
HBase
HBase Introduction
The Weblog analysis for statistics on daily PV and UV is taken as an example to introduce how to use HBase on the Baidu AI Cloud platform in this document.
As a NoSQL database running on Hadoop, HBase is a distributed and scalable big data warehouse, which can use HDFS’s distributed processing mode and Hadoop’s MapReduce program model. HBase integrates the real-time query ability brought by key/value storage mode and the off-line processing or batch processing ability brought by MapReduce. Generally, HBase allows you to query records among massive data and obtain the integrated analysis report.
HBase is not a relational database and needs different methods to define a data model. HBase defines a data model of four dimensions (row key, column family, column qualifier, and version) to obtain the specified data:
- Row key: Every row has a unique row key. The row key has no data type and is internally considered as a byte array.
- Column family: The data is organized as a column family in the row, and every row has the same column family. For different rows, the same column family does not need the same column qualifier. In the engine, HBase stores the column family in its own data file. Hence, the column family needs definition in advance.
- Column qualifier: It means the real column defined by column family. The column qualifier can be considered as the column itself.
- Version: Every column has a certain number of versions to configure, and you can obtain data through the specified version of the column qualifier.
Program Preparation
You can directly use Sample Program. You can design your program and upload it to BOS. For more information, please see Baidu Object Storage (BOS) Start Guide.
Cluster Preparation
- Prepare the data. For more information, please see Data Preparation.
- Prepare Baidu AI Cloud Environment.
-
Log in to the console, select "Product Service->Baidu MapReduce BMR", and click "Create Cluster" to enter the cluster creation page and configure the following:
- Set cluster name
- Set administrator password
- Disable log
- Select image version “BMR 0.2.0(hadoop 2.6)”
- Select the built-in template “hbase”.
- Keep other default configurations of the cluster, and click "Finish" to view the created cluster in the cluster list page. The cluster is created successfully when cluster status changes from "Initializing" to "Waiting".
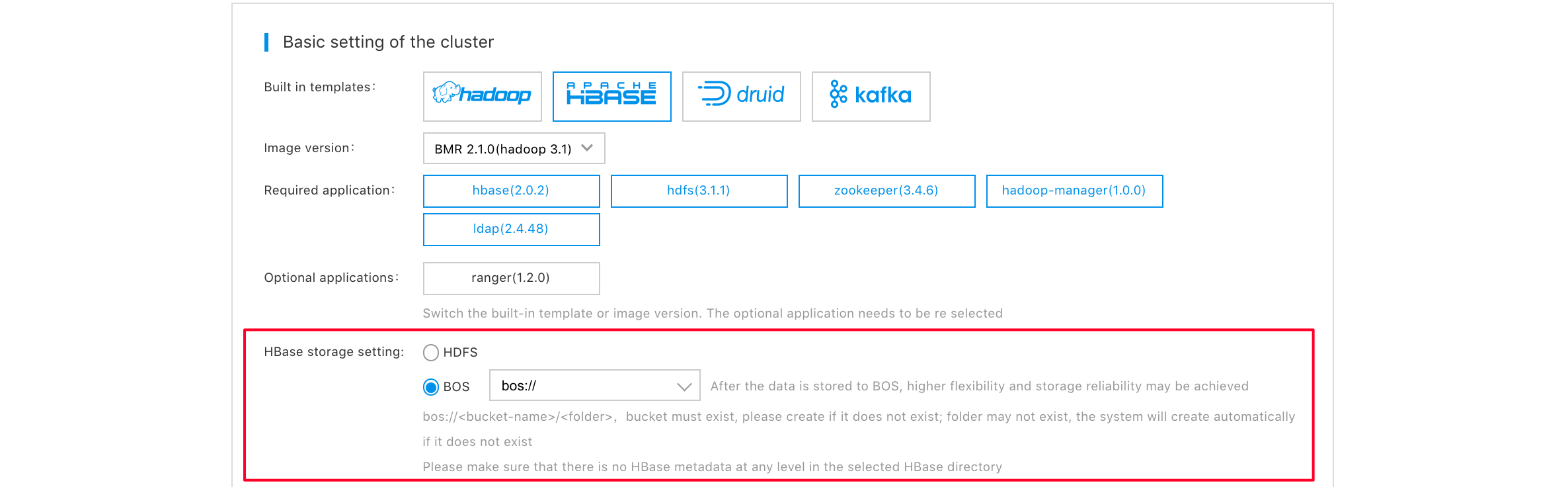
Note: For better data reliability, the Hbase cluster can set deep storage to be BOS during its creation. Please be noted that the selected BOS path must not exist, and changing such path and switching to HDFS storage cannot be permitted at a later time. Please reasonably select your storage mode. The following figure shows the specific setups.
Run Java Steps
Extract Web Access Log Content to HBase Table
- In "Product Service>MapReduce>Baidu MapReduce-Homework List" page, click "Create Step" to enter the step creation page.
-
Configure the Java step parameters as follows:
- Step type: Select “Java step”.
- Step name: Enter the step name with length not exceeding 255 characters.
- Application location: You can enter the sample program path
bos://bmr-public-data/apps/hbase/bmr-hbase-samples-1.0-SNAPSHOT.jar. - Action after failure: Continue.
- MainClass: Enter
com.baidubce.bmr.hbase.samples.logextract.AccessLogExtract. - Application parameters: Enter
-D mapreduce.job.maps=6 -D mapreduce.job.reduces=2 bos://bmr-public-data/logs/accesslog-1k.log AccessTable. (The last parameter "AccessTable" is the name of HBase Table)
- Select the adaptive cluster in the "Cluster Adaption" section.
- Click "Finish" to complete the creation of the step. The status changes from "Waiting" to "Running" when the step is running, and changes to "Completed" when the step is completed.
Count Daily PV
- In "Product Service>MapReduce>Baidu MapReduce-Homework List" page, click "Create Step" to enter the step creation page.
-
Configure the Java step parameters as follows:
- Step type: Select “Java step”.
- Step name: Enter the step name with length not exceeding 255 characters.
- Application location: You can enter the sample program path
bos://bmr-public-data/apps/hbase/bmr-hbase-samples-1.0-SNAPSHOT.jar. - Action after failure: Continue.
- MainClass: Enter
com.baidubce.bmr.hbase.samples.pv.PageView. - Application parameters: Enter
-D mapreduce.job.maps=6 -D mapreduce.job.reduces=2 AccessTable bos://${USER_BUCKET}/pv. bos://${USER_BUCKET}/pv must be granted the write permission, and the directory specified in the path cannot exist on bos. For example, if the output path is bos://test/sqooptest, the sqooptest directory must not exist on bos.
- Select the adaptive cluster in the "Cluster Adaption" section.
- Click "Finish" to complete the creation of the step. The step status changes from "Waiting" to "Running", and the status becomes "Completed" after the step is completed.
Count Daily UV
- In "Product Service>MapReduce>Baidu MapReduce-Homework List" page, click "Create Step" to enter the step creation page.
-
Select the created cluster in the step creation page, and then select "Java Step" to configure parameters.
- Step name: Enter the step name with length not exceeding 255 characters.
- Application location: You can enter the sample program path
bos://bmr-public-data/apps/hbase/bmr-hbase-samples-1.0-SNAPSHOT.jar. - Action after failure: Continue.
- MainClass: Enter
com.baidubce.bmr.hbase.samples.uv.UniqueVisitor. - Application parameters: Enter
-D mapreduce.job.maps=6 -D mapreduce.job.reduces=2 AccessTable bos://${USER_BUCKET}/uv. bos://${USER_BUCKET}/uv must be granted the write permission, and the directory specified in the path cannot exist on bos. For example, if the output path is bos://test/sqooptest, the sqooptest directory must not exist on bos.
- After configuring step parameters, click "Finish" to complete the creation of the step. The status changes from "Waiting" to "Running" when the step is running, and changes to "Completed" when the step is completed.
View Results
Example of final reduce result under bos://${USER_BUCKET}/pv/:
03/Oct/2015 139
05/Oct/2015 372
04/Oct/2015 375
06/Oct/2015 114Example of final reduce result under bos://${USER_BUCKET}/uv/:
03/Oct/2015 111
05/Oct/2015 212
04/Oct/2015 247
06/Oct/2015 97