
使用直连 Pod 模式 LoadBalancer Service
传统模式与直连模式对比
特性
传统模式 LoadBalancer Service 以集群节点的 IP 地址作为 BLB 的后端服务器。 当访问传统模式 LoadBalancer Service 时,请求会被百度智能云提供的负载均衡服务(BLB)转发到节点上,并在节点中进一步通过 iptables 或 IPVS 转发到具体的某一个 Pod 上。 在这个过程中请求经历了 2 次负载均衡操作。
直连 Pod 模式 LoadBalancer Service 以 Pod 的 IP 地址作为其后端服务器。 当访问直连 Pod 模式 LoadBalancer Service 时,请求只需经过一次负载均衡操作即可被转发到具体的 Pod 上。 这种模式的 Service 具有以下优势:
- 保留请求的源 IP;
- 少一次请求转发,系统具有更高的性能。
- Pod 层面更均匀的负载均衡
性能
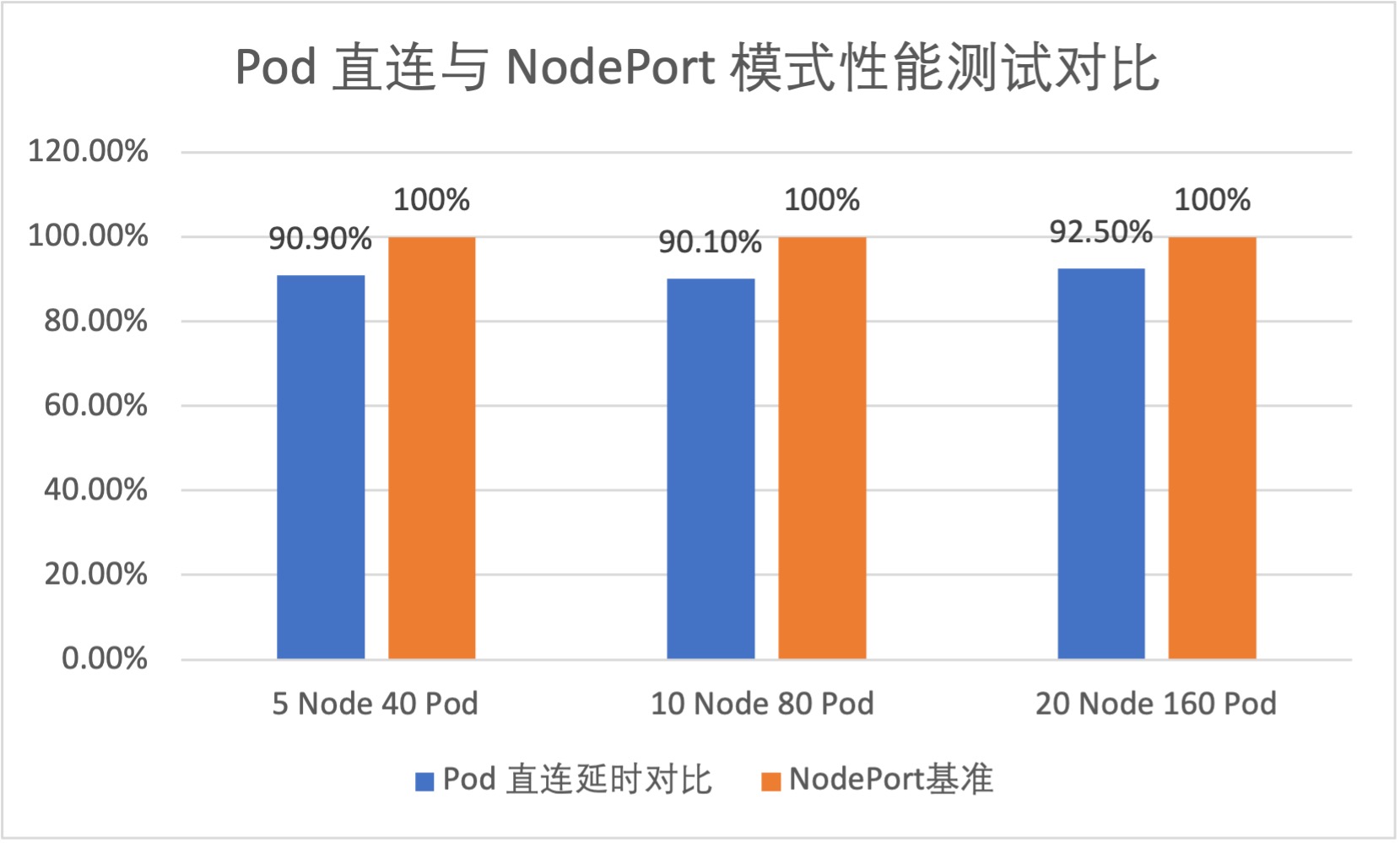
针对两种模式的 LoadBalancer Service,我们对其平均网络延时进行了测试。根据测试结果,直连 Pod 的 LoadBalancer Service 平均可以减少约 10% 的网络时延。
使用限制
使用直连 Pod 模式 LoadBalancer Service 的集群应同时满足集群版本、插件、容器网络类型 3 个方面的前提条件:
确认集群版本
新版 CCE 集群(集群 ID 以 cce- 为前缀)集群支持此功能。
旧版 CCE 集群(集群 ID 以 c- 为前缀)集群不支持此功能。
确认容器网卡类型
- 网卡类型为 veth 或 kubenet 时,满足要求。
-
网卡类型为 IPVLAN 时,需要设置 ConfigMap
cce-ip-masq-agent的masqOutBound和masqOutBoundIPv6属性为 false,操作流程如下:使用Kubectl连接集群,输入
kubectl describe configmap cce-ip-masq-agent -n kube-system指令,您可能会得到如下输出,此时masqOutBound与masqOutBoundIPv6为 true:Plain Text1# kubectl describe configmap cce-ip-masq-agent -n kube-system 2Name: cce-ip-masq-agent 3Namespace: kube-system 4Labels: addonmanager.kubernetes.io/mode=EnsureExists 5Annotations: 6Data 7==== 8config: 9---- 10nonMasqueradeCIDRs: 11 - 10.0.0.0/8 12 - 172.16.0.0/12 13 - 192.168.0.0/16 14 - fc00::/7 15masqOutBound: true 16masqOutBoundIPv6: true 17masqLinkLocal: false 18masqLinkLocalIPv6: false 19resyncInterval: 60s 20 21Events: <none>输入
kubectl edit configmap cce-ip-masq-agent -n kube-system指令,然后修改masqOutBound与masqOutBoundIPv6为 false 并保存,cce-ip-masq-agent 配置信息将会自动更新,此时再次输入kubectl describe configmap cce-ip-masq-agent -n kube-system指令,您可能会得到如下输出,此时masqOutBound与masqOutBoundIPv6已经为 false。Plain Text1# kubectl describe configmap cce-ip-masq-agent -n kube-system 2Name: cce-ip-masq-agent 3Namespace: kube-system 4Labels: addonmanager.kubernetes.io/mode=EnsureExists 5Annotations: 6Data 7==== 8config: 9---- 10nonMasqueradeCIDRs: 11 - 10.0.0.0/8 12 - 172.16.0.0/12 13 - 192.168.0.0/16 14 - fc00::/7 15masqOutBound: false 16masqOutBoundIPv6: false 17masqLinkLocal: false 18masqLinkLocalIPv6: false 19resyncInterval: 60s 20 21Events: <none>
注意事项
检查配额限制
直连 Pod 模式 LoadBalancer Service 使用应用型 BLB,其后端默认最多关联 50 个 Pod。 如果无法满足需求,请提交工单申请开放后端数量限制。
开放安全组端口
当 CCE 集群的容器网络模式为 VPC 网络 时,需要为集群节点绑定的安全组中为目的端口 Service TargetPort 放通流量。否则数据包无法到达 Pod。
当 CCE 集群的容器网络模式为 VPC-CNI 时,需要在 ENI 弹性网卡绑定的安全组中为目的端口 Service TargetPort 放通流量。否则数据包无法到达 Pod。
操作步骤
创建直连 Pod 模式 LoadBalancer Service 时,需要为 annotations 属性添加 service.beta.kubernetes.io/cce-load-balancer-backend-type: "eni"。
示例 yaml 如下:
1apiVersion: v1
2kind: Service
3metadata:
4 name: pod-direct-service-example
5 annotations:
6 prometheus.io/scrape: "true"
7 service.beta.kubernetes.io/cce-load-balancer-backend-type: "eni"
8spec:
9 selector:
10 app: nginx
11 type: LoadBalancer
12 sessionAffinity: None
13 ports:
14 - name: nginx
15 protocol: TCP
16 port: 80
17 targetPort: 80常见问题
Pod 零中断滚动更新
使用直连 Pod 的 LB Service 在 Pod 滚动更新时可能服务中断问题。
原因
一个 Pod 在被终止时,会发生如下事件:
- Pod 进入 Terminating 状态;
- Pod 从 Endpoints 中被摘除;LB Controller 监听到 Endpoints 变化,并从应用型 BLB 中摘除该 Pod 后端;
- Pod 销毁;
其中2,3步是并行执行的。当 Pod 销毁后,LB Controller 仍未将 Pod 摘除时,就可能会有流量被转发到被销毁的 Pod,导致服务中断。
解决方法
为 Pod 设置 preStopHook,睡眠一段时间(一般为 40 秒),待到应用型 BLB 将 Pod 摘除后再销毁。
参考如下:
1 lifecycle:
2 preStop:
3 exec:
4 command: ["sleep", "40"]