
Replication Delay Resulted from the MySQL Table Without a Primary Key
Background
In the production environment, the following case frequently occurs: the customers update or delete massive data in a table without index on the master instance. If master and slave adopt ROW mode for replication, the master database (called the master)needs to scan the full table just one time. However, the slave database or known as the slave needs to do one full table scan against every row of data that is influenced by the master database. That process usually leads to the slave's overly long synchronous delay and is intolerable for services.
MySQL 5.6.6 introduces the parameter "slave_rows_search_algorithms" to indicate the algorithm used in the read-only instance's "apply_binlog_event". That, to some extent, helps resolve (alleviate) the synchronous delay. The following focuses on the introduction of this parameter's principle and usage.
Failure Phenomenon
Online scenarios
-
Master instance configurations:
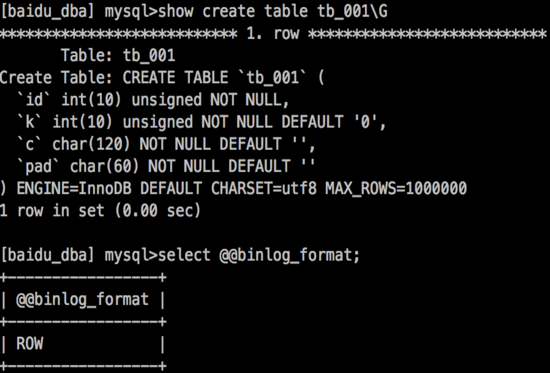
-
Read-only instance configurations:
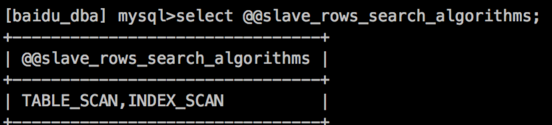
-
Execute master instance:

Read-only instance in synchronous delay, with trend chart as follows:
Influence of "slave_rows_search_algorithms" parameter
-
Master instance's table structure:
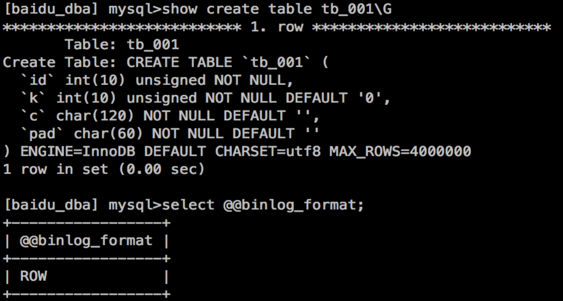
Of which, table tb_001 contains 4 million pieces of data.
-
Master instance executes SQL:
Update tb_001 set k=k+12345 limit {$LIMIT_NUM};
-
Test result -read-only instance's maximum delay time:
Number of rows updated TABLE_SCAN,INDEX_SCAN TABLE_SCAN,INDEX_SCAN,HASH_SCAN 10000 28s 4s 20000 144s 17s 30000 325s 35s 40000 576s 64s From the test result, you can see that if with the parameter "slave_rows_search_algorithms" modified and "HASH_SCAN" added in the parameter, synchronous delay of the tables without primary key and other indexes is alleviated to a large extent.
Analysis of cause
First, provided that "binlog_format_image" adopts the default value "FULL", "before_image" and "after_image" of all actions are recorded in event. slave_rows_search_algorithms
The default value is "TABLE_SCAN,INDEX_SCAN". Now, we make further analysis.
With primary key or unique index
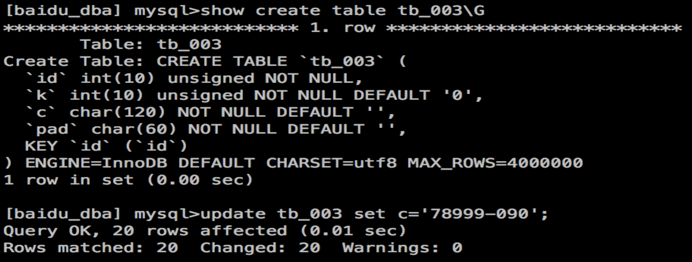
Table structure in test and "update" statement in execution:
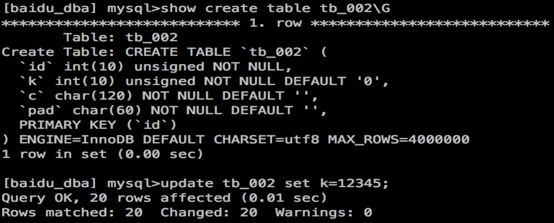
As to this "update" statement: in execution, the master first adopts the primary key and conducts just one index location, and then update the follow-up data via sequential scanning. See the figure for the general flow :
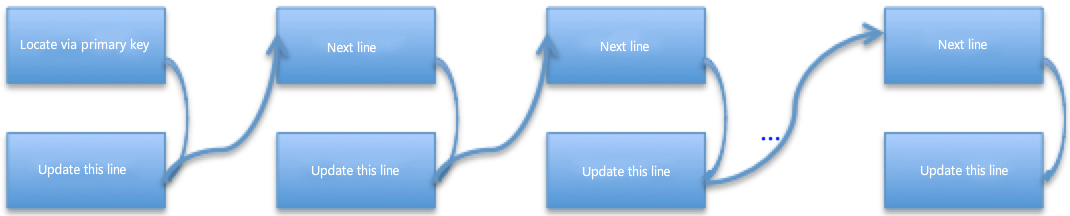
"before_image" parameters of 20 pieces of data updated by current SQL are all recorded in "Update_rows_event". When using the parameters, the slave reassesses the indexes and gives priority to the primary key and the unique key. Since there is a primary key in the tested table, during the execution, the slave needs to locate every piece of data in the "Event" against the specific row via the primary key before updateing the corresponding row.
As for the master, it conducts just one data location, but the slave needs to do one data location to all rows influenced, but there is a primary key (or unique index) on the table, which helps minimize the slave's data location cost.
Without primary key and unique index
Table structure in test and "update" statement:
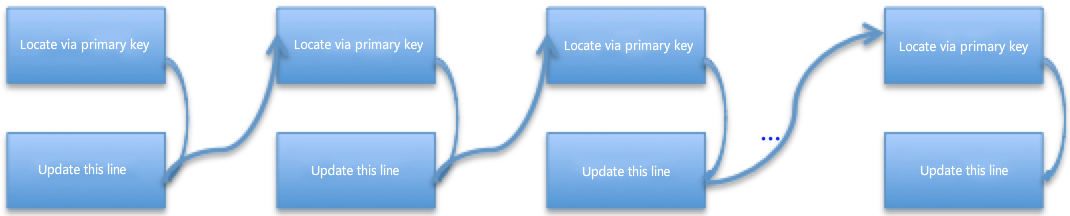
As for this "update" statement, to update 20 pieces of data, the master first conducts one-off positioning by using index key and then updates the follow-up data rows in sequence. See the figure for the general flow :
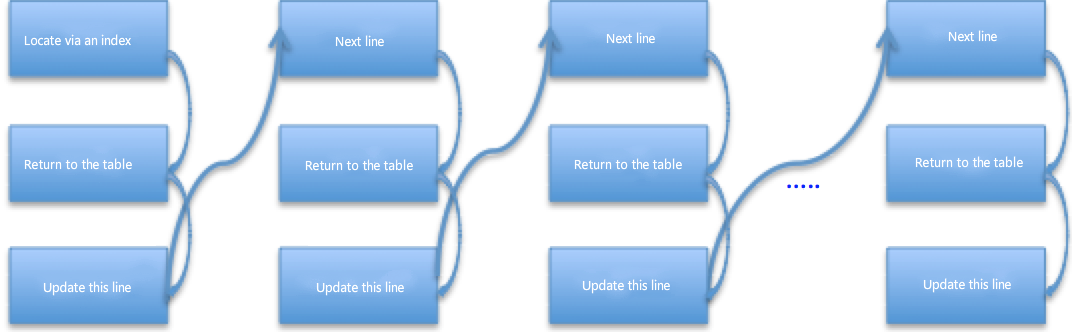
"before_image" parameters of 20 pieces of data updated by current SQL are all recorded in "Update_rows_event". When using the parameters, the slave reassesses the indexes and gives priority to the primary key and the unique key. Since the table has only one common index key, every piece of data in the "Event" needs to be subject to index location. As for the non-unique index, the first-row data returned for the first time is probably not the deleted data, and the next row can be further scanned. See the figure for the general flow :
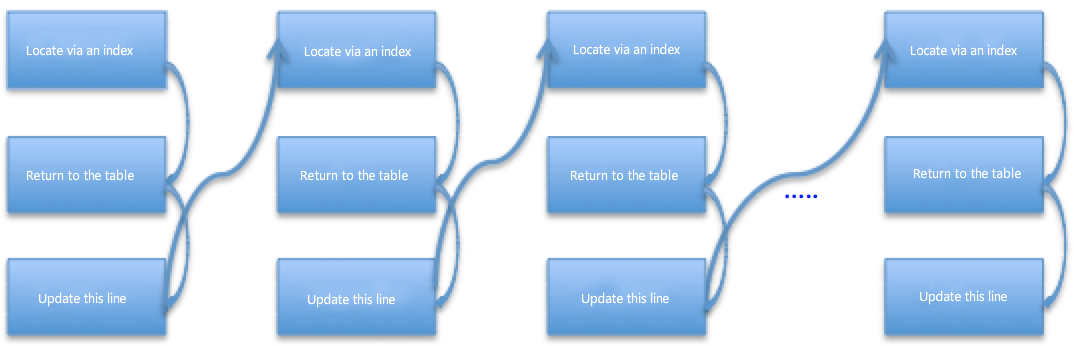
If there is no index on the table, every event executed by the slave must be subject to a full table scan. Thus, the cost is huge. That is the key cause for the slave's relatively long synchronous delay if there is no index on the table. See the figure for the general flow :
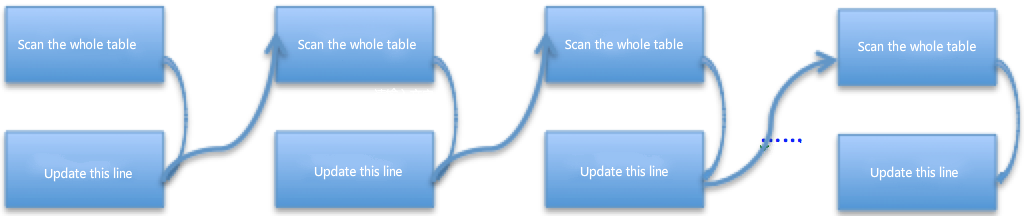
Optimization without index
"slave_rows_search_algorithms" has four portfolios:
- The default value is "TABLE_SCAN,INDEX_SCAN".
- INDEX_SCAN,HASH_SCAN
- TABLE_SCAN,HASH_SCAN
- TABLE_SCAN,INDEX_SCAN,HASH_SCAN(the same as INDEX_SCAN,HASH_SCAN)
Parameter portfolio, Decision table:
- I --> Index scan / search
- T --> Table scan
- Hi --> Hash over index
-
Ht --> Hash over the entire table
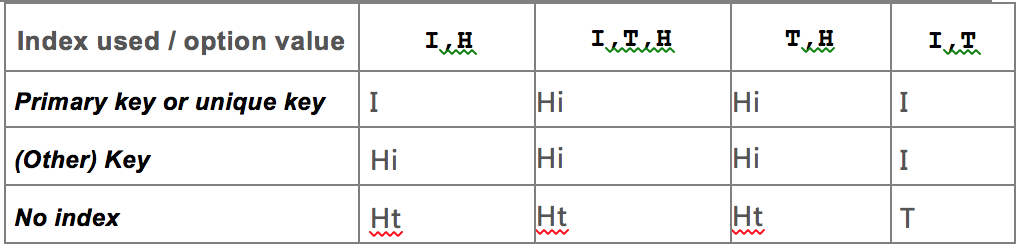
- Default value "TABLE_SCAN, INDEX_SCAN" means that if there is an available index, the index-based search is recommended, or a full table scan is the first choice. INDEX_SCAN means that if there is an available index, the index-based search is recommended. TABLE_SCAN means that on the premise of no index or "HASH_SCAN", a full table scan is the first choice.
- Read-only instance location data options include "INDEX_SCAN", "HASH_SCAN", and "TABLE_SCAN", with priority level in descending order. If there is a primary key or index, "INDEX_SCAN" is recommended. If there is no primary key, HASH_SCAN or TABLE_SCAN is recommended (if both of them exist, HASH_SCAN prevails).
Source code: sql/ log_event.cc
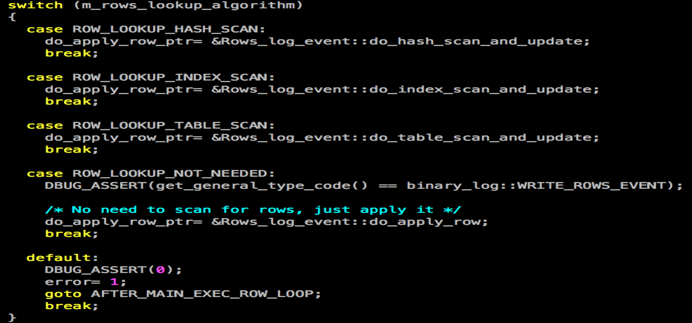
Herein, we only focus on "ROW_LOOKUP_HASH_SCAN", which includes two data search methods:
- Hi --> Hash over index
- Ht --> Hash over the entire table
When the read-only instance "apply rows_log_event" is executed. Every row of data in "log_event" is read, and updated and cached in two structures, namely, "m_hash" and "m_distinct_key_list". m_hash: it is a Hash table used in caching the start position of the updated row records; m_distinct_key_list: if there is index, the index value is pushed to "m_distinct_key_list" as the basis for index scan, namely, Hi (every "EVENT" queries the "m_distinct_key_list" for location). If there is no index on the table, this List structure is not used, and a full table scan is directly used, namely, Ht (every EVENT queries "m_hash" for location);
Special reminder: as for Hi --> Hash over index, if there are few data repetitions in every updating/deletion, a lot of index locations are still required. If there are a large number of data repetitions in each "update/delete" statement, it helps greatly reduce the index location cost.
Conclusions & suggestions
-
We recommend that every table has primary key or unique key. You may check if there is primary key in your database table by using the following SQL:
select table_schema,table_name,engine from information_schema.tables where (table_schema,table_name) not in( select distinct table_schema,table_name from information_schema.columns where COLUMN_KEY='PRI' ) and table_schema in ('${dblist}');
Herein, "${dblist}" is a database list divided by commas.
- Usage of the slave index is automatically determined, and the sequence is primary key ->unique key ->common index. We recommend that the primary key or unique key is set for every table.
-
Even if you have set "HASH_SCAN", it does not mean definite performance improvement, and you need to meet one of the following preconditions.
- there is no index in the table.
2). There is an index in the table, but a lot of data key values are repetitive in the "update/delete" statement.
- In each "update/delete" statement, only a small number of data are modified (for example, one row of data is modified in each statement). That does not improve performance improvement.
- You are advised to set the default value of the online environment "slave_rows_search_algorithms" as "INDEX_SCAN,HASH_SCAN" (changed into default value after 8.0.2).
- If "HASH_SCAN" is not set for the "slave_rows_search_algorithms" parameter and there is no primary key/unique key, the performance is bound to decline sharply, bringing about delay. If there is no index, this problem becomes more serious, for changed data of every row triggers one full table scan.