
GPU资源调度-显存共享
功能说明
GPU显存共享功能主要是为了支持多个边缘AI服务可以运行在多张GPU卡上这个特性。当边缘节点上运行多个AI服务的时候,默认情况下,多个AI服务都会运行在GPU卡1上。这样即使边缘节点有多张AI计算卡,也无法动态调用到GPU卡2。使用GPU共享功能,通过设置边缘AI服务的显存容量需求,实现边缘AI服务在多卡之间的动态调度。GPU共享功能仅支持NVIDIA GPU amd64架构。
安装GPU共享功能后,与节点关联的应用可以配置应用的GPU资源限制。如未安装GPU共享功能,应用即使设置GPU资源限制,也无法生效,并且应用也无法在设备上部署运行。
依赖条件
- 先完成NVIDIA GPU资源监控。
- k3s环境,在安装完毕gpushare组件以后,需要重启一次k3s,可以使用命令
systemctl restart k3s。 - k8s环境,需要使用官网推荐的kubeadm方式创建集群,参考官网安装指南。使用这种方案安装的k8s集群,在master节点的
/etc/kubernetes/manifests目录下,会有kube-scheduler.yaml文件,这个是开启gpushare依赖的配置文件,如下图所示:

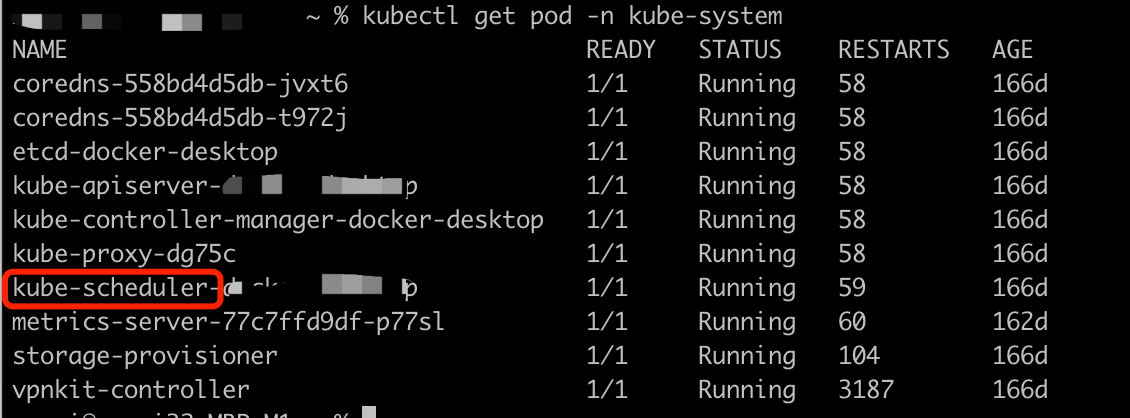
- 正常启动k8s,可以看到有
kube-scheduler这个pod,如下图所示:
特别说明:
- k3s和k8s版本不能大于等于1.21版本,当前测试可用的版本是1.18~1.20。
- GPU共享调度并不适配公有云云原生k8s环境。用户可以租用公有云BCC GPU主机,然后按照官方教程使用kubeadm搭建k8s。
操作指南
显存共享插件安装
1、进入节点详解页面,找到GPU应用,如下图所示:
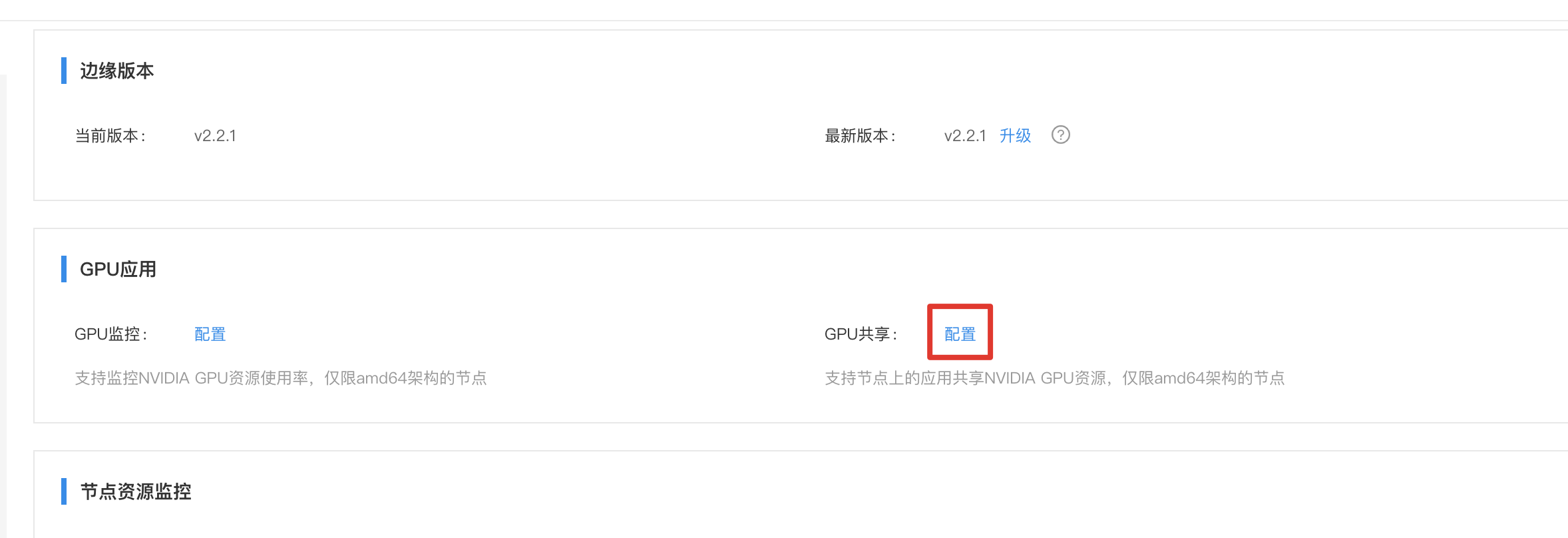
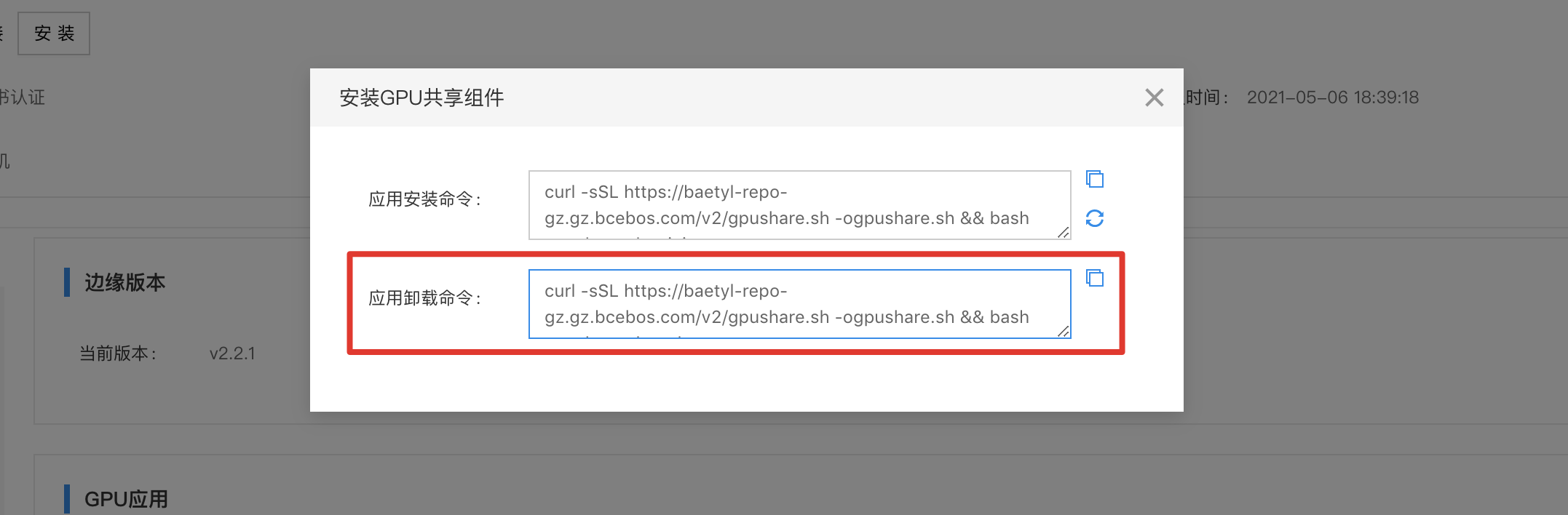
2、点击【配置】弹出对话框,包括有安装和卸载GPU共享的命令,将命令复制并在设备上执行。以安装GPU共享为例,先复制对话框中的应用安装命令:
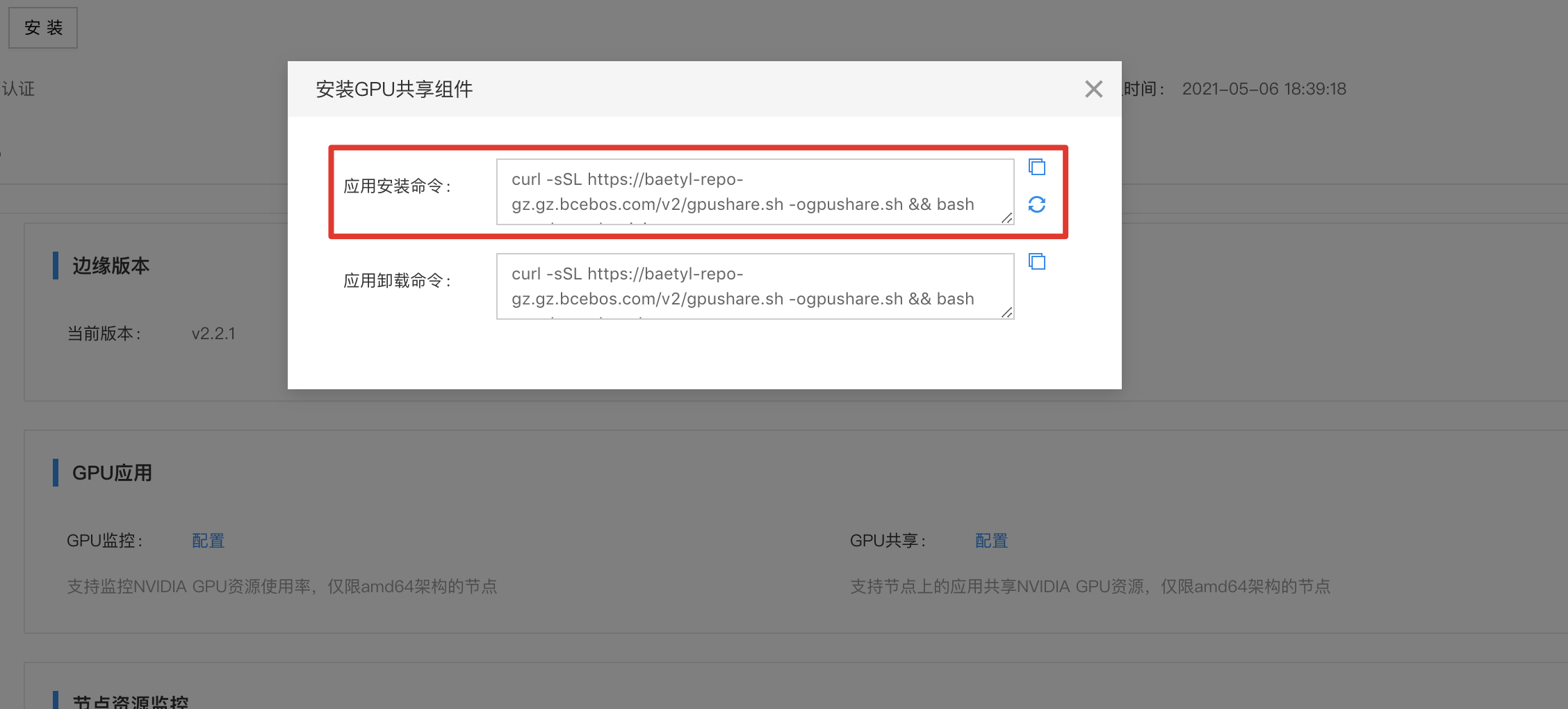
3、在设备上执行该命令。
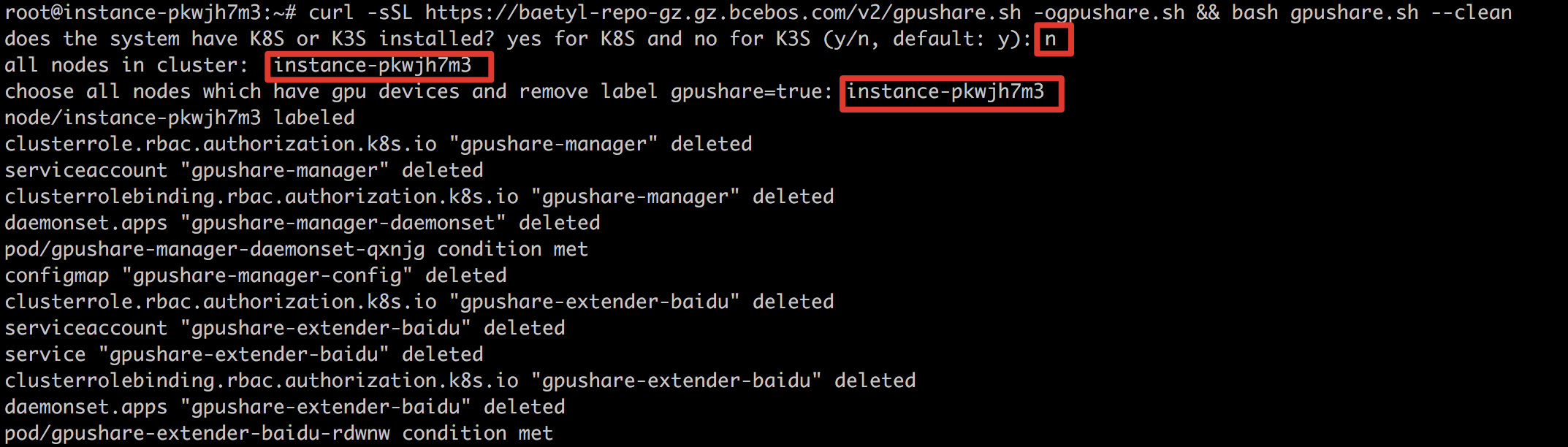
4、然后会要求用户选择有GPU的子节点,并给相应节点添加标签。当前节点只有一个,输入提示的节点名即可。
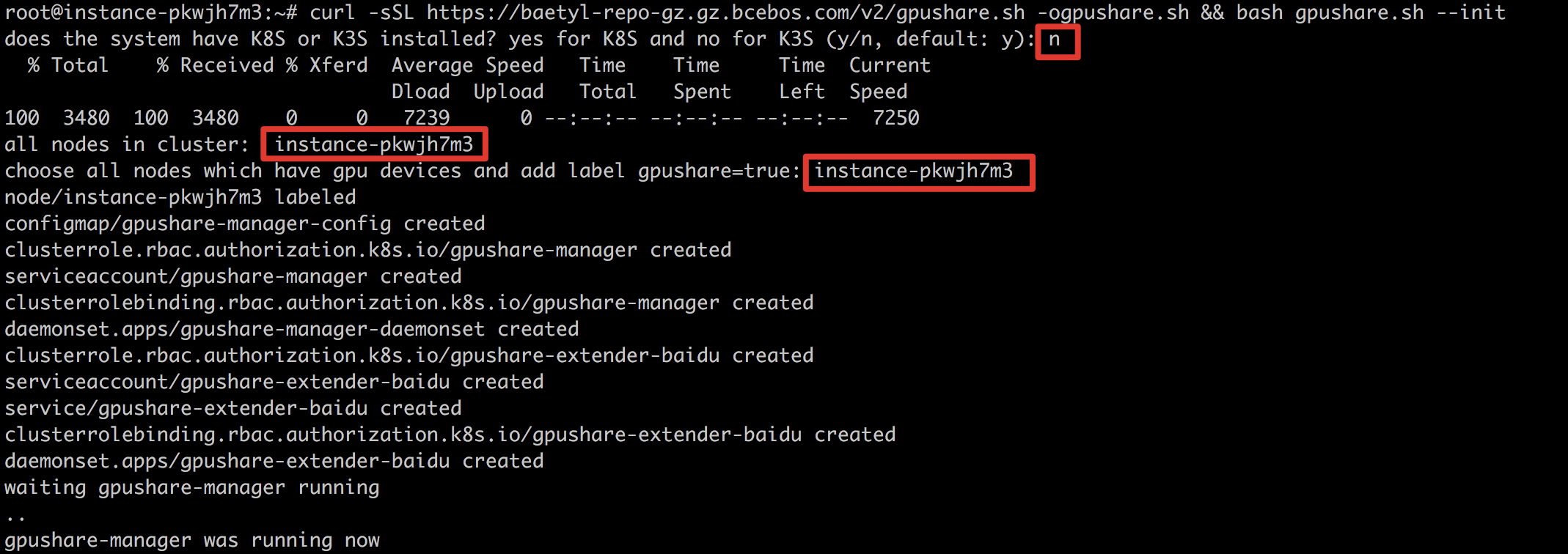
5、随后等安装完成,设备即具备GPU共享功能。由于该功能安装应用的镜像较大,拉取镜像时间可能较长。需要等待镜像拉取完成并启动后才会完成安装。
6、安装完成后,检查边缘节点标签。 kubectl describe node {node name},检查是否成功打上gpu=true的标签
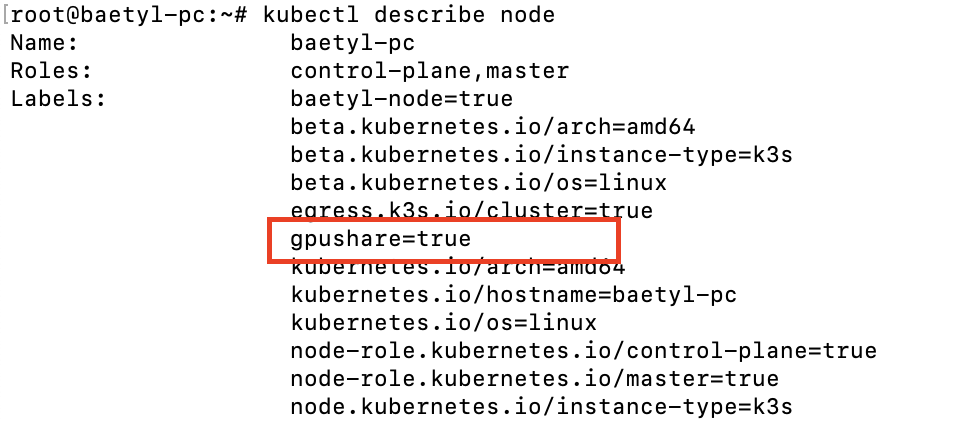
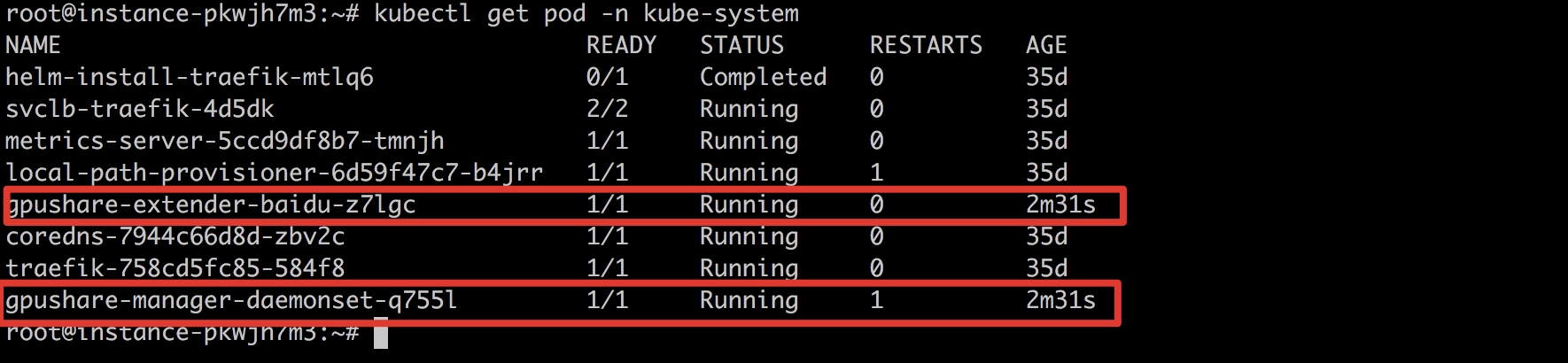
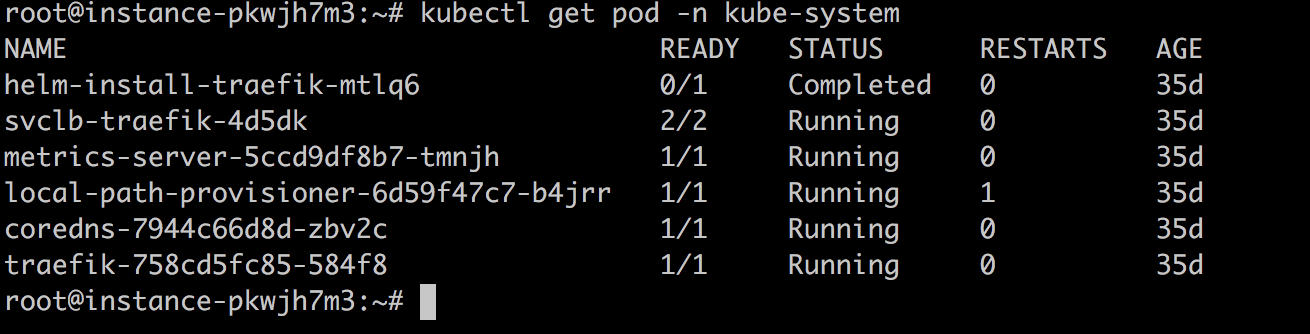
7、查看kube-system命名空间下的pod,确认两个GPU共享服务都已经正常运行即表示安装成功。
8、卸载GPU共享的过程和安装时类似,复制GPU共享配置对话框中的应用卸载命令:
9、在设备上执行,输入具有GPU的子节点并确认。
10、查看kube-system命名空间下的pod,确认两个GPU共享服务都已经删除即表示成功卸载GPU共享功能。
显存共享资源分配
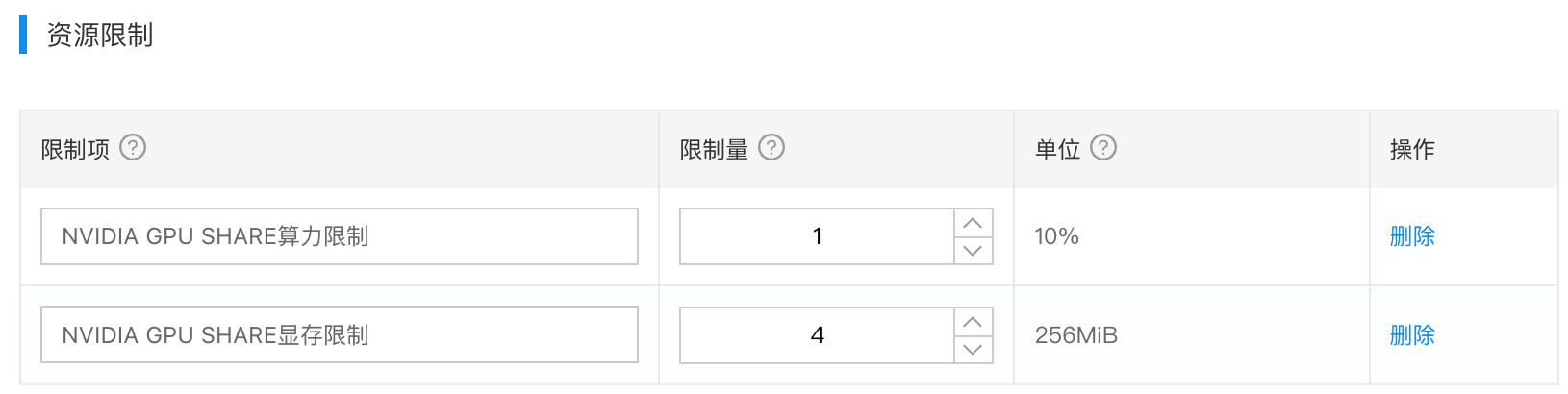
在边缘节点上安装完毕GPU共享命令以后,找到一个测试的GPU应用,然后在服务配置当中,指定AI服务需要使用的显存大小,最小单位是256MiB,如果要给测试AI服务分配1G显存,则限制量就设置为4。算力限制为必填项,如果不设置,GPU显存共享将不生效,默认填写1即可。如下图所示:
也可以通过自定义的方式下发资源限制,比如:
- 限制项:
baidu.com/vcuda-core,限制值:1 - 限制项:
baidu.com/vcuda-memory,限制值:4
多卡分配逻辑
假定GPU服务器有2张AI加速卡,加速卡信息如下,卡1有4G显存,卡2也有4G显存。当前有ai-service-1和ai-server-2两个AI服务。根据对这2个ai-service的不同资源限制,可以控制2个ai-service具体调用的AI计算卡。
- 当ai-service-1和ai-service-2都分配2G显存时,ai-service-1和ai-service-2都将调用卡1的资源,因为卡1刚好能够支持2个ai-service。
- 当ai-service-1分配2G显存,ai-service-2分配3G显存时,这2个ai-service会分别运行在卡1和卡2上。因为没有一张卡的显存容量支持运行2个ai-service。
说明:GPU显存的单位是MiB,需要查看GPU卡具体的显存容量,有些显卡说有2G显存,但是具体的容量没有到2048MiB。
GPU显存共享调度实战
单机单卡
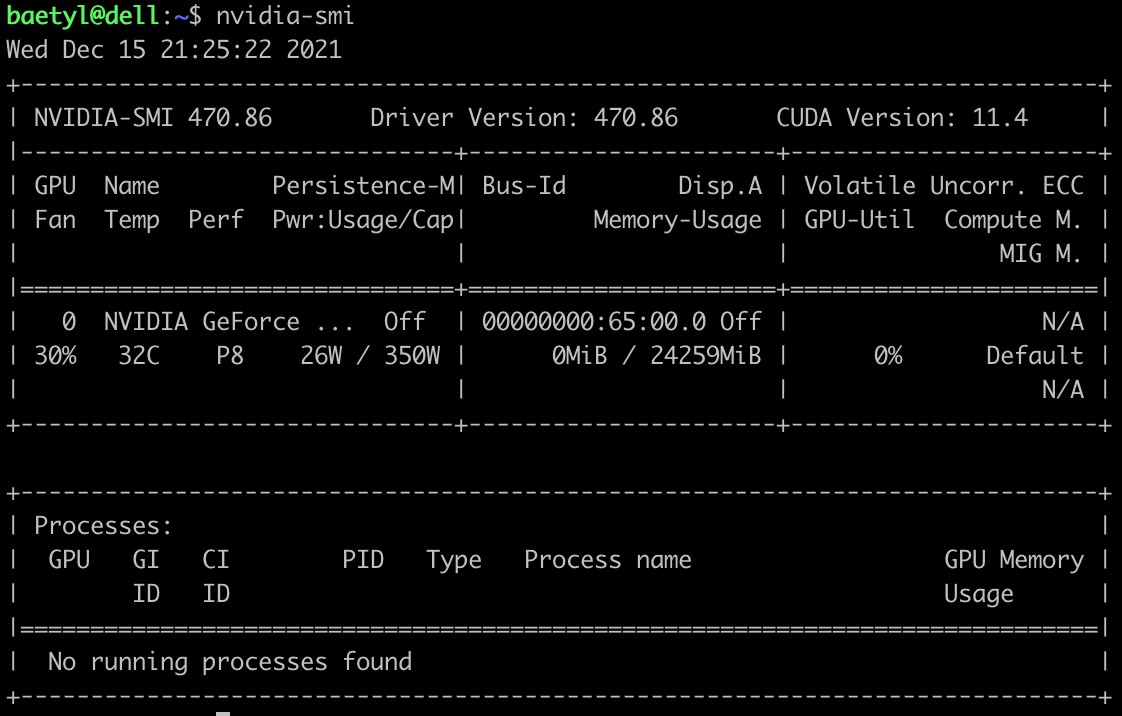
查看gpu服务属性,执行nvidia-smi,可以看到这个一台3090显卡的GPU服务器,显存24259MiB
-
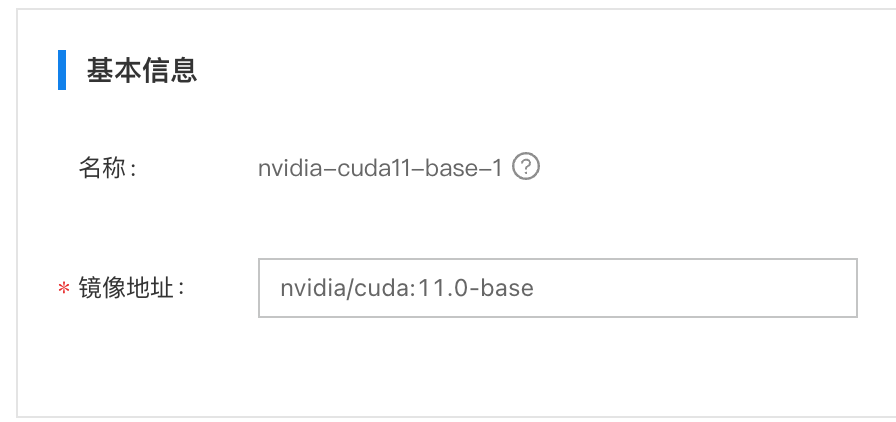
云端创建3个以
nvidia/cuda:11.0-base作为容器镜像的服务,并分配不同gpu限制,具体如下:- 应用1:nvidia-cuda11-base-1,NVIDIA资源限制:50单位,每个单位256MiB
- 应用2:nvidia-cuda11-base-2,NVIDIA资源限制:40单位
- 应用3:nvidia-cuda11-base-3,NVIDIA资源限制:1单位
如下图所示:
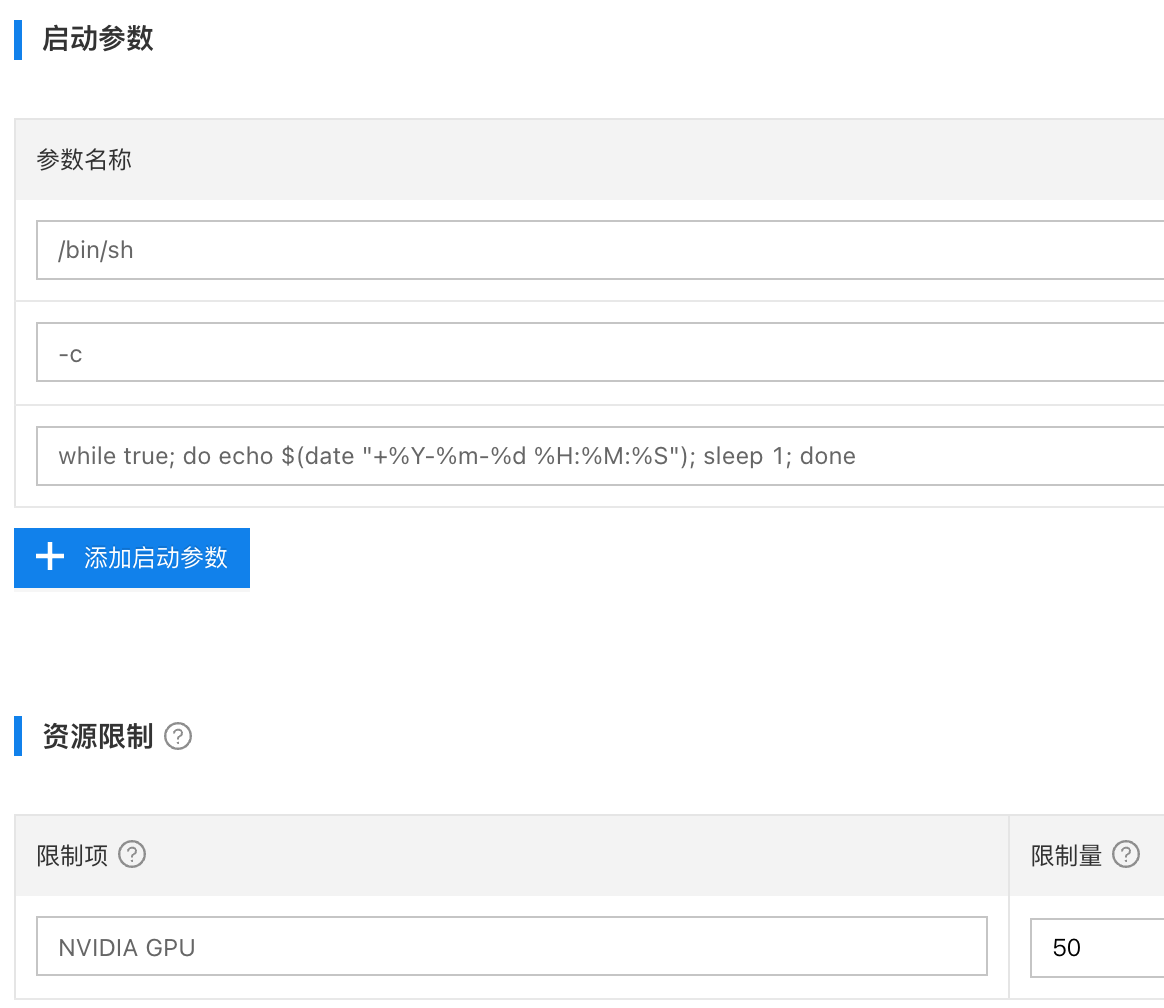
- 容器镜像都是
nvidia/cuda:11.0-base启动参数如下,是为了让容器一直running
- /bin/sh
- -c
- while true; do echo $(date "+%Y-%m-%d %H:%M:%S"); sleep 1; done
- 将三个应用都部署到gpu服务器,查看pod状态,三个都是running状态,如下所示:
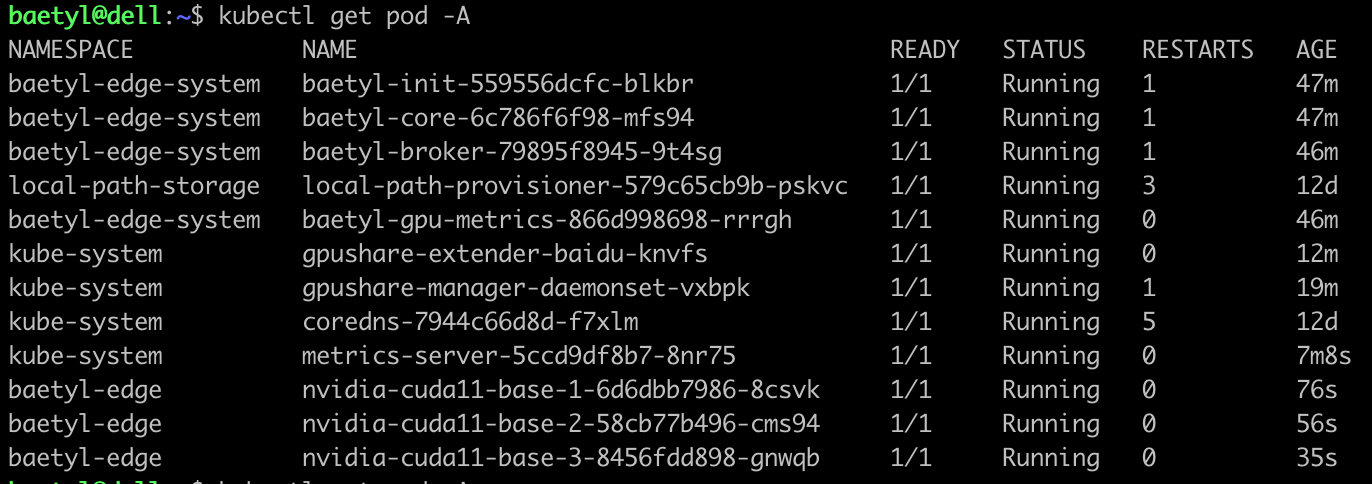
此时调度分配的GPU显存是91单位,即23296MiB,小于3090显卡的24259MiB。
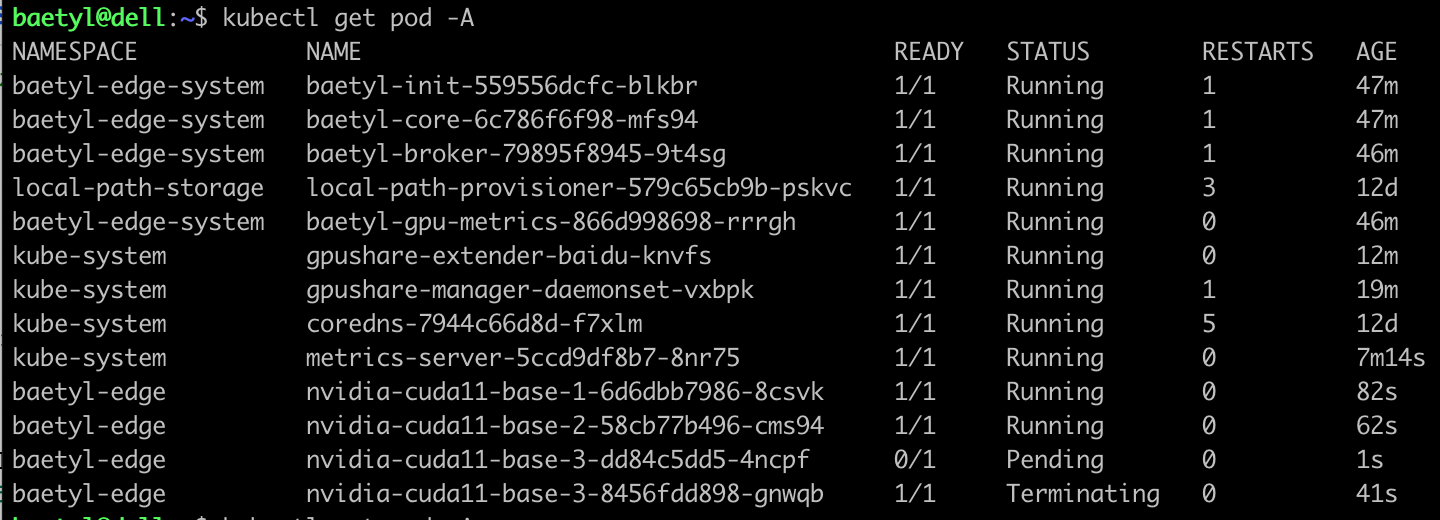
- 修改应用3的NVIDIA资源限制单位为10,此时分配调度的资源是25600MiB,大于24259MiB,此时我们查看边缘pod运行状态。
首先nvidia-cuda11-base-3这个pod会处于Terminating状态:
然后会自动创建一个新的nvidia-cuda11-base-3 pod,处于Pending状态:
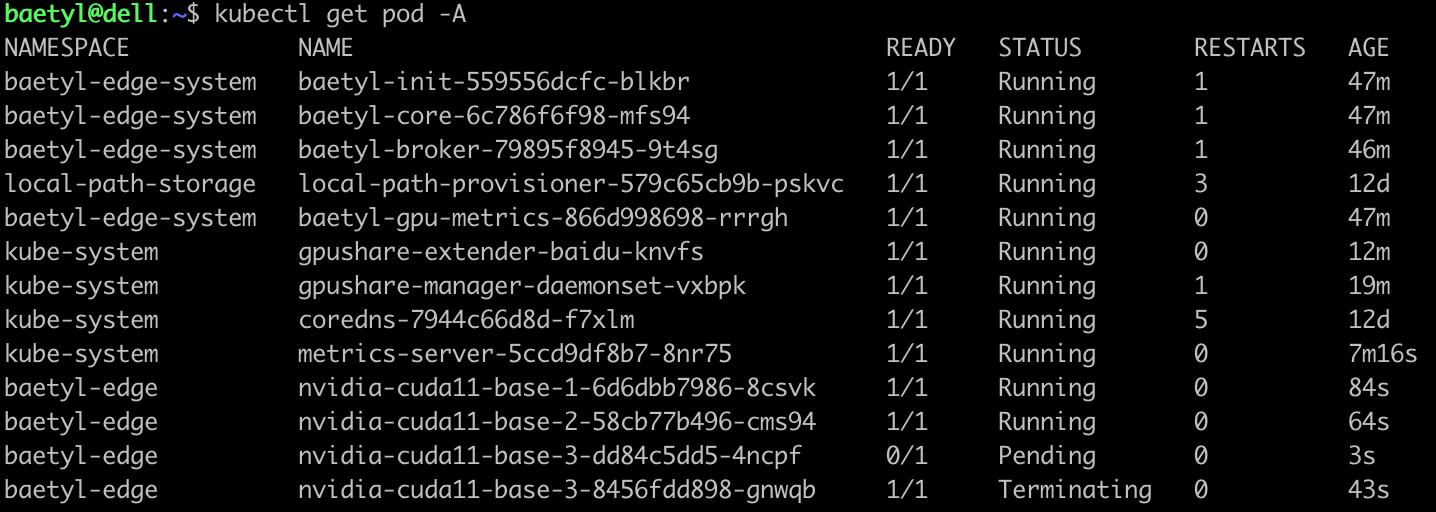
等Terminating状态的nvidia-cuda11-base-3清理掉以后,我们可以看到,剩下的那个nvidia-cuda11-base-3依然处于Pending状态:
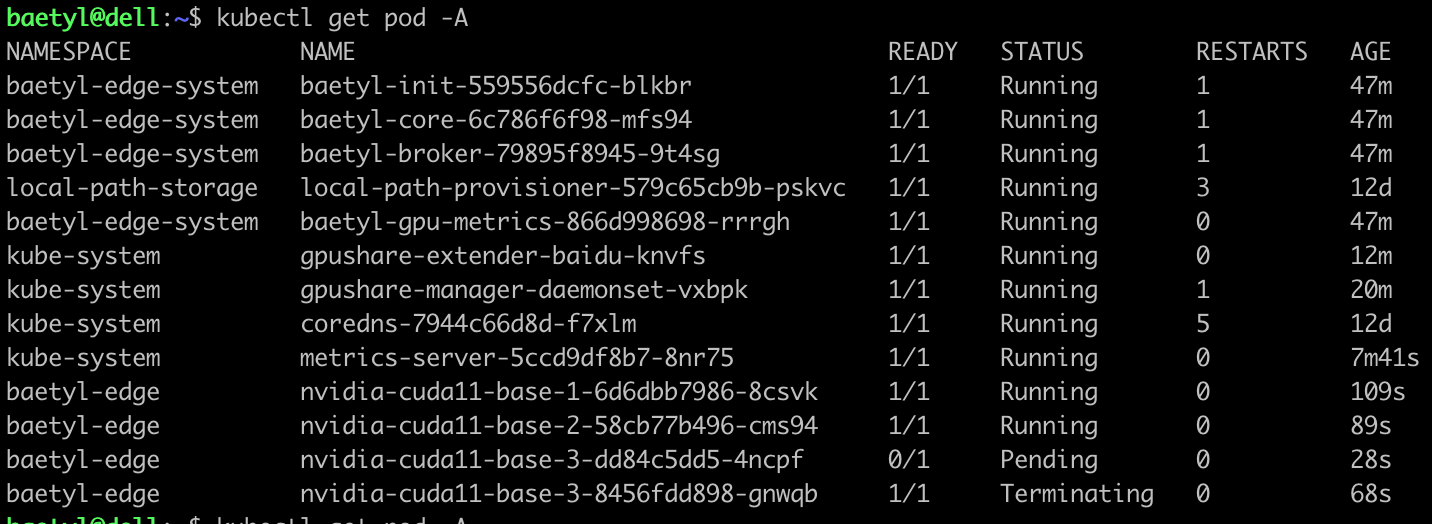
查看这个pod
1kubectl describe pod nvidia-cuda11-base-3-dd84c5dd5-4ncpf -n baetyl-edge我们发现提示资源不够。
1Events:
2 Type Reason Age From Message
3 ---- ------ ---- ---- -------
4 Warning FailedScheduling 59s default-scheduler 0/1 nodes are available: 1 Insufficient baidu.com/vcuda-memory.
5 Warning FailedScheduling 59s default-scheduler 0/1 nodes are available: 1 Insufficient baidu.com/vcuda-memory.单机多卡
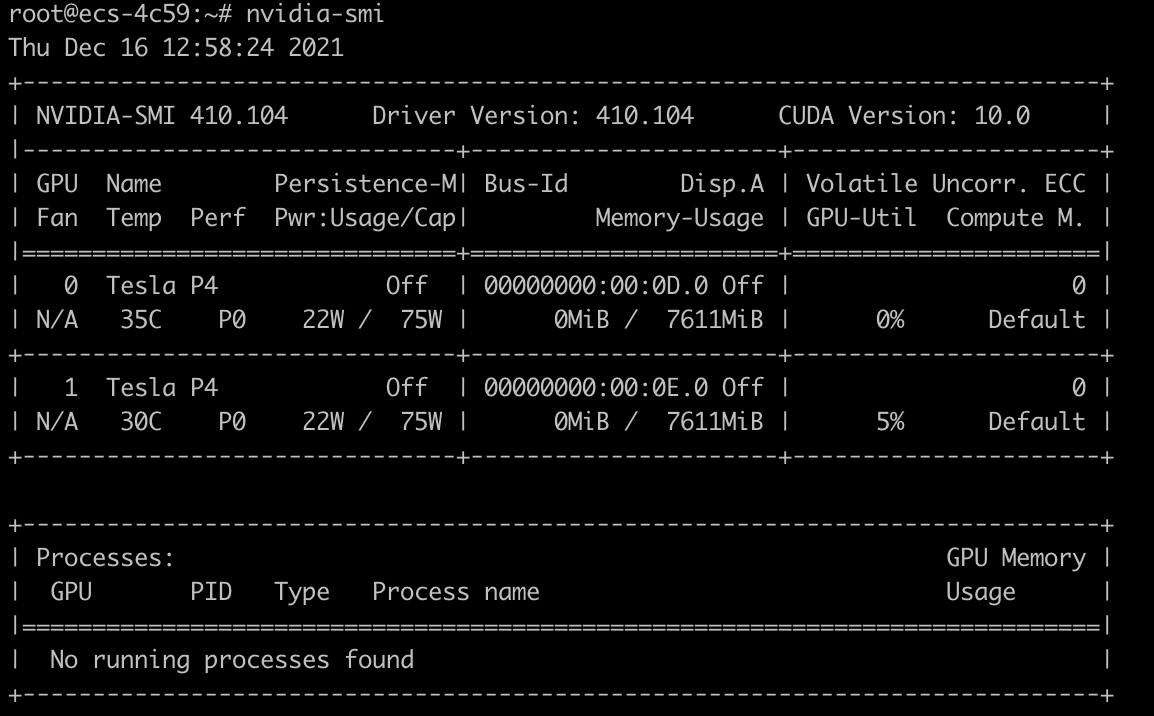
- 查看gpu服务器属性,这是一台2张P4卡的GPU服务器,每张卡的显存是7611MiB。对应每张卡最大29单位。
-
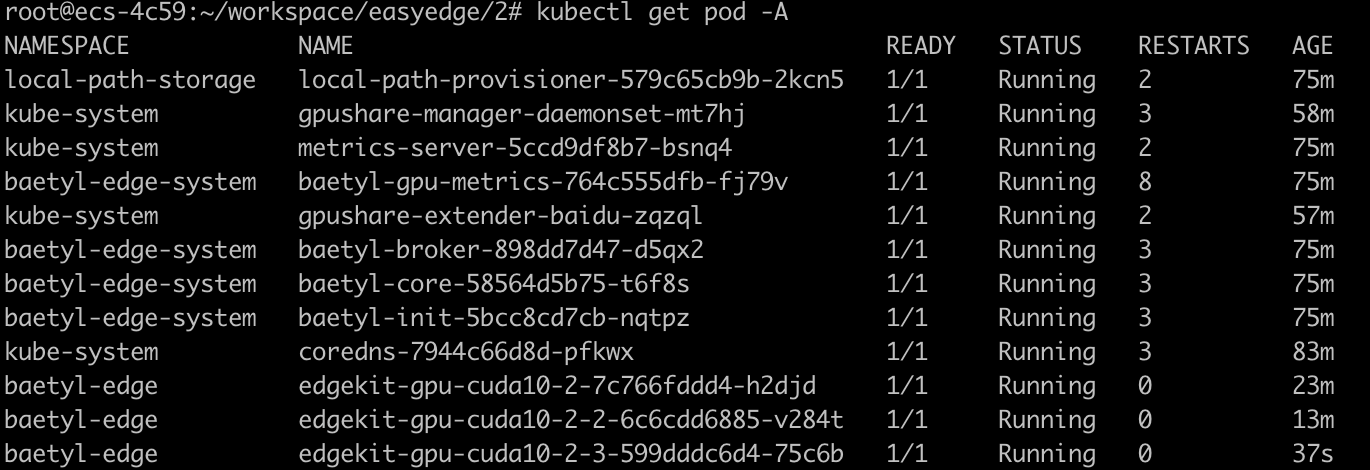
创建三个应用,应用现场分配情况如下:
- 应用1:edgekit-gpu-cuda10-2,NVIDIA资源限制:4单位
- 应用2:edgekit-gpu-cuda10-2-2,NVIDIA资源限制:20单位
- 应用3:edgekit-gpu-cuda10-2-3,NVIDIA资源限制:20单位
- 将上述三个应用部署部署到gpu服务器:
- 查看这3个pod对应的gpu:
1kubectl exec edgekit-gpu-cuda10-2-7c766fddd4-h2djd -n baetyl-edge -- nvidia-smi -L
2kubectl exec edgekit-gpu-cuda10-2-2-6c6cdd6885-v284t -n baetyl-edge -- nvidia-smi -L
3kubectl exec edgekit-gpu-cuda10-2-3-599dddc6d4-75c6b -n baetyl-edge -- nvidia-smi -L
4nvidia-smi -L
-
我们可以看到部署情况如下:
-
GPU 0: Tesla P4 (UUID: GPU-9f12f917-e458-4bb8-3d9d-8dc7fd6cddf7)
- edgekit-gpu-cuda10-2-2
-
GPU 1: Tesla P4 (UUID: GPU-7cf0b881-7598-8b1a-3270-94d6f5d2479a)
- edgekit-gpu-cuda10-2
- edgekit-gpu-cuda10-2-3
-
说明,kubectl exec命令输出的GPU卡,需要看UUID号,对应Pod来说,一个pod只有1个gpu,所以里面的GPU编号都是0,对应宿主机来说,GPU编号有0、1。
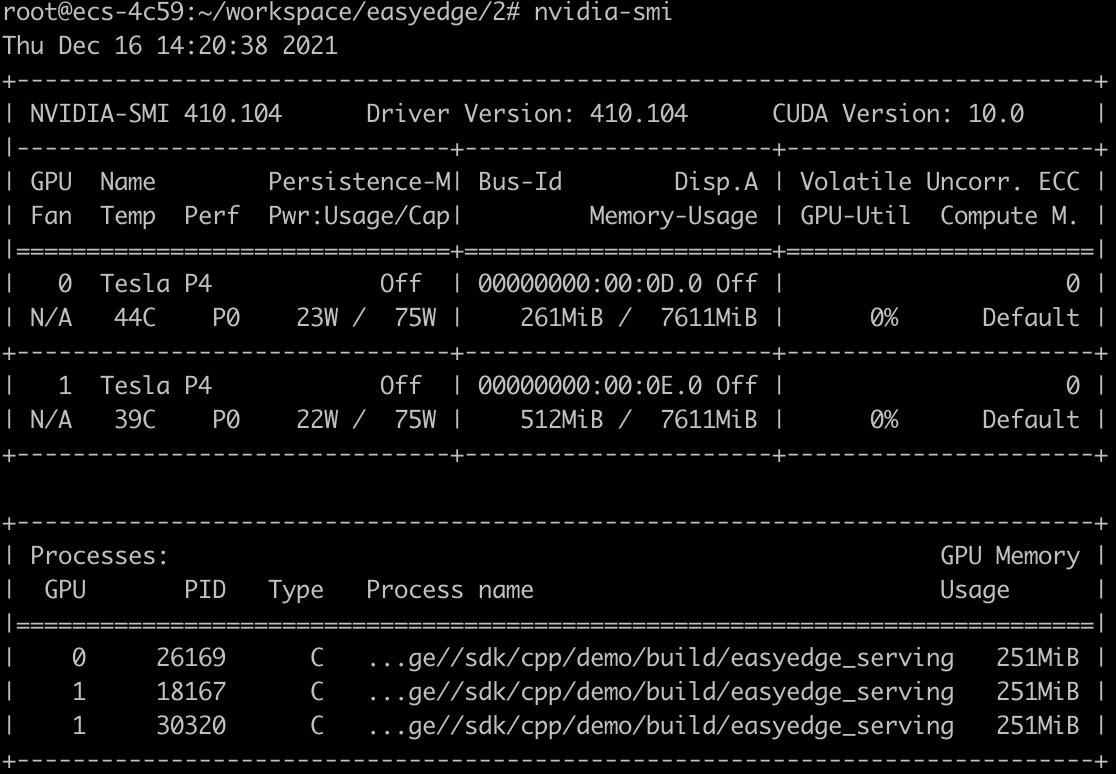
- 执行nvidia-smi,可以查看gpu的使用情况,如下图所示,总计有3个程序,运行在gpu当中,gpu1当中有2个程序。
总结
不论是单机单卡,还是单机多卡,当我们为一个应用分配一张显卡的大部分内存时(80%显存),我们可以做到让这个应用独占一张显卡,不会与其他应用分享。但是因为资源是抢占式的,如果重启k3s或者k8s,你不能保证还是上次的那个应用能够抢占到一张gpu显卡。不过在当gpu显存数量足够的情况下(比如gpu显卡有7张,当前规划的应用就3个),是可以做到应用按卡调度的。
FAQ
- 查看k3s和k8s版本是否满足需求,当前测试验证的版本是1.18、1.19、1.20三个大版本。明确1.21及以上版本不支持gpushare
- 需要先安装gpushare插件,在安装bie边缘节点软件。如果已经安全了边缘节点,需要先卸载边缘节点和gpushare插件,然后从头开始安装gpushare插件+边缘节点
- 在边缘节点上describe pod查看应用信息,检查是否同时包含了
baidu.com/vcuda-core和baidu.com/vcuda-memory这两个限制项,如果没有,可以在云端通过自定义方式配置资源限制