Cross-Cloud Application Migration to Baidu CCE Using Velero
1. Introduction
CCE allows users to use the open-source tool Velero for backing up and restoring Kubernetes clusters in cloud and private environments. It applies to scenarios such as cluster misoperations, cluster failures, and cluster migrations.
Functions of Velero:
- Disaster recovery: Provides the capability to back up and restore K8s clusters
- Migration: Enables copying cluster resources to other clusters
Differences from etcd backup:**
- Backing up etcd requires etcd operation and maintenance permissions, which users of managed clusters on CCE do not have
- etcd is more suitable for backing up data within a single cluster and less suitable for cluster migration
- etcd backs up the current state, while Velero can back up only a subset of resources in the cluster
The working principle of Velero is shown in the figure below (source: Velero Official Website). When a user executes a backup command, the backup process is as follows:
- Call the custom resource API to create a backup object.
- When the BackupController detects the created backup object, it initiates the backup operation.
- Upload the backed-up cluster resources and volume snapshots to Velero’s backend storage.
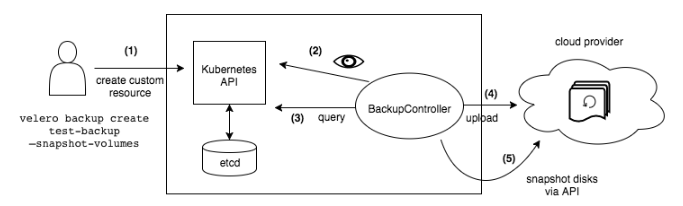
In addition, when a restore operation is performed, Velero synchronizes the data of the specified backup object from the backend storage to the Kubernetes cluster to complete the restoration.
For more information about Velero, see Velero Official Documentation.
This document will introduce how to use Baidu AI Cloud Object Storage (BOS) as the Velero backend storage to implement cluster backup from Alibaba Cloud ACK to Baidu AI Cloud CCE.
2. Installation and configuration
To migrate applications from ACK to CCE, you need to install and configure Velero and the velero-baiducloud-plugin.
- Create your BOS bucket on Baidu AI Cloud
- Obtain your AccessKey and SecretKey on Baidu AI Cloud
- Obtain the migration component CCE-Backup-Controller released by Baidu AI Cloud CCE, configure a container image example in Alibaba Cloud, and push images related to CCE-Backup-Controller
- Install the Velero command-line interface and server
- Modify Helm Values based on actual conditions
- Install and deploy CCE-Backup-Controller in the Alibaba Cloud ACK cluster
2.1 Create a BOS bucket in Baidu AI Cloud object storage
Velero requires object storage to store backup data. Create your BOS bucket on Baidu AI Cloud.
For the process of creating a bucket, refer to: Baidu Object Storage (BOS) - Create Bucket
Example:
- Bucket name: cce-bos-test
2.2 Obtain the AccessKey and SecretKey of the Baidu AI Cloud user
For more information about AK and SK, refer to: How to Obtain AK and SK
2.3 Confirm the environment
-
Source cluster:
- Region: Beijing
- Alibaba Cloud ACK cluster ID
-
Backup to BOS:
- Bucket: cce-bos-test (example)
-
Target cluster:
- Region: Beijing
- Baidu AI Cloud CCE cluster ID
2.4 Install the Velero command-line interface and server
2.4.1 Install the Velero command-line interface
Method 1: macOS - Homebrew
On macOS, you can use Homebrew in the terminal to install the Velero client:
brew install velero
Method 2: GitHub release
- Download the compressed package matching your platform from the Velero Release Page
- Unzip the compressed package
tar -xvf <RELEASE-TARBALL-NAME>.tar.gz
- Move the extracted Velero binary file to a path included in your $PATH environment variable (e.g., /usr/local/bin)
Method 3: Windows - Chocolatey
On the Windows platform, you can use Chocolatey in the terminal to install the Velero client.
choco install velero
2.4.2 Install CCE-Backup-Controller in Alibaba Cloud ACK
We mainly use Helm to install the Velero server.
Step 1: Download the CCE-Backup-Controller Helm Chart and unzip it
Step 2: Push the images in the CCE-Backup-Controller Helm Chart to Alibaba Cloud Container Registry. Alibaba Cloud Container Registry is used as the example in the following content.
Image list:
1registry.baidubce.com/cce-plugin-pro/velero:v1.13.5
2registry.baidubce.com/cce-plugin-pro/velero-plugin-baiducloud:0.6
3registry.baidubce.com/cce-plugin-pro/kubectl:1.24.9After pushing to Alibaba Cloud Container Registry, the image list is:
1registry-vpc.cn-beijing.aliyuncs.com/velero-test/velero:v1.13.5
2registry-vpc.cn-beijing.aliyuncs.com/velero-test/velero-plugin-baiducloud:0.6
3registry-vpc.cn-beijing.aliyuncs.com/velero-test/kubectl:1.24.9Step 3: Configure the CCE-Backup-Controller Chart
Before installing and deploying the Velero server, you need to correctly configure the Velero Helm Chart, that is, edit the values.yaml file in the Chart properly.
- Replace core images. To smoothly pull the core images in the Velero Helm Chart in a CCE environment without Internet access, you need to modify the image addresses in values.yaml
- Replace registry.baidubce.com/cce-plugin-pro/velero:v1.13.2 with registry-vpc.cn-beijing.aliyuncs.com/velero-test/velero:v1.13.2
- Replace registry.baidubce.com/cce-plugin-pro/velero-plugin-baiducloud:0.6 with registry-vpc.cn-beijing.aliyuncs.com/velero-test/velero-plugin-baiducloud:0.6
- Replace registry-vpc.cn-beijing.aliyuncs.com/velero-test/kubectl:1.24.9 with registry-vpc.cn-beijing.aliyuncs.com/velero-test/kubectl:1.24.9 After modification, the sample YAML is as follows:
1# Details of the container image to use in the Velero deployment & daemonset (if
2# enabling node-agent). Required.
3image:
4 repository: registry-vpc.cn-beijing.aliyuncs.com/velero-test/velero
5 tag: v1.13.2
6 # Digest value example: sha256:d238835e151cec91c6a811fe3a89a66d3231d9f64d09e5f3c49552672d271f38.
7 # If used, it will take precedence over the image.tag.
8 # digest:
9 pullPolicy: IfNotPresent
10 # One or more secrets to be used when pulling images
11 imagePullSecrets: []
12 # - registrySecretName
13
14kubectl:
15 image:
16 repository: registry-vpc.cn-beijing.aliyuncs.com/velero-test/kubectl
17 tag: 1.24.9
18 # Digest value example: sha256:d238835e151cec91c6a811fe3a89a66d3231d9f64d09e5f3c49552672d271f38.
19 # If used, it will take precedence over the kubectl.image.tag.
20 # digest:
21 # kubectl image tag. If used, it will take precedence over the cluster Kubernetes version.
22 # tag: 1.16.15- Add the Baidu AI Cloud Velero plugin. To seamlessly save cluster backup files to Baidu AI Cloud BOS, CCE provides a Velero plugin. This configuration should be added to the initContainer configuration. After modification, the sample YAML is as follows:
1initContainers:
2 - name: velero-plugin-baiducloud
3 image: hub.baidubce.com/jpaas-public/velero-plugin-baiducloud:v0.3
4 imagePullPolicy: IfNotPresent
5 env:
6 - name: BAIDU_CLOUD_CREDENTIALS_FILE
7 value: "/credentials/cloud"
8 volumeMounts:
9 - mountPath: /target
10 name: plugins
11 - mountPath: /credentials
12 name: cloud-credentials- Set up Baidu AI Cloud BOS access credentials. Note:
- Replace <BAIDU_CLOUD_ACCESS_KEY_ID> and <BAIDU_CLOUD_SECRET_ACCESS_KEY> with the actual AccessKey and SecretAccessKey of Baidu AI Cloud obtained in Step 2.2;
- Replace <BAIDU_CLOUD_BOS_ENDPOINT> with the BOS service domain name of your region. For the BOS service domain names in various regions, see: Baidu Object Storage (BOS) - Obtain Access Domain Names
1credentials:
2 # Whether a secret should be used. Set to false if, for examples:
3 # - using kube2iam or kiam to provide AWS IAM credentials instead of providing the key file. (AWS only)
4 # - using workload identity instead of providing the key file. (Azure/GCP only)
5 useSecret: true
6 # Name of the secret to create if `useSecret` is true and `existingSecret` is empty
7 name: baidu-bos-credentials
8 # Name of a pre-existing secret (if any) in the Velero namespace
9 # that should be used to get IAM account credentials. Optional.
10 existingSecret:
11 # Data to be stored in the Velero secret, if `useSecret` is true and `existingSecret` is empty.
12 # As of the current Velero release, Velero only uses one secret key/value at a time.
13 # The key must be named `cloud`, and the value corresponds to the entire content of your IAM credentials file.
14 # Note that the format will be different for different providers, please check their documentation.
15 # Here is a list of documentation for plugins maintained by the Velero team:
16 # [AWS] https://github.com/vmware-tanzu/velero-plugin-for-aws/blob/main/README.md
17 # [GCP] https://github.com/vmware-tanzu/velero-plugin-for-gcp/blob/main/README.md
18 # [Azure] https://github.com/vmware-tanzu/velero-plugin-for-microsoft-azure/blob/main/README.md
19 secretContents:
20 cloud: |
21 BAIDU_CLOUD_BOS_ENDPOINT=<BAIDU_CLOUD_BOS_ENDPOINT>
22 BAIDU_CLOUD_ACCESS_KEY_ID=<BAIDU_CLOUD_ACCESS_KEY_ID>
23 BAIDU_CLOUD_SECRET_ACCESS_KEY=<BAIDU_CLOUD_SECRET_ACCESS_KEY>- Configure the backup storage location. This mainly involves specifying where to store the backup files. When using BOS, it allows you to backup cluster files to a designated bucket and directory within BOS. Note:
- Replace <BUCKET_NAME> with the name of the bucket you created in BOS
- Replace <CLUSTER_ID> with your ACK cluster ID
1# Source: cce-backup-controller/templates/backupstoragelocation.yaml
2apiVersion: velero.io/v1
3kind: BackupStorageLocation
4metadata:
5 name: default
6 namespace: cce-backup
7 labels:
8 app.kubernetes.io/name: cce-backup-controller
9 app.kubernetes.io/instance: test-dhr
10 app.kubernetes.io/managed-by: Helm
11 helm.sh/chart: cce-backup-controller-1.1.3
12spec:
13 credential:
14 name: baidu-bos-credentials
15 key: cloud
16 provider: baiducloud
17 accessMode: ReadWrite
18 objectStorage:
19 bucket: "cce-bos-test"
20 prefix: "ceb93762c98b9496889487187c6423196"
21 config:
22 checksumAlgorithm: "SHA256"
23 region: "bj"
24 s3ForcePathStyle: "true"
25 s3Url: "https://s3.bj.bcebos.com"
26 signatureVersion: "AWS4-HMAC-SHA256"Execute the command:
1kubectl --kubeconfig={kubeconfig} apply -f bkp-location.yaml For other Velero-related configurations, refer to the official documentation and the configuration comments in the Helm Chart.
- https://velero.io/docs/v1.14/backup-reference/
- https://github.com/vmware-tanzu/helm-charts/blob/main/charts/velero/README.md
Step 3: Deploy and update CCE-Backup-Controller
Use the Helm command to deploy the Velero server.
1cd cce-backup-controller\nhelm --kubeconfig={kubeconfig} install cce-backup-controller . -n cce-backup --create-namespaceAfter modifying the values.yaml file each time, execute the following command to complete the update:
1helm upgrade cce-backup-controller . -n veleroVerify that the Velero server is running properly:
1kubectl -n cce-backup get pods
2# Result
3NAME READY STATUS RESTARTS AGE\nvelero-76b4d755f5-fzztr 1/1 Running 0 49mStep 4: Create backup and restore tasks
- Create a backup task (command-line instruction)
1velero --kubeconfig {{kubeconfig-path}} backup create nginx-backup --include-namespaces default -n cce-backup
- Check whether the backup task is successful
1velero --kubeconfig {{kubeconfig-path}} -n cce-backup backup get
2.5 View backup data
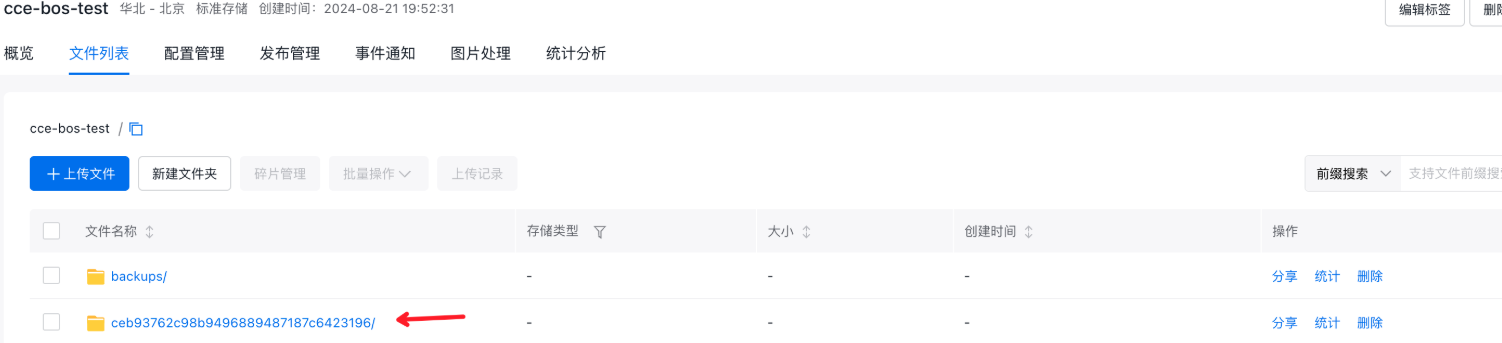
Log in to the BOS console and select your target bucket. In this example, the bucket name is cce-bos-test.
- View the bucket file list. The backup data of each cluster is stored in a separate folder, such as cce-bos-test/ceb93762c98b9496889487187c6423196
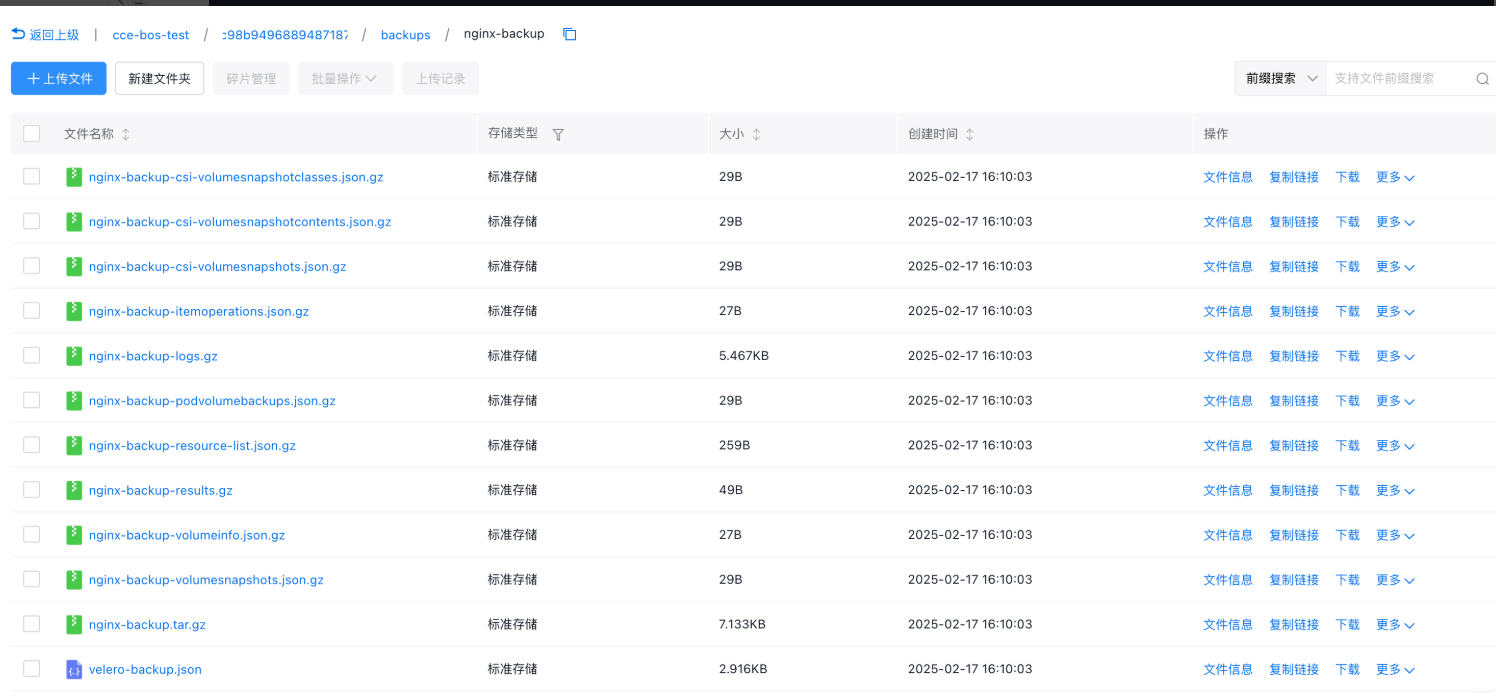
- View cluster backup information:
2.6 Backup restoration
Step 1: Migrate images to ensure that application images can be pulled in CCE
-
Method 1: Use the CCR image migration function to migrate ACK images to Baidu AI Cloud CCR
- After restoring and migrating the application to CCE, you need to manually modify the image to the CCR address;
- Method 2: Modify the ACK application images to be publicly accessible, and enable public network access for the nodes in the target CCE cluster
Step 2: In the target CCE cluster for restoration, install CCE-Backup-Controller through the component center
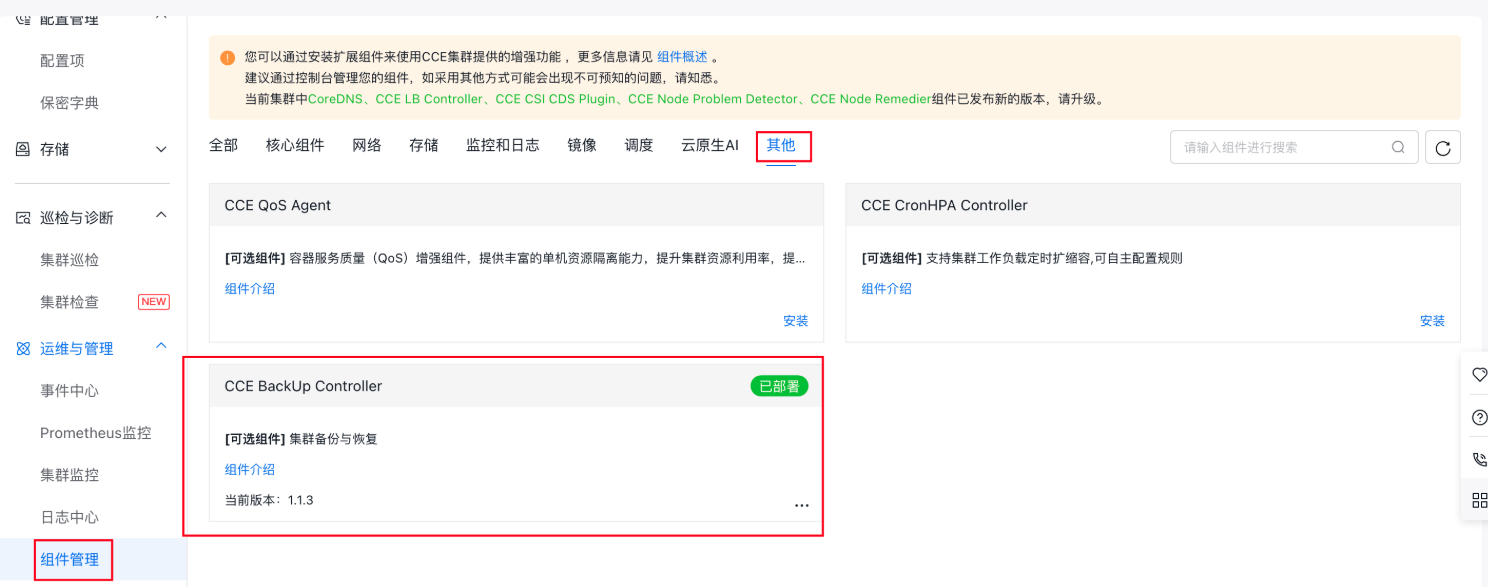 Step 3: Create a backup repository through the command line
Step 3: Create a backup repository through the command line
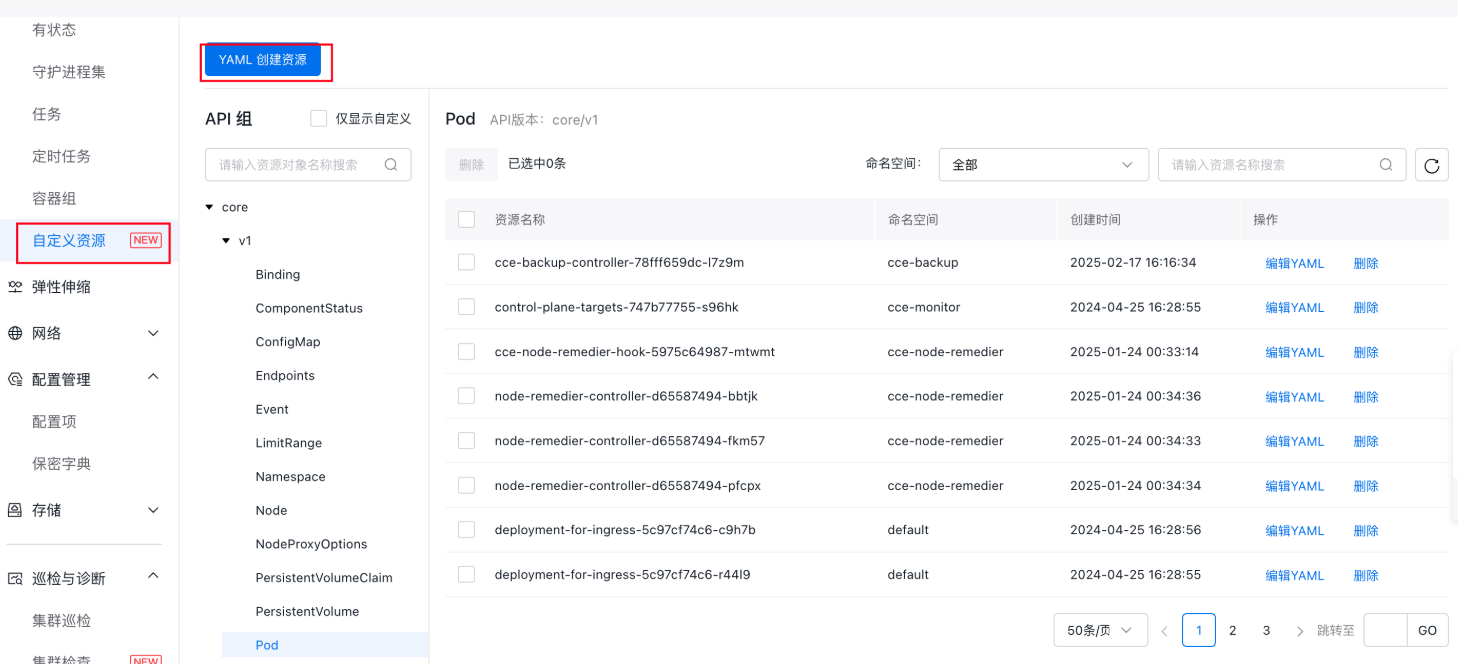
1# Source: cce-backup-controller/templates/backupstoragelocation.yaml
2apiVersion: velero.io/v1
3kind: BackupStorageLocation
4metadata:
5 name: default
6 namespace: cce-backup
7 labels:
8 app.kubernetes.io/name: cce-backup-controller
9 app.kubernetes.io/instance: test-dhr
10 app.kubernetes.io/managed-by: Helm
11 helm.sh/chart: cce-backup-controller-1.1.3
12spec:
13 credential:
14 name: baidu-bos-credentials-bj
15 key: cloud
16 provider: baiducloud
17 accessMode: ReadWrite
18 objectStorage:
19 bucket: "cce-bos-test"
20 prefix: "ceb93762c98b9496889487187c6423196"
21 config:
22 checksumAlgorithm: "SHA256"
23 region: "bj"
24 s3ForcePathStyle: "true"
25 s3Url: "https://s3.bj.bcebos.com"
26 signatureVersion: "AWS4-HMAC-SHA256"Step 4: Execute the backup restoration command
1velero --kubeconfig {{restore-cluster-kubeconfig-path}} restore create --from-backup nginx-backup -n cce-backupStep 5: Confirm that the application is running properly and the relevant configurations are migrated correctly
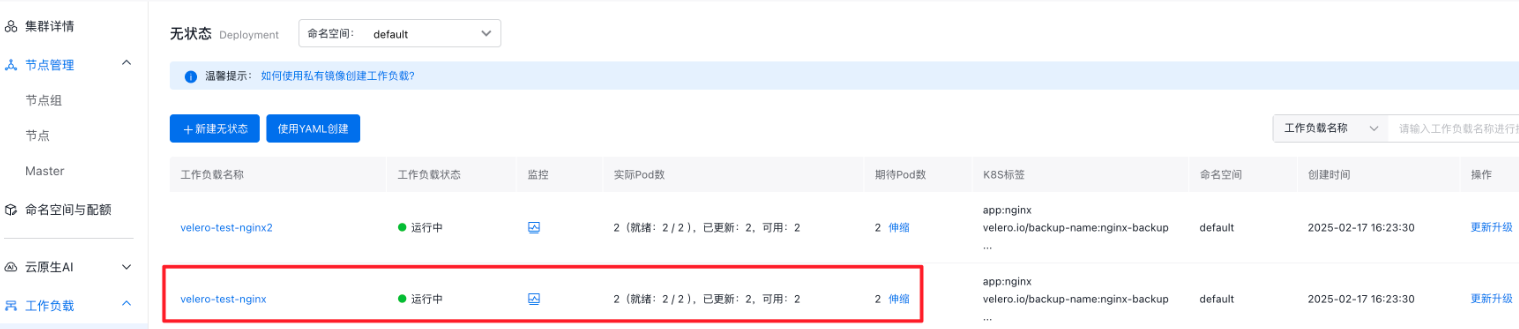
Application images:
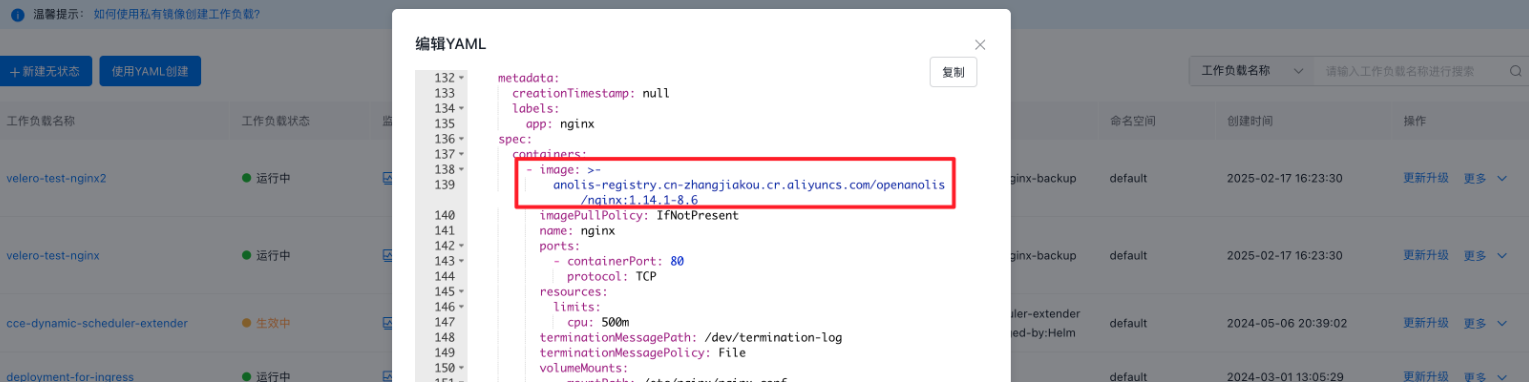
Configuration items: