
CCE AI Job Scheduler Description
Updated at:2025-10-27
Component introduction
The task scheduling component allows for organizing and managing diverse AI tasks. When used with the CCE Deep Learning Frameworks Operator, it enables direct training of deep learning models on CCE.
Component function
- Support a variety of scheduling strategies and advanced job management capabilities.
- Scheduling strategies include two types: "spread" and "binpack." "Binpack" prioritizes centralized GPU card sharing and usage by multiple Pods, ideal for improving GPU resource utilization. "Spread" aims to distribute multiple Pods across different GPU cards for scenarios requiring high GPU availability.
- Preemption modes support intra-queue priority preemption and inter-queue oversell/preemption. Intra-queue priority preemption: In the same queue, high-priority tasks can preempt resources of low-priority tasks to ensure the operation of high-priority tasks; inter-queue oversell/preemption: When queue A is fully utilized and queue B has idle resources, new tasks submitted to queue A will be scheduled to queue B. If queue B later receives new tasks and lacks resources, the oversell tasks will be killed to ensure the running of queue B tasks.
For the use of preemption functions, refer to the relevant descriptions in Queue Management and Task Management.
Application scenarios
Run deep learning tasks directly on CCE clusters to boost AI engineering efficiency.
Limitations
- Supports only Kubernetes clusters of version 1.18 or higher.
Install component
- Sign in to the Baidu AI Cloud official website and enter the management console.
- Go to Product Services - Cloud Native - Cloud Container Engine (CCE) to access the CCE management console.
- Click Cluster Management - Cluster List in the left navigation bar.
- Click on the target cluster name in the Cluster List page to navigate to the cluster management page.
- On the Cluster Management page, click Component Management.
- From the component management list, choose the CCE AI Job Scheduler Component and click Install.
- On the Component Configuration page, finish setting up the deep learning framework.
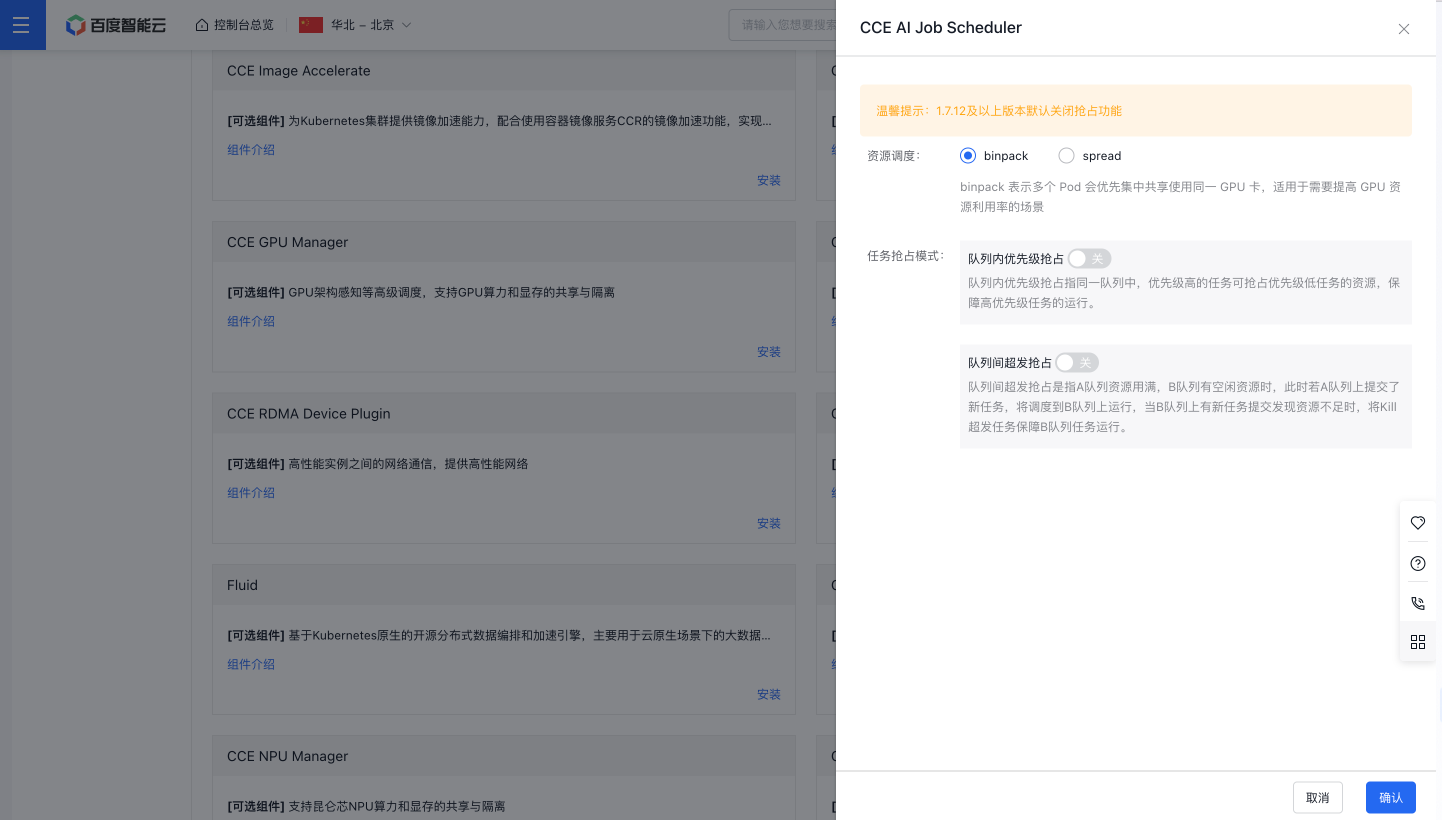
- Scheduling strategies include two options: spread and binpack. Binpack prioritizes centralized use of the same GPU card for multiple Pods, ideal for enhancing GPU resource usage. Spread aims to distribute multiple Pods across different GPU cards, ensuring high availability of GPU resources.
- Preemption modes include intra-queue priority preemption and inter-queue oversell/preemption. For intra-queue priority preemption: Within the same queue, high-priority tasks can seize resources from lower-priority tasks to maintain their operations. For inter-queue oversell/preemption: If queue A is fully utilized and queue B has idle resources, tasks submitted to queue A are scheduled to queue B. In case queue B later experiences a resource shortage due to new tasks, oversell tasks will be terminated to maintain the operation of tasks in queue B.
- Click the OK button to finalize the component installation.
Version records
| Version No. | Cluster version compatibility | Change time | Change content | Impact |
|---|---|---|---|---|
| 1.7.25 | CCE v1.18+ | 2024.11.07 | New Function: Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.24 | CCE v1.18+ | 2024.09.30 | New Function: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.23 | CCE v1.18+ | 2024.09.27 | New Function: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.22 | CCE v1.18+ | 2024.09.03 | New Function: Optimize: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.21 | CCE v1.18+ | 2024.08.14 | Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.20 | CCE v1.18+ | 2024.07.22 | New Function: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.19 | CCE v1.18+ | 2024.07.05 | New Function: Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.18 | CCE v1.18+ | 2024.06.26 | New Function: Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.17 | CCE v1.18+ | 2024.06.02 | New Function: Optimize: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.16 | CCE v1.18+ | 2024.05.23 | New Function: Optimize: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.15 | CCE v1.18+ | 2024.05.17 | New Function: Optimize: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.14 | CCE v1.18+ | 2024.05.09 | New Function: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. For versions below v1.7.13, please contact Baidu AI Cloud for assistance with upgrading. |
| 1.7.13 | CCE v1.18+ | 2024.04.15 | New Function: Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.12 | CCE v1.18+ | 2024.03.28 | New Function Optimize a. Disable online/offline mixed deployment by default b. Disable intra-queue/inter-queue preemption by default c. Disable VPC TOR affinity scheduling by default d. Support SLA policy switches for specific customer scenarios Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.11 | CCE v1.18+ | 2024.01.31 | Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.10 | CCE v1.18+ | 2023.12.21 | Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.9 | CCE v1.18+ | 2023.11.28 | New Function: Optimize: Bug Fixes: - Fix view errors caused by view synchronization delays after scheduler restart |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.8 | CCE v1.18+ | 2023.10.30 | New Function: Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.7 | CCE v1.18+ | 2023.10.11 | New Function: Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.6 | CCE v1.18+ | 2023.09.22 | New Function: Optimize: Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.4 | CCE v1.18+ | 2023.06.14 | New Function: Optimize Bug Fixes: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.3 | CCE v1.18+ | 2023.05.06 | New Function: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.2 | CCE v1.18+ | 2023.04.24 | New Function: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |
| 1.7.0 | CCE v1.18+ | 2023.04.14 | New Function: |
This upgrade will not affect service. Do not support upgrading from versions below v1.5.8 to this version. |