
Elasticsearch as DTS Destination
1. Applicable Scenarios
This document applies to scenarios where you migrate a DTS-supported data source to an Elasticsearch destination with Baidu AI Cloud’s Data Transmission Service (DTS).
2. Restrictions on Using Elasticsearch as DTS destination
- The structure migration isn’t supported
- The incremental synchronization feature cannot synchronize the DDL statements of a relational database.
- When the source-end data source is MySQL, enum/set/timestamp type fields in the source-end binlog only reserve the original binary information. The DTS data migrated to the downstream device incrementally correspond to the source-end binlog. The users need to parse its meaning according to the upstream MySQL list structure.
- The synchronization of the binary type data of source-end data sources isn’t supported
3. Prerequisites for Using Elasticsearch as DTS destination
3.1 Environment requirements
You have created an Elasticsearch instance as the migration destination, such as Baidu Elasticsearch instance and self-built Elasticsearch instance. The Elasticsearch version supported by DTS is 5.0 or above.
3.2 Privilege requirements
The account has the privilege of creating indexes and writing data in the Elasticsearch destination instances.
3.3 Recommended Configuration of destination Elasticsearch
At present, DTS doesn’t support structure migration. If you select the total/increment migration to write data to the downstream node, Elasticsearch creates indexes automatically according to the format of the written data, and designates the corresponding index mapping. However, the field type mapped by Elasticsearch may not meet the requirements during the actual application, so it is not recommended to do this.
Before you **start the DTS task, create the destination Elasticsearch index and designate each field’s type according to the actual query requirements**. Then, start the DTS data migration tasks.
Besides, we recommend you to configure the cluster granularity attribute refresh_interval as the reasonable value to avoid overloads to the downstream Elasticsearch instances due to the batch data write. If you can accept that the written data is visible 1 min after you write the data, you may set the refresh_interval value to 1m.
PUT /indice/_settings
{
"index" : {
"refresh_interval" : "1m"
}
}4. Application of Elasticsearch as DTS destination
For the operation process of task create, pre-check, task start, task pause, and task termination during the use of Elasticsearch as the destination, see Operation Guide.
Task Configuration and Object Mapping are different from other data sources.
4.1 Task Configuration
You need first to configure upstream and downstream connection information of data transmission tasks.
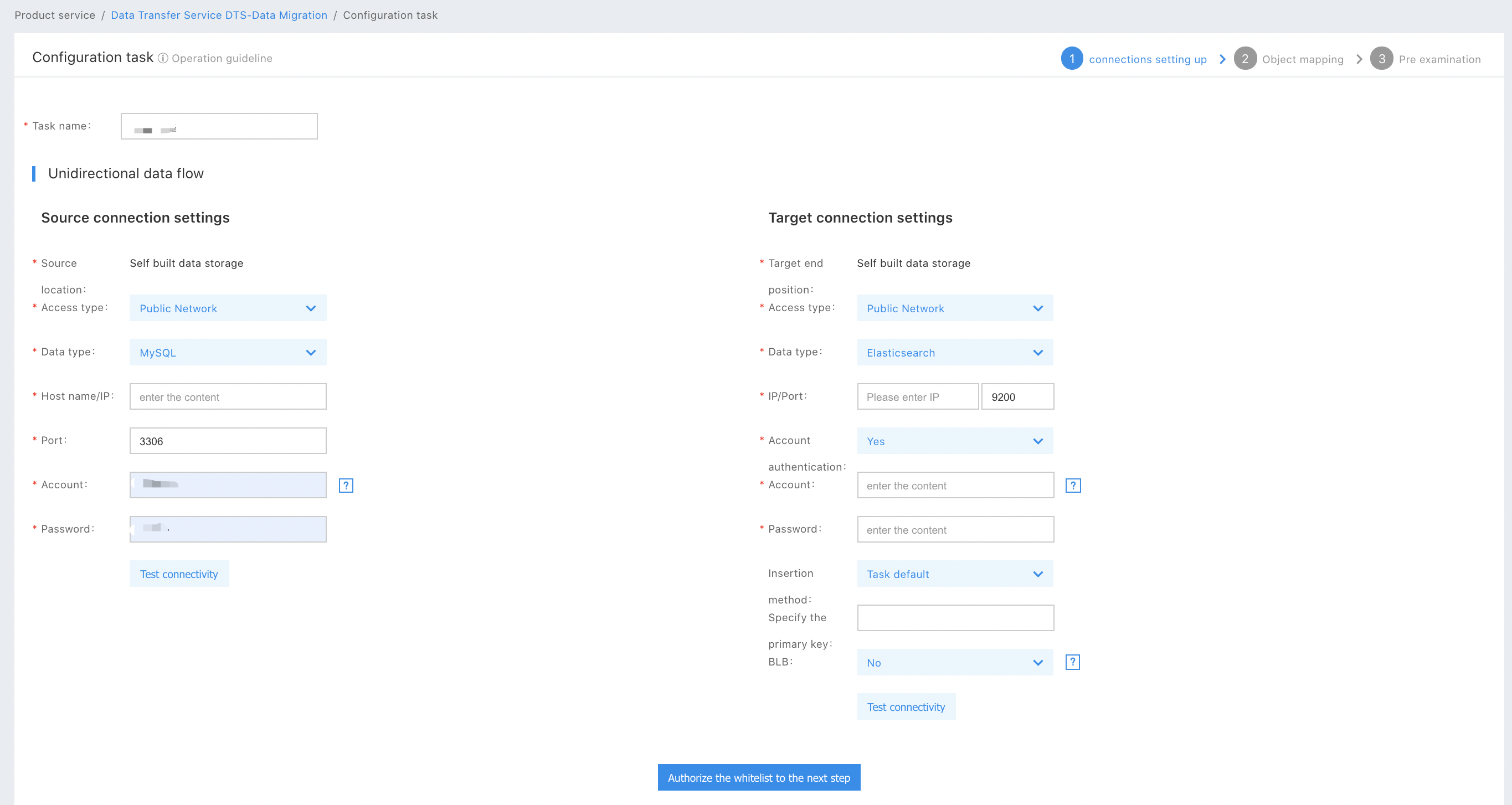
As shown above, you should select a destination Easticsearch instance. The DTS destination supports the products hosted on the cloud, including Baidu Elasticsearch and self-built Elasticsearch instances. The user selects a Baidu Elasticsearch (BES) instance in the North China-Baoding Region in the figure. The configuration parameters of the Elasticsearch destination are described as below:
- Access Type: supports the public network/BCC/BBC/DCC self-built Elasticsearch instances and Baidu Elasticsearch instances.
- Data Type: Regularly select Elasticsearch
- Region: The Baidu AI Cloud logic region where the self-built instances/Baidu Elasticsearch instances are located. If the access type you select is the public network, you don’t need to select a region.
- Instance ID: When the access type you select is BCC/BBC/DCC, the instance ID is the BCC/BBC/DCC instance ID; and when the access type you select is Baidu Elasticsearch, the instance ID is the Baidu Elasticsearch instance ID. If the access type you select is the public network, you don’t need to select the Instance ID but need to enter the instance IP.
- Port: The access port of the Elasticsearch instances. For a Baidu Elasticsearch instance, you don’t need to enter this field.
If your Elasticsearch instances are self-built clusters that contain a plurality of nodes, you only need to enter certain node connection information in the clusters during task configuration. It is recommended to configure tasks at the master nodes.
- Account Authentication: When the access type you select is Baidu Elasticsearch, enter the account and the password, which can be found in the Baidu Elasticsearch instance details page. When the access type you select is public network/BCC/BBC/DCC, you need to select whether to enter the account authentication information according to the actual configuration of the self-built Elasticsearch instance.
- Insertion mode: A data view-related feature. For the configuration method, see [Data View -> How to Configure Tasks](#531-Connection Configuration). For the normal data migration task, you only need to select the Default Task.
- Designated Primary Key: A data view-related feature. For the configuration method, see [Data View -> How to Configure Tasks](#531-Connection Configuration). For the normal data migration task, you don’t need to configure this field.
- Load Balance: It is optional only when the access type you select is public network/BCC/BBC/DCC. If you open the Load Balance, you can query and maintain the global topology of the Elasticsearch cluster during the DTS data migration and send the request to the arbitrary survival nodes of the cluster during the data write.****
After you finish the configuration, click Authorize a Whitelist to Enter the Next Step. Then, enter the Object Mapping Configuration page.
4.2 Object Mapping
As shown above, the data flow direction is as follows: Relational Database Service (MySQL) -> Baidu Elasticsearch (BES). For the Migration Type, choose Total Migration + Incremental Synchronization. For the Transmission Object, you can either migrate the whole instance at the source end or screen migration objects manually. In the figure, three tables, including multi_pk_tbl1, multi_pk_tbl2, and multi_pk_tbl3 under the dtstest database, are used as migration objects.
The selected migration objects may appear in the list of the selected objects on the right side. DTS supports such features as mapping upstream and downstream database table names, row filtering, and blacklist/whitelist column filtering. You can click “Edit” to configure the mapping and filtering rules for each migration object.
As shown above, the user configures the table name mapping rules for the multi_pk_tbl1 and multi_pk_tbl2 in the example task and modifies the table name at the destination into tbl1 and tbl2. You can also configure the row filtering rule and the blacklist/whitelist column filtering.
In the mapping rule of the DTS data migration, a table at the source end corresponds to an index in Elasticsearch, with an index name: Mapped Database Name_Mapped Table Name. If the table name mapping rule is configured in the dtstest.multi_pk_tbl1 table, the downstream index name is dtstest_tbl1 after modifying the multi_pk_tbl1 into tbl1. Similarly, the downstream index name corresponding to the dtstest.multi_pk_tbl2 table is dtstest_tbl2. In the figure, the table name mapping rule isn’t configured in the dtstest.multi_pk_tbl3 table, so the mapped table name is still multi_pk_tbl3, and the corresponding downstream index name is dtstest_multi_pk_tbl3.
If you select the database-level migration, you can only configure the database name mapping, but cannot configure the table name mapping. Downstream index name: Mapped Database Name_Table Name. For example, when there is a table named tbl1 under a test database, the task is to migrate the test database. The database name mapping is configured as follows: test -> alpha, the new index name in the downstream Elasticsearch instance is alpha_tbl1.
Besides, Elasticsearch requires the index name must be lower-case. Therefore, DTS may convert the upstream database table name into the lower-case index name by default. For example, the downstream Elasticsearch index name corresponds to the upstream dtsTEST.TESTTABLE table is dtstest_testtable.
After completing the object mapping configuration, click “Save and Pre-check” to start the task pre-check.
5. Data View
5.1. Business scenarios
For the data view, fit the data in multiple entity tables of the source-end data source to form a view and save it in the same index of the Elasticsearch destination instance.
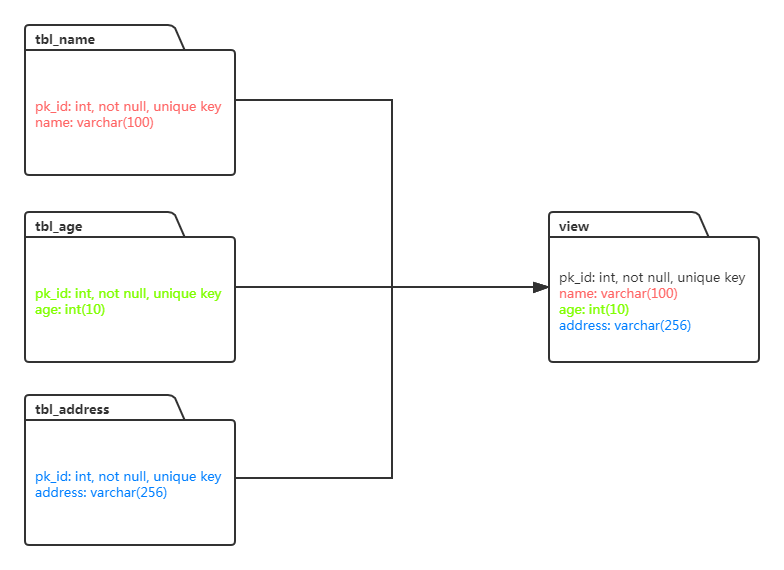
As shown above, there are three entity tables in the source-end data source, including tbl_name, tbl_age, and tbl_address. The primary keys in the three tables are the same, which are pk_id, but other fields in the tables are different. DTS allows you to create a data migration task for synchronizing the data of multiple entity tables at the source end to one or more indexes at the destination. In the synchronization task, you can designate primary keys by taking the pk_id as an index. Also, DTS can synchronize total or incremental data.
5.2 Usage Limits
- Tables in the same view contain primary keys designated by indexes. As shown above, the three tables, including tbl_name, tbl_age, and tbl_address, include the primary key pk_id designated by indexes.
- Users ensure the consistency of the source-end data view. When users add and delete data from tables in the same view, ensure its atomicity.
- The impossibility to modify the designated primary key column of the data view may result in failure to execute tasks.
5.3 How to configure tasks
5.3.1 Connection configuration
Back to the Connection Configuration page in Task Configuration, the difference between the data view feature and the normal migration task is that you need to configure two more fields for the former.
- Insertion method: Select the upsert permanently
- Designate primary key: You need to designate a primary key column in a data view, whose a **format is as follows:** downstream index name 1 [Primary key column]; downstream index name 2 [Primary key columns 1 and 2].
As shown in the example in 5.1 Business Scenarios. The primary key column of the data view consisting of three tables: tbl_name, tbl_age, and tbl_address, is pk_id. The Elasticsearch index name of the source-end data view is dtstest_view, which should be configured as dtstest_view[pk_id] in the designated primary key.
In addition, the synchronization rules of multiple data views can be configured in a data migration task. For example, if you want to configure total migration + incremental migration of two data views: dtstest_view1 (id for primary key column) and dtstest_view2 (user_id and name for primary key column) in a data migration task, you can configure the designated primary key as follows: dtstest_view1[id]; dtstest_view2[user_id,name]. Different views are connected with a semicolon (;), and different primary key columns are connected with a comma (,) under the same view.
5.3.2 Object mapping
In the Object Mapping Configuration page, the difference between the data view feature and the normal migration task is that you need to configure the table name mapping for the entity table of the same data view to ensure total and incremental change records of multiple tables at the source end can be written into the same Elasticsearch index at the destination.
As shown in the following figure, the three tables, including multipktbl1, multipktbl2, and multipktbl3, belong to the same data view. Thus, the destination table names of the three tables are configured as view. The configured destination Elasticsearch index name is as follows: Mapped DataBase Name_Mapped Table Name (dtstest_view)** The index name corresponds to the index name in the primary key configuration (dtstest_view[pk_id]) designated in the previous step**