StatefulSet Management
Overview
A workload that retains data or state during operation is called a stateful workload, corresponding to "StatefulSet" in Kubernetes. For instance, MySQL saves the data generated during its operation. Users can create a stateful deployment based on images using forms or manage it via YAML templates provided by Baidu AI Cloud to control Pods, events, and other aspects of the stateful deployment.
Introduction to StatefulSet
Similar to deployments, StatefulSet also ensures that a specified number of Pods remain running. However, StatefulSet retains the identity of Pods through certain mechanisms:
- Ordered and stable naming: Each Pod in a StatefulSet is named sequentially as
- . For example, if the StatefulSet is "db-app," the Pods will be named "db-app-0" and "db-app-1." When a Pod is deleted and recreated, the new Pod retains the same name. Stable network identity: A StatefulSet often needs to be associated with a Headless Service (specified via spec.serviceName). This Headless Service does not provide load balancing like ClusterIP but is used to assign fixed domain names to Pods (DNS queries for the Headless Service return all matching Pod IPs). After associating with a Headless Service, the domain name of a Pod is formatted as . ..svc. For example: "db-app-01.db-app.default.svc.cluster.local." When a Pod is recreated, its domain name automatically resolves to the new Pod. - Stable persistent storage: StatefulSet allows you to specify a PVC template (via spec.volumeClaimTemplates). A separate PersistentVolumeClaim (PVC) is created for each Pod using this template, following the naming convention
- . Even if a Pod is deleted, the PVC is retained and automatically linked to the new Pod with the same identifier.
The above measures ensure that the Pod of StatefulSet can inherit the original network and storage status after reconstruction, enabling the application to recover and run from persistent data. For more information about StatefulSet, please refer to Official Documentation.
Prerequisites
- A K8S Cluster CCE has been created successfully. For specific operations, refer to Create a K8S Cluster CCE.
Create a stateful workload (StatefulSet)
Users can create a new stateful workload in the CCE console using forms, YAML files, or kubectl commands.
Create via console form
- Sign in to Cloud Container Engine Console (CCE).
- In the left navigation bar, click Cluster Management -> Cluster List to enter the cluster list page. Click the Cluster Name to enter the Cluster Management page.
- In the left navigation bar of the Cluster Management page, click Workload > Stateful.
- Click Create Stateless in the upper left corner of the stateful workload list to enter the Workload Creation page.
- Complete the configuration in the basic information module and click Next to proceed to container configuration.
| Parameters | Description |
|---|---|
| Workload name | Name the workload as prompted by the system. Ensure the name is unique within the same namespace. |
| Namespace | Select the namespace for workload deployment (default: default). Custom namespaces are supported; for details, refer to Namespace Operations. |
| Workload type | Choose the "StatefulSet" deployment type. |
| Desired Pod count | Specify the number of Pod instances for the workload. |
| K8S label | Specify labels for the workload (corresponding to labels in Kubernetes) to identify the key-value pairs of workloads, and help Kubernetes quickly filter target workloads combined with selectors. For details, refer to K8S Label Description. |
| Annotation | Specify annotation information for the workload (corresponding to annotations in Kubernetes) to mainly record additional information for application deployment, security policies and scheduling policies, and fail to identify or distinguish resources. For details, refer to K8S Annotation Description. |
-
In the container configuration section, input the container name and image address. Then, click Select the Image to choose the image address in CCR from the pop-up window. Click Next to proceed to the advanced configuration section.
Description
- Multiple containers can be added to a Pod. Click Add Container on the right to configure additional containers for the Pod.
- If using a private image from CCR, configure repository access credentials in the advanced settings on the current page.
| Parameters | Description |
|---|---|
| Container name | Name the container following the system's rules. Each container name must be unique within the same workload. |
| Image address | Click Select Image to pick the image for the container. Two types of images are supported. |
| Image version | Choose the image version to deploy. |
| Image pull policy | Select an image pull policy. CCE provides three pull policies (imagePullPolicy): |
| Container resources | Configure resources.limits and resources.requests for container resources. If the request value and limit value are not filled in, the quota is not limited. For instructions and recommendations for configuration of request value and limit value, please refer to Requests and Limits.
|
| Container ports | Define the port name, protocol, and port number for the container. |
| Environment variables | Click Add Environment Variable to set up environment variables. Kubernetes automatically injects these variables into containers when creating Pods. Supported types include: |
| Container startup item | Add startup parameters to the container, and currently support the following container startup parameters: kubectl exec -i -t command (configured during Pod startup). |
| Privileged container | Default: Disabled. When enabled, the container gains elevated privileges similar to the host OS of the worker node, such as accessing hardware devices or mounting file systems. |
| Init container | Default: disable. Select whether the container is used as an Init container. Init containers do not support health checks. The Init container is a special container that can run before other application containers in the Pod start. Each Pod can contain multiple containers, and there can also be one or more Init containers in the Pod that start before the application container. The application container in the Pod will only start and run when all Init containers have completed running. For details, refer to Init Container. |
| Health check | Support configuring Liveness Check Readiness Check and Startup Check. Detect whether the load in the container is normal based on HTTP request check, TCP port check, command execution check and GRCP check. Taking the configuration liveness check as an example, the following introduces configuration parameters.
|
| Lifecycle | Set operations to be performed at specific stages of the container's lifecycle, such as startup commands, tasks after starting up, and procedures before shutdown. For details, see Set the Container Lifecycle. |
| Volume | Support mounting various types of volumes for containers for data persistence, including subpath mounting via subPath and extended path mounting via subPathExpr: cm1:path1;cm2:path2.sc1:path1;sc2:path2. |
| Repository access credentials | If a container uses a private image, be sure to add the corresponding access credentials for the image repository. Support creating credentials or selecting existing ones. For details, refer to Configure Access Credentials. |
- In the advanced settings section, set the scheduling policies and click Finish to create the workload.
| Parameters | Description |
|---|---|
| Autoscaler configuration | Two autoscaler configuration types are supported: Horizontal Pod Autoscaler and Cron Horizontal Pod Autoscaler.
|
| Scheduling policies | Enable flexible workload scheduling by defining affinity and anti-affinity rules, which support both load and node affinity.
|
| Pod labels | Add labels to each Pod belonging to the workload (corresponding to labels in Kubernetes), to identify key-value pairs of Pods, and use selectors to help Kubernetes quickly filter target Pods. For details, refer to K8S Label Description. |
| Pod annotations | Add annotations to each Pod belonging to this workload (corresponding to annotations in Kubernetes) to mainly record additional information for application deployment, security policies and scheduling policies, and fail to identify or distinguish resources. For details, refer to K8S Annotation Description. |
Method II: Create via YAML
- Click Create via YAML in the upper left corner of the deployment list to enter the New Workload page.
- Select a namespace from the drop-down list, fill in the YAML file, and click OK.
Note:
- Template type: Create using either the example template or "My Template."
- Replication: Duplicate the content of the current YAML file.
- Save as: Save the current file template under the name "My Template."
- Cancel: Return to the list page.
Workload YAML Example
1apiVersion: apps/v1
2kind: StatefulSet
3metadata:
4 name: statefulset-example
5spec:
6 serviceName: "nginx"
7 replicas: 2
8 selector:
9 matchLabels:
10 app: nginx # has to match .spec.template.metadata.labels
11 template:
12 metadata:
13 labels:
14 app: nginx
15 spec:
16 containers:
17 - name: nginx
18 image: registry.baidubce.com/cce/nginx-alpine-go:latest
19 livenessProbe:
20 httpGet:
21 path: /
22 port: 80
23 initialDelaySeconds: 20
24 timeoutSeconds: 5
25 periodSeconds: 5
26 readinessProbe:
27 httpGet:
28 path: /
29 port: 80
30 initialDelaySeconds: 5
31 timeoutSeconds: 1
32 periodSeconds: 5
33 ports:
34 - containerPort: 80
35 name: web
36 updateStrategy:
37 type: RollingUpdateMethod III: Create via kubectl
- Prepare the YAML file for the StatefulSet.
- Install kubectl and connect to the cluster. For details, refer to Connect to a Cluster via Kubectl.
- Copy the YAML file provided below and save it as statefulset.yaml.
1apiVersion: apps/v1
2kind: StatefulSet
3metadata:
4 name: statefulset-example
5spec:
6 serviceName: "nginx"
7 replicas: 2
8 selector:
9 matchLabels:
10 app: nginx # has to match .spec.template.metadata.labels
11 template:
12 metadata:
13 labels:
14 app: nginx
15 spec:
16 containers:
17 - name: nginx
18 image: registry.baidubce.com/cce/nginx-alpine-go:latest
19 livenessProbe:
20 httpGet:
21 path: /
22 port: 80
23 initialDelaySeconds: 20
24 timeoutSeconds: 5
25 periodSeconds: 5
26 readinessProbe:
27 httpGet:
28 path: /
29 port: 80
30 initialDelaySeconds: 5
31 timeoutSeconds: 1
32 periodSeconds: 5
33 ports:
34 - containerPort: 80
35 name: web
36 updateStrategy:
37 type: RollingUpdate-
Run the following command to create the StatefulSet.
Bash1kubectl apply -f statefulset.yamlExpected output:
Bash1service/nginx created 2statefulset.apps/statefulset-example created -
Execute the following command to view the public IP address of the service.
Bash1kubectl get svc -
Execute the following command to verify whether the StatefulSet is created successfully:
Bash1 kubectl get statefulset
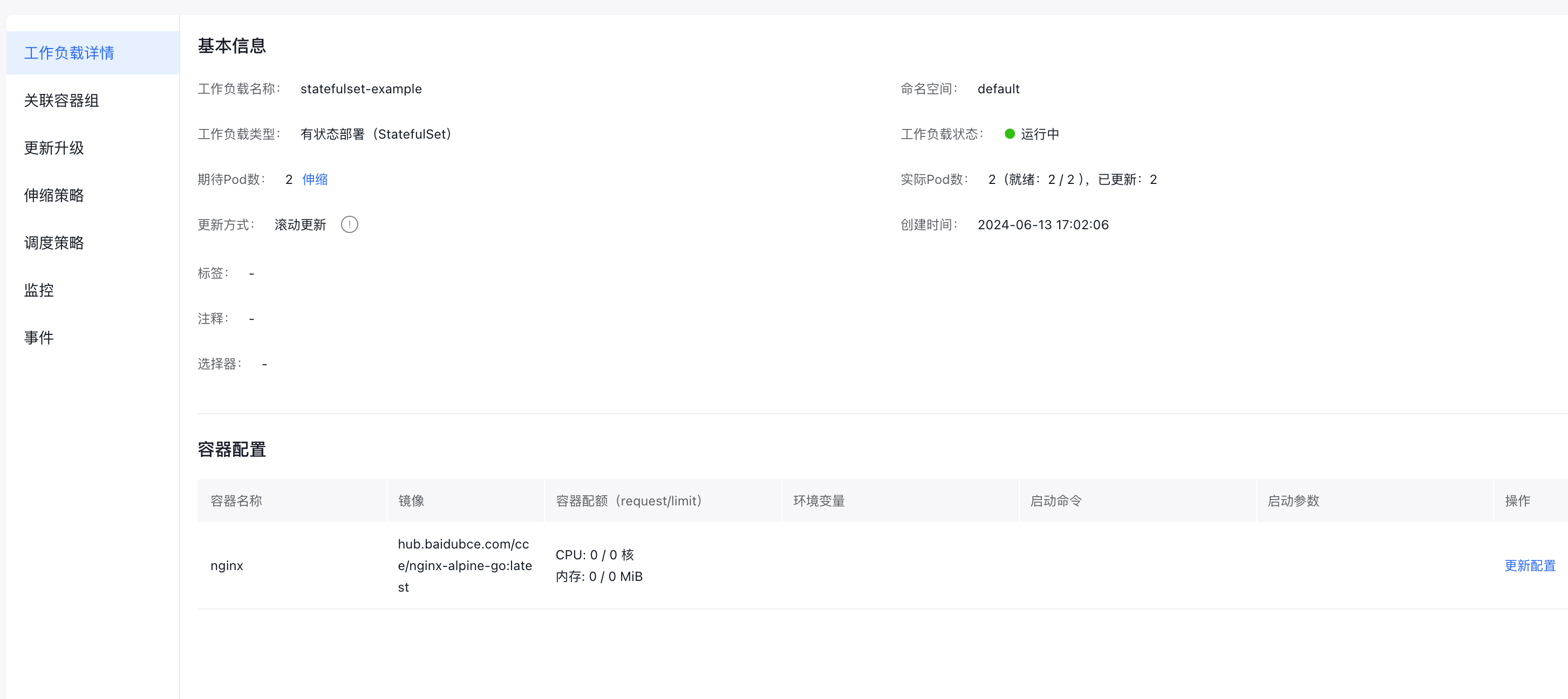
View stateful deployment details
Click the name of any workload in the list to enter its details page, which includes:
workload details, associated Pods, updates/upgrades, scaling policies, scheduling policies, monitoring data, events, etc.
Update Pod count
Enable efficient updates to the Pod count for a stateless workload using the console.
-
Log in to the Stateful Workload Management page.
a. Sign in to Cloud Container Engine Console (CCE).
b. In the left navigation bar, click Cluster Management -> Cluster List to enter the Cluster List page. Click the Cluster Name to enter the Cluster Management page.
c. In the left navigation bar of the Cluster Management page, click Workload > Stateful. - In the target stateful workload list, click Scale in the row of the stateful workload to be adjusted. In the scaling pop-up window, enter the required Pod count and click OK.
Update stateful workloads
You can edit the created stateful workload through the console interface or directly via the YAML file.
-
Log in to the Stateful Workload Management page.
a. Sign in to Cloud Container Engine Console (CCE).
b. In the left navigation bar, click Cluster Management -> Cluster List to enter the Cluster List page. Click the Cluster Name to enter the Cluster Management page.
c. In the left navigation bar of the Cluster Management page, click Workload > Stateful Workload. - In the operation column of the target stateful workload, click Update and Upgrade or Edit YAML.
Description:
Neither console interface updates nor YAML file editing support updating the stateful workload name or namespace.
1a. Update: Update configuration information on the console. For detailed parameter descriptions, please refer to [Create via Console] (https://cloud.baidu.com/doc/CCE/s/cjxpoxrgi). <br>
2 b. Edit YAML: Update configuration information by editing the YAML file. For detailed YAML configuration descriptions, please refer to [Create via YAML] (https://cloud.baidu.com/doc/CCE/s/cjxpoxrgi). <br>- Click Submit after completing the update.
Label and annotation management
Labels are applied to stateful workloads as key-value pairs. Once added, they allow you to manage and select workloads using labels. You can assign labels to specific workloads or multiple workloads at the same time.
Description:
Label format requirements: Labels must start and end with letters or numbers, contain letters, numbers, hyphens (-), underscores (_) or dots (.), and be within 63 characters. For details, refer to K8S Label Description.
-
Log in to the Stateful Workload Management page.
a. Sign in to Cloud Container Engine Console (CCE).
b. In the left navigation bar, click Cluster Management -> Cluster List to enter the Cluster List page. Click the Cluster Name to enter the Cluster Management page.
c. In the left navigation bar of the Cluster Management page, click Workload > Stateful. - Select the Stateful tab, and click More > Labels and Annotations next to the workload.
- Click Add Label, enter the key and value, and then click Update.
View monitor
Check the CPU and memory usage of workloads and Pods in the CCE console to assess the required resource specifications.
Description:
Viewing workload monitoring information depends on the cluster being connected to the Cloud Managed Service for Prometheus. If the cluster is not connected to the Cloud Managed Service for Prometheus, please follow the prompts on the interface to connect. For details, refer to Monitor Clusters with Prometheus.
-
Log in to the Stateful Workload Management page.
a. Sign in to Cloud Container Engine Console (CCE).
b. In the left navigation bar, click Cluster Management -> Cluster List to enter the Cluster List page. Click the Cluster Name to enter the Cluster Management page.
c. In the left navigation bar of the Cluster Management page, click Workload > Stateful. - In the target stateful workload list, click Monitor in the row of the stateful workload to be monitored.
- View the monitor data of the stateful workload on the Monitor page. For descriptions of container-related monitor metrics, please refer to Monitor Metrics Description.
View logs
Use the "Log" function to examine log information for stateless workloads.
Description:
Currently displayed logs are container standard output logs, which do not support persistence or advanced operation and maintenance capabilities. For more comprehensive logging, enable the Log Center Function.
-
Log in to the Stateful Workload Management page.
a. Sign in to Cloud Container Engine Console (CCE).
b. In the left navigation bar, click Cluster Management -> Cluster List to enter the Cluster List page. Click the Cluster Name to enter the Cluster Management page.
c. In the left navigation bar of the Cluster Management page, click Workload > Stateful. - In the target stateful workload list, click More > Log next to the workload.
- Examine container log data on the log page.
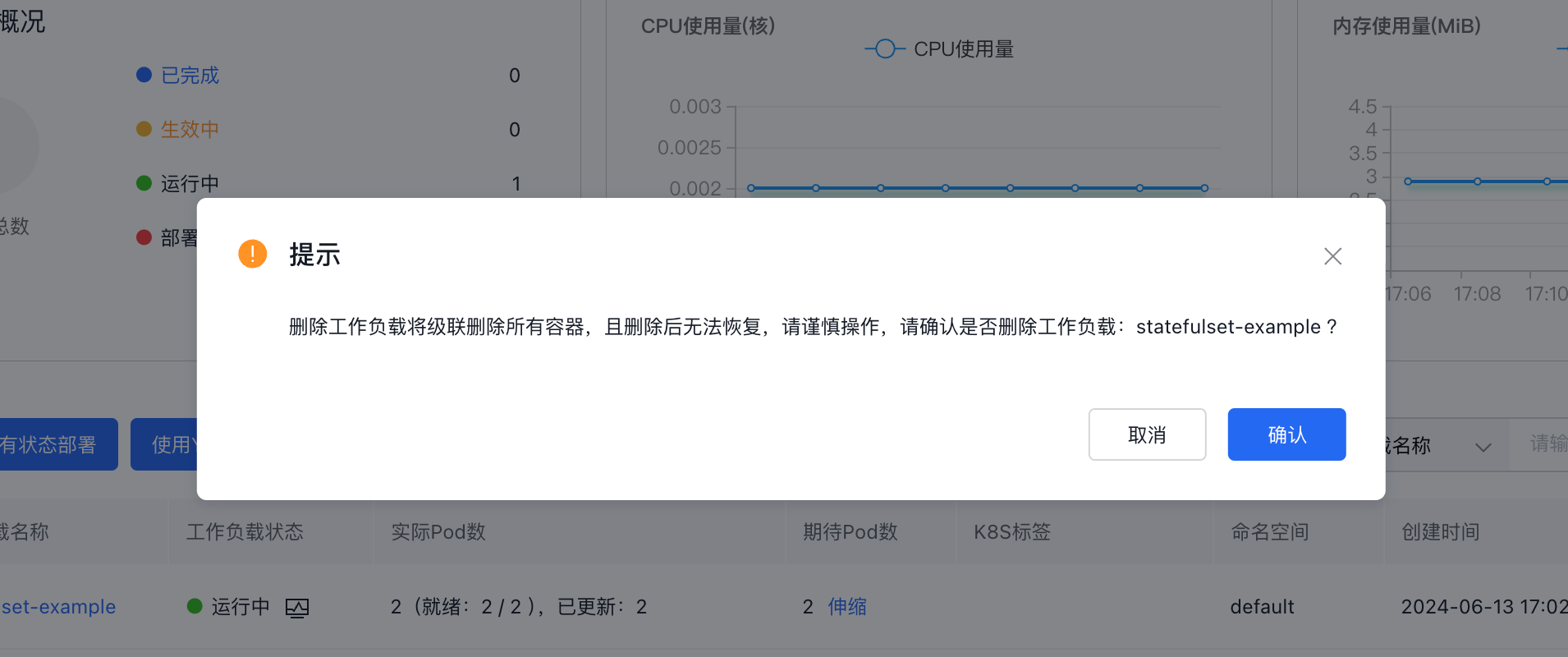
Delete stateful workloads
If a workload is no longer required, you can remove it.
Description:
Deleting a stateful workload may cause service unavailability; please proceed with caution.
-
Log in to the Stateful Workload Management page.
a. Sign in to Cloud Container Engine Console (CCE).
b. In the left navigation bar, click Cluster Management -> Cluster List to enter the Cluster List page. Click the Cluster Name to enter the Cluster Management page.
c. In the left navigation bar of the Cluster Management page, click Workload > Stateful. - In the target stateful workload list, click More > Delete next to the workload.
- In the secondary confirmation dialog box that pops up in the system, confirm the information and click OK.