
NVIDIA Jetson专用模型部署-容器模式
本文针对NVIDIA Jetson nano设备,介绍如何获取适配的端模型文件,并结合NVIDIA L4T Base镜像,将模型部署至BIE,完成AI图像识别。
1、jetson nano版本依赖说明
本实验的模型依赖于以下版本。
jetpack版本
查看jetpack版本,版本号为4.3。
1nano@jetson-nano:~$ head -n 1 /etc/nv_tegra_release
2# R32 (release), REVISION: 4.3, GCID: 21589087, BOARD: t210ref, EABI: aarch64, DATE: Fri Jun 26 04:38:25 UTC 2020cuda-driver版本
查看cudu驱动版本,版本号为10.2。
1nano@jetson-nano:~$ dpkg -l | grep cuda-driver
2ii cuda-driver-dev-10-2 10.2.89-1 arm64 CUDA Driver native dev stub libraryTensorRT版本
查看TensorRT版本,版本号7.1.3。
1nano@jetson-nano:~$ dpkg -l | grep TensorRT
2ii graphsurgeon-tf 7.1.3-1+cuda10.2 arm64 GraphSurgeon for TensorRT package
3ii libnvinfer-bin 7.1.3-1+cuda10.2 arm64 TensorRT binaries
4ii libnvinfer-dev 7.1.3-1+cuda10.2 arm64 TensorRT development libraries and headers
5ii libnvinfer-doc 7.1.3-1+cuda10.2 all TensorRT documentation
6ii libnvinfer-plugin-dev 7.1.3-1+cuda10.2 arm64 TensorRT plugin libraries
7ii libnvinfer-plugin7 7.1.3-1+cuda10.2 arm64 TensorRT plugin libraries
8ii libnvinfer-samples 7.1.3-1+cuda10.2 all TensorRT samples
9ii libnvinfer7 7.1.3-1+cuda10.2 arm64 TensorRT runtime libraries
10ii libnvonnxparsers-dev 7.1.3-1+cuda10.2 arm64 TensorRT ONNX libraries
11ii libnvonnxparsers7 7.1.3-1+cuda10.2 arm64 TensorRT ONNX libraries
12ii libnvparsers-dev 7.1.3-1+cuda10.2 arm64 TensorRT parsers libraries
13ii libnvparsers7 7.1.3-1+cuda10.2 arm64 TensorRT parsers libraries
14ii nvidia-container-csv-tensorrt 7.1.3.0-1+cuda10.2 arm64 Jetpack TensorRT CSV file
15ii python-libnvinfer 7.1.3-1+cuda10.2 arm64 Python bindings for TensorRT
16ii python-libnvinfer-dev 7.1.3-1+cuda10.2 arm64 Python development package for TensorRT
17ii python3-libnvinfer 7.1.3-1+cuda10.2 arm64 Python 3 bindings for TensorRT
18ii python3-libnvinfer-dev 7.1.3-1+cuda10.2 arm64 Python 3 development package for TensorRT
19ii tensorrt 7.1.3.0-1+cuda10.2 arm64 Meta package of TensorRT
20ii uff-converter-tf 7.1.3-1+cuda10.2 arm64 UFF converter for TensorRT package2、上传模型文件包至对象存储
- 将模型文件包fruit-ai-model.zip上传至BOS。
-
模型文件包制作方式参考最后章节。
说明:这个模型包必须部署在能够连接公网的设备上才能生效,因为需要在线激活license,在无法联网的环境当中,无法使用。
3、云端配置
3.1. 创建边缘节点
如下图所示,创建边缘节点jetson-nano

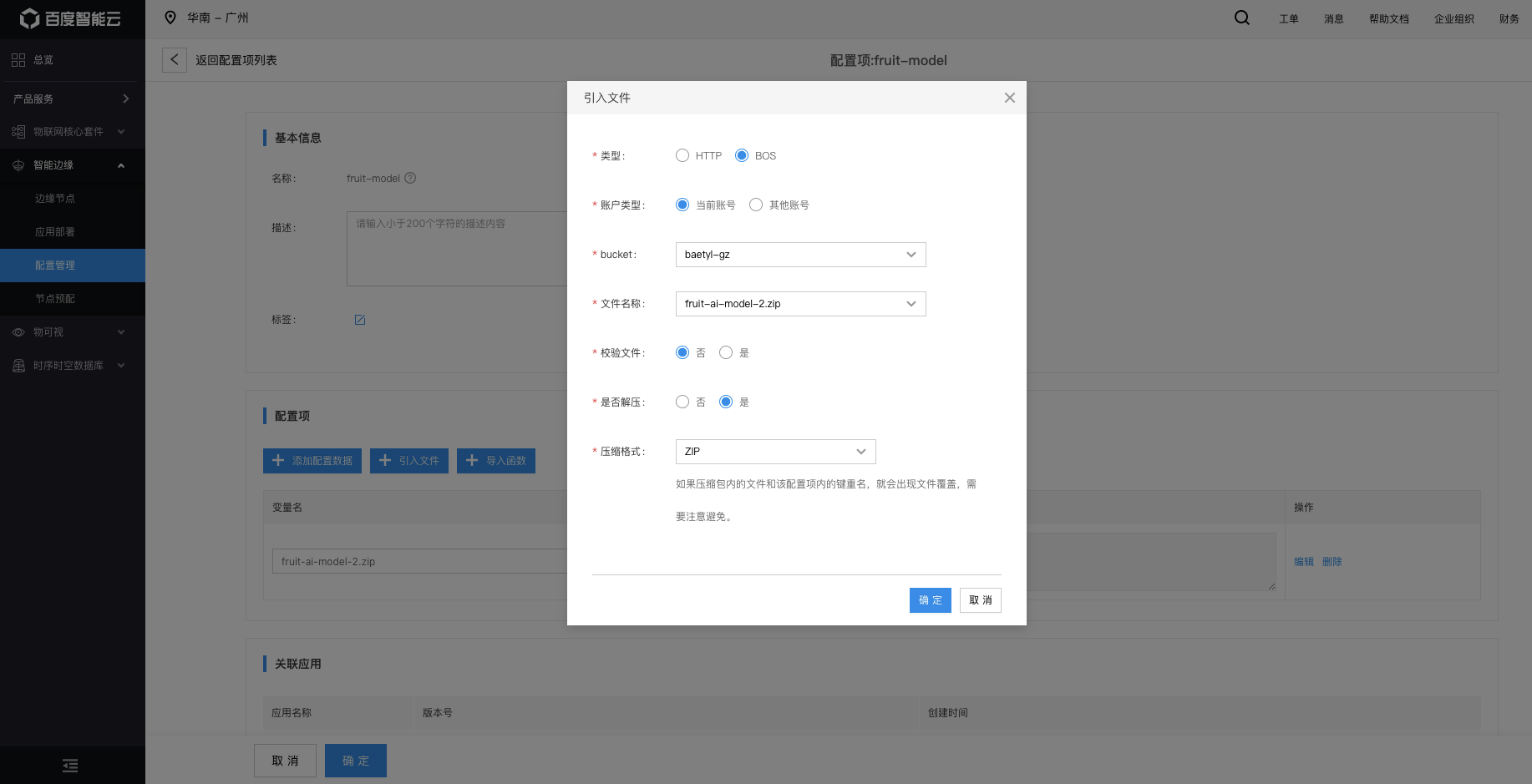
3.2. 创建AI模型配置项
如下图所示,创建配置项:fruit-demo。引入上传至BOS对象存储的模型文件。
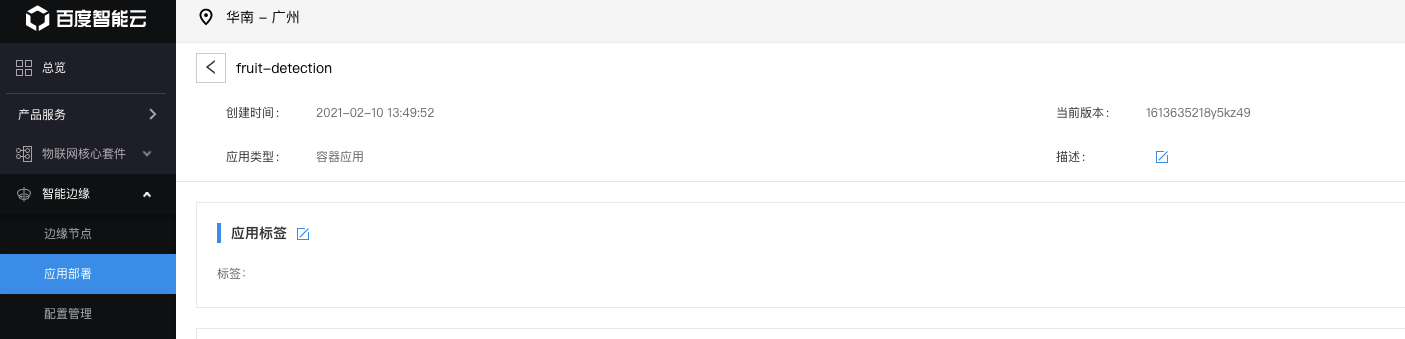
3.3. 创建AI推断服务
如下图所示,创建应用fruit-detection
在应用当中添加一个容器服务,如下图所示:
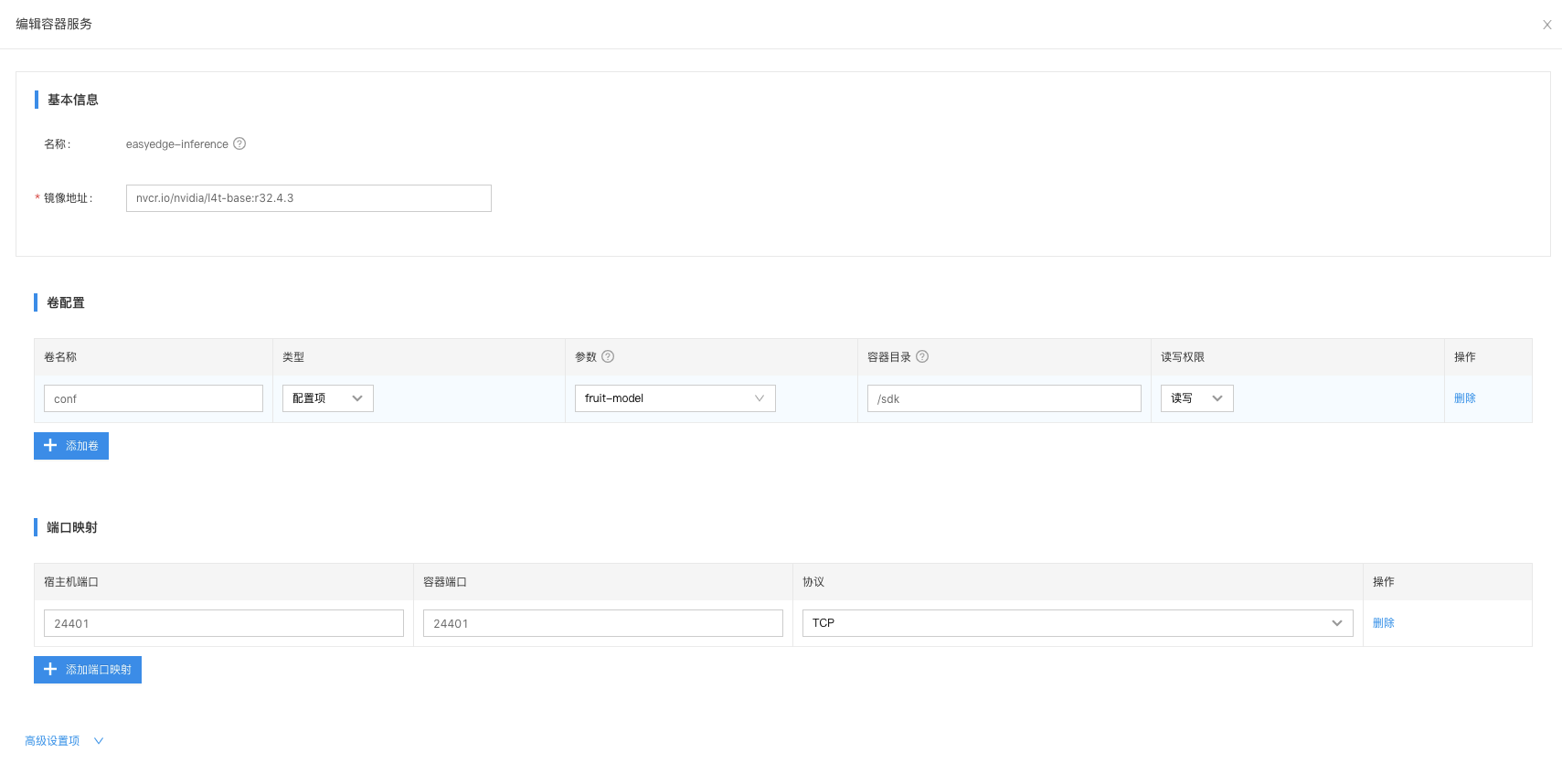

- 镜像地址:nvidia提供了一个面向NVIDIA Jetson系列的容器景象:NVIDIA L4T Base。nvidia官网获取方式:https://ngc.nvidia.com/catalog/containers/nvidia:l4t-base。 该容器镜像提供nvidia jetson的运行环境,能够实现在容器内跑支持jetson设备的AI模型服务。在支持容器化以后,可以通过BIE来管理边缘节点设备,以及提升模型服务部署的效率。
NVIDIA L4T Base官网镜像获取地址:nvcr.io/nvidia/l4t-base:r32.4.3。如果国内下载速度很慢,可以从百度cce上下载镜像:hub.baidubce.com/nvidia/l4t-base:r32.4.3-arm64
- 卷配置:类型为配置项;参数选择之前创建的文件配置项;容器目录:/sdk(与run.sh文件对应)。通过卷配置,实现AI推断服务与模型文件绑定。将推断服务下发至边缘节点的时候,会自动下载AI模型文件。
- 容器服务的端口映射:端口为24401;协议为TCP
- 容器服务的启动参数:bash;/sdk/run.sh
- 无需开启特权模式
3.4. 将应用部署至节点
在边缘应用当中,添加目标节点标签

4、边缘端配置
在jetson nano设备上安装节点
4.1 配置jetson上docker的default runtime为nvidia
执行docker info查看边缘节点容器环境,确保Default Runtime: nvidia
1nano@jetson-nano:~/Downloads/fruit-ai-model$ docker info
2Client:
3 Debug Mode: false
4
5Server:
6 Containers: 38
7 Running: 21
8 Paused: 0
9 Stopped: 17
10 Images: 12
11 Server Version: 19.03.6
12 Storage Driver: overlay2
13 Backing Filesystem: extfs
14 Supports d_type: true
15 Native Overlay Diff: true
16 Logging Driver: json-file
17 Cgroup Driver: cgroupfs
18 Plugins:
19 Volume: local
20 Network: bridge host ipvlan macvlan null overlay
21 Log: awslogs fluentd gcplogs gelf journald json-file local logentries splunk syslog
22 Swarm: inactive
23 Runtimes: nvidia runc
24** Default Runtime: nvidia**
25 Init Binary: docker-init
26 containerd version:
27 runc version:
28 init version:
29 Security Options:
30 seccomp
31 Profile: default
32 Kernel Version: 4.9.140-tegra
33 Operating System: Ubuntu 18.04.5 LTS
34 OSType: linux
35 Architecture: aarch64
36 CPUs: 4
37 Total Memory: 3.871GiB
38 Name: jetson-nano
39 ID: O7GP:DDD5:5CIR:LEWJ:2BQ3:4WIW:VA4H:JDCP:5VGL:L2K3:PLZ7:KBHO
40 Docker Root Dir: /var/lib/docker
41 Debug Mode: false
42 Registry: https://index.docker.io/v1/
43 Labels:
44 Experimental: false
45 Insecure Registries:
46 127.0.0.0/8
47 Live Restore Enabled: false如果Default Runtime不是nvidia,修改/etc/docker/daemon.json文件,添加"default-runtime": "nvidia",修改完毕以后的/etc/docker/daemon.json文件
1nano@jetson-nano:~$ cat /etc/docker/daemon.json
2{
3 "default-runtime": "nvidia",
4 "runtimes": {
5 "nvidia": {
6 "path": "nvidia-container-runtime",
7 "runtimeArgs": []
8 }
9 }
10}修改完毕以后,重启docker
1sudo systemctl restart docker4.2 运行安装命令
- 在copy云端边缘节点安装命令
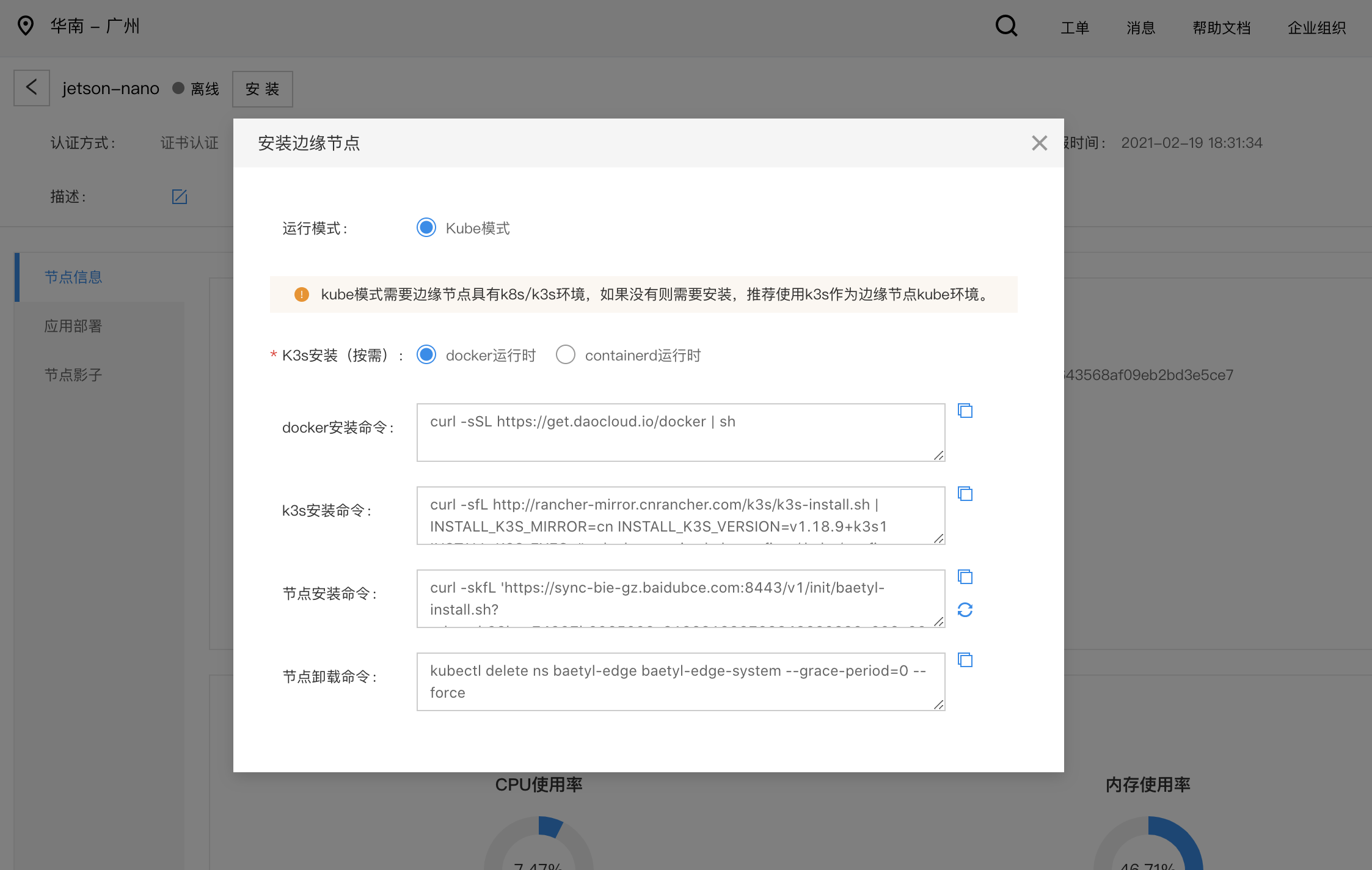
- 在边缘节点执行安装命令
5、验证边缘节点AI推断服务
通过浏览器打开在线推断服务:http://「ip」 :24401/,上传测试图片,推断结果如下,证明AI服务正常启动。

6、easyedge模型包制作方案
6.1. 利用easyedge获取适配jetson nano环境的SDK
上传原始模型
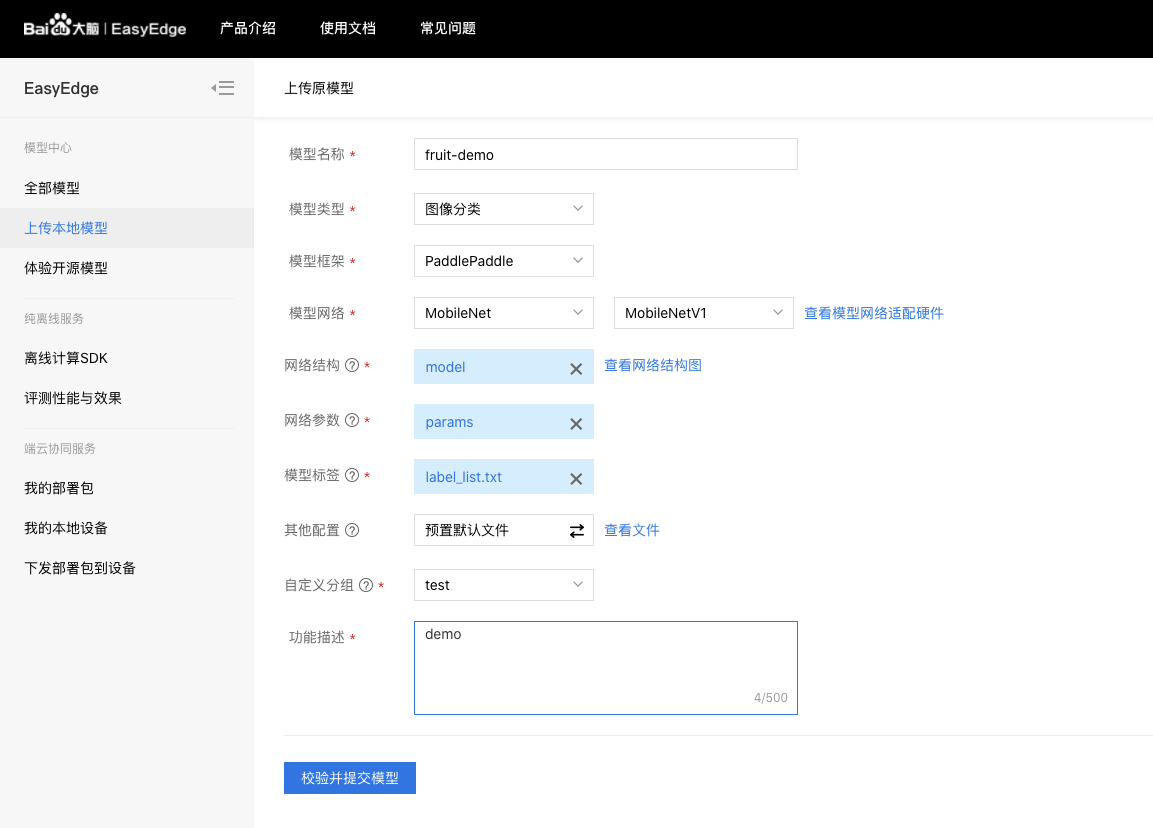
模型提交后,在我的模型界面生成端模型。选择对应的芯片和操作系统,点击发布,获取SDK文件。

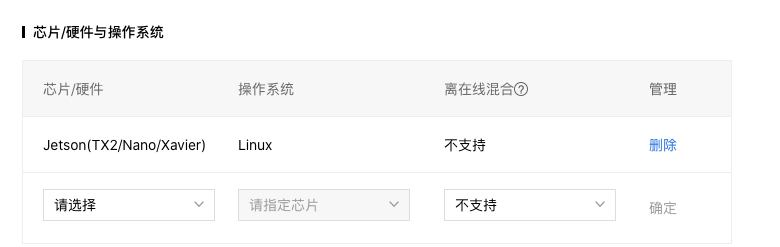
6.2. SDK编译和验证
对SDK文件进行编译和认证,生成在jetson设备上可运行的模型。
- 注意:使用EasyDL的Jetson系列SDK需要安装指定版本的JetPack和相关组件。目前所支持的JetPack版本包括:JetPack4.4和JetPack4.2.2
模型资源文件默认已经打包在下载的SDK包中。Demo工程直接编译即可运行。
1cd demo
2mkdir build && cd build
3cmake .. && make
4sudo ./easyedge_demo {模型RES文件夹} {测试图片路径} {序列号}编译过程参考:
1`nano@jetson-nano:~/Downloads/easydl-sdk/cpp/baidu_easyedge_linux_cpp_aarch64_JetPack4.4_gcc7.4_v0.5.5_20200811/demo/build$ ls
2CMakeCache.txt CMakeFiles cmake_install.cmake easyedge_batch_inference easyedge.log easyedge_multi_thread easyedge_serving install_manifest.txt Makefile
3nano@jetson-nano:~/Downloads/easydl-sdk/cpp/baidu_easyedge_linux_cpp_aarch64_JetPack4.4_gcc7.4_v0.5.5_20200811/demo/build$ ./easyedge_batch_inference /home/nano/Downloads/easydl-sdk/RES /home/nano/Downloads/easydl-sdk/imgs/mix008.jpeg
42020-08-24 03:51:09,915 WARNING [EasyEdge] 548102246416 Only compile_level 2 is supported for this model on JetPack 4.4 DP version. Please read documentation for the details
52020-08-24 03:51:09,915 INFO [EasyEdge] 548102246416 Compiling model for fast inference, this may take a while (Acceleration)
62020-08-24 03:53:08,488 INFO [EasyEdge] 548102246416 Optimized model saved to: /home/nano/.baidu/easyedge/jetson/mcache/26119049355/m_cache, Don't remove it
7Results of image /home/nano/Downloads/easydl-sdk/imgs/mix008.jpeg:
81, tomato, p:0.999717 loc: 0.672033, 0.405379, 0.80056, 0.569352
92, kiwi, p:0.999273 loc: 0.154121, 0.0717932, 0.393312, 0.399547
102, kiwi, p:0.999206 loc: 0.45734, 0.0788124, 0.735513, 0.390724
111, tomato, p:0.998933 loc: 0.385497, 0.0432633, 0.51477, 0.22167
121, tomato, p:0.998886 loc: 0.520549, 0.384235, 0.654002, 0.552556
131, tomato, p:0.998507 loc: 0.295452, 0.452287, 0.422471, 0.588263
141, tomato, p:0.998191 loc: 0.181686, 0.568888, 0.295577, 0.712147
151, tomato, p:0.996489 loc: 0.386017, 0.250961, 0.504955, 0.408554
162, kiwi, p:0.991238 loc: 0.350772, 0.568207, 0.61708, 0.87927
17Done`验证过程参考:
1`nano@jetson-nano:~/Downloads/easydl-sdk/cpp/baidu_easyedge_linux_cpp_aarch64_JetPack4.4_gcc7.4_v0.5.5_20200811/demo/build$ ls
2CMakeCache.txt CMakeFiles cmake_install.cmake easyedge_batch_inference easyedge.log easyedge_multi_thread easyedge_serving install_manifest.txt Makefile
3nano@jetson-nano:~/Downloads/easydl-sdk/cpp/baidu_easyedge_linux_cpp_aarch64_JetPack4.4_gcc7.4_v0.5.5_20200811/demo/build$ ./easyedge_serving /home/nano/Downloads/easydl-sdk/RES "E60A-5124-5ACD-3C9B" 0.0.0.0 24401
42020-08-24 03:56:17,802 WARNING [EasyEdge] 548017537040 Only compile_level 2 is supported for this model on JetPack 4.4 DP version. Please read documentation for the details
52020-08-24 03:56:17,802 INFO [EasyEdge] 548017537040 Compiling model for fast inference, this may take a while (Acceleration)
62020-08-24 03:57:34,965 INFO [EasyEdge] 548017537040 Optimized model saved to: /home/nano/.baidu/easyedge/jetson/mcache/26119049355/m_cache, Don't remove it
72020-08-24 03:57:34,968 INFO [EasyEdge] 548017537040 HTTP is now serving at 0.0.0.0:24401, holding 1 instances
82020-08-24 03:57:55,502 INFO [EasyEdge] 548000241392 [access_log] "GET /" 200 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"
92020-08-24 03:57:55,582 INFO [EasyEdge] 548000241392 [access_log] "GET /api/info" 200 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"
102020-08-24 03:58:31,103 INFO [EasyEdge] 546816874224 [access_log] "POST /" 200 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36"6.3. 生成模型包
- 创建run.sh,该文件为容器的启动文件
1#SDK序列号,需要在线申请,此处为测试序列号
2license_key=E60A-5124-5ACD-3C9B
3#curr_dir为/sdk,后续在BIE推断服务配置当中用到,作为容器内的工作目录
4curr_dir=/sdk
5demo_dir=${curr_dir}/cpp/sdk/demo/build
6lib_dir=${curr_dir}/cpp/sdk/lib
7res_dir=${curr_dir}/RES
8export LD_LIBRARY_PATH=${lib_dir}:${LD_LIBRARY_PATH}
9#run
10${demo_dir}/easyedge_serving ${res_dir} ${license_key}2.将cpp目录、RES目录,以及run.sh文件打包成一个fruit-ai-model.zip文件,并上传至BOS对象存储。
- 注意:此处是将多个目录和文件压缩为一个zip文件,而不是直接压缩最外层的那个目录。如果压缩层级不对,将导致模型下载到边缘设备以后解压的目录不匹配。
- 编译好的模型包参考:fruit-ai-model.zip