
Use OpenVPN to Submit Hadoop Steps
This section introduces how to use OpenVPN to submit Hadoop steps in Linux, Windows, and Mac OS X operating systems.
When using the client to submit steps, you need to set the environment variable “HADOOP_USER_NAME=hdfs” in the system, or you need to configure the MapReduce step, that is, to add the “System.setProperty("HADOOP_USER_NAME","hdfs")” to the first line of the program to submit steps as an hdfs user.
Linux
In the Linux operating system, use OpenVPN to submit Hadoop steps.
- Download the Hadoop Client. Download address: http://bmr.bj.bcebos.com/tools/hadoop/hadoop-2.6.0-SNAPSHOT.tar.gz.
- Download the Hadoop configuration files. Log in to the console, select “Product Service” -> “Baidu MapReduce-Cluster List”, enter the cluster list page, click the cluster name to enter the cluster details page, and click and download “hadoop-conf.zip” in the "Tools Download" section.
- Decompress the “hadoop-conf.zip”. Replace all files under “hadoop-2.6.0-SNAPSHOT/etc/hadoop/” with the configuration files in “conf”.
- The java path in configuration files is used in the hadoop script, and it can cause conflict with the client machine. If the client machine adds java to the path, you need to modify the bin/hadoop file:
cdto the directoryhadoop-2.6.0-SNAPSHOT/bin, execute the commandvi hadoop, and modifyexec $JAVA $JAVA_HEAP_MAX $HADOOP_OPTS $CLASS "$@"to beexec java $JAVA_HEAP_MAX $HADOOP_OPTS $CLASS "$@". -
Submit the hadoop step.
cdto the directoryhadoop-2.6.0-SNAPSHOT/binand executehadoop jar {jar file} {main class path} {parameters}. The hint of file compression class not existing indicates the image has no such class, and you need to find and delete the exceptional class in “io.compression.codecs” of core-site.xml.
Windows
How to use Eclipse to submit Hadoop steps via OpenVPN in the Windows operating system:
-
Configure the Hadoop Client.
- Hadoop Client download address: http://bmr.bj.bcebos.com/tools/hadoop/hadoop-2.6.0-SNAPSHOT.tar.gz. Download and decompress the file.
- Click https://github.com/srccodes/hadoop-common-2.2.0-bin/archive/master.zip to download. Download and decompress the file, and replace the files in “\hadoop-2.6.0-SNAPSHOT\bin\” with the files in “\hadoop-common-2.2.0-bin-master\bin\”.
Notes:
If the jdk is 1.8 for the system and 1.7 for the cluster, the exception of version conflict can occur after the step is packed and submitted. You must uninstall java1.8, and then download and install the version 1.7.
-
Configure the Hadoop configuration files.
- Log in to the console, select “Product Service” -> “Baidu MapReduce-Cluster List”, enter the cluster list page, click the cluster name to enter the cluster details page, and click and download “hadoop-conf.zip” in the "Tools Download" section.
-
After the decompression, add the following code to mapred-site.xml to ensure the system consistency:
mapred.remote.os Linux mapreduce.app-submission.cross-platform true
-
Select any of the following ways to create a project.
-
Create a general java project:
- Copy all files in the configuration file “conf” to the “src”.
-
Copy the following files under the directory “etc/share” of Hadoop Client to the dependency: mapreduce/*.jar;mapreduce/lib/*.jar;hdfs/*.jar;hdfs/lib/*.jar;yarn/*.jar;yarn/lib/*.jar;common/*.jar;
common/lib/*.jar.
-
Create a Maven project:
- Copy all files in the configuration file “conf” to the “/main/resources”.
- Configure hadoop-hdfs, hadoop-common, hadoop-mapreduce-client-core, hadoop-mapreduce-client-common and hadoop-mapreduce-client-jobclient in the pom.xml. The version must be the same as that of the cluster.
-
-
Write the main function. The main function needs to configure hadoop image path and step file location. For the main function, you can refer to the following code:
public static void main(String[] args) throws Exception { String hadoop_home = “”;//hadoop mirror path String jar_path = “”; String input_path = “”; String output_path = “”; String job_name = “”;
System.setProperty("hadoop.home.dir", hadoop_home);
Configuration conf = new Configuration(); conf.set("mapreduce.job.jar", jar_path);
Job job = new Job(conf, job_name); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class);
job.setMapperClass(Map.class); job.setReducerClass(Reduce.class);
job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(input_path)); FileOutputFormat.setOutputPath(job, new Path(output_path));
job.waitForCompletion(true); }
-
Compile and submit the project.
-
Compile and submit the general java project:
-
Right-click the project, and then select “export jar” (general package).
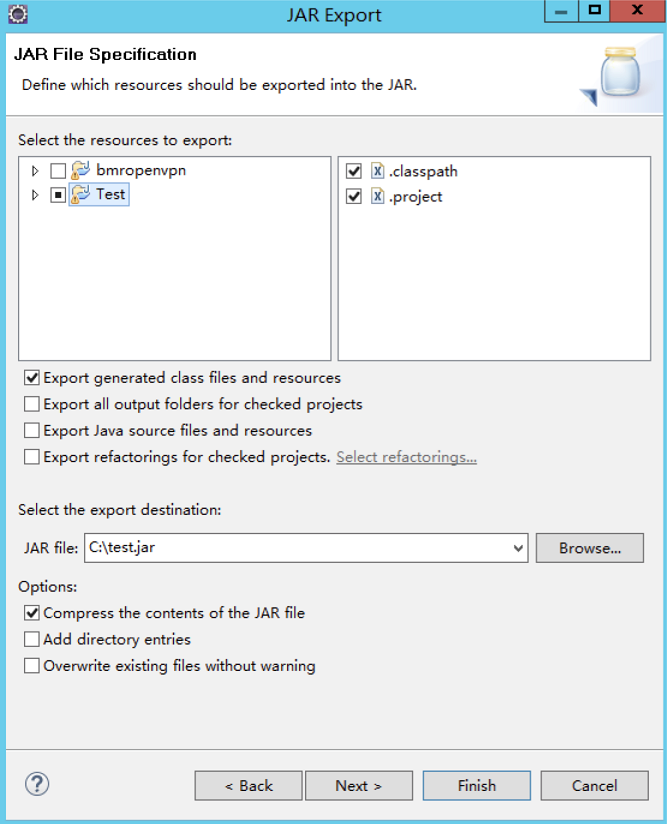
- Right-click the project, and then select
run as java applicationto submit steps to the cluster.
-
-
Compile and submit a Maven project:
- Right-click the project and select
run as maven install. The jar file generated is stored in the target folder under the directory of the Maven project package. - Copy the jar package in the target for reference. Otherwise, an exception occurs that the file is being occupied.
- Right-click the project and select
-
Mac
It is the same as Linux. For more information, please see Linux.