
Streaming Application Scenario
Scenarios Description
This scenario is used for data streaming processing, and BLS (Baidu Log Service), BMS (Baidu Messaging System), and BMR (Baidu MapReduce) are used.
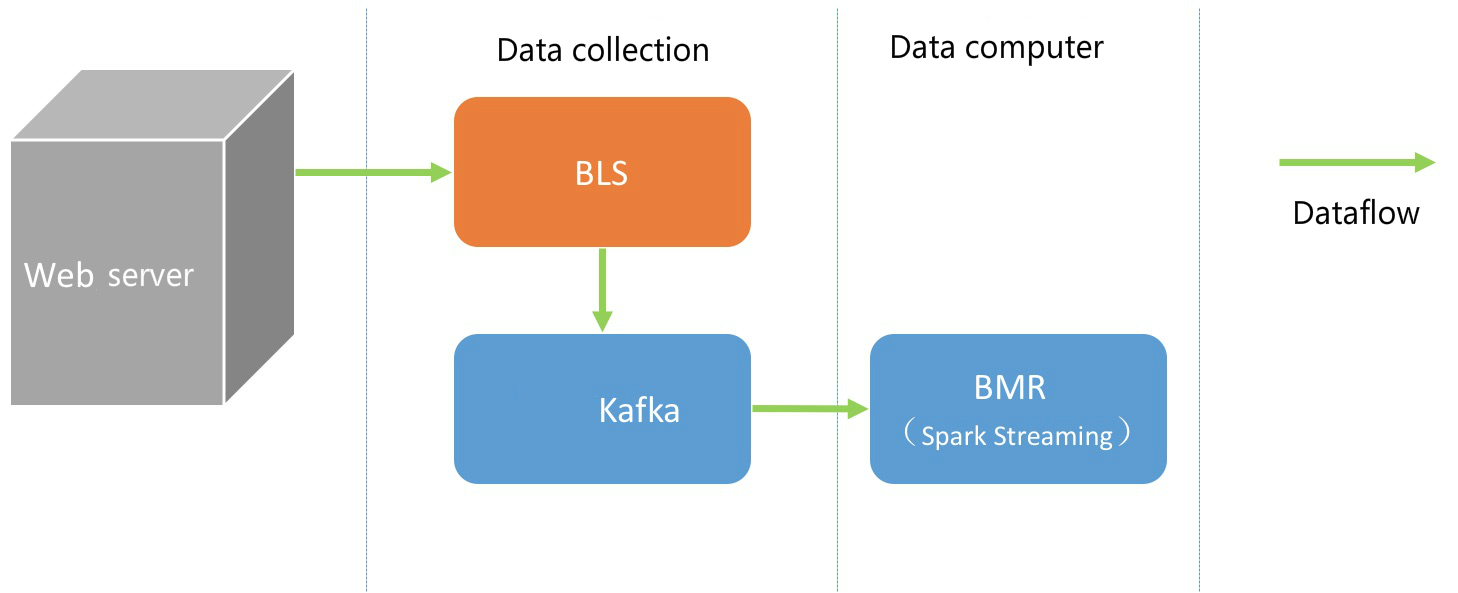
The whole process consists of data collection and data computing.
Data Collection
Data collection is realized via the BLS and Baidu Messaging System (BMS).
Step 1 Create BMS Topic
For more information, please see the documentation: Create BMS Topic.
Currently, BMS supports “North China - Beijing”, “South China - Guangzhou” and “Hong Kong region 2” regions. Before creating a topic, you can select different regions as needed.
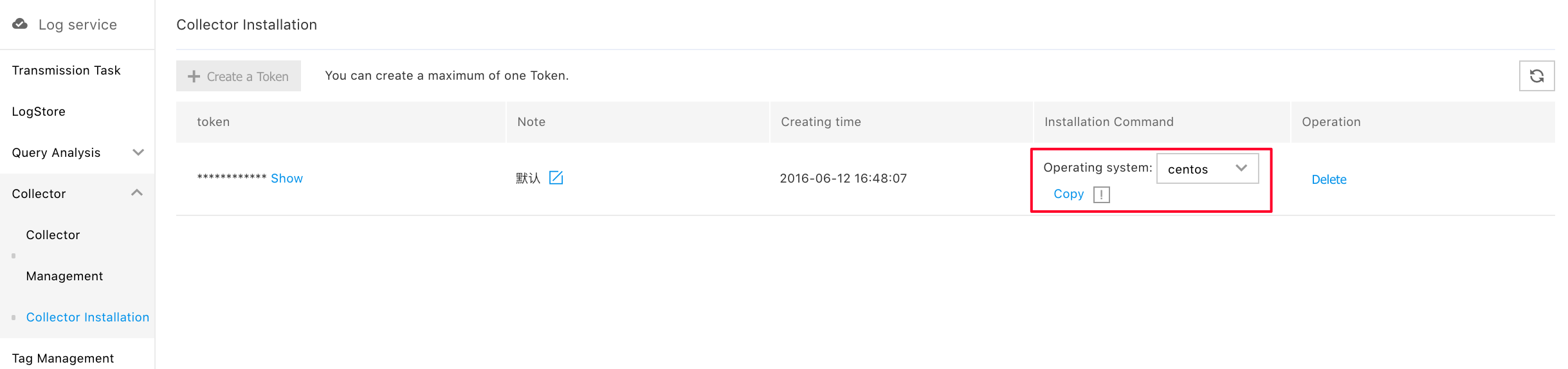
Step 2 Install BLS Collector
For more information, please see the documentation Install Collector.
-
Select "Install Collector", and click "Copy" after selecting the operating system;
-
Log in to the CVM server, which needs log transmission, and execute "Copy" installation command under root privilege.

Step 3 Create BLS Transmission Task
The specific steps are as follows:
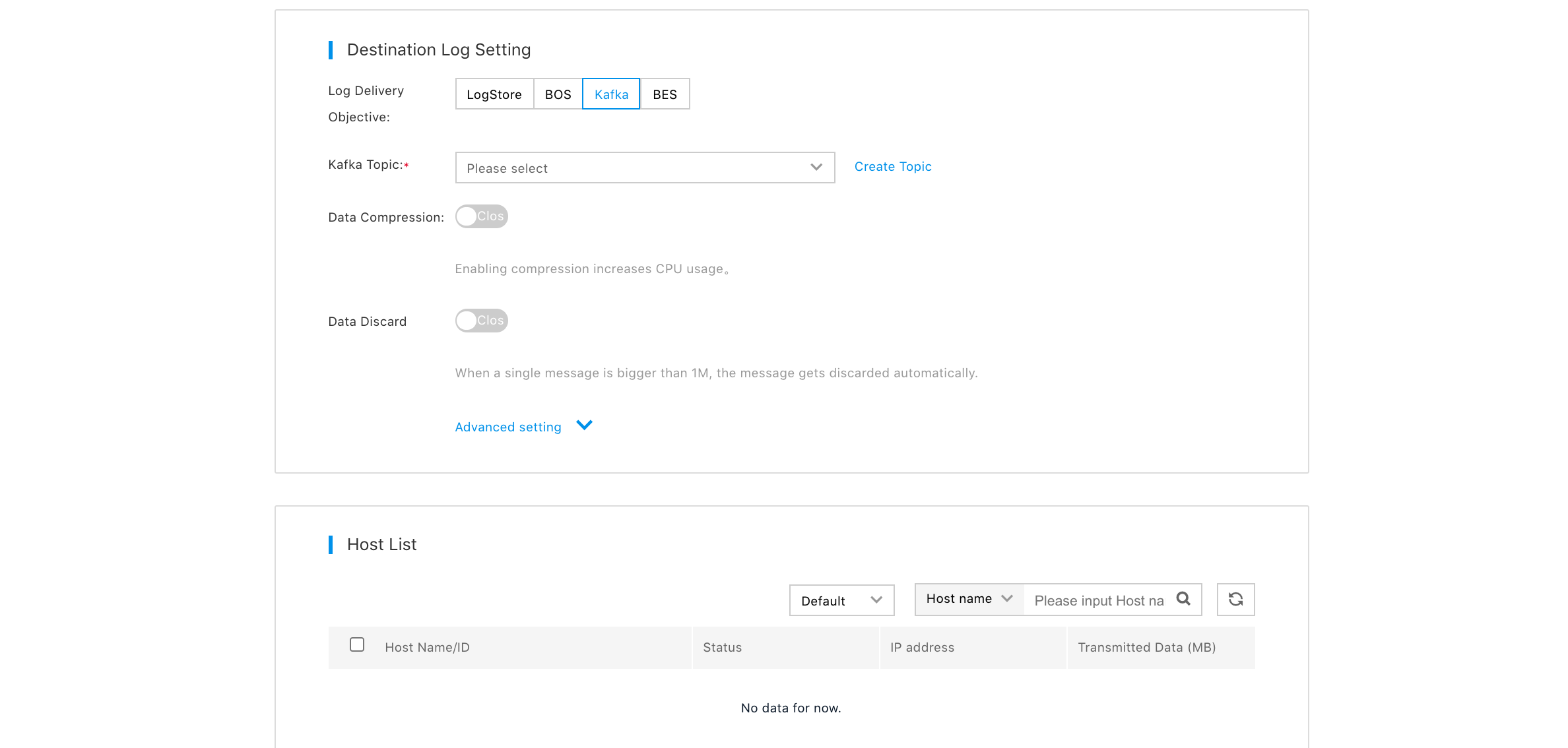
- In the transmission task list page, click "Create Transmission Task" to enter the page of creating transmission task;
- Enter task name in "Task Information" section;
- In "Source Setup" section, select and configure source types according to types of source data;
- In "Destination Setup" section, select "Kafka" as log delivery destination;
- In "CVM Server List" section, click "Add CVM Server", and select CVM server with "Collector" installed;
- In "CVM Server List" section, select CVM server which needs to deploy transmission task, and click "Create";
For operating steps, please see the documentation: Create Transmission Task.
Currently, BMS supports “North China - Beijing” and “South China - Guangzhou” regions. Before creating a topic, you can select different regions as needed.
Data Computing (Python)
The data computing process is connected to Baidu Messaging System through BMR’s Spark Streaming. The use of PySpark (Spark version 1.6 and on-line Kafka version 0.10) is taken as an example. The specific steps are as follows:
Step 1 Create BMR Spark Cluster
For more information, please see the documentation: Create Cluster
Note: In "Cluster Configuration" section, select "Spark" built-in template, and check Spark.
Step 2 Download Spark Kafka Streaming Dependency
# obtain eip from instance list in BMR Console cluster details page
ssh root@eip
# switch to hdfs user
su hdfs
cd
# download dependency
wget http://bmr-public-bj.bj.bcebos.com/sample/spark-streaming-kafka-0-10-assembly_2.10-1.6.0.jarRemarks
Obtain cluster login public IP.
Step 3 Write Spark Streaming Program
Taking Kafka_wordcount for example, please delete annotation before use:
from __future__ import print_function
import sys
import ConfigParser
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.kafka010 import KafkaUtils
from pyspark.streaming.kafka010 import PreferConsistent
from pyspark.streaming.kafka010 import Subscribe
# read configuration files
def read_config(file_name):
cf = ConfigParser.ConfigParser()
# read config file
cf.read(file_name)
# read kafka config
section = "kafka"
opts = cf.options(section)
config = {}
for opt in opts:
# topics should be a list
if opt == "topics":
config[opt] = str.split(cf.get(section, opt), ",")
else:
config[opt] = cf.get(section, opt)
return config
if __name__ == "__main__":
"""
if len(sys.argv) != 3:
print("Usage: kafka_wordcount.py <bootstrap-server> <topic>", file=sys.stderr)
exit(-1)
"""
# build SparkContext and StreamingContext, and demo processing interval is 20s
sc = SparkContext(appName="PythonStreamingKafkaWordCount")
ssc = StreamingContext(sc, 20)
# read configuration file test.conf, and obtain Baidu Kafka connection parameters
config_file = "test.conf"
kafkaParams = read_config(config_file)
# build kafka input stream
topics = kafkaParams["topics"]
kvs = KafkaUtils.createDirectStream(ssc, PreferConsistent(), Subscribe(topics, kafkaParams))
lines = kvs.map(lambda x: x[1])
counts = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a+b)
counts.pprint()
# enable StreamingContext
ssc.start()
ssc.awaitTermination()Step 4 Download BMS Certificate
Download the certificate.
Step 5 Create Kafka Connection Configuration Files
Take “test.conf” as an example:
vi test.conf
# write following content
[kafka]
bootstrap.servers = kafka.bj.baidubce.com:9091
topics = test_for_demo
group.id = test
# the following SSL configuration is replaced according to content of client.properties
security.protocol = SSL
ssl.truststore.password = test_truststore_password
ssl.truststore.location = client.truststore.jks
ssl.keystore.location = client.keystore.jks
ssl.keystore.password = test_keystore_passwordParameter Description:
bootstrap.servers: kafka service address
topics: Topics to consume are separated with commas, for example, topic1, topic2, and topic3
group.id: To avoid conflict with other users, you cannot set the consumer group’s id at random, and kafka service supports groupId isolation in the future.For more configurations, please see:http://kafka.apache.org/0100/documentation.html#newconsumerconfigs
Step 6 Submit Streaming Steps
Based on above four steps, the current directory (hdfs home directory) has five files: test.conf, client.truststore.jks, client.keystore.jks, kafka_wordcount.py, and spark-streaming-kafka-0-10-assembly_2.10-1.6.0.jar:

Use spark-submit to submit streaming step:
/usr/bin/spark-submit --master yarn --deploy-mode cluster --files test.conf,client.keystore.jks,client.truststore.jks --jars spark-streaming-kafka-0-10-assembly_2.10-1.6.0.jar kafka_wordcount.pyStep 7 Show Step Outputs
In "Cluster Details Page", click "Hadoop Yarn Web UI" to open yarn console:
In the yarn console, you can see application logs to view the program’s output. Taking kafka_wordcount for example, you can check output in stdout:
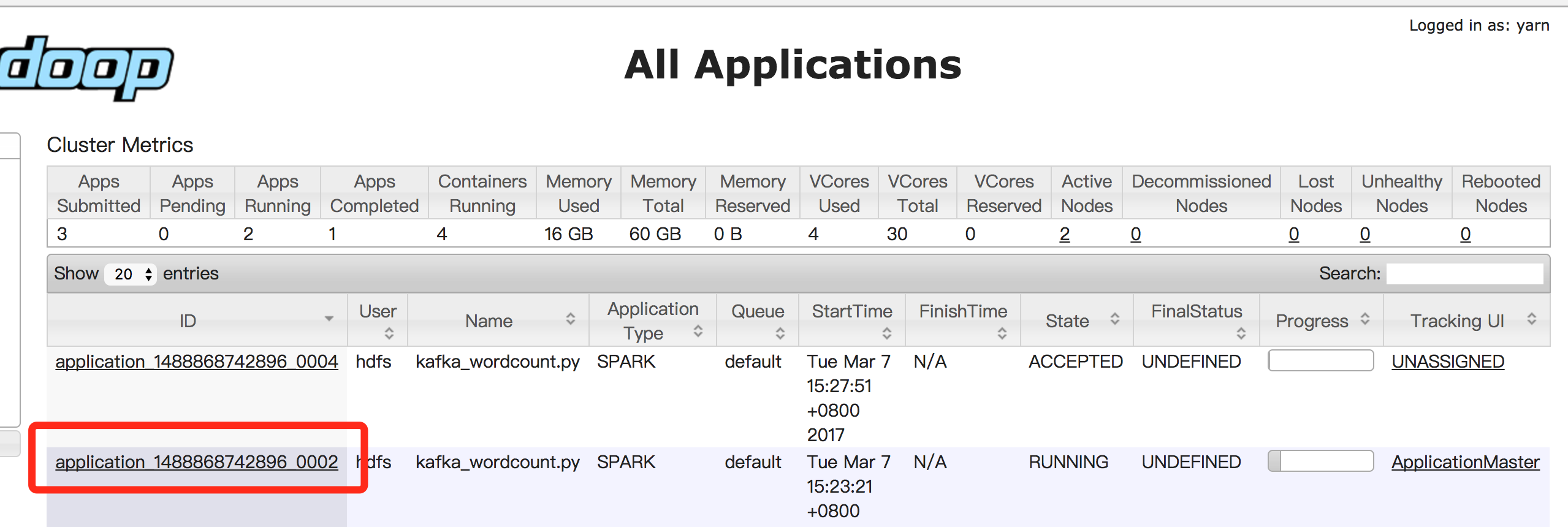
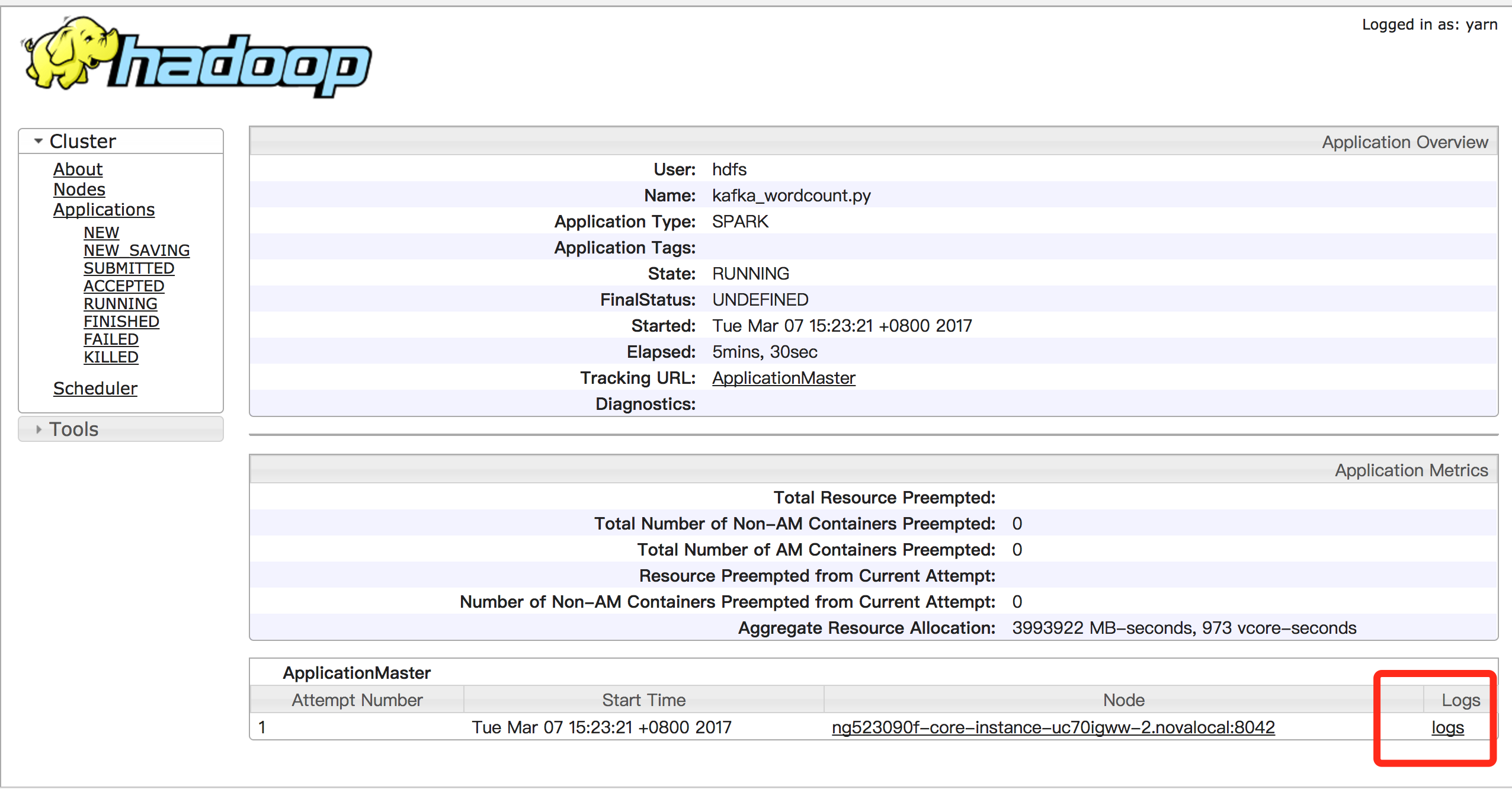
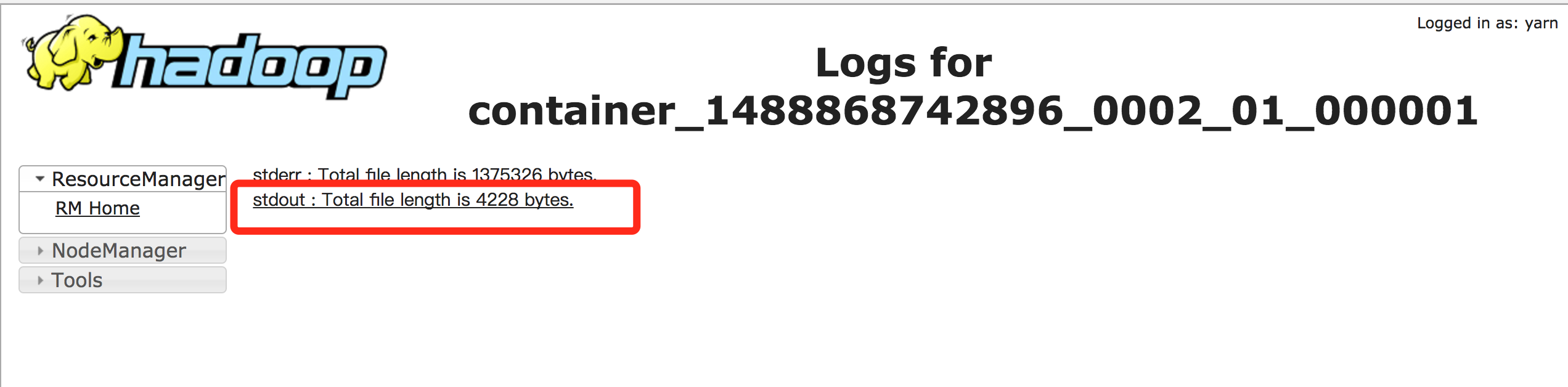

Notes
-
In case of stopping any step, you can use “yarn application -kill applicationId” command, for example:
yarn application -kill application_1488868742896_0002
- If multiple steps are running, you need to modify group.id configuration in test.conf
Data Computing (Scala)
The data computing process is connected to Baidu Messaging System (BMS) through BMR’s Spark Streaming. The use of Scala (Spark version 2.1 and on-line Kafka version 0.10) is taken as an example. The specific steps are as follows:
Step 1 Create BMR Spark Cluster
For more information, please see the documentation: Create Cluster
Note: In "Cluster Configuration" section, select "Spark2" built-in template, and check Spark.
Step 2 Download Spark Kafka Streaming Dependency
# obtain eip from instance list in BMR Console cluster details page
ssh root@eip
# switch to hdfs user
su hdfs
cd
# download dependency
wget https://bmr-public-bj.bj.bcebos.com/sample/original-kafke-read-streaming-1.0-SNAPSHOT.jarStep 3 Download BMS Certificate
Download the certificate.
Step 4 Create Kafka Connection Configuration Files
Take “test.conf” for example:
vi test.conf
# write following content
[kafka]
bootstrap.servers = kafka.bj.baidubce.com:9091
topics = test_for_demo
group.id = test
# the following SSL configuration is replaced according to content of client.properties
security.protocol = SSL
ssl.truststore.password = test_truststore_password
ssl.truststore.location = client.truststore.jks
ssl.keystore.location = client.keystore.jks
ssl.keystore.password = test_keystore_passwordParameter Description:
bootstrap.servers: kafka service address
topics: Topics to consume are separated with commas, for example, topic1, topic2, and topic3
group.id: To avoid conflict with other users, you cannot set the consumer group’s id at random, and kafka service supports groupId isolation in the future.For more configurations, please see:http://kafka.apache.org/0100/documentation.html#newconsumerconfigs
Step 5 Submit Streaming Steps
Based on the above four steps, the current directory has four files: test.conf, client.truststore.jks, client.keystore.jks and

Use spark-submit to submit streaming step:
spark-submit --class com.baidu.inf.spark.WordCount --master yarn --deploy-mode cluster --files test.conf,client.keystore.jks,client.truststore.jks ./original-kafke-read-streaming-1.0-SNAPSHOT.jar "$topics" "$bootstrap.servers" "$group.id" "$ssl.truststore.password" "$ssl.keystore.password"(Note: Please replace last 5 parameter values in the command with actual values, i.e., fields described in test.conf)
Example:
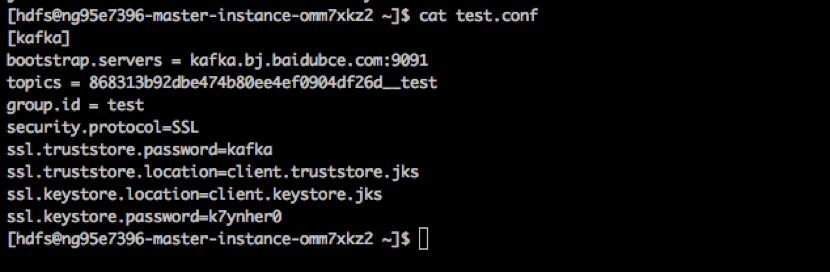
spark-submit --class com.baidu.inf.spark.WordCount --master yarn --deploy-mode cluster --files test.conf,client.keystore.jks,client.truststore.jks ./original-kafke-read-streaming-1.0-SNAPSHOT.jar "868313b92dbe474b80ee4ef0904df26d__test" "kafka.bj.baidubce.com:9091" "test" "kafka" "k7ynher0"WordCount example code is provided here:
package com.baidu.inf.spark
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import org.apache.spark.streaming.{Seconds, StreamingContext}
object WordCount {
def className = this.getClass.getName.stripSuffix("$")
def main(args: Array[String]): Unit = {
if (args.length < 4) {
System.err.println(
s"Usage:Input Params: "
+ " <topic> "
+ " <bootstrap.servers> "
+ " <group.id> "
+ " <ssl.truststore.password>"
+ " <ssl.keystore.password>"
)
sys.exit(1)
}
val Array(topic, bootstrap, group,
truststore, keystore, _*) = args
val conf = new SparkConf().setAppName(className).setIfMissing("spark.master", "local[2]")
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val ssc = new StreamingContext(conf, Seconds(5))
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> bootstrap,
"key.deserializer" -> classOf[StringDeserializer].getName,
"value.deserializer" -> classOf[StringDeserializer].getName,
"group.id" -> group,
"auto.offset.reset" -> "latest",
"serializer.class" -> "kafka.serializer.StringEncoder",
"ssl.truststore.location" -> "client.truststore.jks",
"ssl.keystore.location" -> "client.keystore.jks",
"security.protocol" -> "SSL",
"ssl.truststore.password" -> truststore,
"ssl.keystore.password" -> keystore,
"enable.auto.commit" -> (true: java.lang.Boolean)
)
ssc.sparkContext.setLogLevel("WARN")
val topics = Array(topic)
// consume kafka data
val stream = KafkaUtils.createDirectStream[String, String](
ssc,
PreferConsistent,~~~~
Subscribe[String, String](topics, kafkaParams)
).map(record => record.value())
val counts = stream.flatMap(_.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.print()
ssc.start()
ssc.awaitTermination()
ssc.stop(true, true)
}
}Step 6 Show Step Outputs
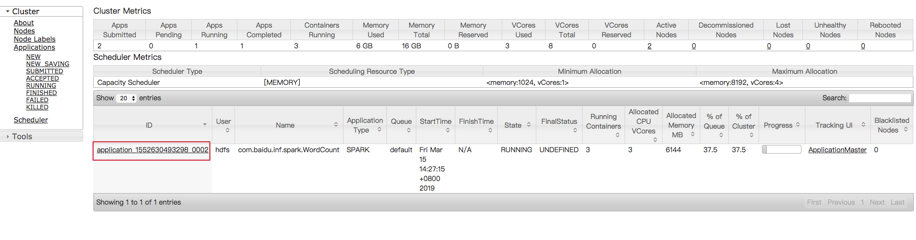
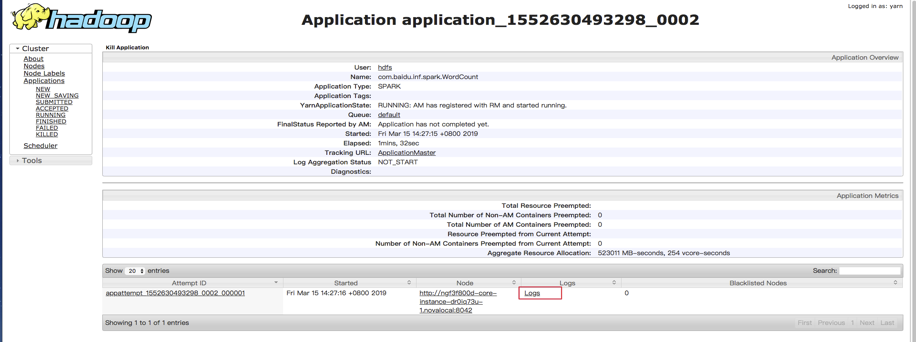
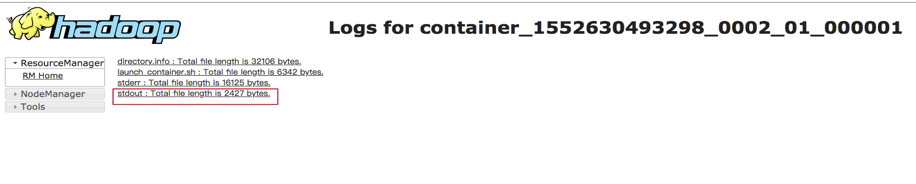
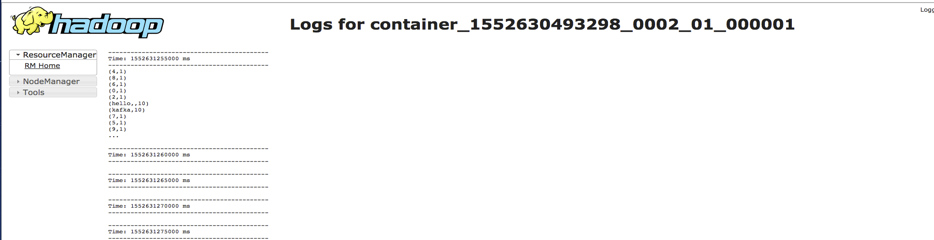
In "Cluster Details Page", click "Hadoop Yarn Web UI" to open yarn console:
In the yarn console, you can see application logs to view the program’s output. Taking kafka_wordcount for example, you can check output in stdout:
Notes
-
In case of stopping any step, you can use “yarn application -kill applicationId” command, for example:
yarn application -kill application_1488868742896_0002
- If multiple steps are running, you need to modify group.id configuration in test.conf