCE GPU Manager component supports isolation-optimized mode, facilitating shared use and isolation of computing power and memory.
Component function
- Topology allocation: Enables a GPU topology allocation function. When more than one GPU card is assigned to a Pod, the system automatically chooses the fastest topology connection mode to allocate GPU devices.
- GPU sharing: Provides the option to enable memory sharing for GPU devices on a node and supports allocating GPU cards to multiple Pods based on memory size.
- Memory and computing power isolation: Ensures isolation of memory and computing power when multiple Pods share a single GPU card.
- Fine-grained scheduling: When enabled, you can select specific GPU models during the creation of queues and tasks. When disabled, only quota input is allowed while creating queues and containers, and specific GPU models cannot be selected.
- Encoding/decoding instances: Submit encoding/decoding tasks using the independent encoding/decoding units of GPUs for hardware-based encoding/decoding.
- For detailed component usage instructions, please refer to: GPU Exclusive and Shared Instructions
Application scenarios
Running GPU applications in CCE clusters addresses the issue of resource waste caused by exclusively using entire GPU cards in scenarios like AI training, thereby improving resource utilization and reducing costs.
Limitations
- Only supports Kubernetes clusters of version v1.18 and above.
- Currently, this component depends on the CCE AI Job Scheduler. If required, please install both components together; otherwise, the functions of this component may be unavailable.
- GPU-shared virtualization supports the following mainstream GPU CUDA and Driver versions. The isolation-optimized mode imposes additional requirements on OS kernel versions and others. For adaptation to other versions, please submit a request. The current support details are as follows.
| Configuration | Version |
|---|---|
| Container runtime | Docker、Containerd |
| GPU CUDA/Driver version | |
| OS kernel version (isolation-optimized mode only) | CentOS: Ubuntu: |
Install component
- Sign in to the Baidu AI Cloud Official Website and enter the management console.
- Go to Product Services - Cloud Native - Cloud Container Engine (CCE) to access the CCE management console.
- Click Cluster Management > Cluster List in the left navigation bar.
- Click on the target cluster name in the Cluster List page to navigate to the cluster management page.
- On the Cluster Management page, click O&M & Management > Component Management.
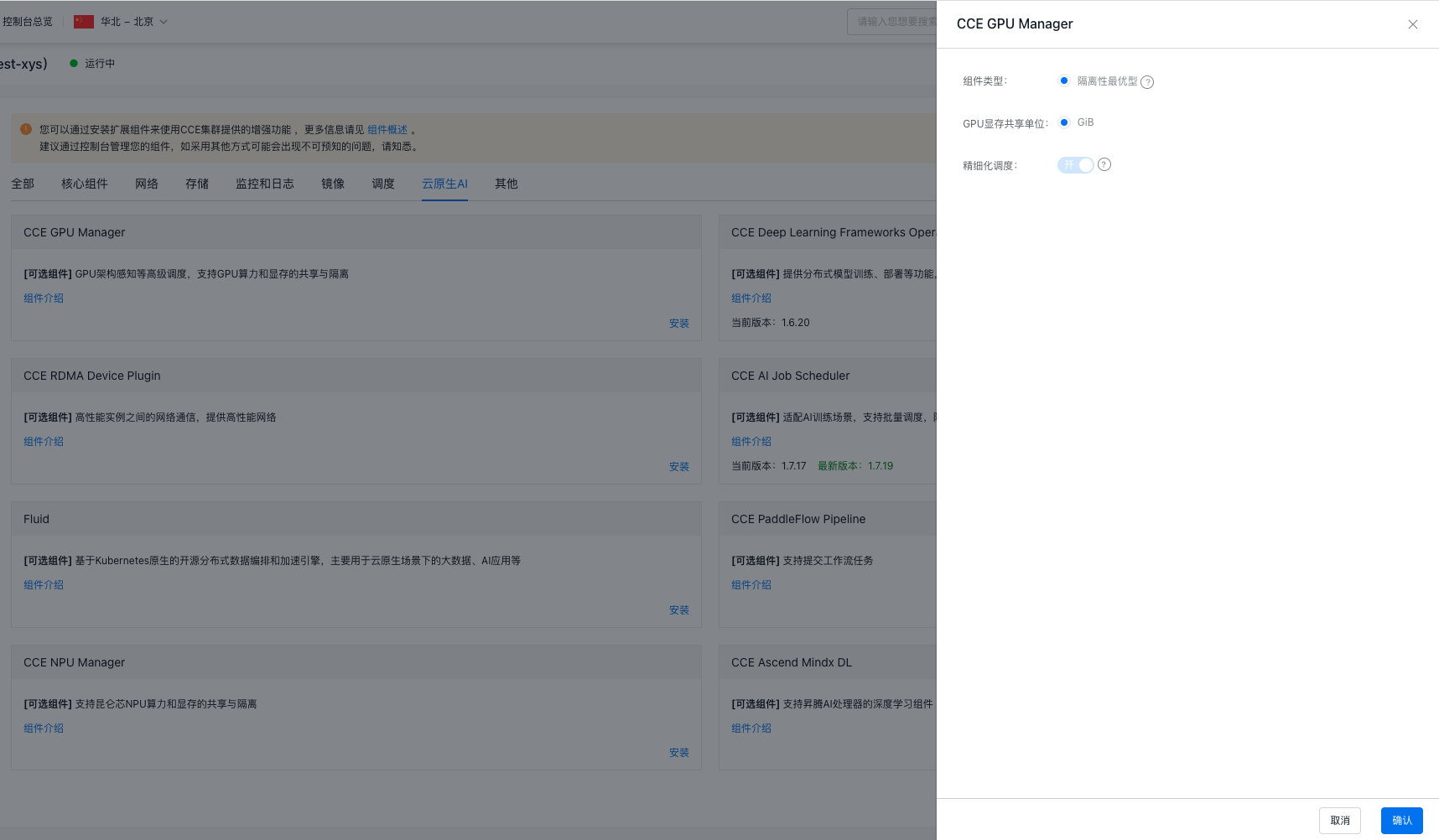
- Select the CCE GPU Manager component from the component management list and click on Install.
- In the installation confirmation dialog box, isolation-optimized mode is selected by default.
- The default unit for GPU memory sharing is GiB.
- Fine-grained scheduling is enabled by default.
- Click the OK button to finalize the component installation.
Version records
| Version No. | Cluster version compatibility | Update time | Change content | Impact |
|---|---|---|---|---|
| 1.5.35 | CCE v1.18+ | 2024.07.05 | New function: Optimize: Bug Fixes: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.34 | CCE v1.18+ | 2024.06.24 | Optimize: Bug Fixes: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.33 | CCE v1.18+ | 2024.05.31 | New function: Optimize: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.32 | CCE v1.18+ | 2024.05.15 | New function: Optimize: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.31 | CCE v1.18+ | 2024.05.06 | New function: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.30 | CCE v1.18+ | 2024.03.26 | New function: Fix: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.29 | CCE v1.18+ | 2024.01.19 | New function: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.28 | CCE v1.18+ | 2023.12.15 | New function: Optimize: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.27 | CCE v1.18+ | 2023.12.1 | Optimize: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.26 | CCE v1.18+ | 2023.11.17 | New function: Optimize: Bug Fixes: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.25 | CCE v1.18+ | 2023.11.03 | New function: Optimize: Add pre-checks for the sgpu.ko kernel on nodes: including verification of residual module versions and deletion/reinstallation of invalid residual modules Bug Fixes: Limit: |
GPU kernel mode virtualization services do not support hotspot upgrades; the upgrade mode is to drain the node upgrade |
| 1.5.24 | CCE v1.18+ | 2023.09.22 | New function Bug Fixes: Usage Limitations: |
|
| 1.5.23 | CCE v1.18+ | 2023.08.29 | Optimize: Usage Limitations: |
|
| 1.5.22 | CCE v1.18+ | 2023.08.10 | Bug fixes Usage Limitations: |