Job Management
Users can create CronJobs from images using forms or manage CronJobs by creating and editing YAML file templates provided by Baidu AI Cloud to control and handle Pods, events, and other elements associated with scheduled tasks.
Introduction to jobs
A job is responsible for batch processing of short-term one-time tasks, which are tasks that are executed only once, to ensure that one or more Pods of the batch processing task are completed. Kubernetes supports the following types of jobs:
- Non-parallel job: Typically, create one Pod until it completes successfully
- Job with fixed completions: Set spec.completions to create multiple Pods, and end running when spec.completions are successful for all Pods
- Parallel job: Set spec.Parallelism without setting spec.completions, and create spec.Parallelism for Pods. The job is considered successful when all Pods have ended and at least one has succeeded
Typical usage scenarios:
Based on the settings of spec.Parallelism and spec.completions, jobs can be divided into the following modes:
| Job type | Usage example | Behavior | completions | Parallelism |
|---|---|---|---|---|
| One-time job | Database migration | Create one Pod until it succeeds | 1 | 1 |
| Job with fixed completions | Pod processing work queues | Create one Pod at a time and run it until completion is successful | 2+ | 1 |
| Parallel job with fixed completions | Multiple Pods process work queues simultaneously | Create multiple Pods in sequence and run them until completion is successful | 2+ | 2+ |
| Parallel job | Multiple Pods process work queues simultaneously | Create one or more Pods until one succeeds | 1 | 2+ |
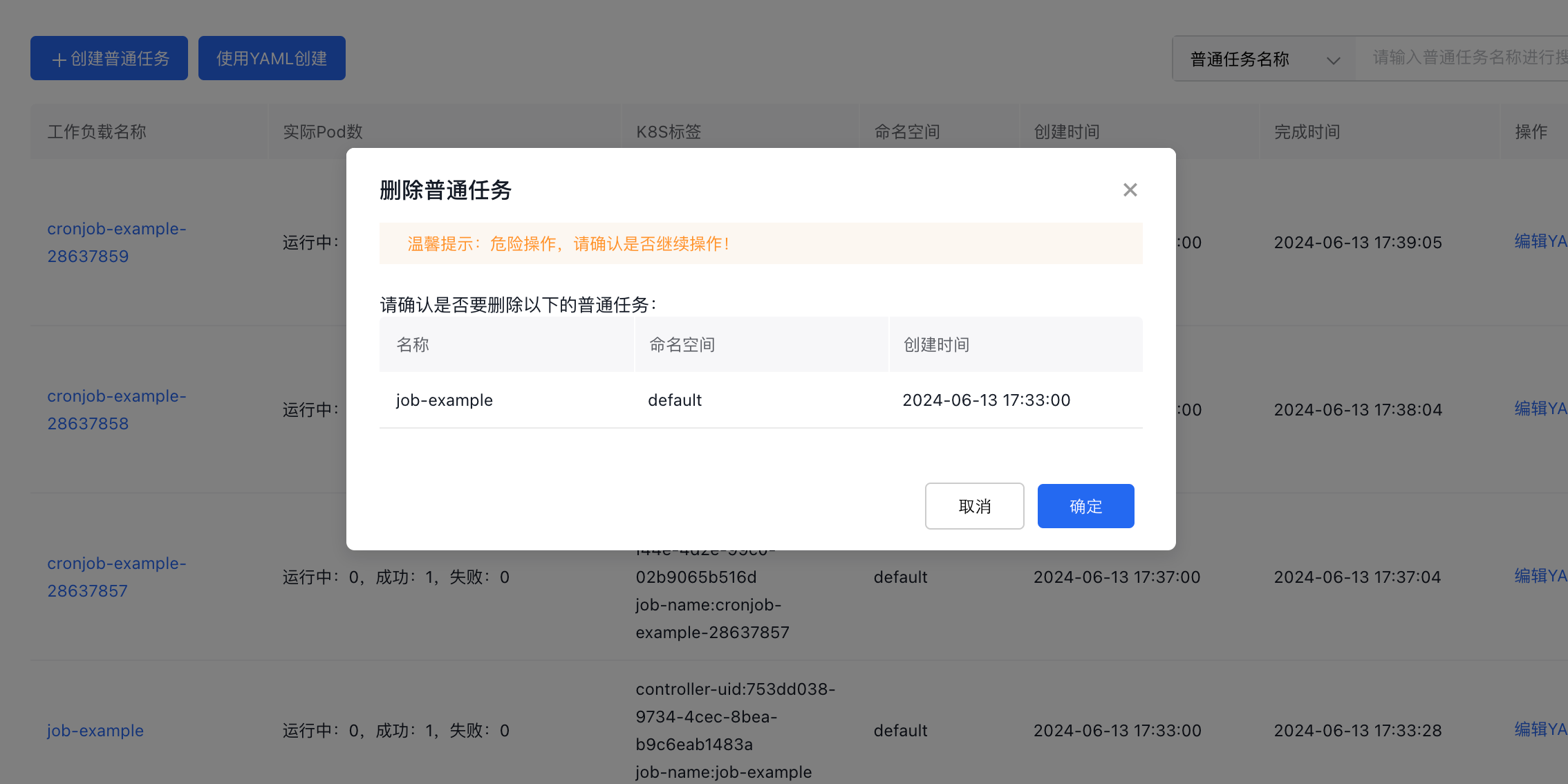
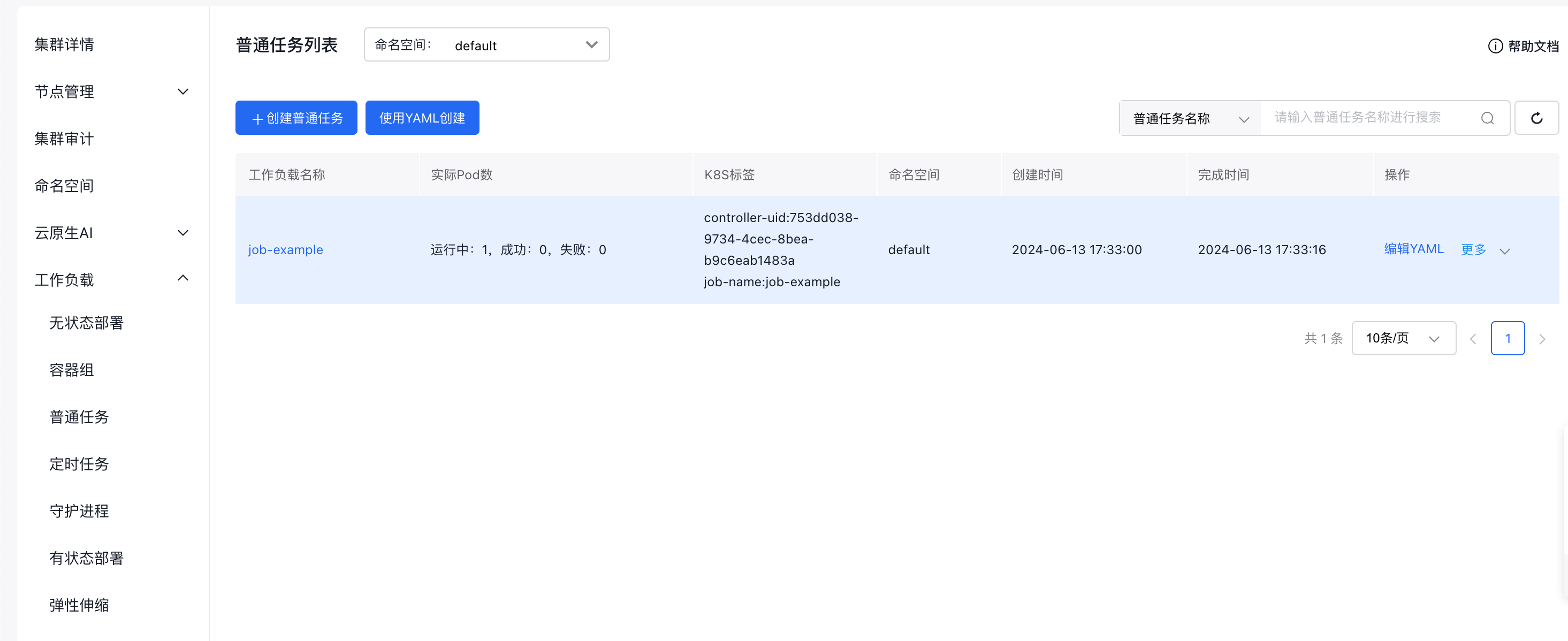
View the list of regular tasks
Navigate to Product Services > Cloud Container Engine (CCE), then go to Workload > Regular Task using the left navigation bar to enter the Regular Tasks page. The contents include:
- List data: Display the list information of all regular tasks with options to create, delete, and modify tasks
Create a regular task
Click Create a Regular Task, where users can choose to create it either via a form or a YAML file.
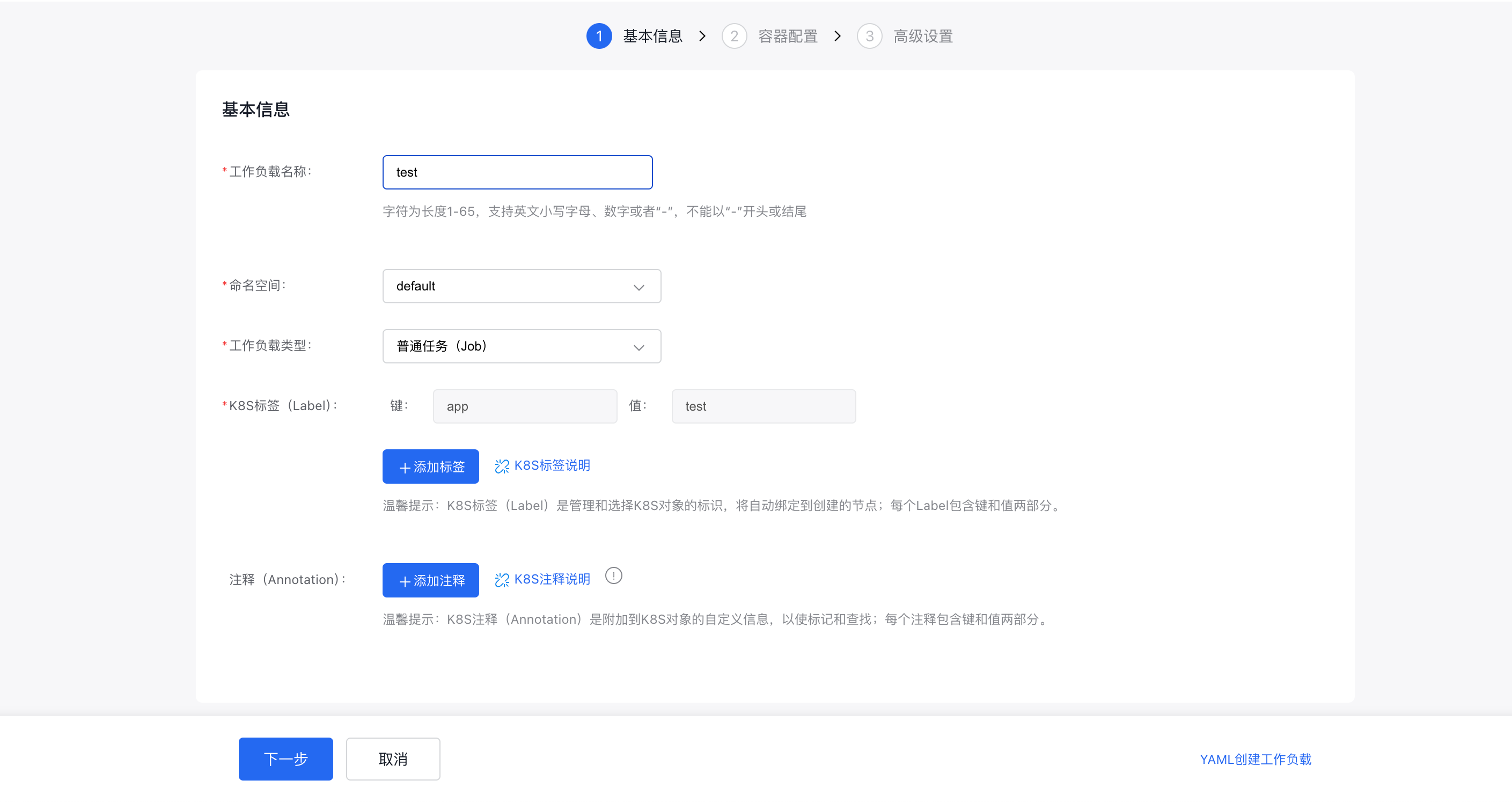
(1) Create via form:
- Fill in the regular task name, namespace and labels;
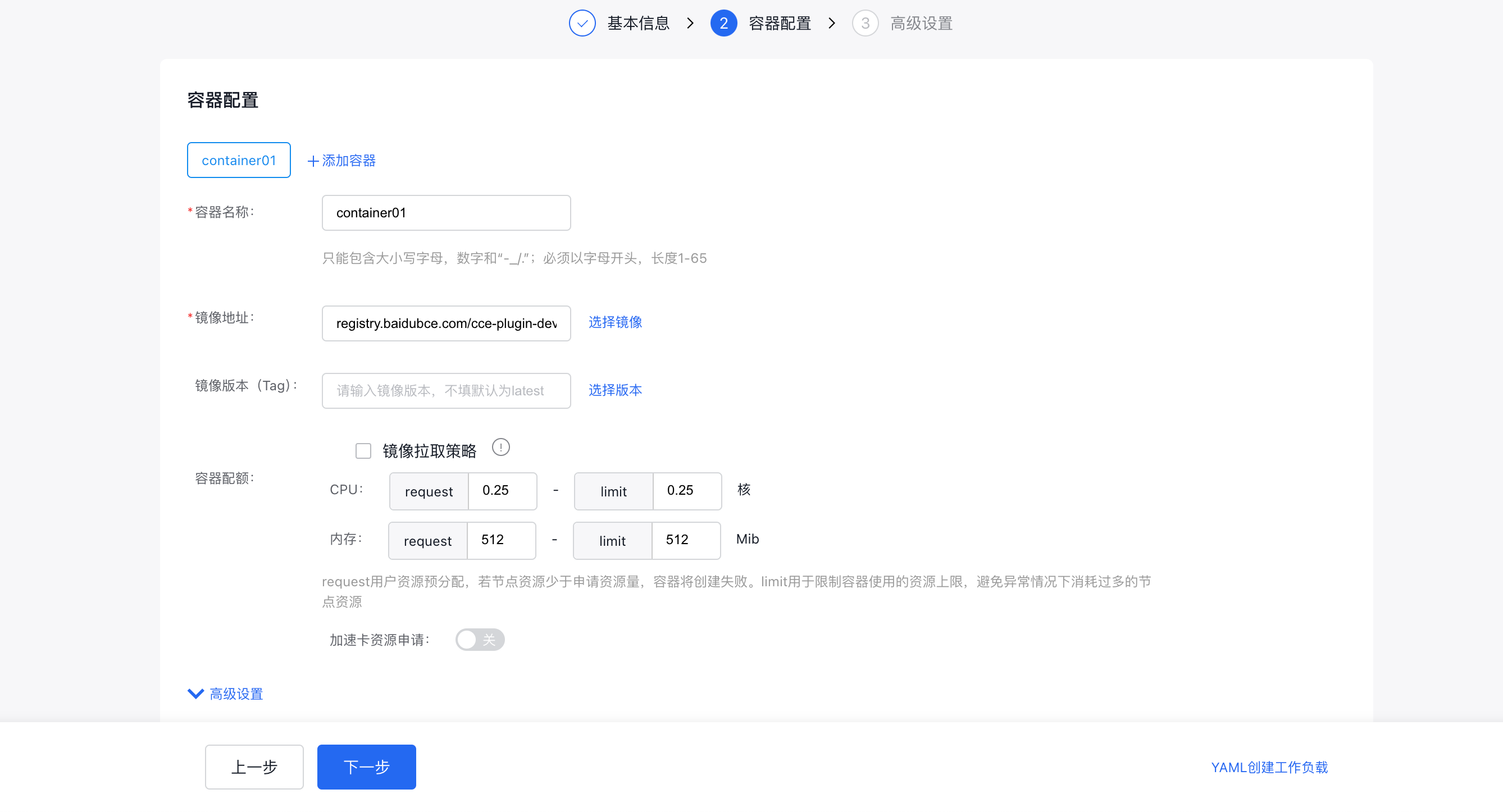
- On the second page (Container Configuration), enter the container name, image address and container configuration information;
- On the Advanced Settings page (third step), configure the task settings and scheduling policies, then finalize the creation process.
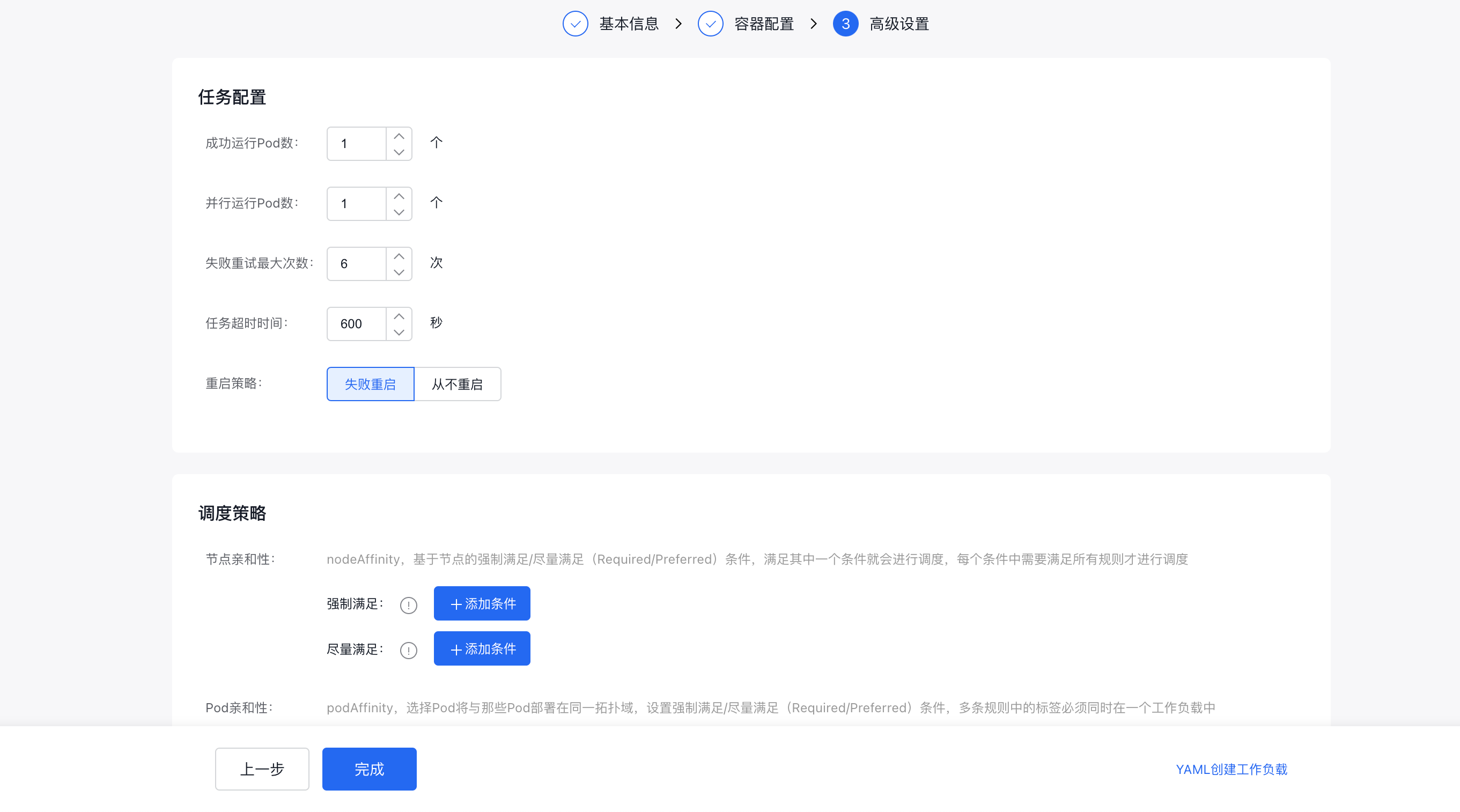
(2) Create via YAML:
- Select a namespace, complete the YAML file, and click OK.
- Template type: Use either the example template or a custom template.
- Replication: Replicate the content of the current YAML file
- Confirm: Create a job
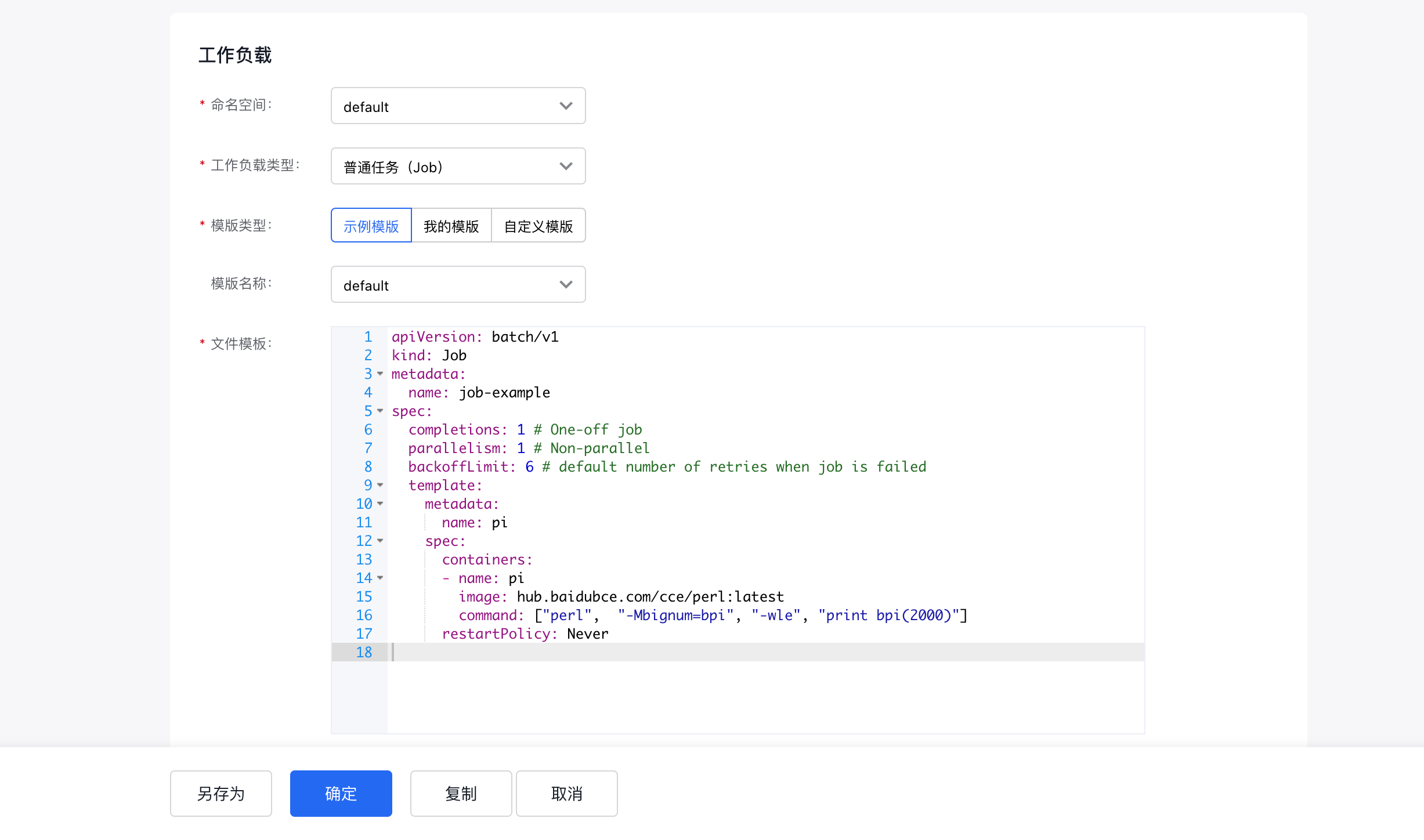
Field explanations
- completions: Indicate the number of Pods that need to run successfully for the Job to end. The default value is 1
- parallelism: Indicate the number of Pods running in parallel. The default value is 1
- backoffLimit: Indicate the number of retries when the Job fails. Default to 6
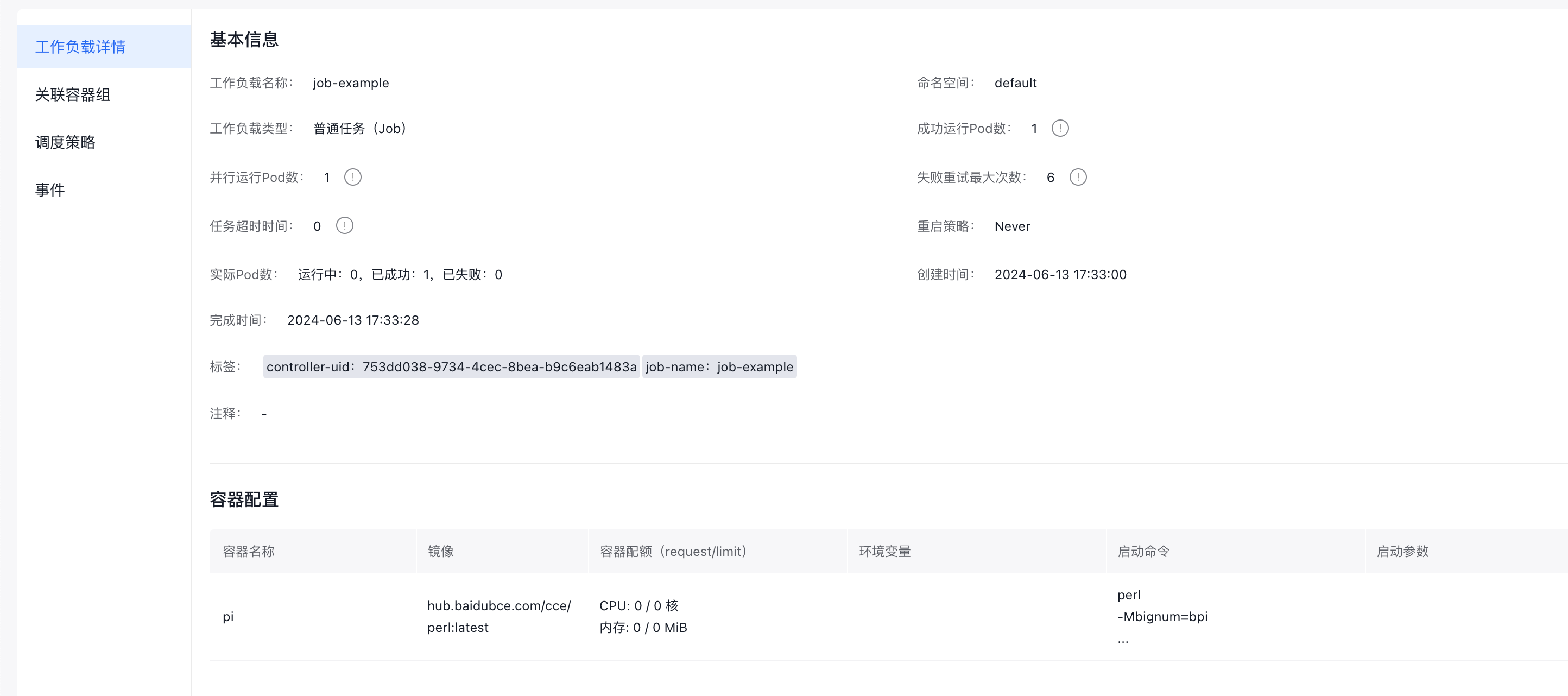
View regular task details
Click the name of any regular task in the list to enter its details page, which includes:
- workload details, associated Pods, scheduling policies and events
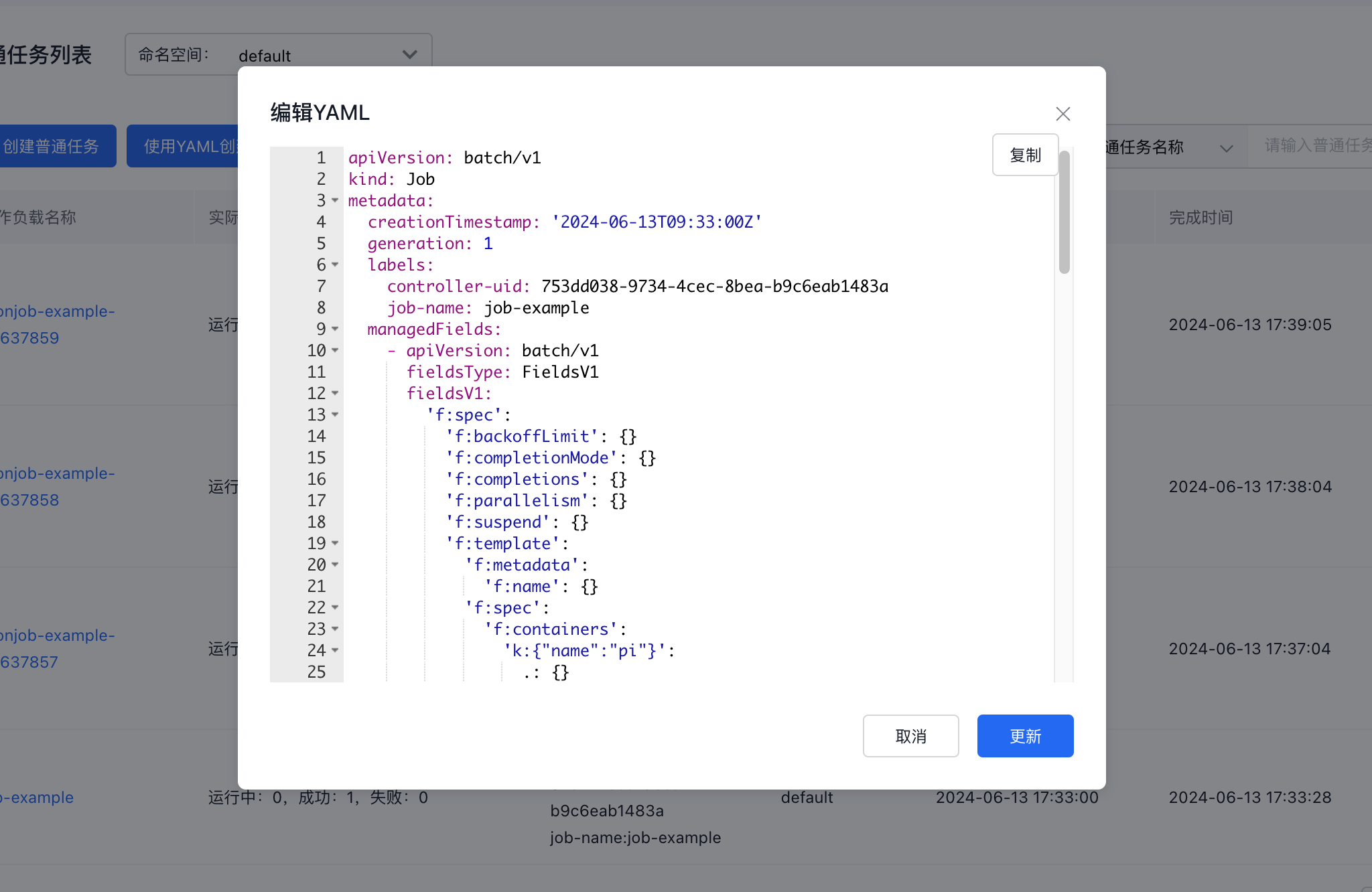
Modify a regular task
On the Regular Task list page, select the Edit YAML button for the task you want to modify. After making the necessary edits, click Update to save the changes.
Delete the regular task
On the Regular Task List page, choose the regular task you want to delete, click the More button, select Delete, confirm the details, and click OK.