CronJob Management
Users can create CornJobs through forms based on images or create and modify CornJobs using YAML file templates provided by Baidu AI Cloud to manage Pods, events, and related tasks.
Introduction to CronJob
CronJob is similar to CronTab in Linux systems, running specified jobs at specified time period, specifically:
- Running once at a given time point
- Running periodically at a given time point
Typical usage scenarios:
- Schedule the job to run at a given time point (e.g., clearing log files after 5 min)
- Create periodically running Jobs (e.g., performing database backups every 1 h)
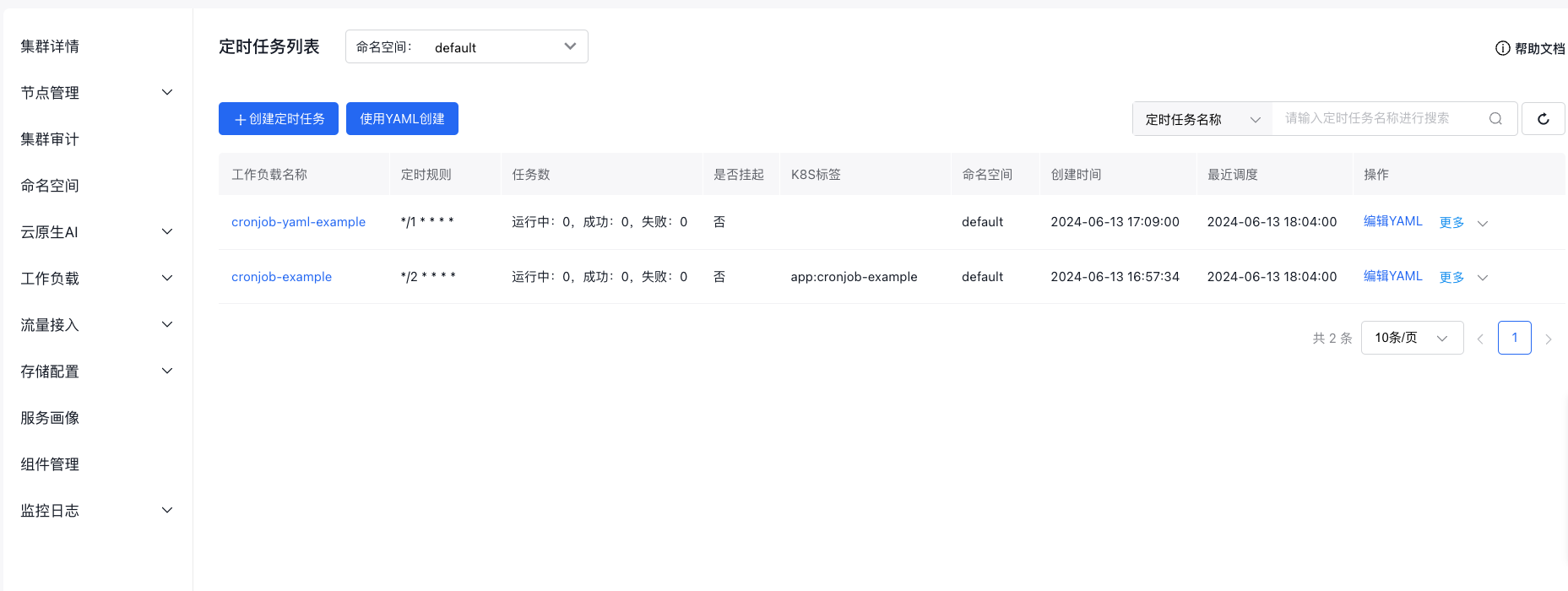
View the CornJob list
Navigate to Product Services > Cloud Container Engine CCE, select a cluster, and click Workload > CornJob to enter the CornJob page. By default, select the latest CCE cluster; then select the "default" namespace under the cluster to load all CornJobs in that namespace. The content includes:
- List data: Display the list information of all CornJobs with options to create, delete and modify tasks
Create CornJob
Users have the option to create CornJobs via forms or YAML files.
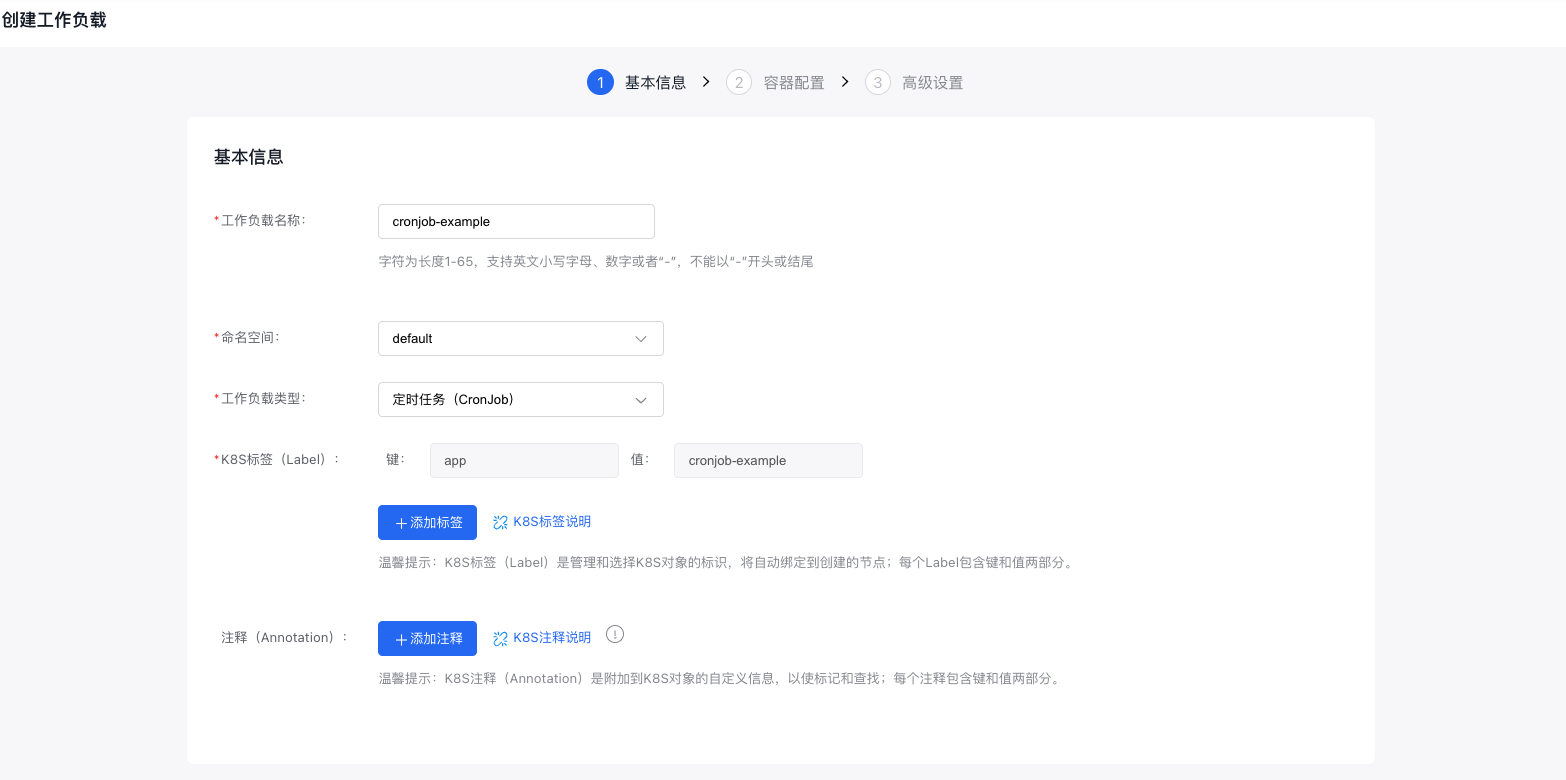
(1) Create via form:
- Click "+ Create CornJob";
- Basic information: Fill in the workload name, select the namespace and workload type, and add K8S labels and annotations as needed;
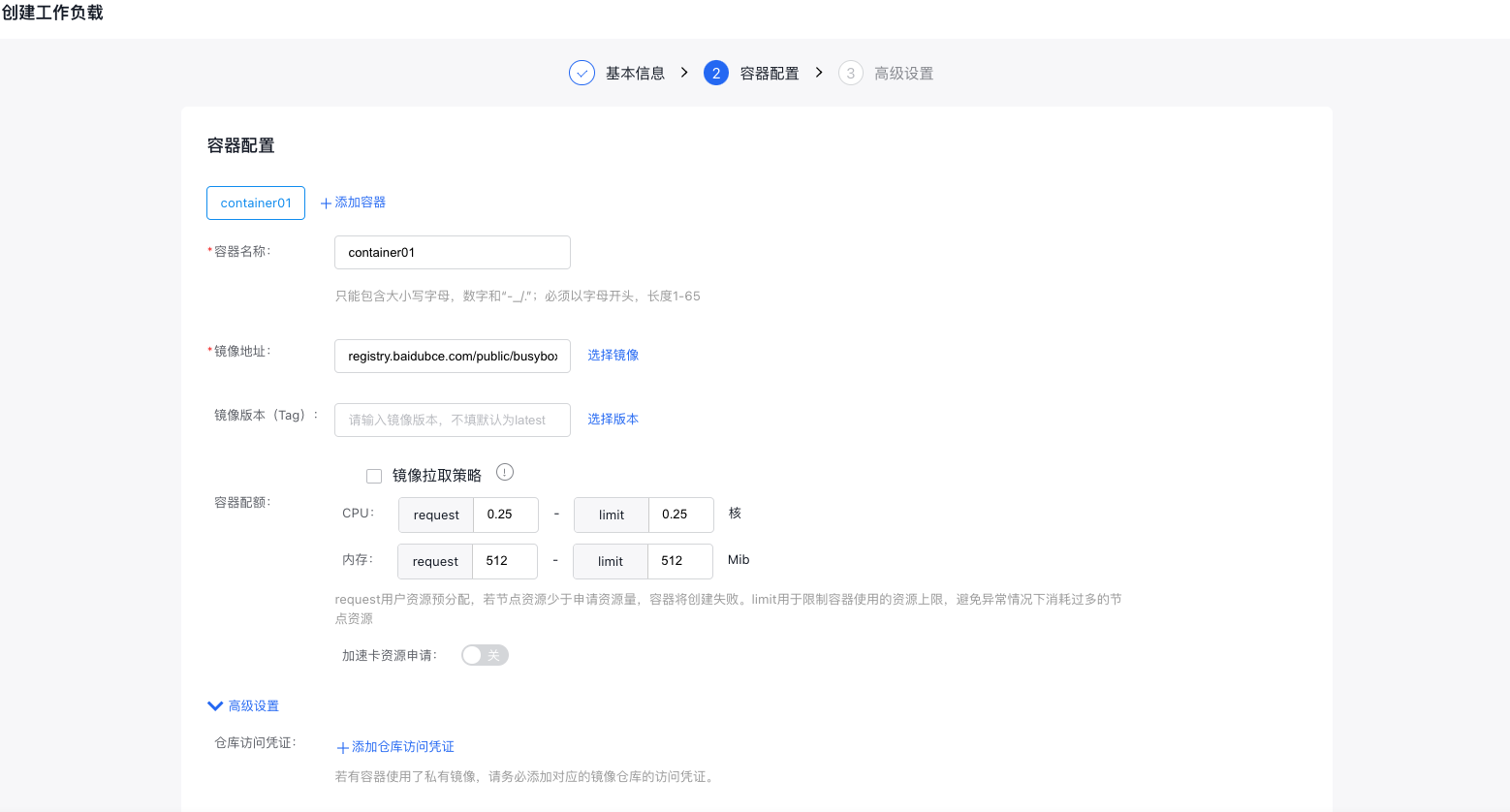
- Container configuration: Enter the container name, select the image address and version, and adjust container quotas; to apply for acceleration card resources, click the Acceleration Card Resource Application Switch and configure it; to add container configurations, click +Add Container;
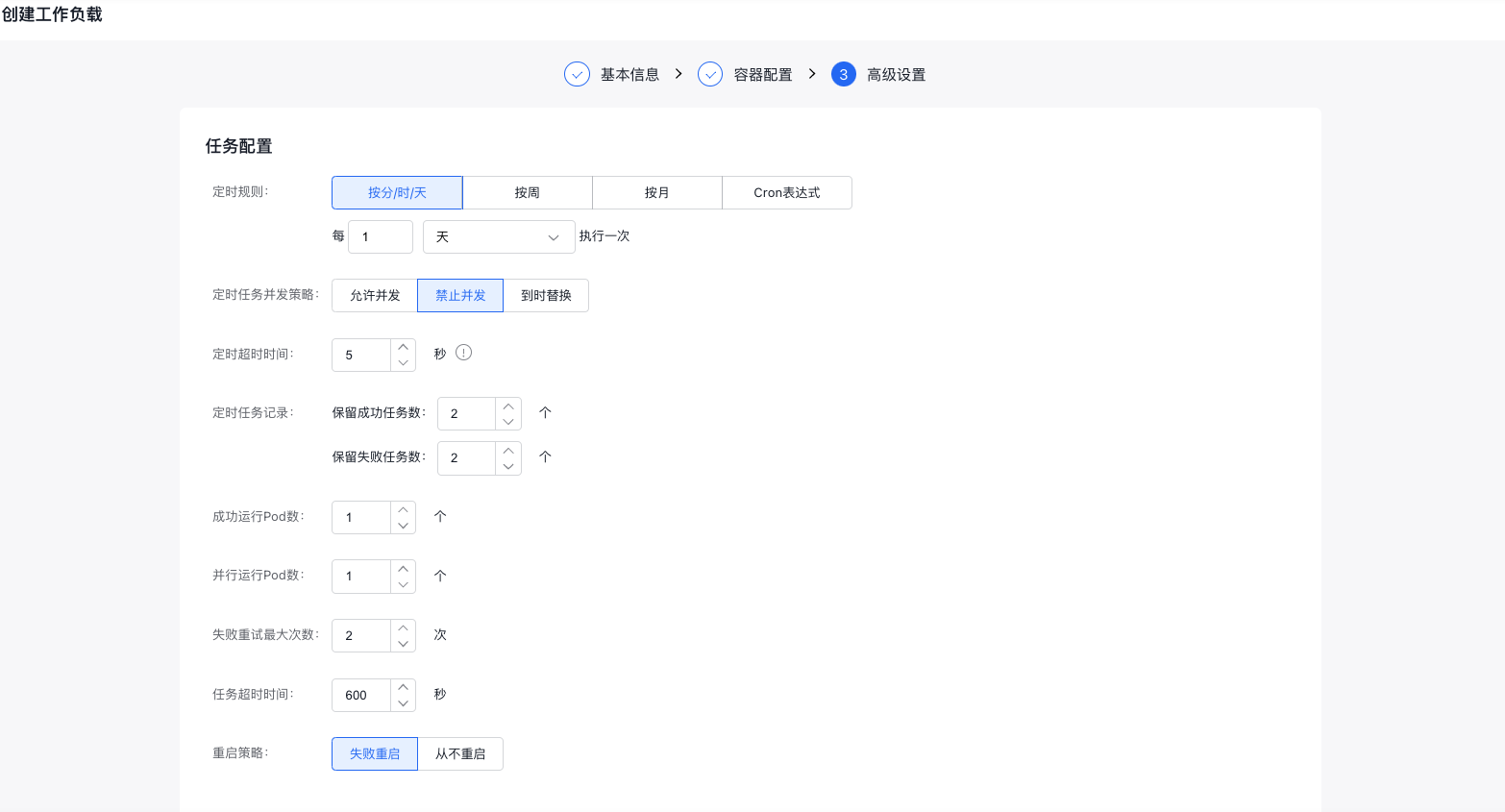
- Advanced settings - task configuration: Configure scheduled rules, CornJob concurrency policies, scheduled timeout duration, maximum retry count, task timeout duration, restart policy, etc.;
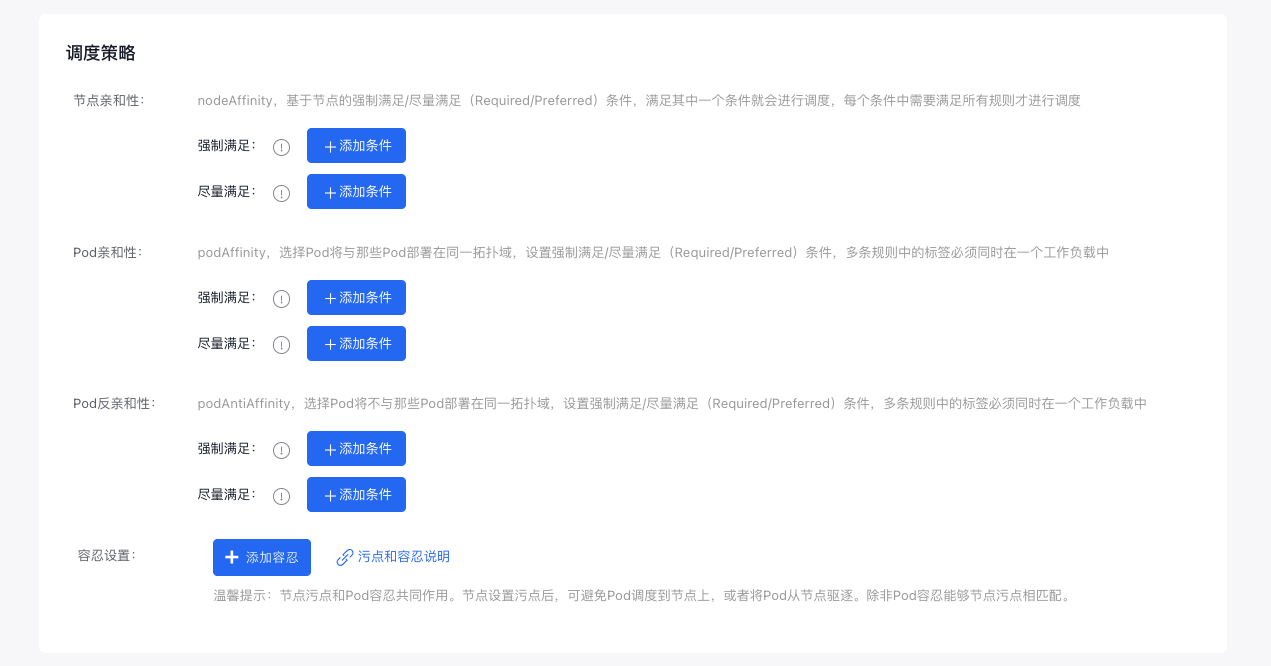
- Advanced settings - scheduling policy: Customize scheduling policies for pods and nodes;
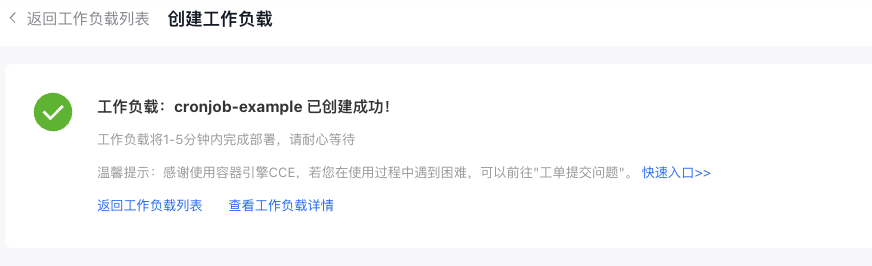
- Click Finish to display a success message confirming that creation is complete.
(2) Create via YAML:
- Select a namespace, complete the YAML file, and click OK.
- Template type: Use either the example template or a custom template.
- Replication: Duplicate the content of the current YAML file.
- Cancel: Return to the list page.
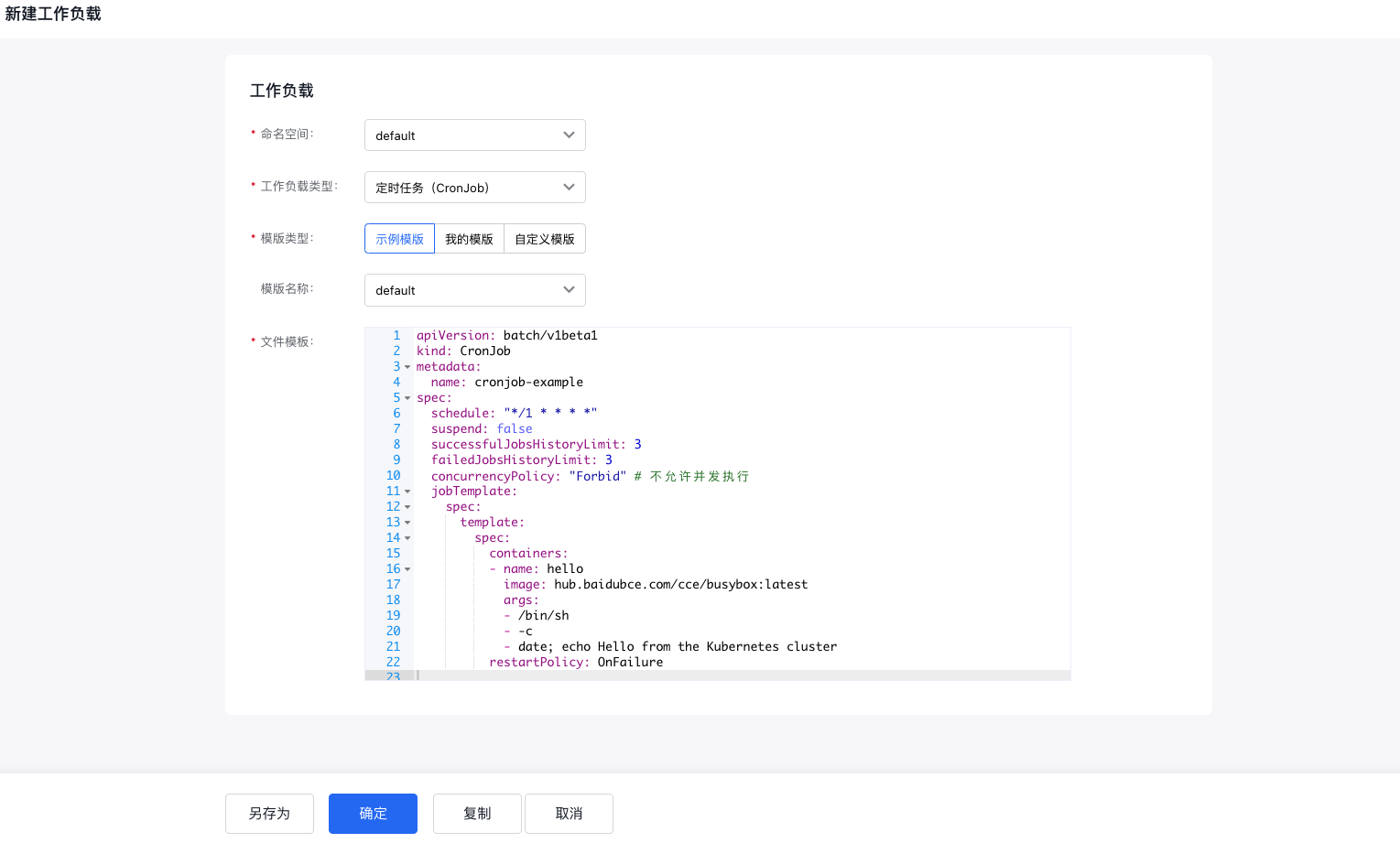
Field explanations
Scheduling:
The spec.schedule field is a required field for cronjob, with a value in Cron format (e.g., 0 * * * * or @hourly). Kubernetes will create and run jobs according to the scheduling time specified in this field
Suspension:
The spec.suspend field is optional, with a default value of false. If set to true, the execution of all subsequent jobs will be suspended
Concurrency policy:
The spec.concurrencyPolicy field is optional, with a default value of Allow. It specifies how jobs created by the CronJob shall run concurrently. Only one of the following policies can be specified:
- Allow: Allow concurrent running of jobs. If the previous job has not been completed, run the current job when it is time to run it
- Forbid: Forbid concurrent running. If the previous one has not been completed and it is time for the current job to run, it will be skipped directly
- Replace: Cancel the currently running job and replace it with a new job
History limit of job
The .spec.successfulJobsHistoryLimit and .spec.failedJobsHistoryLimit fields are optional. They specify limits on the number of completed and failed jobs that can be retained.
By default, there are no limits, and all successful and failed jobs are retained. However, when executing CronJobs, a large number of jobs can quickly accumulate. It is recommended to set values for these two fields. If the limit is set to 0, completed jobs of the specified type will not be retained.
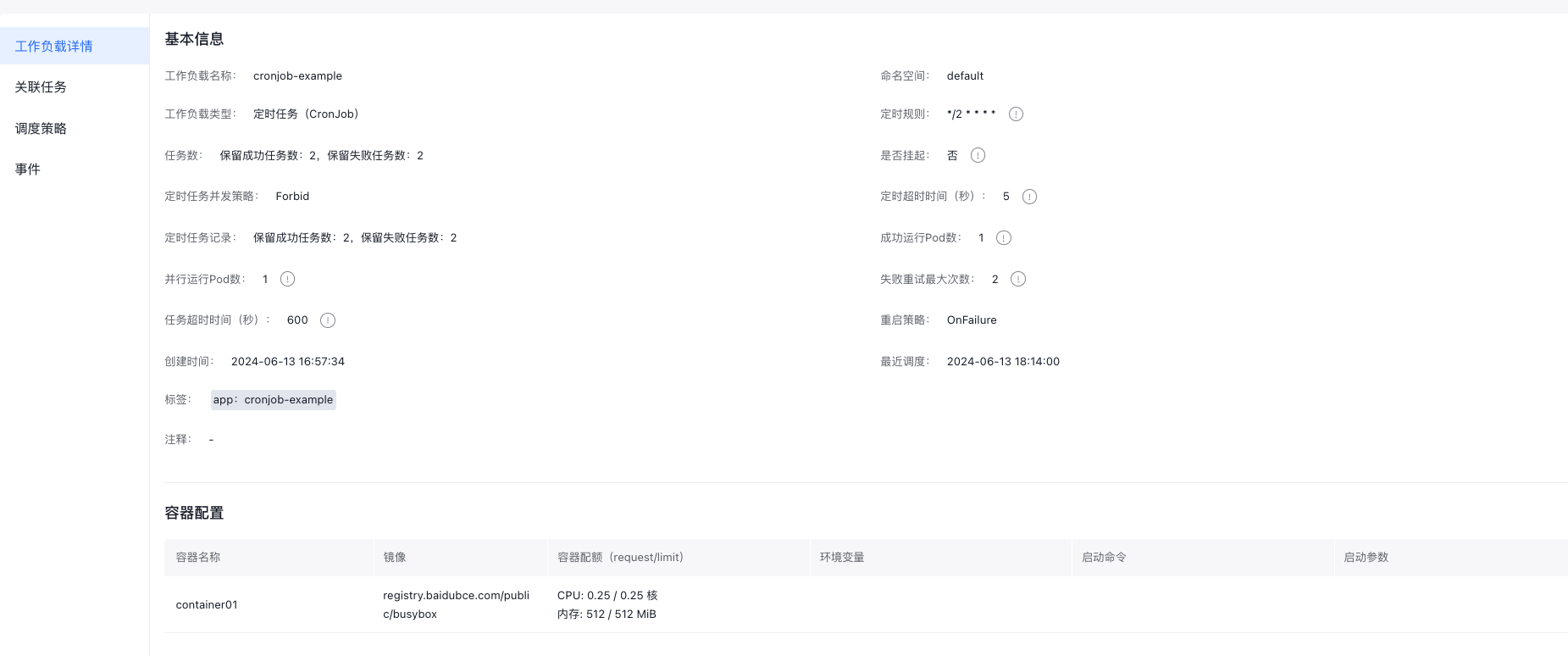
View CornJob details
Click the name of any CornJob in the list to enter its details page, which includes:
- CornJob details: basic information and container configuration
- Associated tasks
- Scheduling policies
- Event
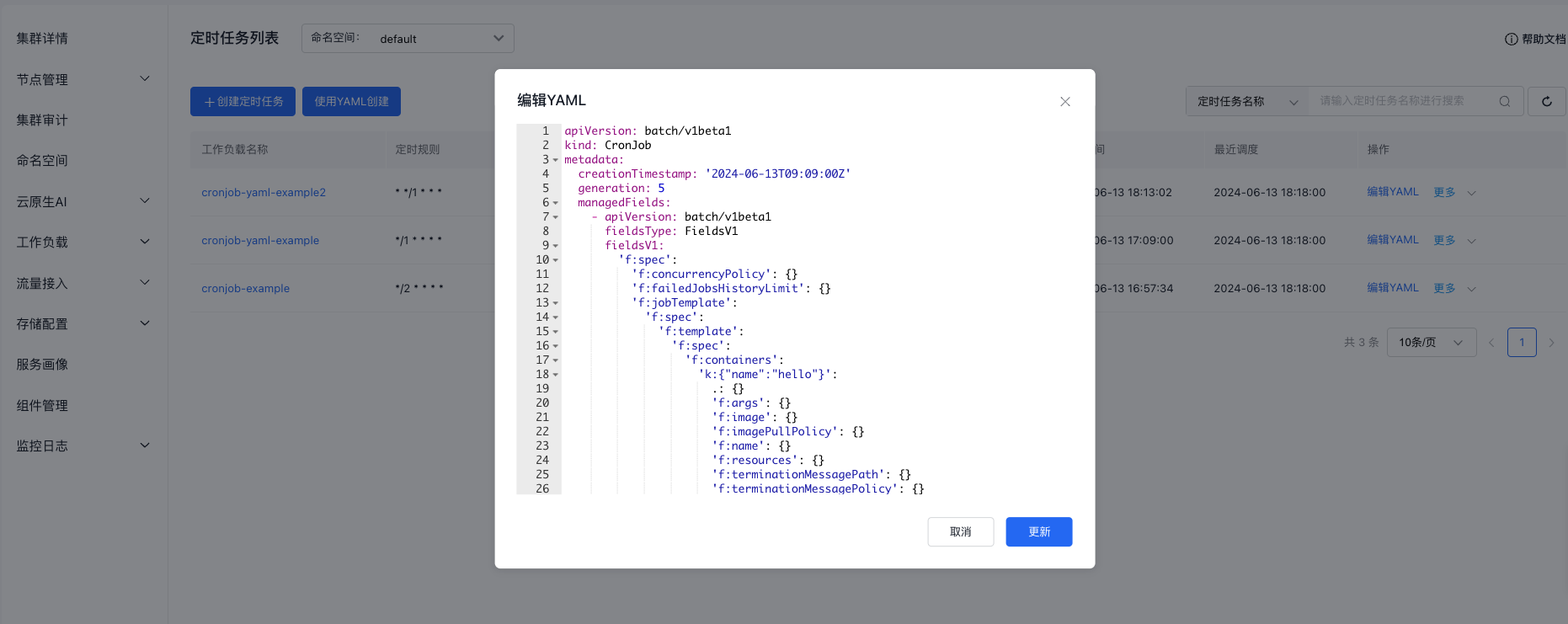
Modify CornJob
On the CornJob List page, locate the CornJob to be modified, and click the Edit YAML button. After making the necessary changes, click Update to save the modifications.
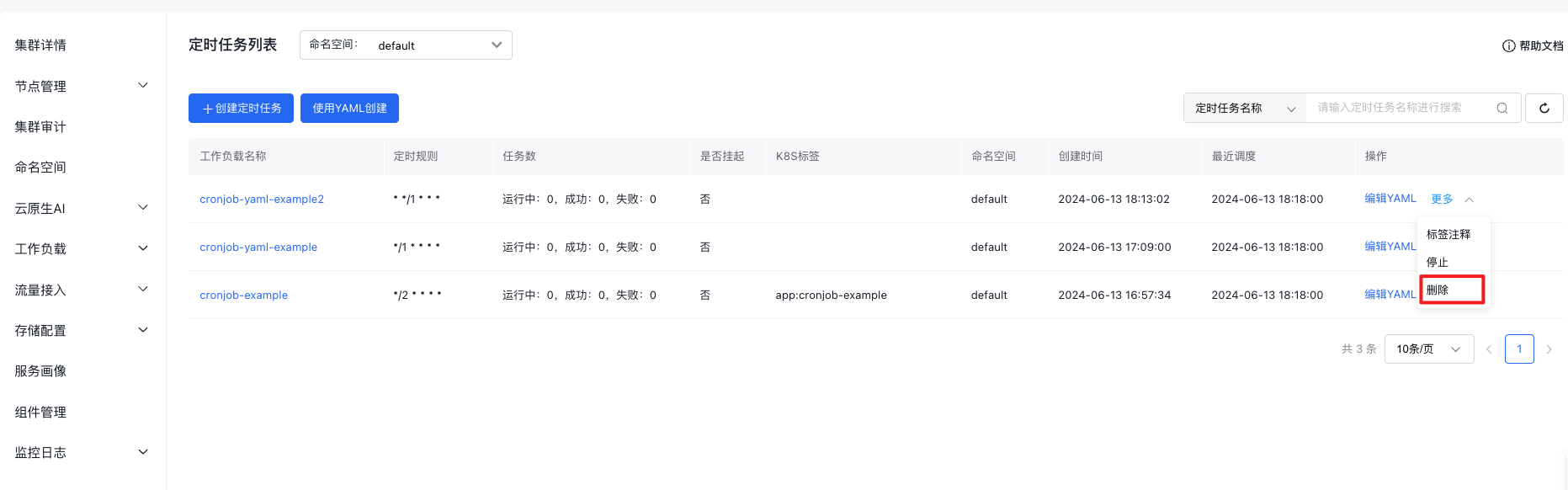
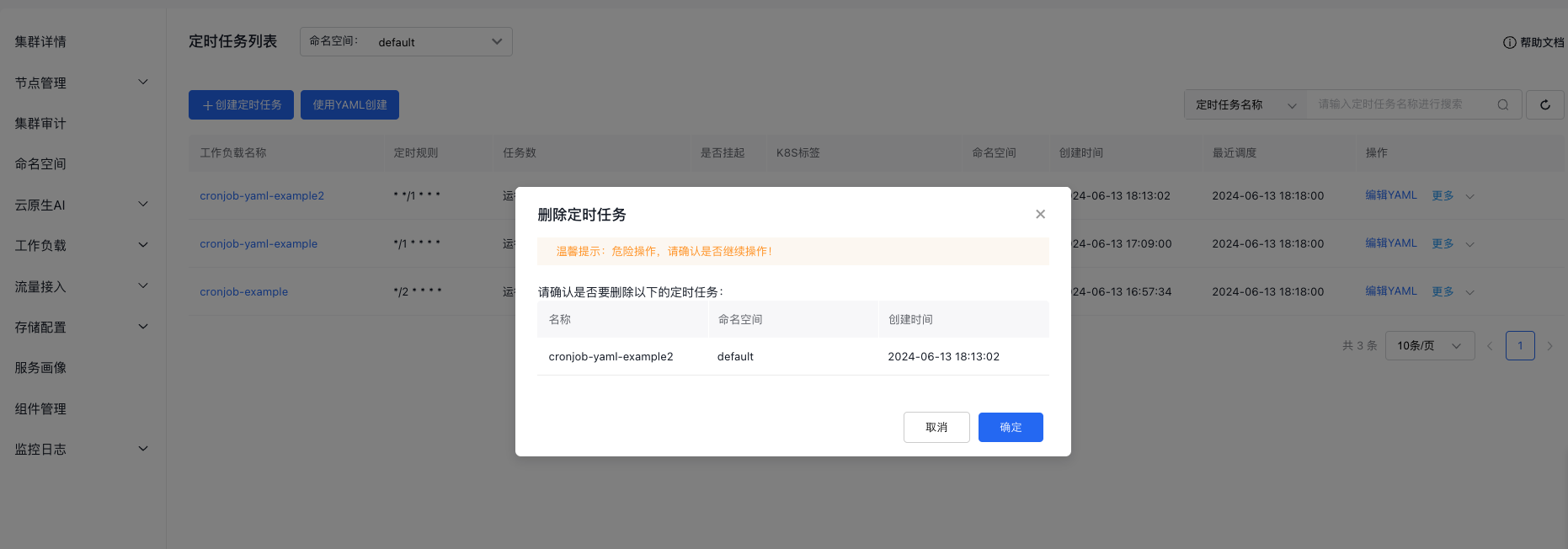
Delete CornJob
On the CornJob List page, find the task to be deleted, click More, then select Delete, confirm the details, and click OK.
Note:Currently, only single deletion is supported.