
GPU资源调度-显存隔离
更新时间:2025-08-21
1 功能说明
GPU显存隔离在GPU显存共享的基础上,加入了显存资源逻辑隔离的能力。两者主要区别如下:
- 通过显存隔离,可以将1张大显存的物理GPU卡虚拟化成多张小显存的虚拟机GPU卡。并且保障运行在虚拟GPU上的服务之间相互隔离、互不影响。 假定运行在虚拟机GPU上的服务需要的显存大于分配给他的显存,则该服务将启动失败,服务获取不到超过分配给他的显存资源。
- 相比于显存隔离,显存共享场景下,即使给服务指定了显存大小限制,服务还是可以调用大于分配的显存资源,从而可能出现抢占其他服务资源的情况。
2 依赖条件
- 先完成NVIDIA GPU资源监控。
- NVIDIA CUDA版本:使用11.4版本cuda及配套驱动,可在官网下载。
-
云原生环境依赖说明:
- K8s场景:如果是K8s环境,适配使用官网推荐的kubeadm方式创建K8s环境,参考官网安装指南。并不适配公有云云原生K8s环境。用户可以租用公有云裸金属GPU主机,然后按照K8s官方教程使用kubeadm搭建环境。
- K3s场景:如果是K3s环境,适配使用K3s官方安装命令创建的K3s环境。
3 操作指南
3.1 显存隔离插件安装
- 进入节点详情页面,找到AI加速卡,如下图所示:
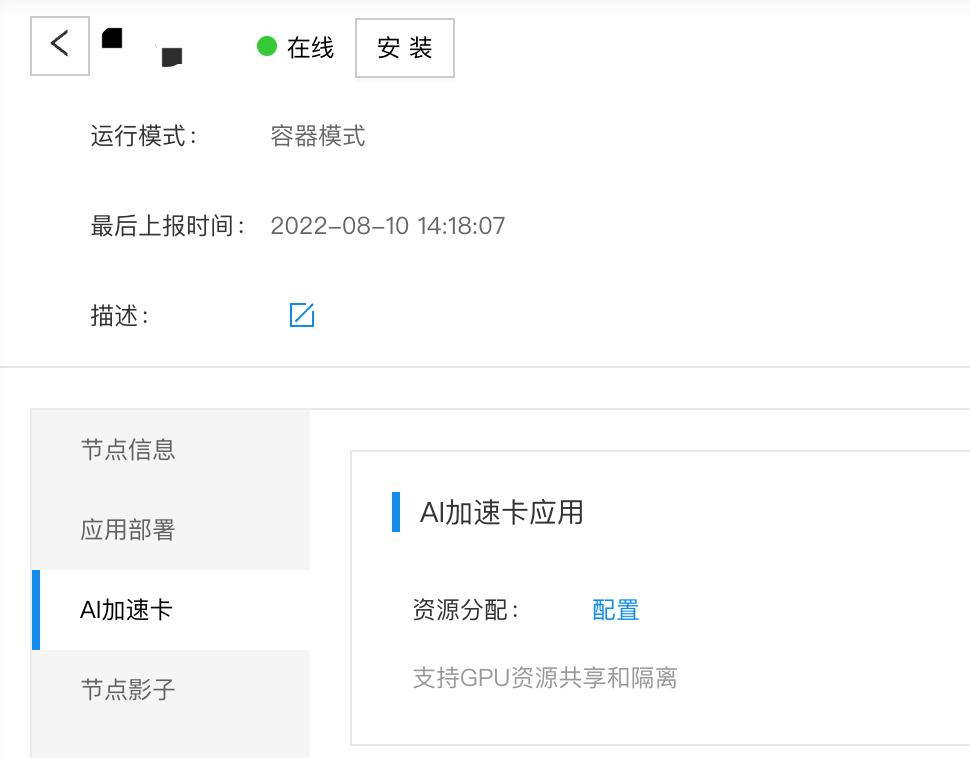
- 点击【配置】弹出对话框,包括有安装和卸载GPU共享的命令,将命令复制并在设备上执行。以安装GPU共享为例,先复制对话框中的应用安装命令:
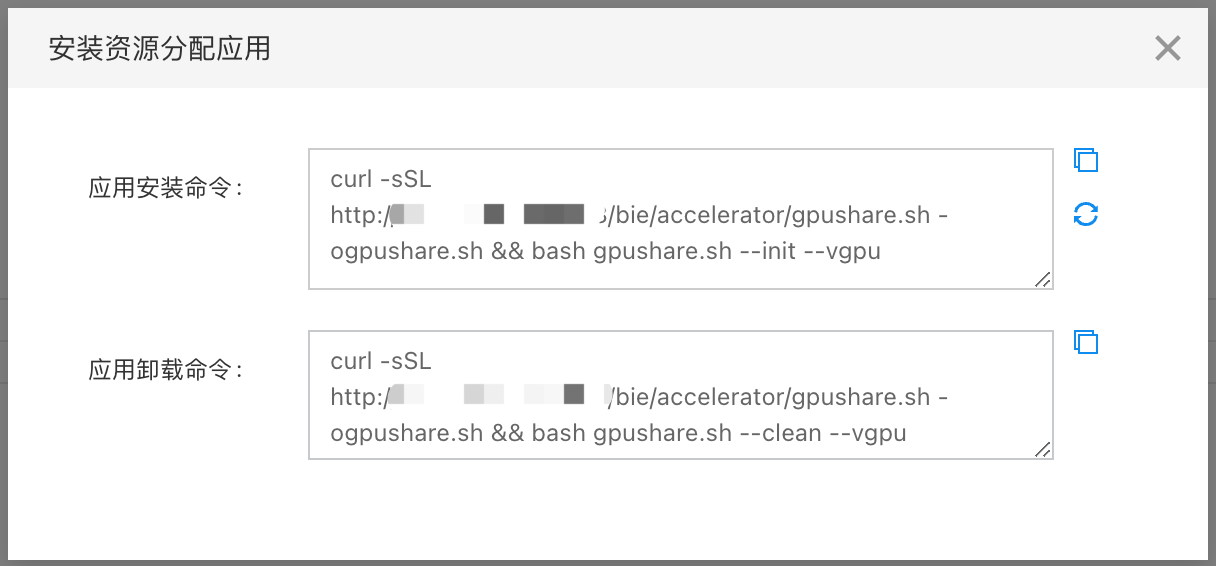
- 在设备上执行该命令,会要求用户选择有GPU加速卡的Kubernetes节点,并给相应节点添加标签。当前节点只有一个,输入提示的节点名即可。

- 随后等安装完成,由于该功能安装应用的镜像较大,拉取镜像时间可能较长。需要等待镜像拉取完成并启动后才会完成安装。安装完成以后会自动重启Kubernetes的调度服务,使得显存隔离生效。查看kube-system命名空间下的pod,如果以下4个pod正常运行,即表示显存隔离插件安装成功。
Plain Text
1kubectl get pod -A
2NAMESPACE NAME READY STATUS RESTARTS AGE
3kube-system nvidia-mps-76544 1/1 Running 0 2m30s
4kube-system baidu-cgpu-monitor-wc2n5 1/1 Running 0 2m30s
5kube-system gpushare-scheduler-extender-b94cs 1/1 Running 0 2m18s
6kube-system nvidia-shared-device-plugin-daemonset-c5qdx 1/1 Running 0 2m- 卸载GPU显存隔离插件的过程和安装类似,只需要复制卸载命令在边缘节点设备上运行即可。
3.2 手动配置显存隔离并验证
在边缘节点上安装完GPU显存隔离插件以后,进入到应用部署,找到测试的GPU应用,对测试应用进行显存隔离配置。
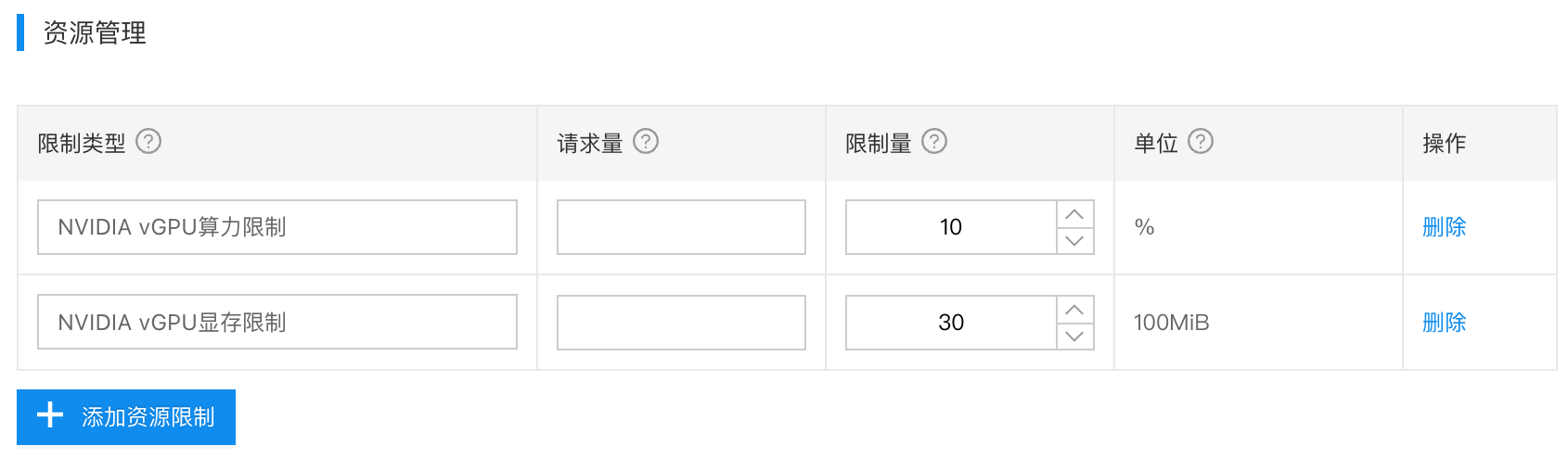
3.2.1 资源管理
找到资源管理,添加以下2个限制项,如下图所示:
3.2.2 环境变量
找到环境变量,添加以下6个环境变量配置,如下图所示:
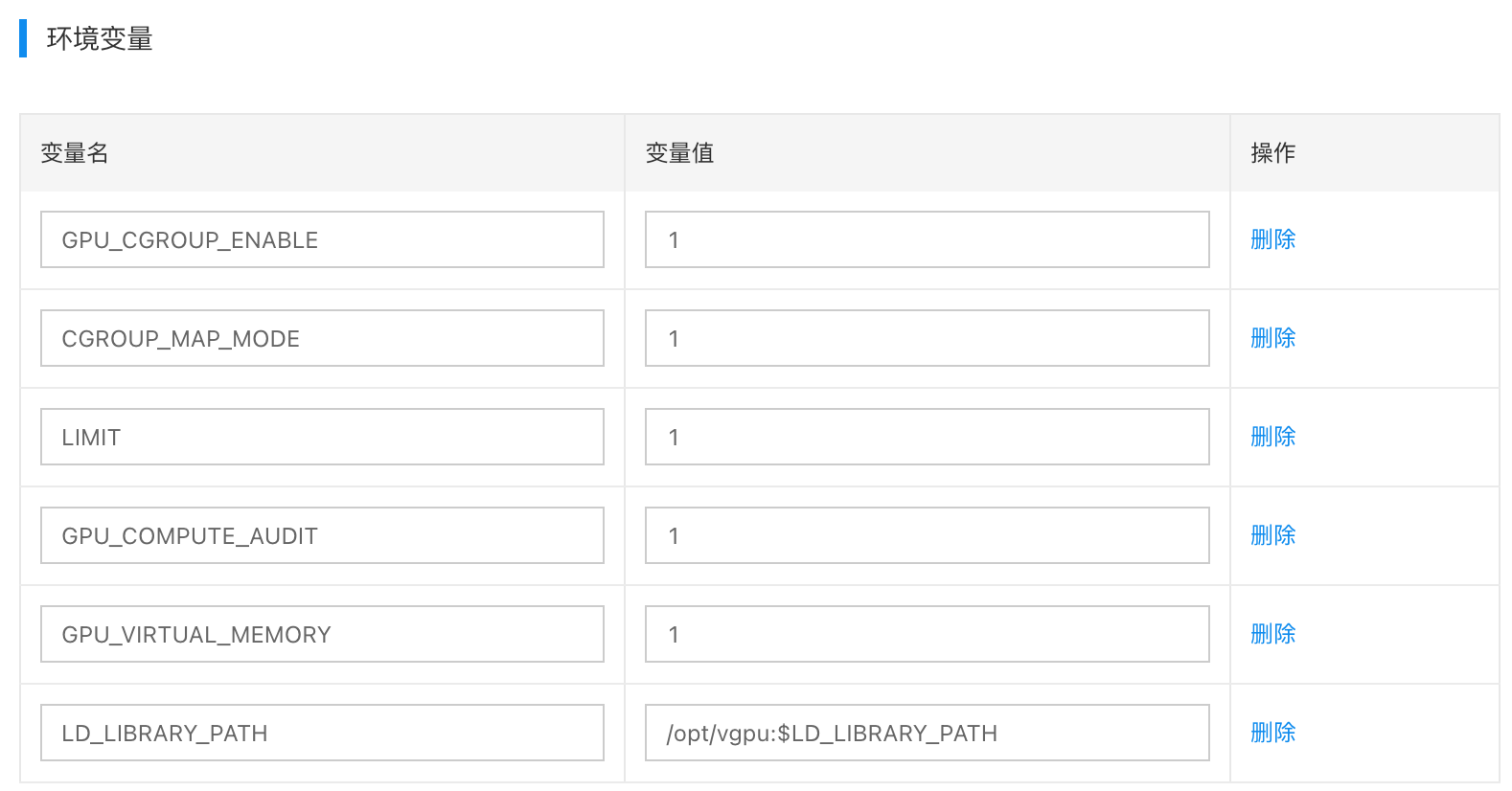
- GPU_CGROUP_ENABLE=1
- LIMIT=1
- CGROUP_MAP_MODE=1
- GPU_COMPUTE_AUDIT=1
- GPU_VIRTUAL_MEMORY=1
- LD_LIBRARY_PATH=/opt/vgpu:$LD_LIBRARY_PATH
3.2.3 启动显存隔离
- 通过远程调试进入到边缘AI服务容器内。如果不使用远程调试功能的话,可以直接在边缘节点上执行如下命令进入到容器内:
Shell
1kubectl exec -it [pod-name] -n baetyl-edge bash- 在边缘容器内,执行以下命令,手动启动显存隔离:
Bash
1/opt/vgpu/manage --reset- 在容器内执行查看资源隔离情况
Shell
1# 进入容器
2~# kubectl exec -it vgpu-memory-usage-1200mib-6dbd95489d-j2kjd -n baetyl-edge bash
3kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl kubectl exec [POD] -- [COMMAND] instead.
4
5# 手动开启显存隔离
6[root@vgpu-memory-usage-1200mib-749f9b65cc-l595n /]# /opt/vgpu/manage --reset
7manage.cpp:87 GPU DEVICE 0 FOUND IN DEV.
8loader.cpp:190 Line read: 13:devices:/kubepods/besteffort/podb67ccdb1-89aa-42dc-8b55-f10d9d05162f/ee5a230e75ac6734344b7fbd1b915313e23efd71aac5e3bbf0043383d1078918
9
10Use exist sem.
11stats.cpp:77 Total buffers allocated: 30720
12stats.cpp:78 Total buffers freed: 0
13stats.cpp:81 possible memory leak!
14stats.cpp:84 Total memory allocated: 1258291200
15stats.cpp:85 Total memory freed: 0
16stats.cpp:86 Peak memory: 1258291200
17stats.cpp:87 Peak # of buffers: 30720
18stats.cpp:92 index[0] pid[8] live_memory[1258291200]
19
20# 在容器内查看显存容器,可以看到是限制量3000MiB
21[root@vgpu-memory-usage-1200mib-6dbd95489d-j2kjd /]# nvidia-smi
22Fri Nov 4 11:51:17 2022
23+-----------------------------------------------------------------------------+
24| NVIDIA-SMI 470.42.01 Driver Version: 470.42.01 CUDA Version: 11.4 |
25|-------------------------------+----------------------+----------------------+
26| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
27| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
28| | | MIG M. |
29|===============================+======================+======================|
30| 0 NVIDIA GeForce ... Off | 00000000:17:00.0 On | N/A |
31| 33% 62C P2 114W / 350W | 0MiB / 3000MiB | 90% Default |
32| | | ERR! |
33+-------------------------------+----------------------+----------------------+
34
35+-----------------------------------------------------------------------------+
36| Processes: |
37| GPU GI CI PID Type Process name GPU Memory |
38| ID ID Usage |
39|=============================================================================|
40| No running processes found |
41+-----------------------------------------------------------------------------+3.2.4 开发建议
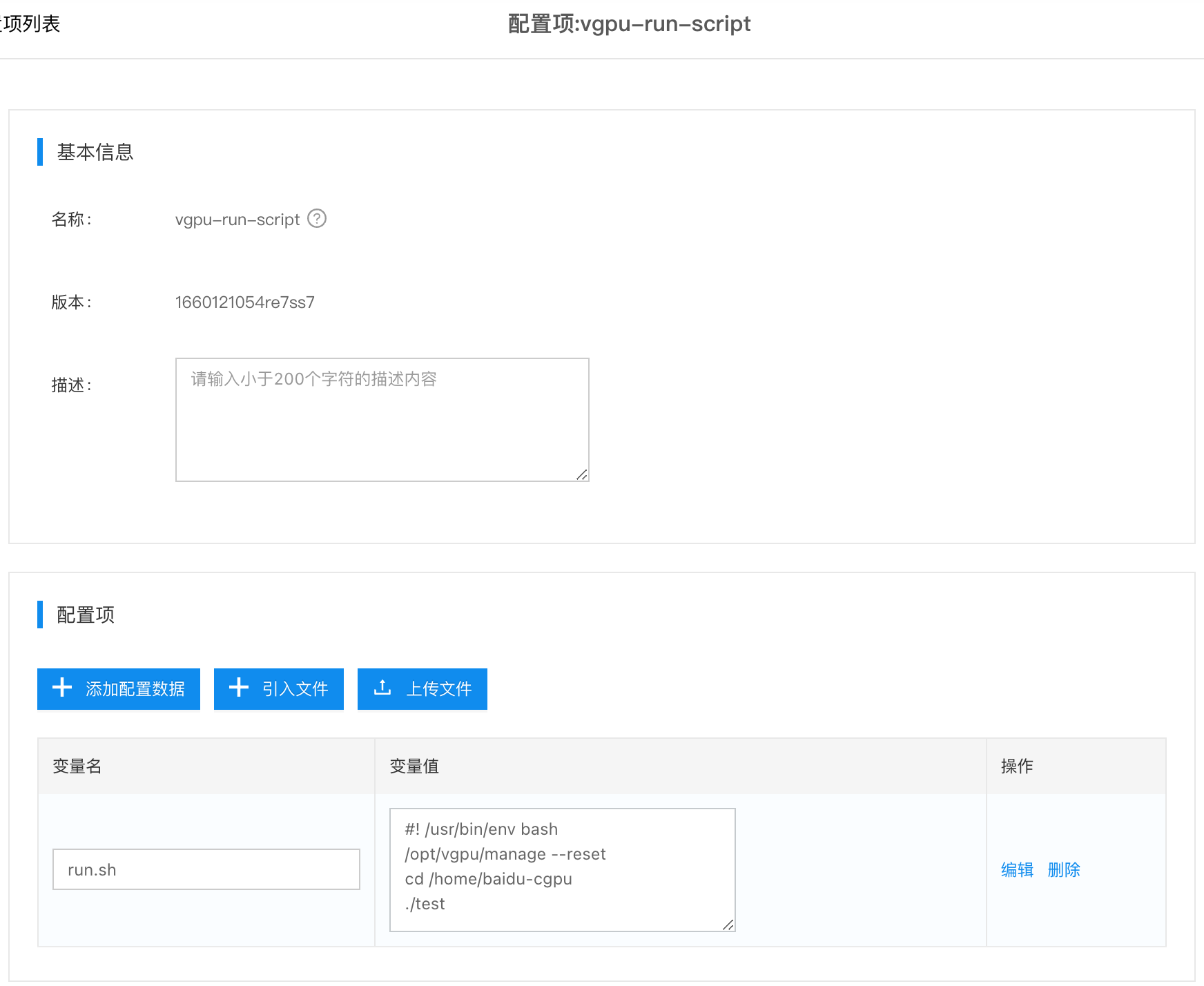
- 可以将上述
/opt/vgpu/manage --reset指令放到AI应用容器的启动脚本(sh脚本)的最前面执行,实现自动显存隔离,避免手动操作。 - 启动脚本可以通过BIE配置项创建,并通过BIE下发至边缘AI应用容器,假定AI程序是
/home/baidu-cgpu/test,在容器内启动显存隔离+启动AI程序的示例脚本如下:
Bash
1#! /usr/bin/env bash
2# 启动显存隔离命令
3/opt/vgpu/manage --reset
4# 启动调用显存占用命令
5cd /home/baidu-cgpu
6./test- 配置项如下图所示,配置项的key为run.sh,将作为AI容器应用的启动参数。具体使用方式可以参考示例应用。
3.3 导入示例应用并验证
3.3.1 导入示例配置与应用
按照顺序导入如下2个配置项和1个应用:
- 导入:配置项-vgpu-memory-usage-1200mib.json
- 导入:配置项-vgpu-run-script.json
- 导入:应用-vgpu-memory-usage-1200mib.json
- 将上述vgpu-memory-usage-1200mib部署至边缘节点,该示例应用默认分配了3000MiB的显存容器,启动时将默认占用1200MiB的显存容量。
3.3.2 显存隔离验证
- 在部署示例以后,在边缘查看应用信息,可以看到 vgpu-memory-usage-1200mib 处于running状态。
Shell
1~# kubectl get pod -A
2NAMESPACE NAME READY STATUS RESTARTS AGE
3kube-system metrics-server-9cf544f65-6mvjh 1/1 Running 11 (9h ago) 71d
4kube-system baidu-cgpu-monitor-h2tfb 1/1 Running 0 10h
5kube-system nvidia-mps-lgzzs 1/1 Running 0 10h
6kube-system gpushare-scheduler-extender-6rhtp 1/1 Running 0 10h
7kube-system coredns-85cb69466-c9srp 1/1 Running 13 (9h ago) 71d
8kube-system nvidia-shared-device-plugin-daemonset-wrt79 1/1 Running 1 (9h ago) 10h
9baetyl-edge-system baetyl-init-5d498cb794-9597m 1/1 Running 0 103m
10baetyl-edge-system baetyl-core-fgx6r54tv-79789cb988-jjq2s 1/1 Running 0 102m
11baetyl-edge-system baetyl-accelerator-metrics-whxp3xvrg-c4ztc 1/1 Running 0 102m
12baetyl-edge-system baetyl-broker-enkb2phdr-7887ffd664-58pcm 1/1 Running 0 102m
13baetyl-edge-system baetyl-agent-aamegzfdb-vtxk5 1/1 Running 0 102m
14baetyl-edge vgpu-memory-usage-1200mib-749f9b65cc-l595n 1/1 Running 0 50m- 进入边缘容器,查看该容器的GPU显存分配以及显存占用。可以看到,显存大小被限制为3000MiB,与云端配置的资源限制保持一致。实际调用的显存为1200MiB,与测试程度申请的显存大小一致。
Bash
1~# kubectl exec -it vgpu-memory-usage-1200mib-749f9b65cc-l595n -n baetyl-edge bash
2kubectl exec [POD] [COMMAND] is DEPRECATED and will be removed in a future version. Use kubectl kubectl exec [POD] -- [COMMAND] instead.
3[root@vgpu-memory-usage-1200mib-749f9b65cc-l595n /]# nvidia-smi
4Fri Nov 4 12:08:09 2022
5+-----------------------------------------------------------------------------+
6| NVIDIA-SMI 470.42.01 Driver Version: 470.42.01 CUDA Version: 11.4 |
7|-------------------------------+----------------------+----------------------+
8| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
9| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
10| | | MIG M. |
11|===============================+======================+======================|
12| 0 NVIDIA GeForce ... Off | 00000000:17:00.0 On | N/A |
13| 40% 63C P2 115W / 350W | 1200MiB / 3000MiB | 100% Default |
14| | | ERR! |
15+-------------------------------+----------------------+----------------------+
16
17+-----------------------------------------------------------------------------+
18| Processes: |
19| GPU GI CI PID Type Process name GPU Memory |
20| ID ID Usage |
21|=============================================================================|
22| No running processes found |
23+-----------------------------------------------------------------------------+- 在宿主机上执行
nvidia-smi,我们可以看到总显存是24259MiB,与物理显卡一致,使用显存为1719MiB。同时有可以看到调用显存的测试程序是./vgpu-memory-usage-1200mib,与实际一致。
Bash
1~$ nvidia-smi
2Fri Nov 4 21:01:30 2022
3+-----------------------------------------------------------------------------+
4| NVIDIA-SMI 470.42.01 Driver Version: 470.42.01 CUDA Version: 11.4 |
5|-------------------------------+----------------------+----------------------+
6| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
7| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
8| | | MIG M. |
9|===============================+======================+======================|
10| 0 NVIDIA GeForce ... Off | 00000000:17:00.0 On | N/A |
11| 35% 61C P2 115W / 350W | 1607MiB / 24259MiB | 14% Default |
12| | | N/A |
13+-------------------------------+----------------------+----------------------+
14
15+-----------------------------------------------------------------------------+
16| Processes: |
17| GPU GI CI PID Type Process name GPU Memory |
18| ID ID Usage |
19|=============================================================================|
20| 0 N/A N/A 1311 G /usr/lib/xorg/Xorg 35MiB |
21| 0 N/A N/A 1846 G /usr/lib/xorg/Xorg 54MiB |
22| 0 N/A N/A 2054 G /usr/bin/gnome-shell 19MiB |
23| 0 N/A N/A 2370569 C ./vgpu-memory-usage-1200mib 251MiB |
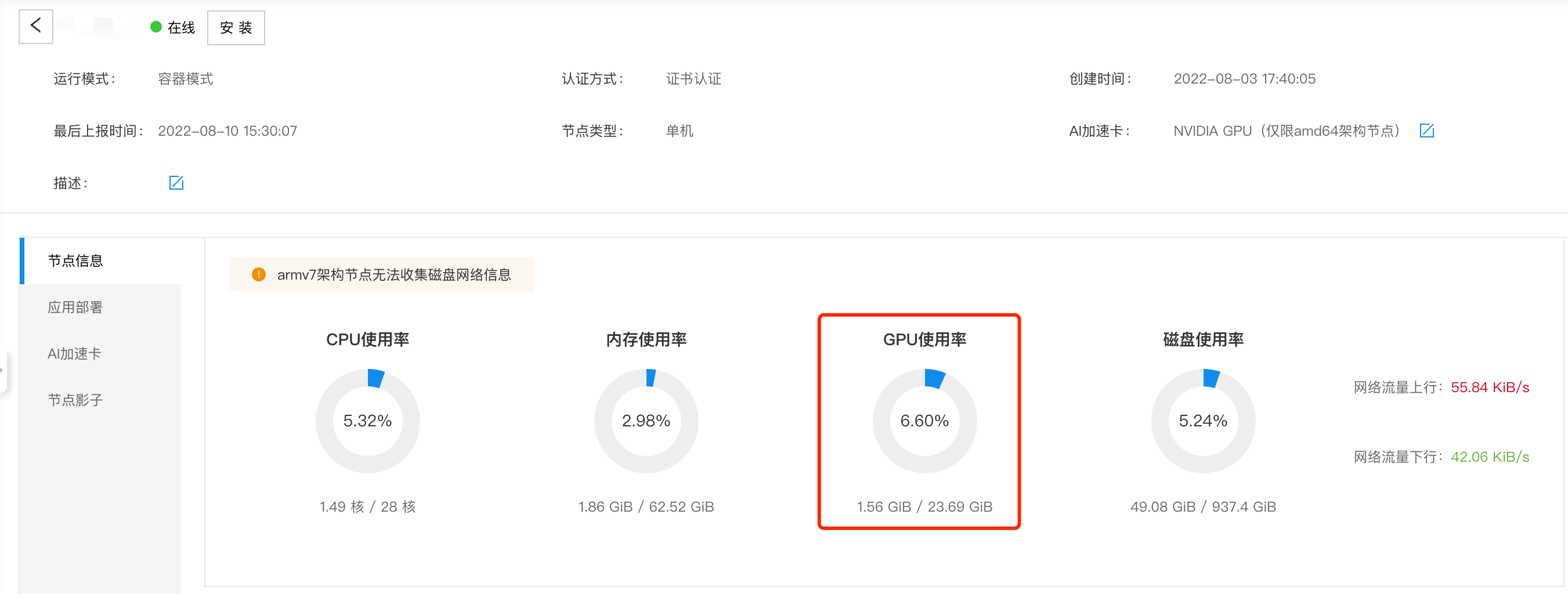
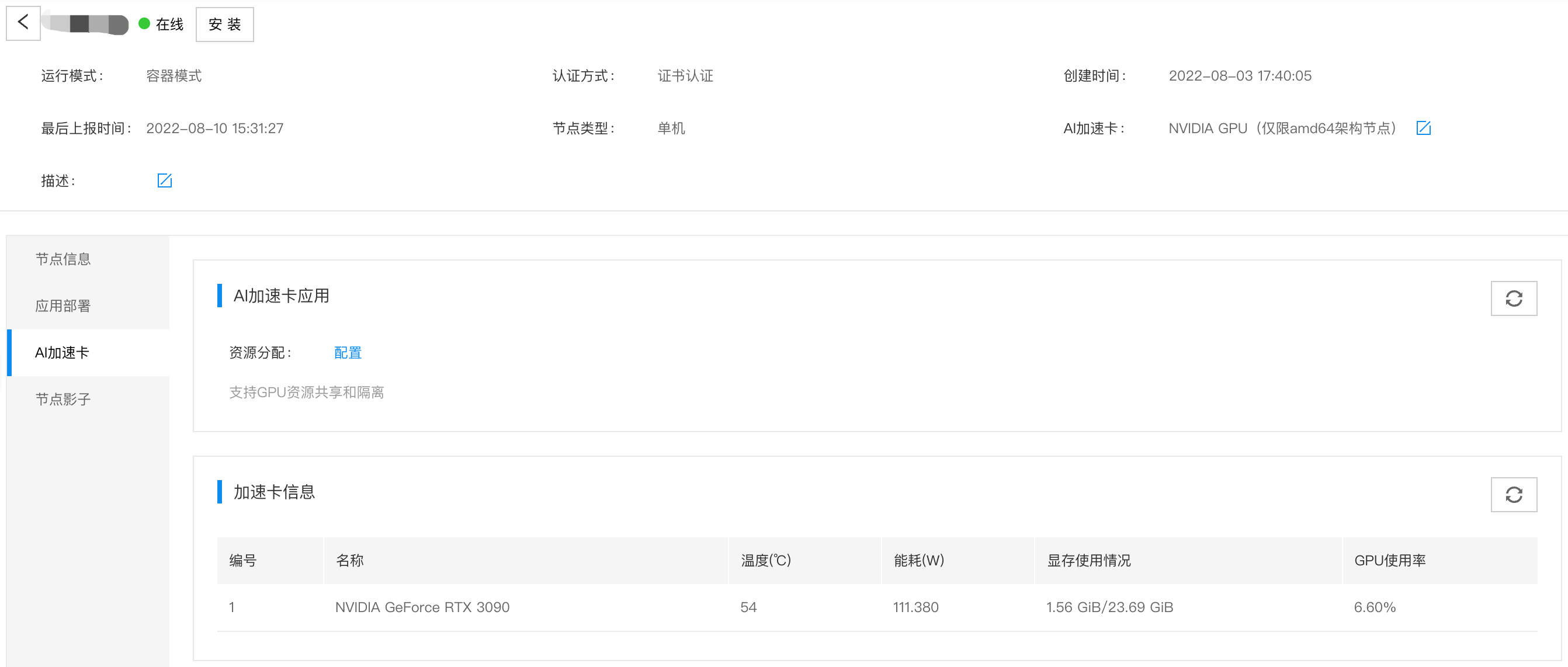
24+-----------------------------------------------------------------------------+- 在云端查看GPU使用情况,结果如下图所示,整体与边缘侧保持一致。
- 将显存限制设置为10 * 1000MiB,则测试程序无法启动,提示显存申请失败,是因为 显存限制值(1000MiB) < 程序实际显存值使用值(1200MiB)。
3.3.3 多卡调度验证
- 机器环境:有2张12G显存的单机服务上,
- 应用配置1:vgpu-memory-usage-1200mib应用开启2个实例,显存限制值设置为8000MiB,则可以看到2个vgpu-memory-usage-1200mib实例使用2张显卡。
- 应用配置2:vgpu-memory-usage-1200mib应用开启2个实例,显存限制值设置为2000MiB,则可以看到2个vgpu-memory-usage-1200mib实例使用1张显卡。
- 可以通过一下方式查看vgpu-memory-usage-1200mib实例实际使用的显卡。
Bash
1kubectl exec -it pod-name bash
2nvidia-smi -L