
设置工作负载自动水平伸缩
更新时间:2025-08-21
概述
容器引擎 CCE 提供的 Pod 自动扩缩容功能(Horizontal Pod Autoscaler,HPA)可以根据CPU、内存度量指标自动伸缩服务的 Pod 数量,能更好的应对突发流量等场景。本文介绍如何通过百度智能云容器引擎控制台或 YAML 方式实现 Pod 自动扩缩容。
实现原理
- HPA 组件每隔 15 秒会获取 Pod 的监控指标,然后根据当前指标数据、当前副本数和该指标的目标值进行计算,计算所得结果作为工作负载的期望副本数。当期望副本数与当前副本数不一致时,HPA会触发工作负载进行Pod副本数调整,从而达到自动伸缩的目的。
- 以 CPU 使用率为例,假设工作负载有 2 个实例,平均 CPU 使用率(当前指标数据)为 90%,自动伸缩设置的目标值为 60% 时,则自动调整的副本数为:90% * 2 /60% = 3,即由 2 个实例自动扩容为 3 个实例。
说明:
如果对一个工作负载设置了多个伸缩指标,HPA 会根据各个指标分别计算出目标副本数,取最大值进行扩缩容操作。
前提条件
- 已创建 CCE 集群,具体操作请参见 创建CCE集群。
操作步骤
通过容器引擎控制台使用HPA
方式一:为已有工作负载开启HPA
- 登录百度智能云管理控制台,进入产品服务 > 云原生 > 容器引擎 CCE,单击集群管理 > 集群列表,单击目标集群名称,进入"集群详情"页,在侧边栏单击工作负载 > 弹性伸缩。
- 在“弹性伸缩 HPA”页面单击新建规则操作。
- 在“新建弹性伸缩”页面配置伸缩策略。
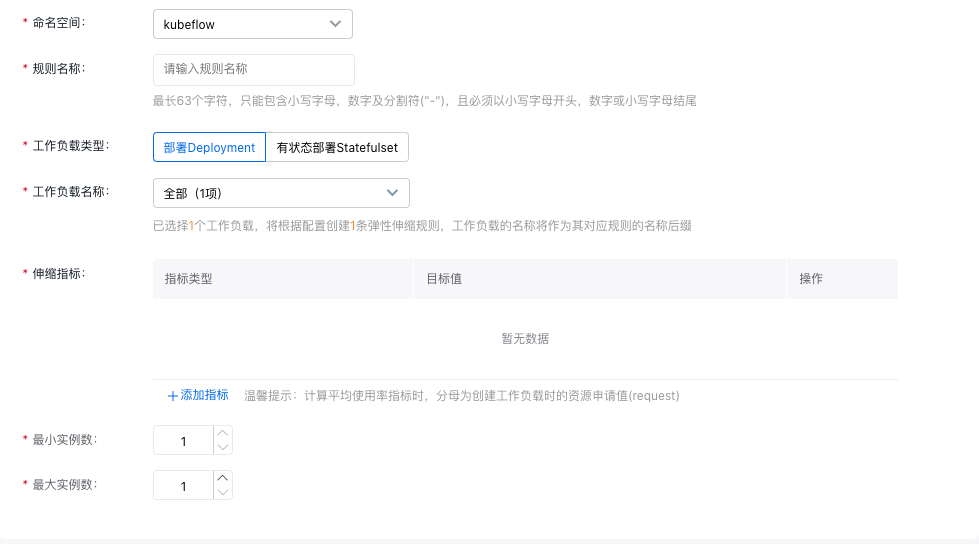
| 配置项 | 必选/可选 | 配置说明 |
|---|---|---|
| 命名空间 | 必选 | 选择伸缩规则所在的命名空间 |
| 规则名称 | 必选 | 弹性伸缩规则的名称,最长63个字符,只能包含小写字母,数字及分割符("-"),且必须以小写字母开头,数字或小写字母结尾 |
| 工作负载类型 | 必选 | 支持无状态部署Deployment和有状态部署Statefulset |
| 工作负载名称 | 必选 | 选择已选命名空间下的无状态部署或有状态部署,支持选择多个 |
| 伸缩指标 | 必选 | 提供CPU、内存指标,支持选择多个指标 |
| 最小Pod数 | 必选 | Pod数量不会低于设定范围 |
| 最大Pod数 | 必选 | Pod数量不会超过设定范围 |
说明:
- 支持选择多个工作负载,若选择多个工作负载,则会按照工作负载数量生成对应的伸缩规则,实际生成的伸缩规则名称为“规则名称+工作负载名称”
- Pod数量会在设定的范围内自动调节,不会超出该设定范围。
- 单击确认,您可以在伸缩规则列表中查看伸缩规则关联工作负载伸缩指标的当前值以及目标值,当前实例数以及伸缩范围。

方式二:在创建工作负载过程中开启HPA
当前以创建无状态部署为例:
- 登录百度智能云管理控制台,进入产品服务>云原生>容器引擎 CCE,单击集群管理>集群列表,单击目标集群名称,进入"集群详情"页,在侧边栏单击工作负载>无状态部署。
- 在"无状态部署"页面单击新建无状态部署操作。
- 在“新建无状态部署-高级设置”页面配置伸缩策略。
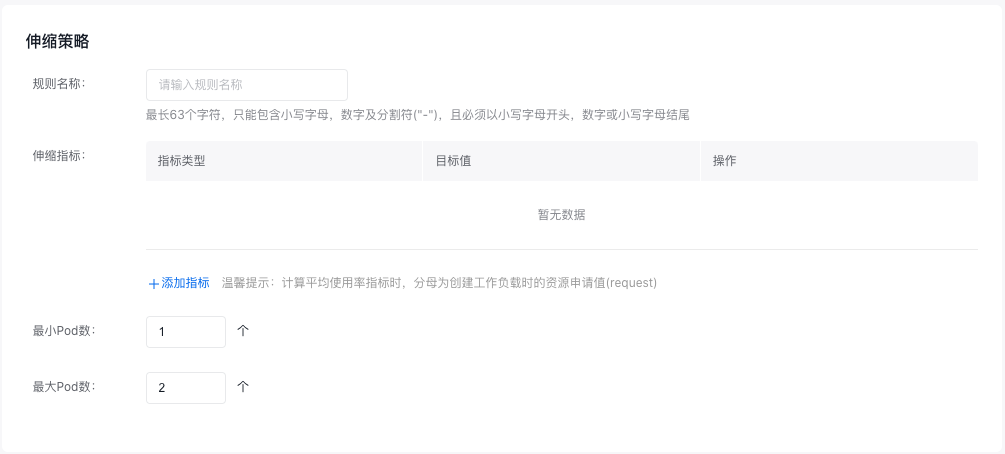
| 配置项 | 必选/可选 | 配置说明 |
|---|---|---|
| 规则名称 | 必选 | 弹性伸缩规则的名称,最长63个字符,只能包含小写字母,数字及分割符("-"),且必须以小写字母开头,数字或小写字母结尾 |
| 伸缩指标 | 必选 | 提供CPU、内存指标,支持选择多个指标 |
| 最小Pod数 | 必选 | Pod数量不会低于设定范围 |
| 最大Pod数 | 必选 | Pod数量不会超过设定范围 |
- 单击完成,一个支持HPA的无状态部署就已配置完成。
通过kubectl命令使用HPA
为演示 HPA,将使用一个基于 php-apache 镜像的定制 Docker 镜像。镜像中包括一个 index.php 页面,其中包含一些可以运行 CPU 密集计算任务的代码。 示例 Dockerfile 如下:
Dockerfile
1FROM php:5-apache
2
3ADD index.php /var/www/html/index.php
4
5RUN chmod a+rx index.php示例 index.php 文件如下:
PHP
1<?php
2$x = 0.0001;
3for ($i = 0; $i <= 1000000; $i++) {
4 $x += sqrt($x);
5}
6echo "OK!";
7?>前提条件
- 已配置 kubectl,可以在本机访问 Kubernetes 集群,详情参见 通过kubectl连接集群。
步骤一:部署工作负载及服务
- 首先,部署一个 Deployment 运行上述 Docker 镜像并将其暴露成为一个 Kubernetes 服务(Service)
Bash
1kubectl run php-apache --image=hpa-example --requests=cpu=200m --expose --port=80
2
3service "php-apache" created
4deployment "php-apache" created步骤二:创建HPA
Bash
1kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
2deployment "php-apache" autoscaled
3
4
5# 创建出来后,当前监控值为unknown,执行第3步后,等待1-2分钟,这里会变为正常的百分比
6[root@instance-2tpjy37t ~]# kubectl get hpa
7NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
8php-apache Deployment/php-apache <unknown>/50% 1 10 1 5s对应 YAML 如下:
YAML
1apiVersion: autoscaling/v2alpha1
2kind: HorizontalPodAutoscaler
3metadata:
4 name: php-apache
5 namespace: default
6spec:
7 scaleTargetRef:
8 apiVersion: apps/v1beta1
9 kind: Deployment
10 name: php-apache
11 minReplicas: 1
12 maxReplicas: 10
13 metrics:
14 - type: Resource
15 resource:
16 name: cpu
17 targetAverageUtilization: 50字段解释:
- scaleTargetRef: HPA 自动扩缩容的目标对象
- minReplicas:最小 Pod 数量
- maxReplicas:允许的最大 Pod 数量
- metrics:度量指标
- targetAverageUtilization:即设定的资源利用率,超过设定值时触发水平扩展
HPA 目前支持 3 种类型的度量指标,详情参考 kubernetes Horizontal Pod Autoscaler:
- 预定义指标: Pod 的 CPU 和内存使用率(内置支持)
- 自定义 Pod 指标: 应用程序提供的监控指标(需部署监控、自定义 metric server)
- 自定义 Object 指标: 和 Pod 同一个命名空间中的其它资源的监控指标(需部署监控、自定义 metric server)
步骤三:向服务增加负载,验证自动扩容
启动一个容器,并通过一个循环向php-apache服务器发送无限的查询请求(请在另一个终端中运行以下命令)
Bash
1kubectl run -i --tty load-generator --image=busybox /bin/sh
2
3Hit enter for command prompt
4
5$ while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
6
7# 输出:
8OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!!OK!OK!OK!OK步骤四:观察HPA的变化
负载升高后,Deployment 的副本数量(Replicas)会开始增加
Bash
1[root@instance-2tpjy37t ~]# kubectl get hpa
2NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
3php-apache Deployment/php-apache 332%/50% 1 10 7 19m
4
5[root@instance-2tpjy37t ~]# kubectl get deployment php-apache
6NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
7php-apache 7 7 7 7 19m步骤五:停止服务负载,验证自动缩容
在生成负载的容器的终端中,输入<ctrl> + c来终止负载的产生。
然后再次查看负载状态(等待几分钟时间)
Bash
1[root@instance-2tpjy37t ~]# kubectl get hpa
2NAME REFERENCE TARGET MINPODS MAXPODS REPLICAS AGE
3php-apache Deployment/php-apache/scale 0% / 50% 1 10 1 11m
4
5# 负载降低后,Pod 数量也随之减少
6[root@instance-2tpjy37t ~]# kubectl get deployment php-apache
7NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
8php-apache 1 1 1 1 27m