
Product Introduction
Last Updated:2020-09-22
Overview
Baidu MapReduce (BMR) is a full-hosting Hadoop/Spark cluster that is accessible to on-demand deployment and elastic expansion and focuses on the processing, analysis, and reporting of big data. The Baidu operations OPS team with years of experience in massively distributed computing technology is fully responsible for the operations OPS of the cluster.
Baidu MapReduce supports the complete Hadoop ecology:
- Hadoop: Provides the reliable storage of HDFS and MapReduce programming paradigms for the massively parallel processing of data.
- Spark: Provides the distributed-memory-based massive parallel processing framework to enhance the big data analysis performance significantly. Spark provides a SQL query interface, stream data processing, and machine learning.
- HBase: Massively distributed NoSQL database contains unstructured and semi-structured random-access mass data.
Compared with the self-built Hadoop cluster, Baidu MapReduce holds the following advantages:
- Convenience: Create a cluster in several minutes without assigning, deploying, and optimizing the time invested in nodes.
- Elasticity: Create and dynamically adjust any size of cluster, i.e., increase the size of the cluster during the peak period to improve the computing ability and decrease the size of the cluster during the off-peak period to reduce the costs.
- Openness: Full compatibility with the open-source Hadoop/Spark community, and zero-cost business migration.
- Tangible benefits: On-demand payment and prepaid service, and transparent and straightforward pricing.
- Security: Private VPC (Virtual Private Cloud) and system environment for exclusive use to ensure data security.
Baidu MapReduce Components
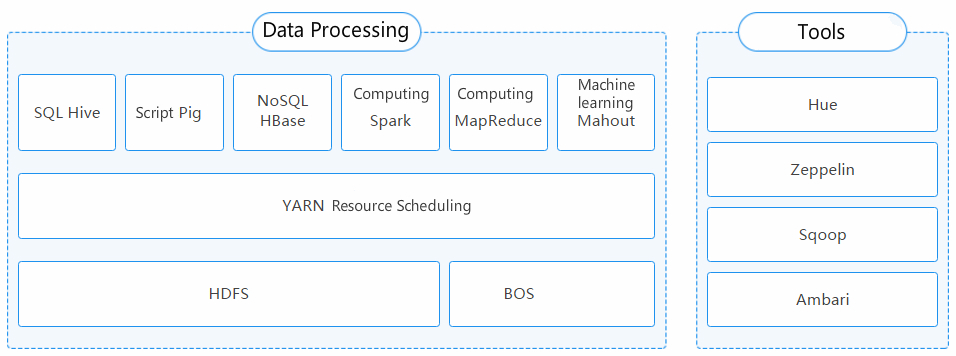
- MapReduce: Programming model for distributed parallel computing of large datasets, which efficiently allows the developer to run his program on a distributed system without the distributed parallel programming.
- Spark: Open-source cluster computing framework. By expanding the memory, Spark runs much faster than Hadoop in iterative computation and interactive computation of mass data. Spark improves the developer’s efficiency by supporting SQL requests, stream data processing, machine learning, and graph processing.
- HBase: Open-source, non-relational, distributed column-based database, which provides NoSQL function for Hadoop.
- Hive: Allows for data query through SQL-similar syntax and suitable for analysis of data warehouse.
- Pig: Procedural language used to load data, express converted data, and store the final result, making sense of logs and other semi-structured data.
- Hue: A set of web applications used to administer Hadoop clusters and execute Hive or Pig scripts.
- Sqoop: Import and export of data between Hadoop and traditional database.
- Kafka: Open-source, high-throughput distributed message queue system, which supports Hadoop parallel data loading.
- Zeppelin: Web version of the notebook, which is used for data analysis and visualization and allows for seamless connection with Hive and SparkSQL.