
Elastic and Fault-Tolerant Training Using CCE AITraining Operator
This document explains how to implement elasticity and fault tolerance for distributed training in CCE using the AI Training Operator and the Horovod training framework.
Model training is a pivotal step in deep learning. Training complex models typically involves long runtimes and substantial computing power. Traditional distributed deep learning tasks do not allow dynamic adjustment of the number of workers during runtime once a task is submitted. Elastic model training enables dynamic modification of the number of workers for deep learning training tasks. Additionally, fault tolerance ensures that in scenarios such as pod eviction due to node failures, the system will reassign a new node to an affected worker, allowing the task to continue without disruption due to a single worker's failure.
Environment requirements
- Install the AI Training Operator component in the CCE environment.
- Leverage Horovod/PaddlePaddle as the distributed training framework.
Component installation
- Install the AI Training Operator component via the CCE console.
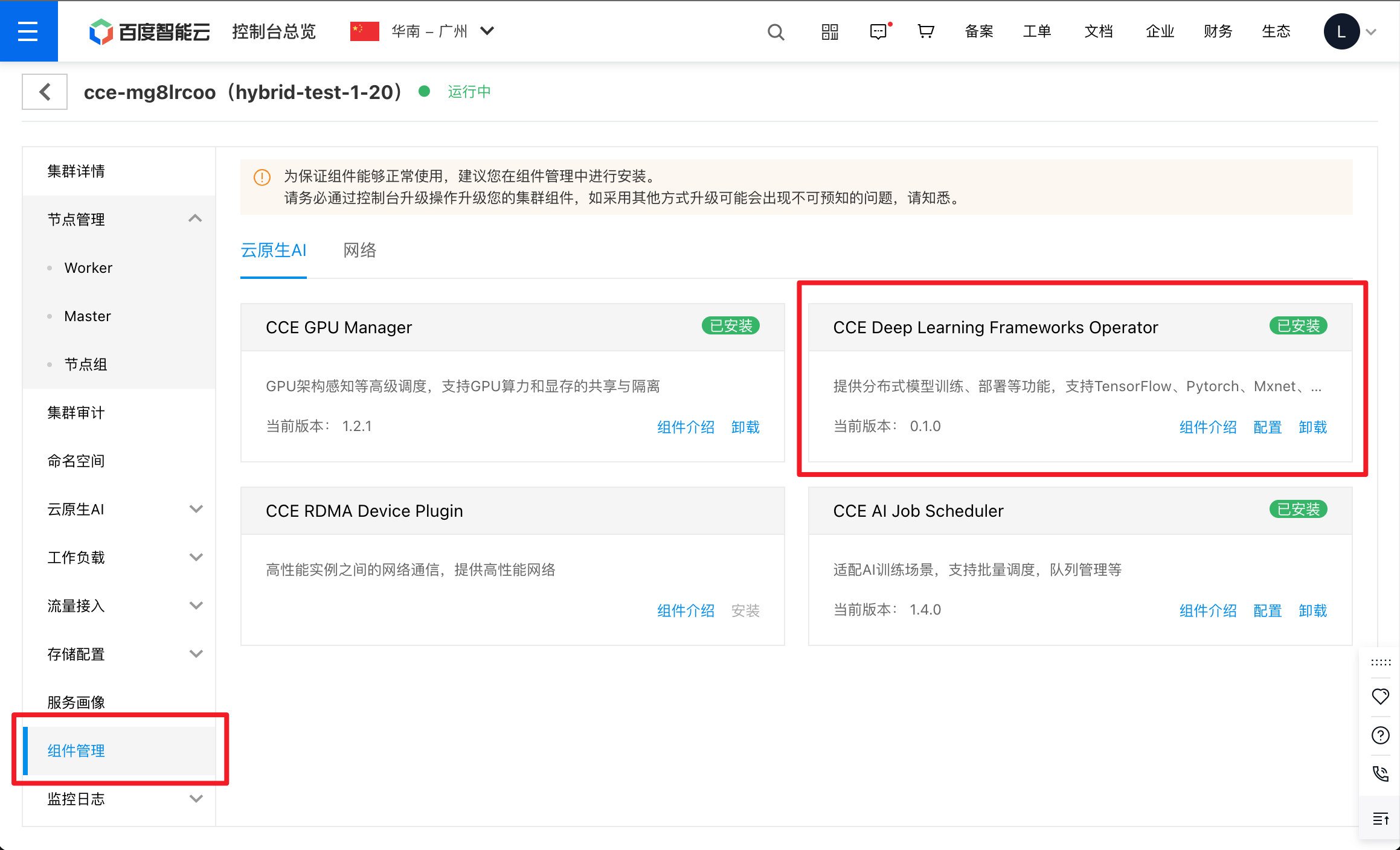
- Verify the installation by checking CCE Training.
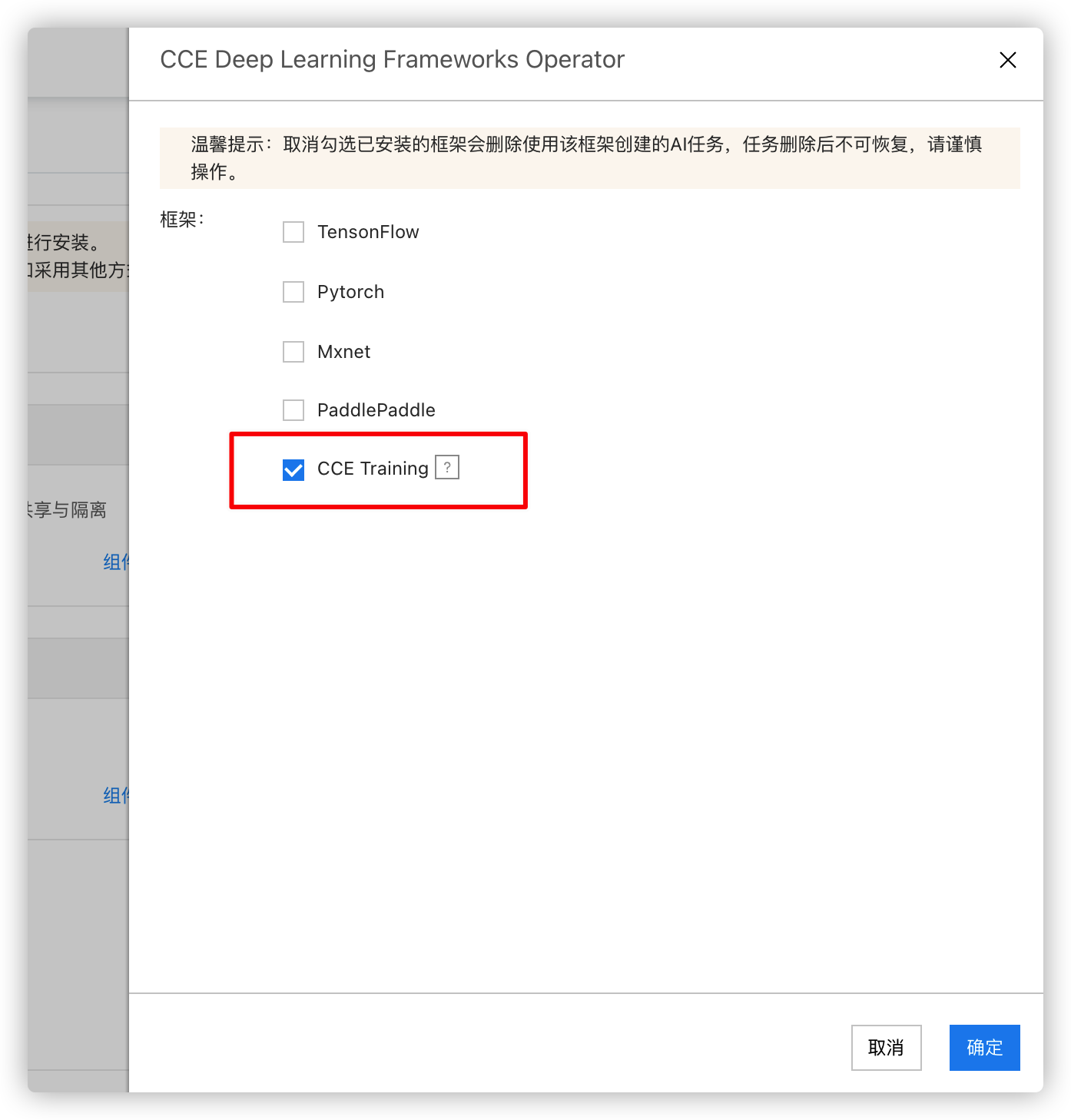
Task submission
In the CCE cluster console, go to Cloud Native AI - Task Management and submit a task. Select the framework: AITrainingJob. To enable fault tolerance (required for both fault-tolerant tasks and elastic tasks), check the Fault Tolerance option.
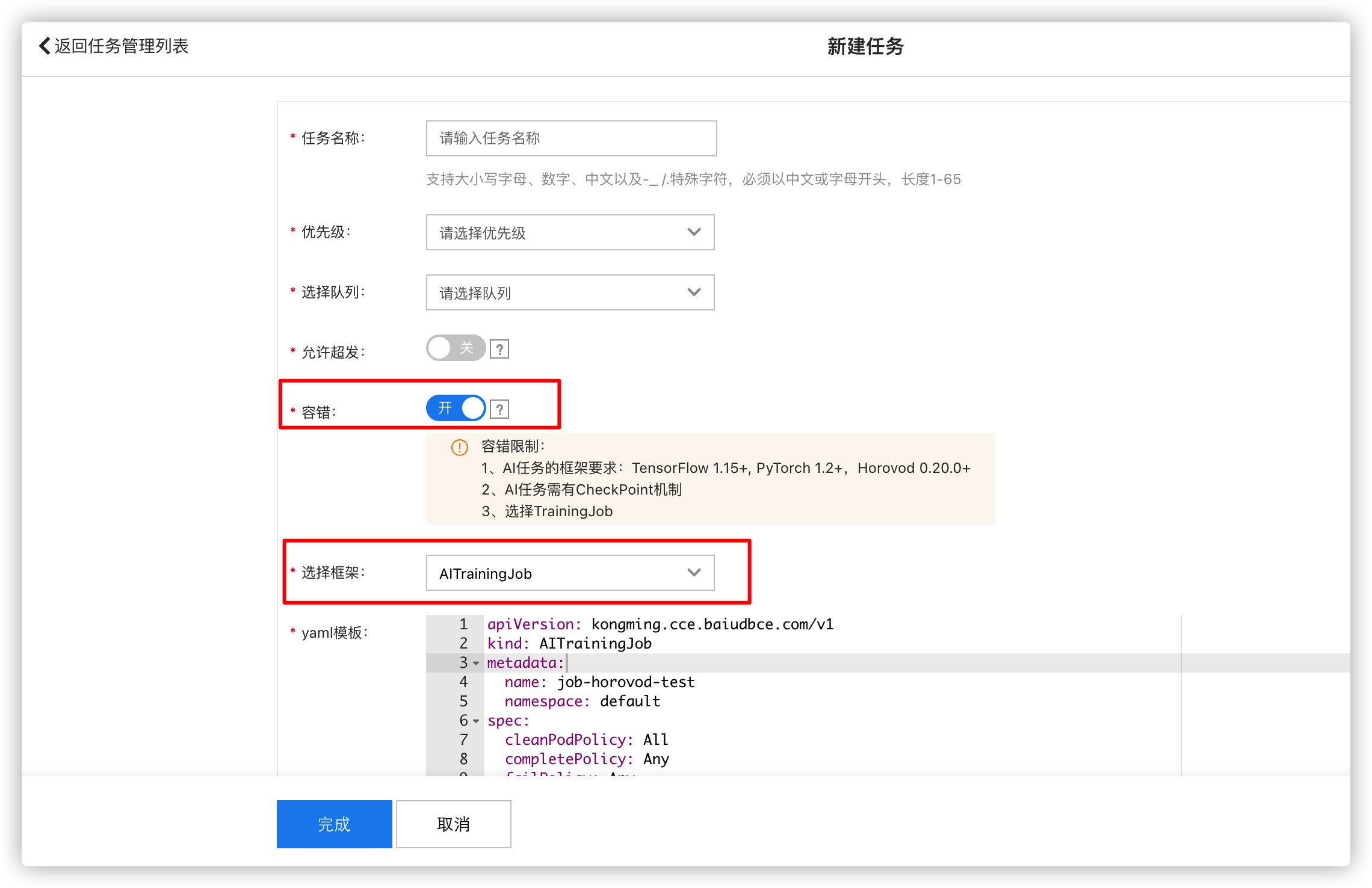
Generate YAML template for elastic & fault-tolerant training tasks:
1apiVersion: kongming.cce.baiudbce.com/v1
2kind: AITrainingJob
3metadata:
4 name: test-horovod-elastic
5 namespace: default
6spec:
7 cleanPodPolicy: None
8 completePolicy: Any
9 failPolicy: Any
10 frameworkType: horovod
11 faultTolerant: true
12 plugin:
13 ssh:
14 - ""
15 discovery:
16 - ""
17 priority: normal
18 replicaSpecs:
19 launcher:
20 completePolicy: All
21 failPolicy: Any
22 faultTolerantPolicy:
23 - exitCodes: 129,101
24 restartPolicy: ExitCode
25 restartScope: Pod
26 - exceptionalEvent: nodeNotReady
27 restartPolicy: OnNodeFail
28 restartScope: Pod
29 maxReplicas: 1
30 minReplicas: 1
31 replicaType: master
32 replicas: 1
33 restartLimit: 100
34 restartPolicy: OnNodeFailWithExitCode
35 restartScope: Pod
36 restartTimeLimit: 60
37 restartTimeout: 864000
38 template:
39 metadata:
40 creationTimestamp: null
41 spec:
42 initContainers:
43 - args:
44 - --barrier_roles=trainer
45 - --incluster
46 - --name=$(TRAININGJOB_NAME)
47 - --namespace=$(TRAININGJOB_NAMESPACE)
48 - --dns_check_svc=kube-dns
49 image: registry.baidubce.com/cce-plugin-dev/jobbarrier:v0.9-1
50 imagePullPolicy: IfNotPresent
51 name: job-barrier
52 restartPolicy: Never
53 schedulerName: volcano
54 terminationMessagePath: /dev/termination-log
55 terminationMessagePolicy: File
56 securityContext: {}
57 containers:
58 - command:
59 - /bin/bash
60 - -c
61 - export HOROVOD_GLOO_TIMEOUT_SECONDS=300 && horovodrun -np 3 --min-np=1 --max-np=5 --verbose --log-level=DEBUG --host-discovery-script /etc/edl/discover_hosts.sh python /horovod/examples/elastic/pytorch/pytorch_synthetic_benchmark_elastic.py --num-iters=1000
62 env:
63 image: registry.baidubce.com/cce-plugin-dev/horovod:master-0.2.0
64 imagePullPolicy: Always
65 name: aitj-0
66 resources:
67 limits:
68 cpu: "1"
69 memory: 1Gi
70 requests:
71 cpu: "1"
72 memory: 1Gi
73 volumeMounts:
74 - mountPath: /dev/shm
75 name: cache-volume
76 dnsPolicy: ClusterFirstWithHostNet
77 terminationGracePeriodSeconds: 30
78 volumes:
79 - emptyDir:
80 medium: Memory
81 sizeLimit: 1Gi
82 name: cache-volume
83 trainer:
84 completePolicy: None
85 failPolicy: None
86 faultTolerantPolicy:
87 - exceptionalEvent: "nodeNotReady,PodForceDeleted"
88 restartPolicy: OnNodeFail
89 restartScope: Pod
90 maxReplicas: 5
91 minReplicas: 1
92 replicaType: worker
93 replicas: 3
94 restartLimit: 100
95 restartPolicy: OnNodeFailWithExitCode
96 restartScope: Pod
97 restartTimeLimit: 60
98 restartTimeout: 864000
99 template:
100 metadata:
101 creationTimestamp: null
102 spec:
103 containers:
104 - command:
105 - /bin/bash
106 - -c
107 - /usr/sbin/sshd && sleep infinity
108 image: registry.baidubce.com/cce-plugin-dev/horovod:master-0.2.0
109 imagePullPolicy: Always
110 name: aitj-0
111 env:
112 - name: NVIDIA_DISABLE_REQUIRE
113 value: "true"
114 - name: NVIDIA_VISIBLE_DEVICES
115 value: "all"
116 - name: NVIDIA_DRIVER_CAPABILITIES
117 value: "all"
118 resources:
119 limits:
120 baidu.com/v100_32g_cgpu: "1"
121 baidu.com/v100_32g_cgpu_core: "20"
122 baidu.com/v100_32g_cgpu_memory: "4"
123 requests:
124 baidu.com/v100_32g_cgpu: "1"
125 baidu.com/v100_32g_cgpu_core: "20"
126 baidu.com/v100_32g_cgpu_memory: "4"
127 volumeMounts:
128 - mountPath: /dev/shm
129 name: cache-volume
130 dnsPolicy: ClusterFirstWithHostNet
131 terminationGracePeriodSeconds: 300
132 volumes:
133 - emptyDir:
134 medium: Memory
135 sizeLimit: 1Gi
136 name: cache-volume
137 schedulerName: volcanoSpecify 3 workers and submit the task:
1NAME READY STATUS RESTARTS AGE
2test-horovod-elastic-launcher-vwvb8-0 0/1 Init:0/1 0 6s
3test-horovod-elastic-trainer-q7gmp-0 1/1 Running 0 7s
4test-horovod-elastic-trainer-spkb8-1 1/1 Running 0 7s
5test-horovod-elastic-trainer-sxf6s-2 1/1 Running 0 7sElastic scenario
Adjust the number of workers for a running training task and define the scaling timeout.
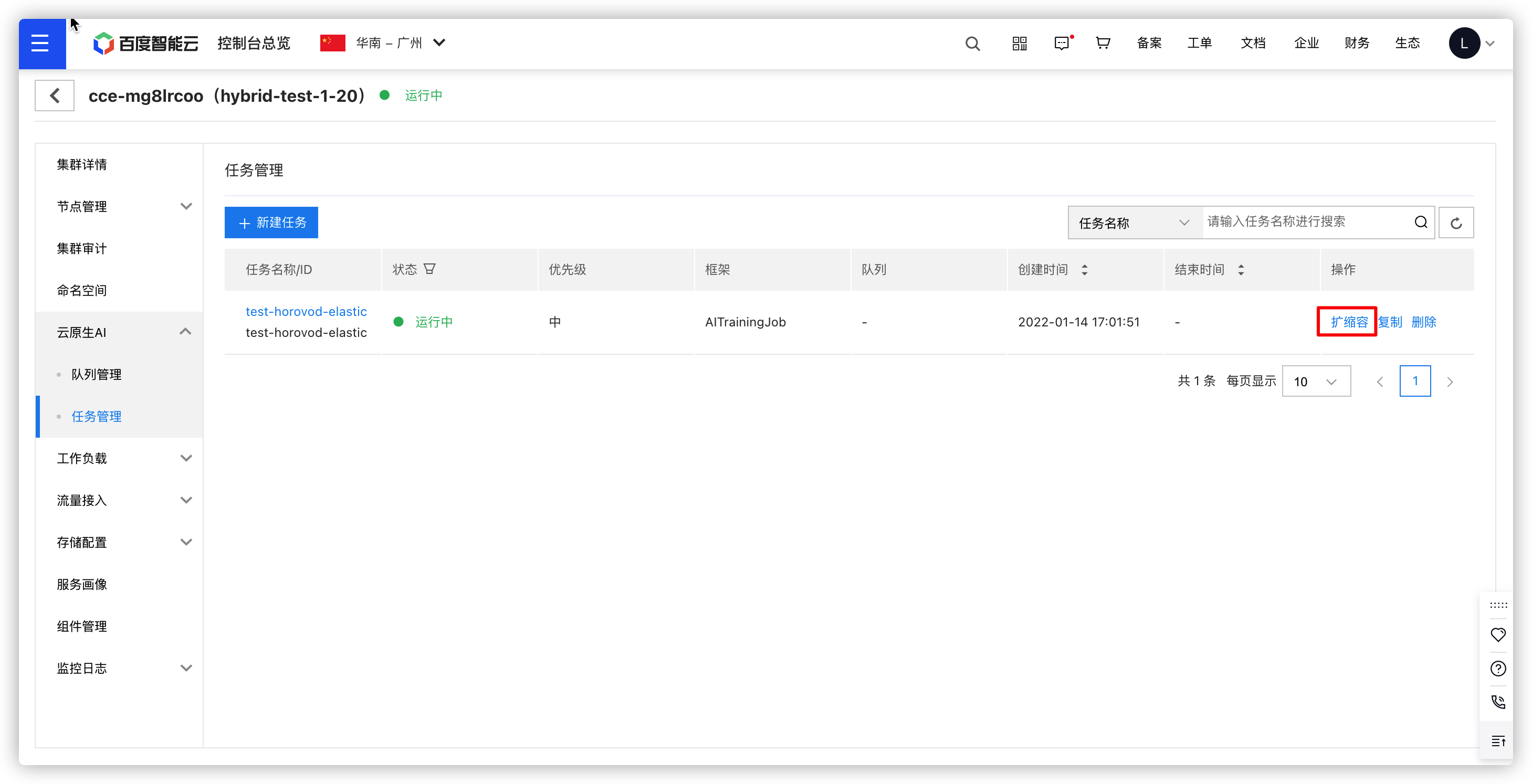
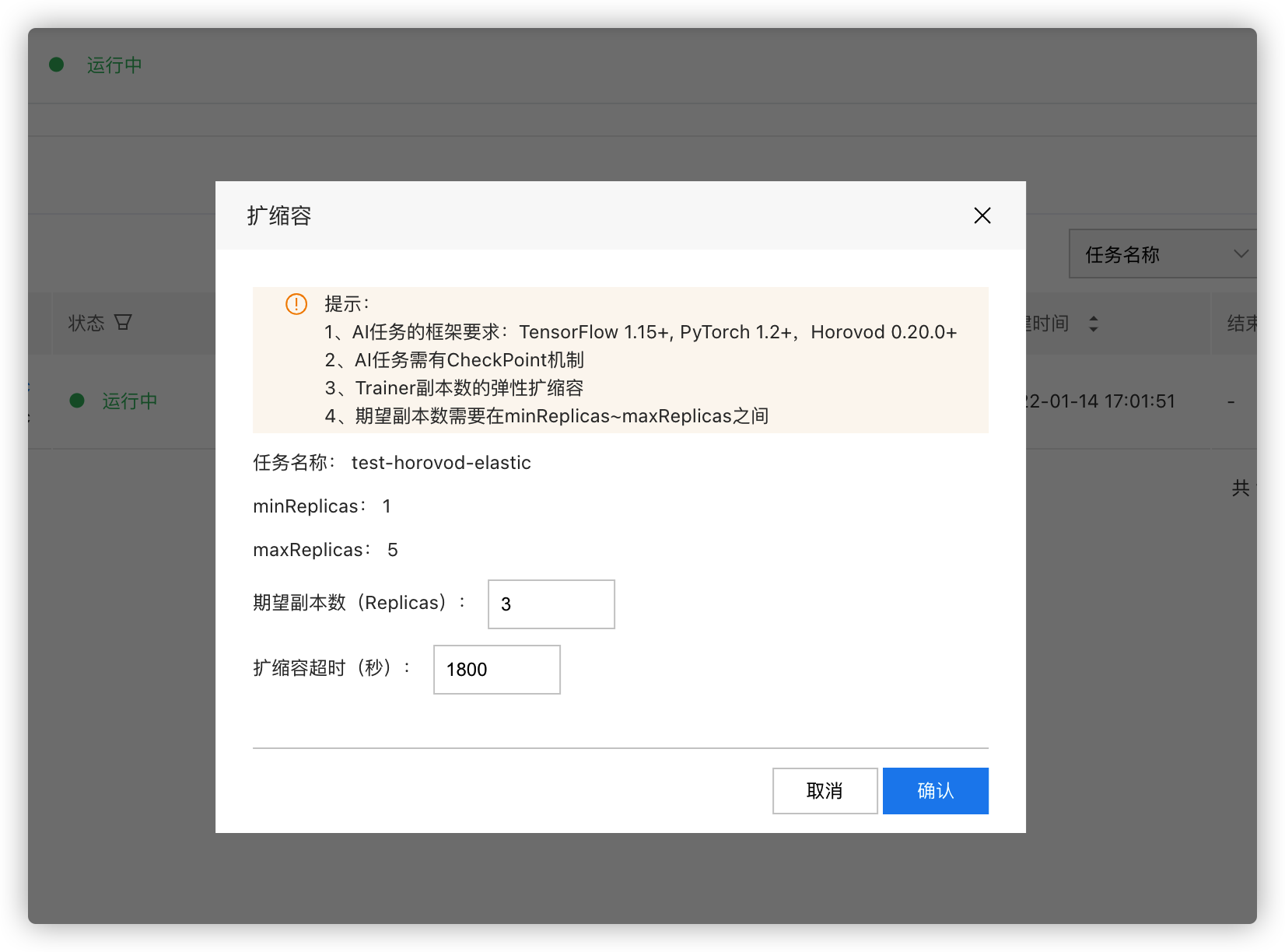
Directly edit the CR YAML in the cluster. Modify the value of spec.replicaSpecs.trainer.replicas to set the desired number of workers for elasticity.
Scaling events will be recorded, and new worker pods will be created in the cluster to join the active task.
1status:
2 RestartCount:
3 trainer: 0
4 conditions:
5 - lastProbeTime: "2022-01-14T09:01:52Z"
6 lastTransitionTime: "2022-01-14T09:01:52Z"
7 message: all pods are waiting for scheduling
8 reason: TrainingJobPending
9 status: "False"
10 type: Pending
11 - lastProbeTime: "2022-01-14T09:01:53Z"
12 lastTransitionTime: "2022-01-14T09:01:53Z"
13 message: pods [test-horovod-elastic-launcher-vk9c2-0] creating containers
14 reason: TrainingJobCreating
15 status: "False"
16 type: Creating
17 - lastProbeTime: "2022-01-14T09:02:27Z"
18 lastTransitionTime: "2022-01-14T09:02:27Z"
19 message: all pods are running
20 reason: TrainingJobRunning
21 status: "False"
22 type: Running
23 - lastProbeTime: "2022-01-14T09:06:16Z"
24 lastTransitionTime: "2022-01-14T09:06:16Z"
25 message: trainingJob default/test-horovod-elastic scaleout Operation scaleout
26 scale num 1 scale pods [test-horovod-elastic-trainer-vdkk6-3], replicas name
27 trainer job version 1
28 status: "False"
29 type: Scaling
30 - lastProbeTime: "2022-01-14T09:06:20Z"
31 lastTransitionTime: "2022-01-14T09:06:20Z"
32 message: all pods are running
33 reason: TrainingJobRunning
34 status: "True"
35 type: Running1NAME READY STATUS RESTARTS AGE
2test-horovod-elastic-launcher-vk9c2-0 1/1 Running 0 7m4s
3test-horovod-elastic-trainer-4zzk4-0 1/1 Running 0 7m5s
4test-horovod-elastic-trainer-b5rc2-2 1/1 Running 0 7m5s
5test-horovod-elastic-trainer-kdjq2-1 1/1 Running 0 7m5s
6test-horovod-elastic-trainer-vdkk6-3 1/1 Running 0 2m40sFault tolerance scenario
After creating a training task in CCE and enabling fault tolerance, the fault tolerance policy will be specified in the faultTolorencePolicy field of the submitted YAML, as follows:
1faultTolerantPolicy:
2 - exceptionalEvent: nodeNotReady,PodForceDeleted
3 restartPolicy: OnNodeFail
4 restartScope: PodWhen a pod exits unexpectedly with a specific exit code, is evicted due to a node being in a "NotReady" state, or is forcibly deleted, the operator automatically initiates a new training pod to replace the faulty one and resumes the training task.
After forcibly deleting one pod, a new pod will eventually be created to replace it, restoring the original 4 training instances:
1➜ kubectl get pods -w
2NAME READY STATUS RESTARTS AGE
3test-horovod-elastic-launcher-vk9c2-0 1/1 Running 0 7m59s
4test-horovod-elastic-trainer-4zzk4-0 1/1 Terminating 0 8m
5test-horovod-elastic-trainer-b5rc2-2 1/1 Running 0 8m
6test-horovod-elastic-trainer-kdjq2-1 1/1 Running 0 8m
7test-horovod-elastic-trainer-vdkk6-3 1/1 Running 0 3m35s
8test-horovod-elastic-trainer-4zzk4-0 0/1 Terminating 0 8m7s
9test-horovod-elastic-trainer-4zzk4-0 0/1 Terminating 0 8m8s
10test-horovod-elastic-trainer-4zzk4-0 0/1 Terminating 0 8m8s
11test-horovod-elastic-trainer-htbz4-0 0/1 Pending 0 0s
12test-horovod-elastic-trainer-htbz4-0 0/1 Pending 0 1s
13test-horovod-elastic-trainer-htbz4-0 0/1 Pending 0 1s
14test-horovod-elastic-trainer-htbz4-0 0/1 Pending 0 1s
15test-horovod-elastic-trainer-htbz4-0 0/1 ContainerCreating 0 1s
16test-horovod-elastic-trainer-htbz4-0 1/1 Running 0 3s