
Druid
Druid Introduction
Druid is a high-performance real-time data analysis system, whose source is opened by MetaMarkets in 2012 and which is specially designed for the OLAP scenario. Druid complies with Lambda architecture, supports batching and real-time data import, and provides high-performance data queries.
Cluster Preparation
Druid Template
Log in to Baidu AI Cloud console, select "Product Service->Baidu MapReduce BMR", and click "Create Cluster" to enter the cluster creation page. You can select the Druid template when purchasing the cluster. Druid’s metadata storage supports local MySQL and cloud database RDS MySQL. As the following figure shows:
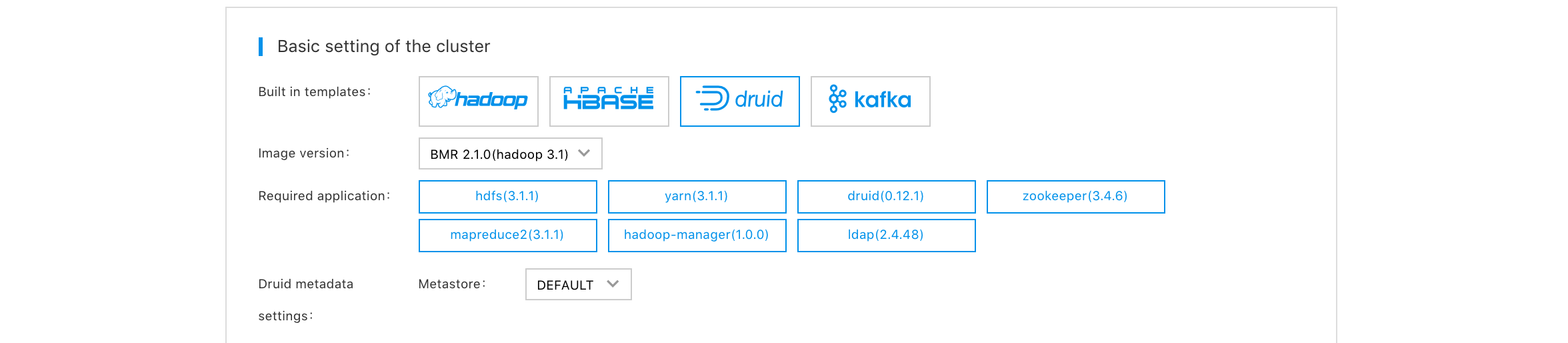
Node Types
Druid’s Overlord, Coordinator, Broker, and Router are deployed on BMR’s Master nodes to submit tasks, view data sources, and query data.
For the easier expansion of nodes, Druid's Historical and MiddleManager are deployed on BMR’s Core nodes, and Druid’s Broker and MiddleManager are deployed on Task nodes. You can change the number of Core and Task nodes on your demands.
Druid has high demands on memory, and the node configuration of 4 cores and 16GB (or higher configuration) is recommended. In the Druid cluster, it is not recommended to use MapReduce to run the steps of other open-source components.
Usage Introduction (Batch Indexing)
Ports used by Druid:
| Druid Node Types | Port |
|---|---|
| Broker | 8590 |
| Overlord | 8591 |
| Coordinator | 8592 |
| Router | 8593 |
| Historical | 8594 |
| MiddleManager | 8595 |
Druid provides Http access, and the result is returned for every request. If nothing is returned after the use of curl command, you can add -v to view the specific response.
-
Remotely log in to the created cluster
ssh hdfs@[master node public network ip]
Use the password entered during cluster creation -
Create a quickstart directory on HDFS
hdfs dfs -mkdir /user/druid/quickstart -
Copy the example data file wikiticker-2015-09-12-sampled.json.gz to HDFS
hdfs dfs -copyFromLocal /opt/bmr/druid/quickstart/wikiticker-2015-09-12-sampled.json.gz /user/druid/quickstart -
Submit the batch indexing task to Overlord
curl -v -X POST -H 'Content-Type: application/json' -d @/opt/bmr/druid/quickstart/wikiticker-index.json http://xxx-master-instance-xxx-1(hostname):8591/druid/indexer/v1/task
Successful return of result {"task":"index_hadoop_wikiticker_yyyy-MM-ddThh:mm:ss.xxZ"}If the high-availability cluster is used, only one Overlord is Active, and the valid "hostname" can be xxx-master-instance-xxx-2.
-
Use Web UI to view task running conditions
Use
ssh -ND [local unused port] hdfs@[public network ip]and configure the browser. For example, the Chrome browser uses Swichysharp to configure VPN (accesses cluster through SSH-Tunnel). If OpenVPN is used, you can use Master node’s "private ip" and Overlord port (8591) to view the result, as the following figure shows:
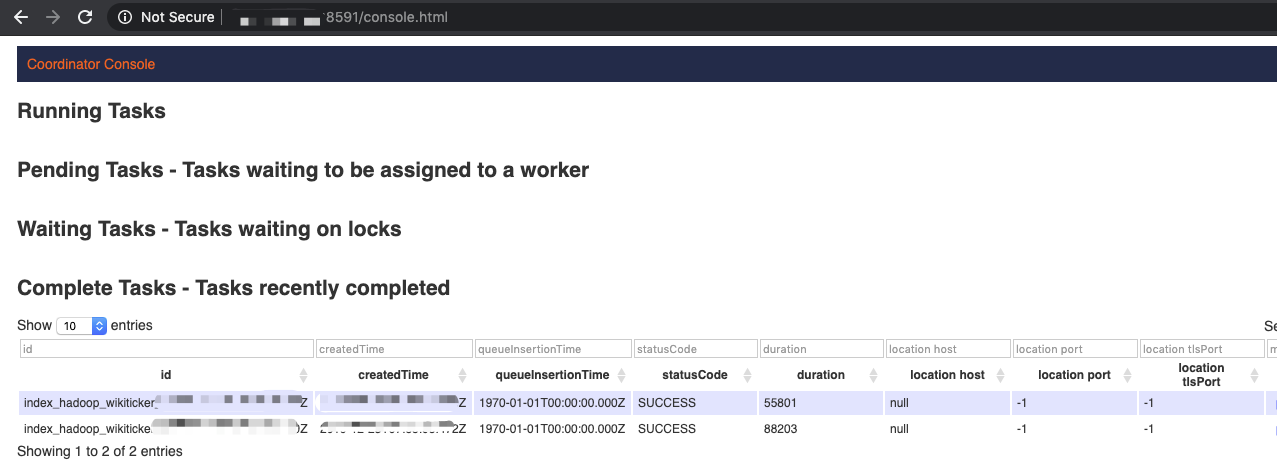
-
Wait for the indexing task to execute successfully, and view the data sources
Use Web UI: After the configuration of VPN, you can use Master node’s "private ip" and Coordinator port (8592) to view the result, as following figure shows:
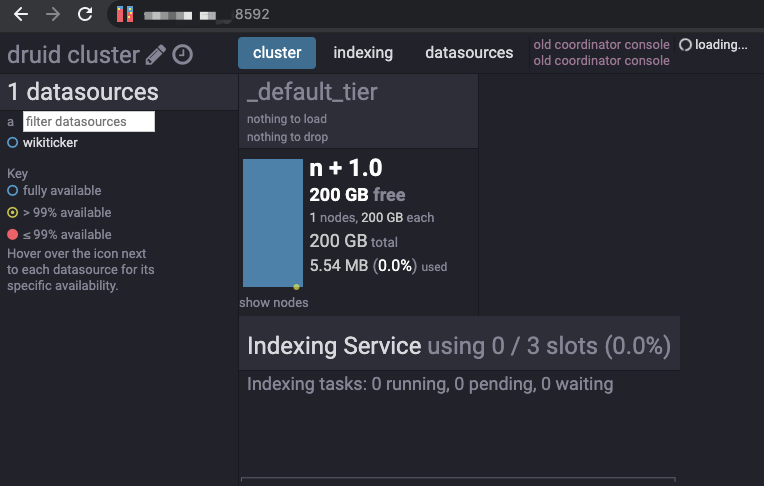
use Http:
curl -v -X GET http://xxx-master-instance-xxx-1:8592/druid/coordinator/v1/datasourcesSuccessful return of result ["wikiticker"]
If the high-availability cluster is used, only one Coordinator is Active, and the valid hostname can be xxx-master-instance-xxx-2.
-
Query data
When Overlord Web UI shows successful task or data source check shows wikiticker, you can use Broker to query data:
curl -v -X 'POST' -H 'Content-Type:application/json' -d @/opt/bmr/druid/quickstart/wikiticker-top-pages.json http://[master/task hostname或ip]:8590/druid/v2?pretty
Tips: Editing under ~ directory and local backup are recommended if you need to use your Druid Spec JSON. For Spec writing, please see the official documentation of Apache Druid.
Use Kafka Indexing Service
Druid provides Kafka Indexing Service to ingest real-time data. For more information, please see Official Documentation of Druid. BMR-hosting Druid supports Kafka clusters in BMS, BMR, and the same VPC. BMS is taken as an example here. Kafka clusters deployed in other ways have similar steps.
- Use BMS to create the topic
kafka_demo,and then download the BMS certificate to create Kafka creators and consumers in a later time. For more information, please see BMS Documentation
. -
Upload and decompress the downloaded BMS certificate to ~ directory (/home/hdfs), and then scp to other nodes.
unzip -d kafka-key kafka-key.zip scp -rp kafka-key hdfs@[node ip or hostname]:~/ -
Write the Druid Spec file kafka_demo.json under ~ directory (/home/hdfs), and BMS’s topic needs to take the prefix generated after the creation.
View client.properties file, and replace ssl.keystore.password in kafka_demo.json { "type": "kafka", "dataSchema": { "dataSource": "wiki_kafka_demo", "parser": { "type": "string", "parseSpec": { "format": "json", "timestampSpec": { "column": "time", "format": "auto" }, "dimensionsSpec": { "dimensions": [ "channel", "cityName", "comment", "countryIsoCode", "countryName", "isAnonymous", "isMinor", "isNew", "isRobot", "isUnpatrolled", "metroCode", "namespace", "page", "regionIsoCode", "regionName", "user", { "name": "added", "type": "long" }, { "name": "deleted", "type": "long" }, { "name": "delta", "type": "long" } ] } } }, "metricsSpec" : [], "granularitySpec": { "type": "uniform", "segmentGranularity": "DAY", "queryGranularity": "NONE", "rollup": false } }, "tuningConfig": { "type": "kafka", "reportParseExceptions": false }, "ioConfig": { "topic": "[accountID]__kafka_demo", "replicas": 2, "taskDuration": "PT10M", "completionTimeout": "PT20M", "consumerProperties": { "bootstrap.servers": "[kafka_address]:[kafka_port]", "security.protocol": "SSL", "ssl.truststore.password": "kafka", "ssl.truststore.location": "/home/hdfs/kafka-key/client.truststore.jks", "ssl.keystore.location": "/home/hdfs/kafka-key/client.keystore.jks", "ssl.keystore.password": "******" } } }If the Kafka cluster used does not enable SSL, and you only need to configure bootstrap.servers in consumerProperties, such as Kafka in the BMR cluster.
-
Submit Kafka Supervisor task to Overlord
curl -XPOST -H'Content-Type: application/json' -d @kafka_demo.json http://[overlord_ip]:8591/druid/indexer/v1/supervisorSuccessful return of
{"id":"wiki_kafka_demo"}, and you can see the result on Overlord Web UI:
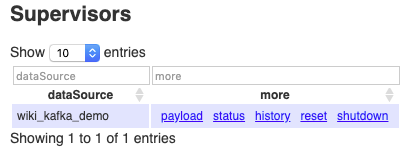
-
Decompress the BMS certificate package to the local directory and then use the client.properties to enable Kafka creator and send messages
sh bin/kafka-console-producer.sh --producer.config client.properties --topic <accountID>__kafka_demo --sync --broker-list [kafka_address]:[kafka_port] {"time":"2015-09-12T23:58:31.643Z","channel":"#en.wikipedia","cityName":null,"comment":"Notification: tagging for deletion of [[File:Axintele team.gif]]. ([[WP:TW|TW]])","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"User talk","page":"User talk:AlexGeorge33","regionIsoCode":null,"regionName":null,"user":"Sir Sputnik","delta":1921,"added":1921,"deleted":0}| {"time":"2015-09-12T23:58:33.743Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using [[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Codiaeum finisterrae","regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":18,"added":18,"deleted":0}| {"time":"2015-09-12T23:58:35.732Z","channel":"#en.wikipedia","cityName":null,"comment":"Put info into infobox, succession box, split sections a bit","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Jamel Holley","regionIsoCode":null,"regionName":null,"user":"Mr. Matté","delta":3427,"added":3427,"deleted":0} {"time":"2015-09-12T23:58:38.531Z","channel":"#uz.wikipedia","cityName":null,"comment":"clean up, replaced: ozbekcha → o?zbekcha, olchami → o?lchami (3) using [[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":true,"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Chambors","regionIsoCode":null,"regionName":null,"user":"Ximik1991Bot","delta":8,"added":8,"deleted":0}| {"time":"2015-09-12T23:58:41.619Z","channel":"#it.wikipedia","cityName":null,"comment":"/* Gruppo Discovery Italia */","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":true,"metroCode":null,"namespace":"Main","page":"Deejay TV","regionIsoCode":null,"regionName":null,"user":"Ciosl","delta":4,"added":4,"deleted":0} {"time":"2015-09-12T23:58:43.304Z","channel":"#en.wikipedia","cityName":null,"comment":"/* Plot */","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Paper Moon (film)","regionIsoCode":null,"regionName":null,"user":"Siddharth Mehrotra","delta":0,"added":0,"deleted":0} {"time":"2015-09-12T23:58:46.732Z","channel":"#en.wikipedia","cityName":null,"comment":"/* Jeez */ delete (also fixed Si Trew's syntax error, as I think he meant to make a link there)","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Wikipedia","page":"Wikipedia:Redirects for discussion/Log/2015 September 12","regionIsoCode":null,"regionName":null,"user":"JaykeBird","delta":293,"added":293,"deleted":0} {"time":"2015-09-12T23:58:48.729Z","channel":"#fr.wikipedia","cityName":null,"comment":"MàJ","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Wikipédia","page":"Wikipédia:Bons articles/Nouveau","regionIsoCode":null,"regionName":null,"user":"Gemini1980","delta":76,"added":76,"deleted":0} {"time":"2015-09-12T23:58:51.785Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using [[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Amata yezonis","regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":10,"added":10,"deleted":0}| {"time":"2015-09-12T23:58:53.898Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using [[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Codia triverticillata","regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":36,"added":36,"deleted":0}| -
Use Coordinator Web UI to view real-time data sources
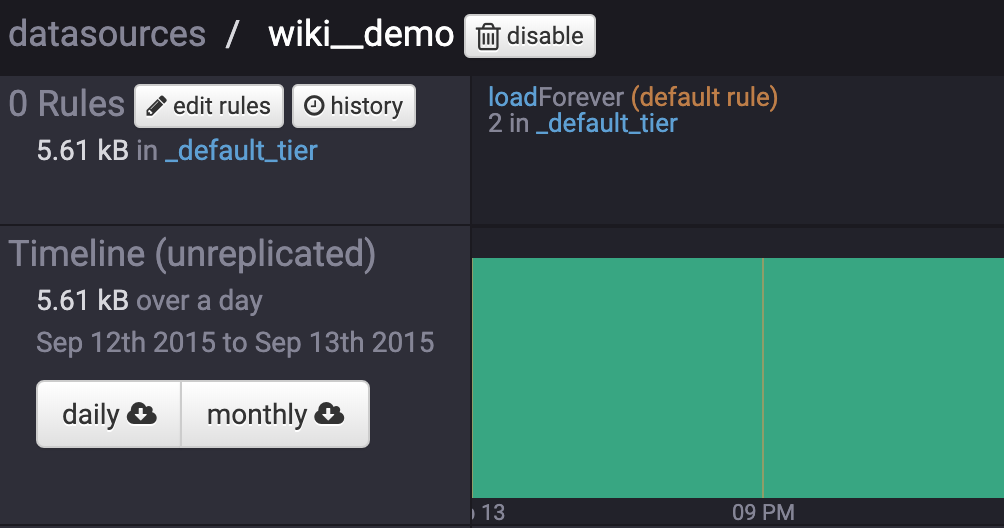
Use Druid Across Clusters
Druid supports the cooperation with other Hadoop components (such as Hadoop, Hive, and Spark) across clusters. In the cluster creation page, create multiple clusters under the same Virtual Private Cloud (VPC). You can use curl command or Http client to specify IP and port to send across-cluster requests to Druid components.
Currently, the hdfs users can only use IP address to access the CVM server of another cluster under the same VPC.
Use Hive to Simplify Druid Actions
In Hive, you can specify the IP address and port to access Druid nodes.
An executable example is provided here. For more information, please see the official documentation of Apache Hive available on https://cwiki.apache.org/confluence/display/Hive/Druid+Integration.
Example 1: Query
Hive is recommended to query Druid data. It can simplify the common Druid queries, and you do not need to write complex JSON files for simple queries.
-
Create a Hive cluster, and hdfs user logs in to Hive cluster
ssh hdfs@[public network ip of hive cluster]
Use the password entered during hive cluster creation -
Specify IP address and port for Druid cluster Broker
hive>
SET hive.druid.broker.address.default=x.x.x.x:8590; -
Create external tables, and make sure the
wikitickerdata source is created according to the preceding examplehive>
CREATE EXTERNAL TABLE druid_hive_demo_01 STORED BY 'org.apache.hadoop.hive.druid.DruidStorageHandler' TBLPROPERTIES ("druid.datasource" = "wikiticker"); -
View meta information
hive>
DESCRIBE FORMATTED druid_hive_demo_01;
Dimension column is string type, metric column is bigint type, and time stamp field __time is timestamp with local time zone type -
Query data
hive>
SELECT `__time`, count, page, `user`, added FROM druid_hive_demo_01 LIMIT 10;Note: Druid table cannot be fully scanned when Hive is used, and the error is reported if the limit is not used in the above example
__time is the time stamp field of Druid table (data sources) and needs escape with back quotes in Hive, and the returned result is as follows:
2015-09-12 08:46:58.771 Asia/Shanghai 1 36 Talk:Oswald Tilghman GELongstreet 2015-09-12 08:47:00.496 Asia/Shanghai 1 17 Rallicula PereBot 2015-09-12 08:47:05.474 Asia/Shanghai 1 0 Peremptory norm 60.225.66.142 2015-09-12 08:47:08.77 Asia/Shanghai 1 18 Apamea abruzzorum Cheers!-bot 2015-09-12 08:47:11.862 Asia/Shanghai 1 18 Atractus flammigerus ThitxongkhoiAWB 2015-09-12 08:47:13.987 Asia/Shanghai 1 18 Agama mossambica ThitxongkhoiAWB 2015-09-12 08:47:17.009 Asia/Shanghai 1 0 Campanya dels Balcans (1914-1918) Jaumellecha 2015-09-12 08:47:19.591 Asia/Shanghai 1 345 Talk:Dani Ploeger New Media Theorist 2015-09-12 08:47:21.578 Asia/Shanghai 1 121 User:WP 1.0 bot/Tables/Project/Pubs WP 1.0 bot 2015-09-12 08:47:25.821 Asia/Shanghai 1 18 Agama persimilis ThitxongkhoiAWB
Example 2: Import Historical Data
You can use the existing Hive table. By creating external tables, you can import HDFS data to Druid, without writing complex Druid Ingestion Spec files. Note: You must specify the time stamp field __time, and the time stamp type is timestamp with local time zone.
-
Enter ~ directory, download the example data file and create an example Hive table
wget http://files.grouplens.org/datasets/movielens/ml-100k.zip unzip ml-100k.zip hive> CREATE TABLE u_data ( userid INT, movieid INT, rating INT, unixtime STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE; LOAD DATA LOCAL INPATH 'ml-100k/u.data' OVERWRITE INTO TABLE u_data; - Set Hive attributes, and associate Druid
// obtain metadatabase information of druid cluster: ssh hdfs@public_ip 'cat /etc/druid/conf/_common/common.runtime.properties | grep "druid.metadata.storage.connector"'|
// across-cluster access to druid cluster’s mysql, needs to use ip address, and needs to update hive cluster’s hosts file if hostname is used
// enabled when external table needs to delete, and Druid data can be cleared: SET external.table.purge=true;
SET hive.druid.metadata.uri=jdbc:mysql://[druid_mysql_ip]:3306/druid?characterEncoding=UTF-8;
SET hive.druid.metadata.username=[druid_user];
SET hive.druid.metadata.password=[druid_passwd];
SET hive.druid.broker.address.default=[druid_broker_ip]:8590;
SET hive.druid.overlord.address.default=[druid_overlord_ip]:8591;
SET hive.druid.coordinator.address.default=[druid_coordinator_ip]:8592;
SET hive.druid.storage.storageDirectory=hdfs://[hive_hdfs_ip]:8020/user/druid/warehouses;- Method 1: Create a table and then import data
CREATE EXTERNAL TABLE druid_hive_demo_02
(`__time` TIMESTAMP WITH LOCAL TIME ZONE, userid STRING, moveid STRING, rating INT)
STORED BY 'org.apache.hadoop.hive.druid.DruidStorageHandler'
TBLPROPERTIES (
"druid.segment.granularity" = "MONTH",
"druid.query.granularity" = "DAY"
);
INSERT INTO druid_hive_demo_02
SELECT
cast (from_unixtime(cast(unixtime as int)) as timestamp with local time zone) as `__time`,
cast(userid as STRING) userid,
cast(movieid as STRING) moveid,
cast(rating as INT) rating
FROM u_data;Method 2: Use the CTAS statement to create a Druid table and import data
// Enable CTAS of Hive external table
SET hive.ctas.external.tables=true;
CREATE EXTERNAL TABLE druid_hive_demo_02
STORED BY 'org.apache.hadoop.hive.druid.DruidStorageHandler'
TBLPROPERTIES (
"druid.segment.granularity" = "MONTH",
"druid.query.granularity" = "DAY")
AS
SELECT
cast (from_unixtime(cast(unixtime as int)) as timestamp with local time zone) as `__time`,
cast(userid as STRING) userid,
cast(movieid as STRING) moveid,
cast(rating as INT) rating
FROM u_data;If the CTAS statement fails, and the created table exists, you can continue to use the INSERT statement to insert data, or you can delete the table and execute it again.
- Query results
hive> SELECT * FROM druid_hive_demo_02 LIMIT 10;
OK
1997-09-19 08:00:00.0 Asia/Shanghai 259 1074 3
1997-09-19 08:00:00.0 Asia/Shanghai 259 108 4
1997-09-19 08:00:00.0 Asia/Shanghai 259 117 4
1997-09-19 08:00:00.0 Asia/Shanghai 259 173 4
1997-09-19 08:00:00.0 Asia/Shanghai 259 176 4
1997-09-19 08:00:00.0 Asia/Shanghai 259 185 4
1997-09-19 08:00:00.0 Asia/Shanghai 259 200 4
1997-09-19 08:00:00.0 Asia/Shanghai 259 210 4
1997-09-19 08:00:00.0 Asia/Shanghai 259 255 4
1997-09-19 08:00:00.0 Asia/Shanghai 259 286 4Example 3: Import Kafka Real-Time Data
- Use BMS to create the topic
kafka_demo,and then download the certificate scp to druid cluster nodes. For more information, please see BMS Documentation.
scp -rp kafka-key hdfs@[Node ip of druid cluster or hostname]:~/ - Create a Hive table, and associate BMS Kafka through attributes
// obtain metadatabase information of druid cluster: ssh hdfs@public_ip 'cat /etc/druid/conf/_common/common.runtime.properties | grep "druid.metadata.storage.connector"'|
// across-cluster access to druid cluster’s mysql, needs to use ip address, and needs to update hive cluster’s hosts file if hostname is used //
SET hive.druid.metadata.uri=jdbc:mysql://[druid_mysql_ip]:3306/druid?characterEncoding=UTF-8;
SET hive.druid.metadata.username=[druid_user];
SET hive.druid.metadata.password=[druid_passwd];
SET hive.druid.broker.address.default=[druid_broker_ip]:8590;
SET hive.druid.overlord.address.default=[druid_overlord_ip]:8591;
SET hive.druid.coordinator.address.default=[druid_coordinator_ip]:8592;
SET hive.druid.storage.storageDirectory=hdfs://[hive_hdfs_ip]:8020/user/druid/warehouses;
// Kafka Supervisor configuration prefix is druid.kafka.ingestion
CREATE EXTERNAL TABLE druid_kafka_demo
(
`__time` TIMESTAMP WITH LOCAL TIME ZONE,
`channel` STRING,
`cityName` STRING,
`comment` STRING,
`countryIsoCode` STRING,
`isAnonymous` STRING,
`isMinor` STRING,
`isNew` STRING,
`isRobot` STRING,
`isUnpatrolled` STRING,
`metroCode` STRING,
`namespace` STRING,
`page` STRING,
`regionIsoCode` STRING,
`regionName` STRING,
`added` INT,
`user` STRING,
`deleted` INT,
`delta` INT
)
STORED BY 'org.apache.hadoop.hive.druid.DruidStorageHandler'
TBLPROPERTIES (
"kafka.bootstrap.servers" = "[kafka_address]:[kafka_port]",
"kafka.security.protocol" = "SSL",
"kafka.ssl.truststore.password" = "kafka",
"kafka.ssl.truststore.location" = "/home/hdfs/kafka-key/client.truststore.jks",
"kafka.ssl.keystore.location" = "/home/hdfs/kafka-key/client.keystore.jks",
"kafka.ssl.keystore.password" = "******",
"kafka.topic" = "[account_id]__kafka_demo",
"druid.kafka.ingestion.useEarliestOffset" = "true",
"druid.kafka.ingestion.maxRowsInMemory" = "5",
"druid.kafka.ingestion.startDelay" = "PT1S",
"druid.kafka.ingestion.period" = "PT1S",
"druid.kafka.ingestion.taskDuration" = "PT10M",
"druid.kafka.ingestion.completionTimeout" = "PT20M",
"druid.kafka.ingestion.consumer.retries" = "2"
);If the Kafka used does not enable SSL, you can remove ssl configurations, such as Kafka in the BMR cluster.
-
Launch Kafka creator to send data
sh bin/kafka-console-producer.sh --producer.config client.properties --topic druid_kafka_demo --sync --broker-list [kafka_address]:[kafka_port] {"__time":"2015-09-12T23:58:31.643Z","channel":"#en.wikipedia","cityName":null,"comment":"Notification: tagging for deletion of [[File:Axintele team.gif]]. ([[WP:TW|TW]])","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"User talk","page":"User talk:AlexGeorge33","regionIsoCode":null,"regionName":null,"user":"Sir Sputnik","delta":1921,"added":1921,"deleted":0}| {"__time":"2015-09-12T23:58:33.743Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using [[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Codiaeum finisterrae","regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":18,"added":18,"deleted":0}| {"__time":"2015-09-12T23:58:35.732Z","channel":"#en.wikipedia","cityName":null,"comment":"Put info into infobox, succession box, split sections a bit","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Jamel Holley","regionIsoCode":null,"regionName":null,"user":"Mr. Matté","delta":3427,"added":3427,"deleted":0} {"__time":"2015-09-12T23:58:38.531Z","channel":"#uz.wikipedia","cityName":null,"comment":"clean up, replaced: ozbekcha → o?zbekcha, olchami → o?lchami (3) using [[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":true,"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Chambors","regionIsoCode":null,"regionName":null,"user":"Ximik1991Bot","delta":8,"added":8,"deleted":0}| {"__time":"2015-09-12T23:58:41.619Z","channel":"#it.wikipedia","cityName":null,"comment":"/* Gruppo Discovery Italia */","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":true,"metroCode":null,"namespace":"Main","page":"Deejay TV","regionIsoCode":null,"regionName":null,"user":"Ciosl","delta":4,"added":4,"deleted":0} {"__time":"2015-09-12T23:58:43.304Z","channel":"#en.wikipedia","cityName":null,"comment":"/* Plot */","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Paper Moon (film)","regionIsoCode":null,"regionName":null,"user":"Siddharth Mehrotra","delta":0,"added":0,"deleted":0} {"__time":"2015-09-12T23:58:46.732Z","channel":"#en.wikipedia","cityName":null,"comment":"/* Jeez */ delete (also fixed Si Trew's syntax error, as I think he meant to make a link there)","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Wikipedia","page":"Wikipedia:Redirects for discussion/Log/2015 September 12","regionIsoCode":null,"regionName":null,"user":"JaykeBird","delta":293,"added":293,"deleted":0} {"__time":"2015-09-12T23:58:48.729Z","channel":"#fr.wikipedia","cityName":null,"comment":"MàJ","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":false,"isUnpatrolled":false,"metroCode":null,"namespace":"Wikipédia","page":"Wikipédia:Bons articles/Nouveau","regionIsoCode":null,"regionName":null,"user":"Gemini1980","delta":76,"added":76,"deleted":0} {"__time":"2015-09-12T23:58:51.785Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using [[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Amata yezonis","regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":10,"added":10,"deleted":0}| {"__time":"2015-09-12T23:58:53.898Z","channel":"#vi.wikipedia","cityName":null,"comment":"clean up using [[Project:AWB|AWB]]","countryIsoCode":null,"countryName":null,"isAnonymous":false,"isMinor":false,"isNew":false,"isRobot":true,"isUnpatrolled":false,"metroCode":null,"namespace":"Main","page":"Codia triverticillata","regionIsoCode":null,"regionName":null,"user":"ThitxongkhoiAWB","delta":36,"added":36,"deleted":0}| - You can use DDL to control start/stop of Kafka to import data
// Only if druid.kafka.ingestion is START, Hive can submit real-time tasks to Druid
ALTER TABLE druid_kafka_demo SET TBLPROPERTIES('druid.kafka.ingestion' = 'START');
ALTER TABLE druid_kafka_demo SET TBLPROPERTIES('druid.kafka.ingestion' = 'STOP');
ALTER TABLE druid_kafka_demo SET TBLPROPERTIES('druid.kafka.ingestion' = 'RESET');- When the first Segment is uploaded successfully and Coordinator shows the data sources, you can use Hive to query data. For more information, please see Example 1.