Cluster Service Profiling
Overview
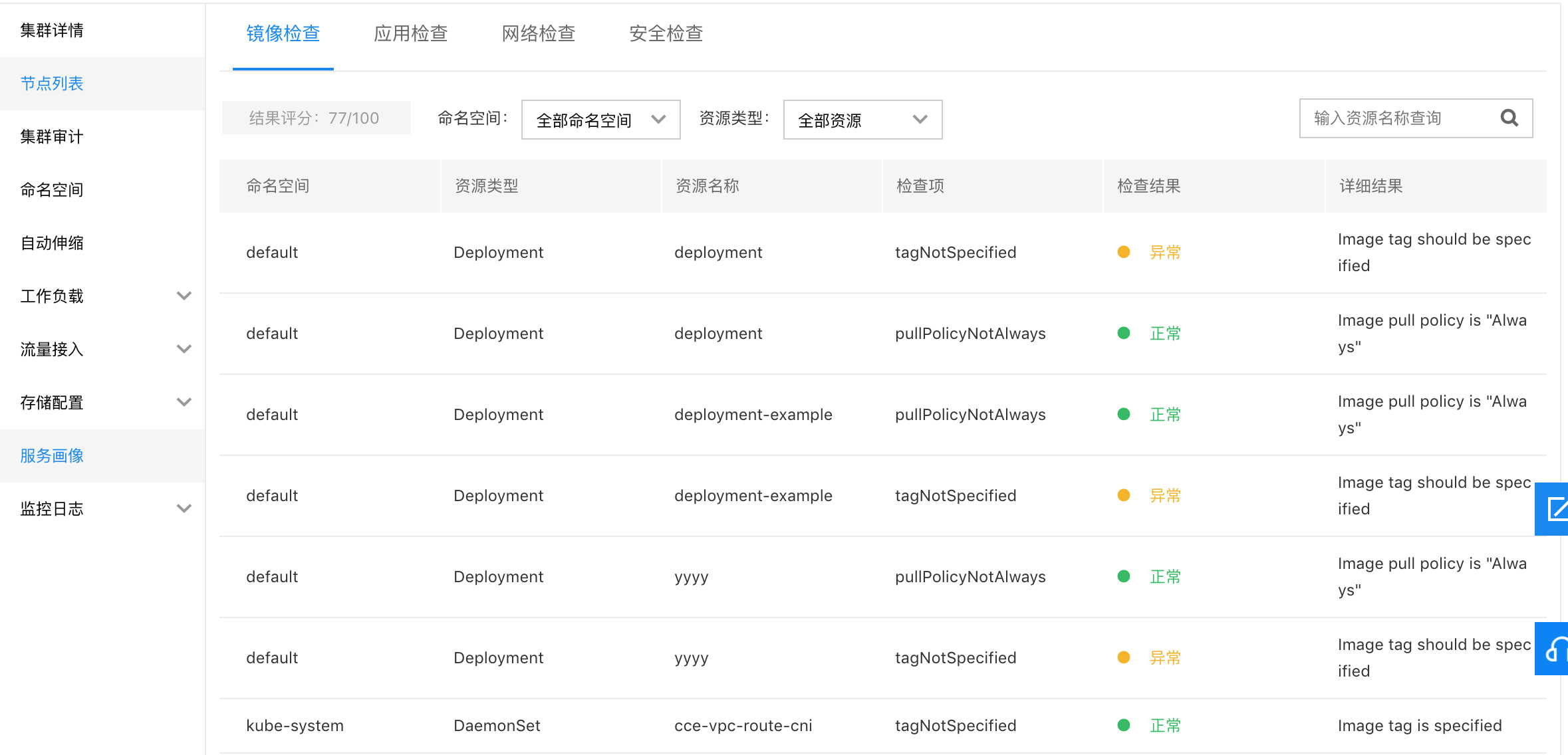
The CCE service profiling feature allows users to assess the characteristics and compliance of all resources in the cluster (e.g., image checks, application checks, network checks, and security checks). Detailed scores and explanations are provided to help users better understand the cluster's service status.
Note: Service profiling results are derived from the previous day's cluster data, and inspection rules are general criteria that may not fully align with all service scenarios.
Inspection object
Inspected objects include:
- All namespaces within the cluster.
- Resource objects include: Deployment, DaemonSet, StatefulSet, Service, CronJob, and Job.
Inspection rules
I. Image inspection
| Inspection items | Meaning | Impact level |
|---|---|---|
| tagNotSpecified | A tag or the tag being latest is not declared for the image address | danger |
| pullPolicyNotAlways | The image pull policy is not always | warning |
Explanation:
- tagNotSpecified: If the image version (tag) is not specified, it defaults to "latest." This can lead to various issues, such as different pods running different programs simultaneously even though they seem to share the same image version. Moreover, images without version identifiers cannot distinguish versions upon release, making rollback operations impossible.
- pullPolicyNotAlways: Images relying on caching can cause problems, especially when using the "latest" tag. In such cases, the local cached images are used directly instead of fetching the latest images. It is recommended to set the policy to "Always"; if not explicitly configured, the default is "Always.\
Reference document: https://vsupalov.com/docker-latest-tag/
Error example:
1containers:
2 - name: nginx
3 image: hub.baidubce.com/cce/nginx-alpine-go:latest
4 imagePullPolicy: NeverCorrect example:
1containers:
2 - name: nginx
3 image: hub.baidubce.com/cce/nginx-alpine-go:v1
4 imagePullPolicy: AlwaysII. Application Inspection
| Inspection items | Meaning | Impact level |
|---|---|---|
| cpuRequestsMissing | No CPU resource request value declared | danger |
| cpuLimitsMissing | No CPU resource limit value declared | danger |
| memoryRequestsMissing | No memory resource request value declared | danger |
| memoryLimitsMissing | No memory resource limit value declared | danger |
| readinessProbeMissing | No readinessProbe declared | danger |
| livenessProbeMissing | No livenessProbe declared | danger |
Explanation:
- Configuring resource requests and limits for containers running in Kubernetes is a standard practice. Setting appropriate requests ensures that all applications have sufficient computational resources, while setting appropriate limits prevents applications from consuming excessive resources.
- readinessProbe and livenessProbe help maintain the health of applications running in Kubernetes. By default, Kubernetes only indicates if a process is running but does not verify if it is running correctly. Properly configuring readiness and liveness probes ensures the application operates as expected.
Reference documentation:
- https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/
- https://cloud.google.com/blog/products/gcp/kubernetes-best-practices-resource-requests-and-limits
- https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
Error example:
1Resources, livenessProbe, readinessProbe are not configuredCorrect example:
1 resources: # Limit Range
2 limits:
3 cpu: 250m
4 memory: 512Mi
5 requests:
6 cpu: 250m
7 memory: 512Mi
8 livenessProbe: # Health Check: Liveness Probe
9 httpGet:
10 path: /
11 port: 80
12 initialDelaySeconds: 20
13 timeoutSeconds: 5
14 periodSeconds: 5
15 readinessProbe: # Health Check: Readiness Probe
16 httpGet:
17 path: /
18 port: 80
19 initialDelaySeconds: 5
20 timeoutSeconds: 1
21 periodSeconds: 5III. Network Inspection
| Inspection items | Meaning | Impact level |
|---|---|---|
| hostNetworkSet | hostNetwork is configured | warning |
| hostPortSet | hostPort is configured | warning |
Explanation:
- hostNetworkSet: Although Kubernetes permits deploying pods that access the host's network namespace, this practice is not recommended. Pods with hostNetwork enabled can access loopback devices, listen to local host services, and potentially monitor the network activities of other pods on the same node. Certain specialized system components, like node-exporter, may set hostNetwork to "true.\
- hostPortSet: Setting the hostPort attribute on a container ensures it is accessible through a specific port on each node where it is deployed. However, specifying hostPort restricts the ability to schedule pods across the cluster.
Reference documentation: https://kubernetes.io/docs/concepts/configuration/overview/#services
Error example:
1spec:
2 hostNetwork: true
3 containers:
4 - name: nginx
5 ports:
6 - containerPort: 80
7 hostPort: 80Correct example:
1spec:
2 hostNetwork: false
3 containers:
4 - name: nginx
5 ports:
6 - containerPort: 80IV. Security Inspection
| Inspection items | Meaning | Impact level |
|---|---|---|
| hostIPCSet | hostPID is set | danger |
| hostPIDSet | hostPID is set | danger |
| notReadOnlyRootFileSystem | File system is not set to be read-only | warning |
| privilegeEscalationAllowed | Privileged upgrade is allowed | danger |
| runAsRootAllowed | Execute as the root account | danger |
| runAsPrivileged | Execution in privileged mode | danger |
| dangerousCapabilities | Capabilities contain risky options such as ALL/SYS_ADMIN/NET_ADMIN | danger |
Explanation:
Protecting workloads in Kubernetes is a crucial aspect of overall cluster security. The main objective is to ensure containers run with minimal privileges. This includes avoiding privilege escalation, not running containers as the root user, and using read-only file systems whenever possible.
Reference documentation: https://kubernetes.io/docs/tasks/configure-pod-container/security-context/
Error example:
1spec:
2 hostPID: true
3 hostIPC: true
4 containers:
5 - name: nginx
6 securityContext:
7 capabilities:
8 add: ["SYS_ADMIN"]Correct example:
1spec:
2 hostPID: false
3 hostIPC: false
4 containers:
5 - name: nginxScoring rules
The result score is calculated as: (count of passed checks / total count of checks) * 100
Example page: