
Auto Scaling
Overview
In the big data processing and analysis scenarios, you often need to dynamically adjust the number of task nodes for the cluster as the business conditions change. In this way, you can reduce costs while ensuring successful delivery. The auto scaling function supports to adjust the scale of task nodes for the cluster according to the time rule or the index rule. It applies to the following scenarios:
- Business scale has the regular time cycle and the distinct wave peak and wave trough, such as daily statements, weekly statements, and other processing and analysis scenarios during a specific period.
- Business changes have no time rules, but the timely running of necessary steps is required, and the cluster scale needs dynamic adjustment according to cluster load indexes.
Configure Node Packages
- Select "Product Service>Data Analysis>Baidu MapReduce>Cluster management" to enter the cluster list page.
- Click the "Auto Scaling" button in the Action column behind the selected cluster, and then enter the "Administer Auto Scaling" page.
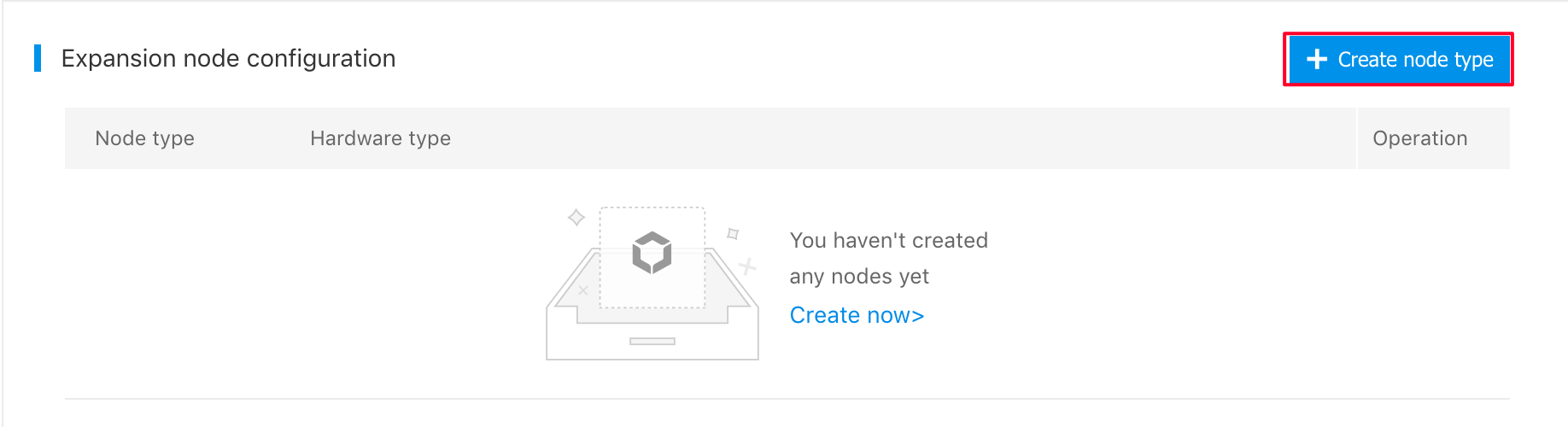
In the "Expansion Node Configurations" bar, click the "Add Node Types", select the node package in the pop-up box, configure the system disk and data disk, and click "OK". After selecting the node configurations, click "Modify" or "Delete" to reconfigure the node package. Click "Save" to complete the configuration of the node package.
Note: Once the node package is saved, it is not allowed to modify the package during the rule operation. To modify the package, you need to click "reset and release all nodes" in the upper right corner of the page to release the expanded nodes and reset the package type.
Manage Scaling Rules
Administer the cluster's auto scaling rules, set the scale of auto scaling, and create and edit the content of rules.
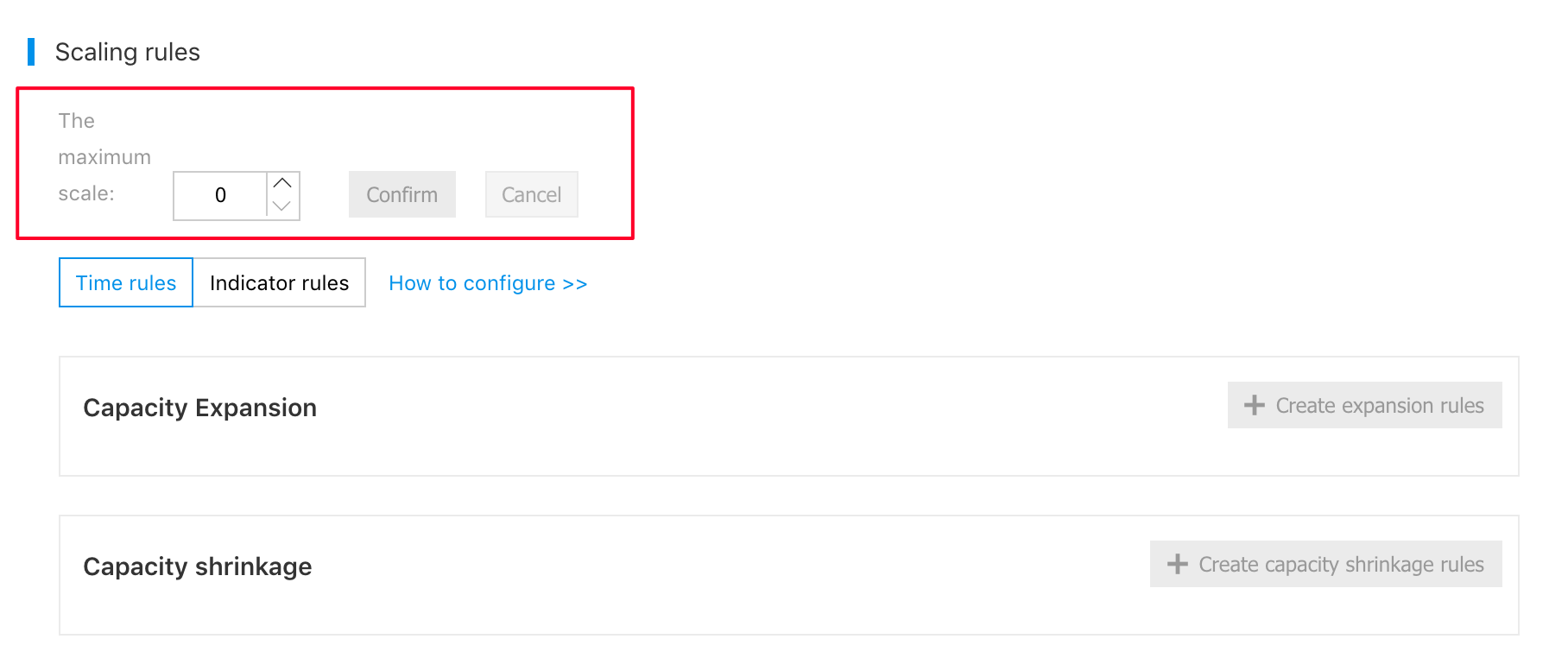
Configure Maximum Scale of Auto Scaling
Maximum scale: It means the maximum task nodes that the auto scaling expands. The auto scaling stops expansion after task nodes reach the maximum scale.
Note: The task nodes under auto scaling are independent of those for the cluster, and capacity expansion and capacity reduction do not affect each other. For example, if the cluster currently has 5 task nodes, then the cluster always has 5 task nodes, no matter how the auto scaling rule is triggered.
Configuration Rules
The scaling adopts time rule and index rule, and such two rules are independent of each other and do not take effect simultaneously. Click the "Rule Type and Name" to change the rules. After the change, the original rules lose effect and are no longer triggered, and the expanded nodes are not released until the new capacity reduction rules are triggered.
Note: Configure and save the node packages before creating the rules.
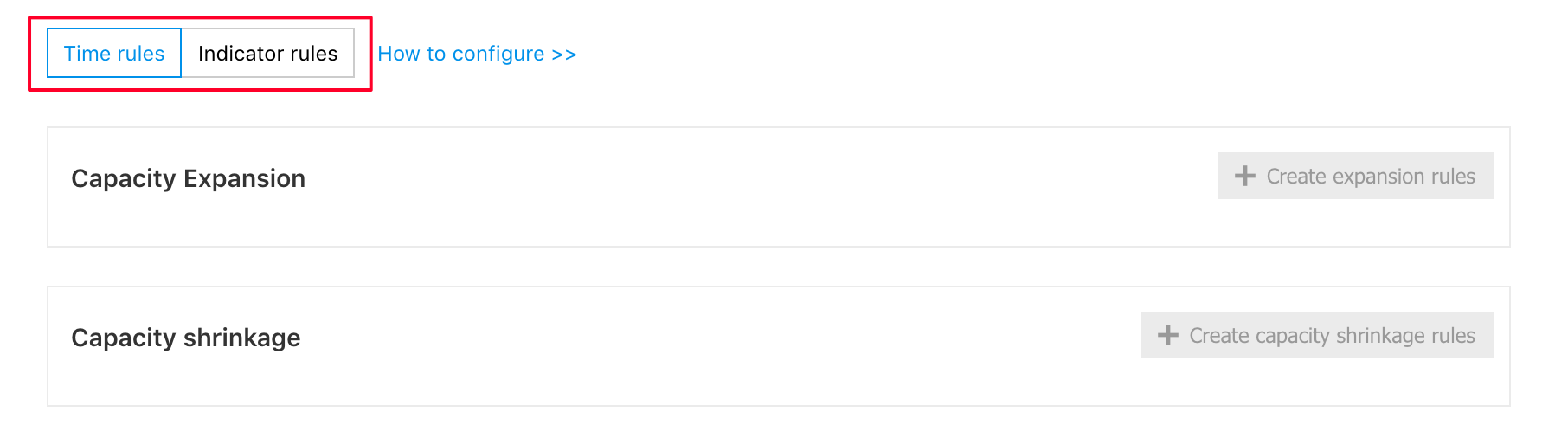
Click "Create Rule" to configure the rules.
-
Create the time rule
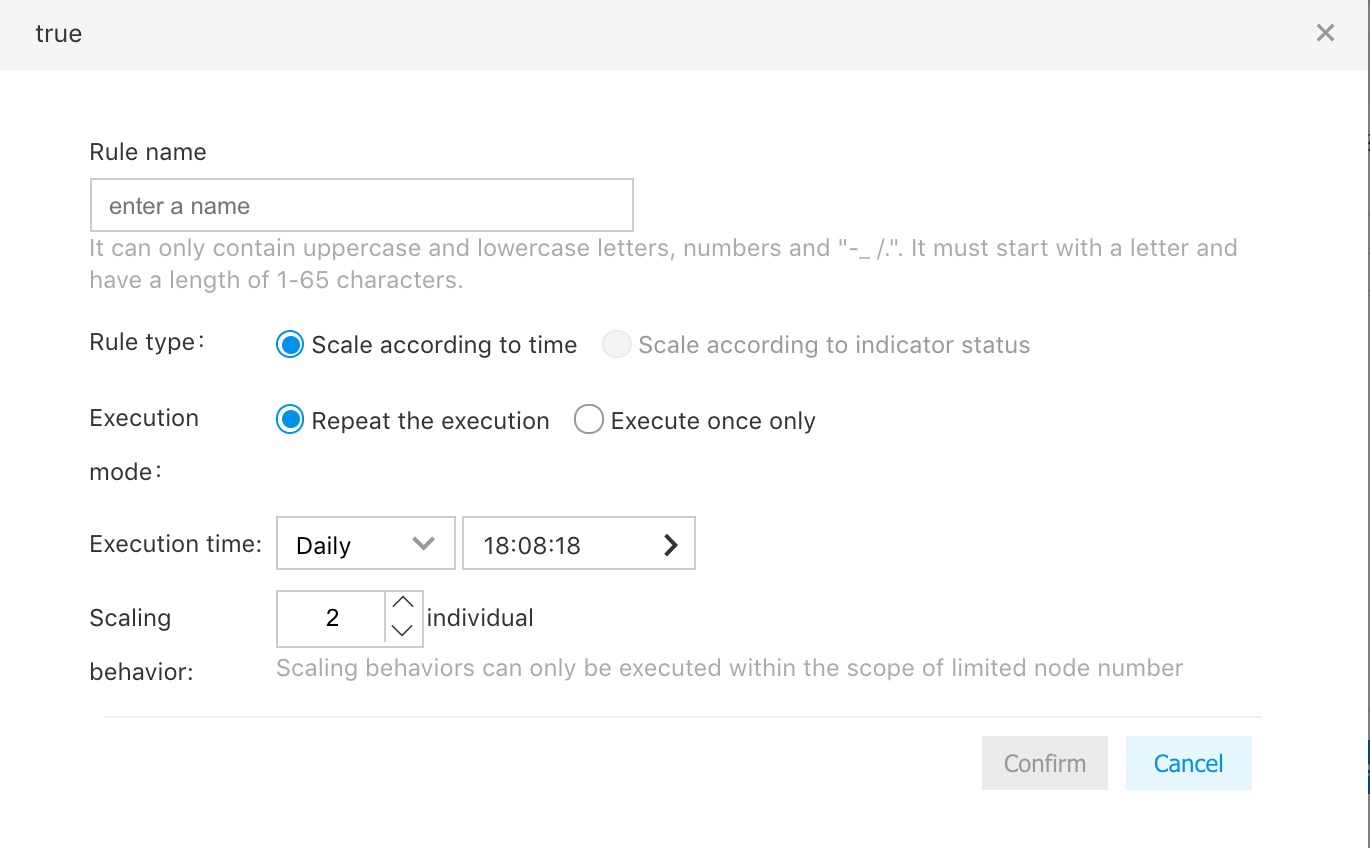
- Rule name: Enter the rule name
- Rule type: Not optional, and the same as the type of current rule
- Execution times: Repeated executions or execution once
- Execution period: In case of repeated executions, select the repetition cycle of "Every Day", "Every Week" or "Every Month", and then select the execution timing in the format of hour-minute-second; in case of execution once, select the specific date, and then select the execution timing in the format of hour-minute-second
- Scaling motion: Number of expansion nodes when the rule is triggered
-
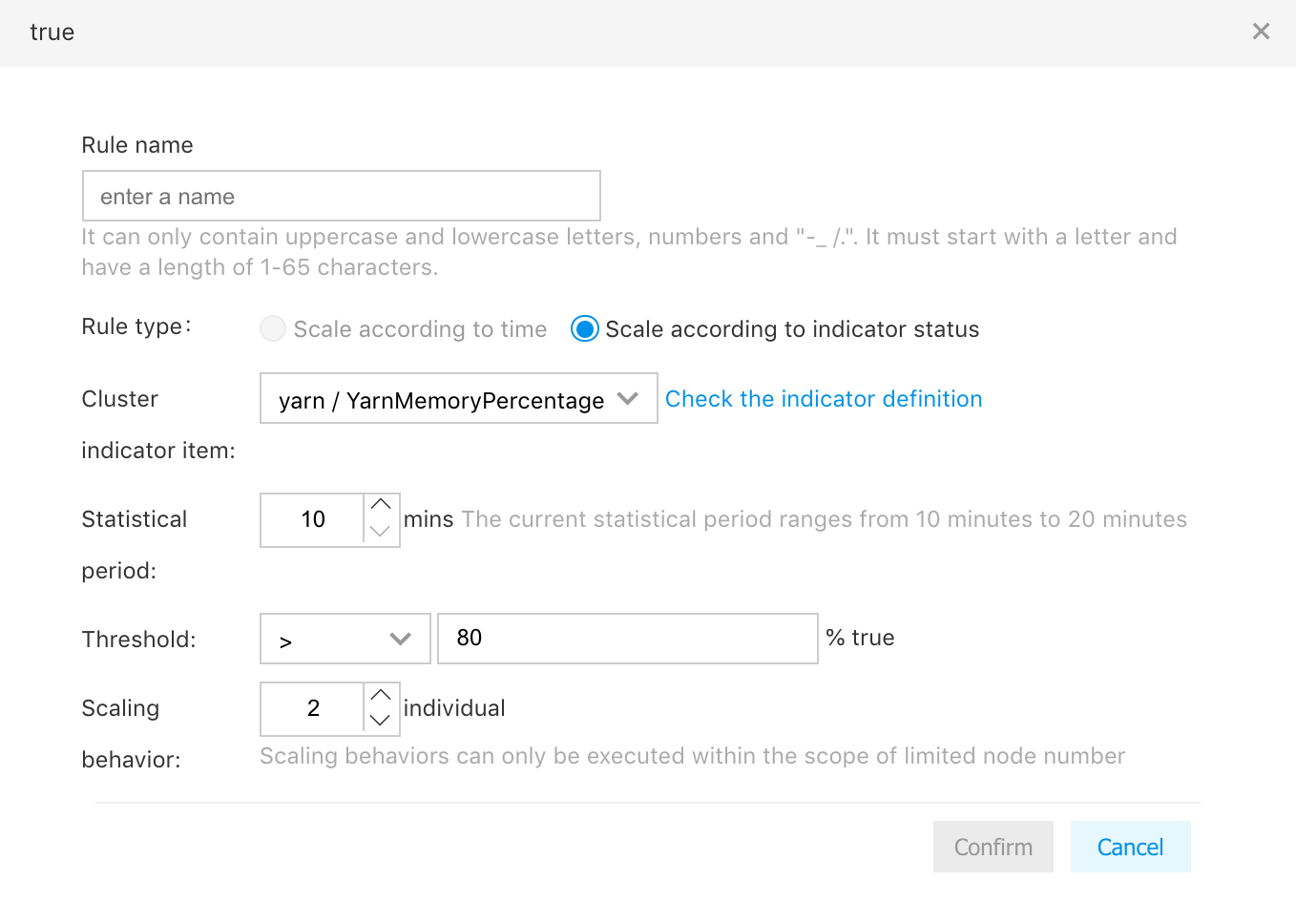
Create the index rule
- Rule name: Enter the rule name
- Rule type: Not optional, and the same as the type of current rule
- Cluster indexes: Select the cluster indexes to monitor, and select the statistical rules for index data (current options: mean value, maximum value, and minimum value)
- Statistical cycle: Time cycle used to evaluate if the selected cluster indexes meet the conditions, for example, the rule is triggered if the mean value of Yarn memory usage is more than 80% during the statistical cycle of 5 minutes
- Threshold: select the operative symbols ">" and "<"; configure the threshold numbers
- Scaling motion: Number of expansion nodes when the rule is triggered
- Definition of cluster indexes:
| Index Type | Index Name | Description |
|---|---|---|
| Yarn | YarnMemoryPercentage | Yarn memory usage percentage |
| - | YarnAppsPending | Number of pending tasks in Yarn |
| Cluster | ClusterCpuUsagePercentage | Mean cpu usage percentage of cluster |
Note: The hour-minute-second interval is more than 30 minutes between any two of the time rules. For example, the rule at 09:00 of every day conflicts with the rule at 09:00 of every Monday.
The cooldown period is 5 minutes between any two capacity expansions or capacity reductions, and during such period, no rule takes effect even if it meets the conditions of taking effect.
If two or more index rules are simultaneously triggered and take effect, the first rule triggered in order of precedence is executed.
Modify Rule Configurations
Click "Invalidate", "Edit" and "Delete" in the Action column to handle the rules.
- Rule status: The rule has two kinds of status. "Valid" means the rule can be triggered and executed; "Invalid" means the rule cannot be triggered.
- Invalid/Valid: Click "Invalid/Valid" in the Action column to change the rule's status
- Edit: Click "Edit" in the Action column to edit new rules
- Delete: Click "Delete" in the Action column to delete the rule
Release All Expansion Nodes
In the "Auto Scaling" page, click "Release All Nodes" at the upper right to release the expanded nodes. Meanwhile, all rules are in the invalid status, and no scaling is triggered.
View Auto Scaling Logs
The log function allows you to view the auto scaling operation records.
- Select "Product Service>Data Analysis>Baidu MapReduce>Cluster>Selected Cluster’s Name" to enter the cluster details page.
-
Click the "Auto Scaling Log" button to view the log records.
- Start time: Means the start time of expanding capacity or reducing capacity
- End time: Means the end time of expanding capacity or reducing capacity, and shows "Null" if the operation fails
- Rule name: Means the name of the rule triggered
- Scaling motion: Means the actual number of nodes in the operation
- Execution status: Means the execution result of the operation
- Number of nodes after execution: Means the total number of task nodes under auto scaling after the operation is executed