
CCE QoS Agent 说明
更新时间:2025-08-21
组件介绍
cce-qos-agent 基于 BaiduLinux 的能力,为容器提供基于 Kubernetes 原生 QoS 的服务质量保障、容器隔离与加固能力,同时提升资源利用率。
注意:QoS 相关能力仅支持在使用 BaiduLinux3 作为操作系统的节点上使用,若您的节点使用其他操作系统,相关能力无法生效。
组件功能
- 配置节点资源水位,当整机资源用量超过配置的资源水位时,将触发对低优容器的压制或驱逐;
- 容器 QoS 增强,包括如下表所示能力
| 功能 | 说明 |
|---|---|
| CPU QoS 增强 | 支持 CPU 优先级配置,可以通过对工作负载设置优先级,保证高优先级业务在发生资源竞争时的资源供给量,并压制低优先级业务。 |
| 内存 QoS 增强 | 支持内存背景回收、OOMKill 优先级等,提升整体内存性能。 |
| 网络 QoS 增强 | 支持网络带宽优先级配置,出入方向限速等,灵活限制容器对网络的使用。 |
限制说明
- 集群版本在 1.18.9 以上
- BaiduLinux3 作为节点操作系统
- 能够使用 kubectl 访问集群,操作步骤见:通过kubectl连接集群
安装组件
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的 集群管理 > 集群列表。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击 组件管理 。
- 在组件管理列表中选择 CCE QoS Agent 组件单击“安装”。
- 在组件配置页面中完成节点资源水位配置。
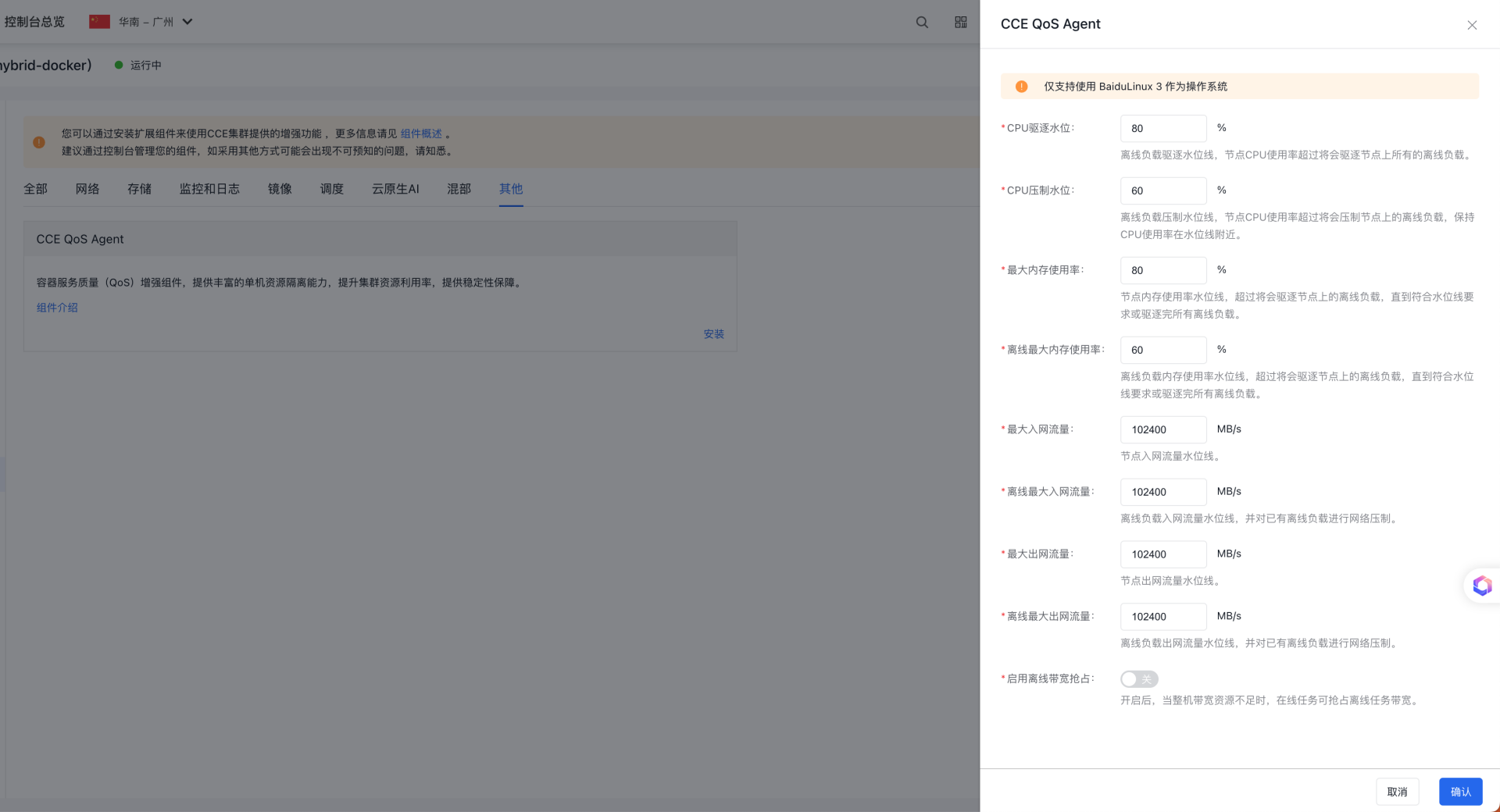
- 点击“确定”按钮完成组件的安装。
配置节点资源水位
配置项含义如下:
- CPU驱逐水位线:当整机CPU使用量达到销毁水位线时,驱逐全部的低优服务保障高优服务,默认值 80%;
- CPU压制水位线:当整机CPU使用量达到压制水位线时,压制全部的低优服务保障高优服务,默认值 60%;
- 内存整机最大水位线:当整机内存超过最大内存使用量时,驱逐低优服务保障高优服务,默认值 80%;
- 内存低优最大水位线:当低优内存超过低优内存使用量时,驱逐低优服务保障高优服务,默认值 60%;
- 整机最大入网流量:当整机入网流量超过最大入网流量,禁止将离线应用调度到节点;
- 离线最大入网流量:当离线入网流量超过最大入网流量,将对已有的离线负载进行网络压制;
- 整机最大出网流量:当整机入网流量超过最大入网流量,禁止将离线应用调度到节点;
- 离线最大出网流量:当离线入网流量超过最大入网流量,将对已有的离线负载进行网络压制;
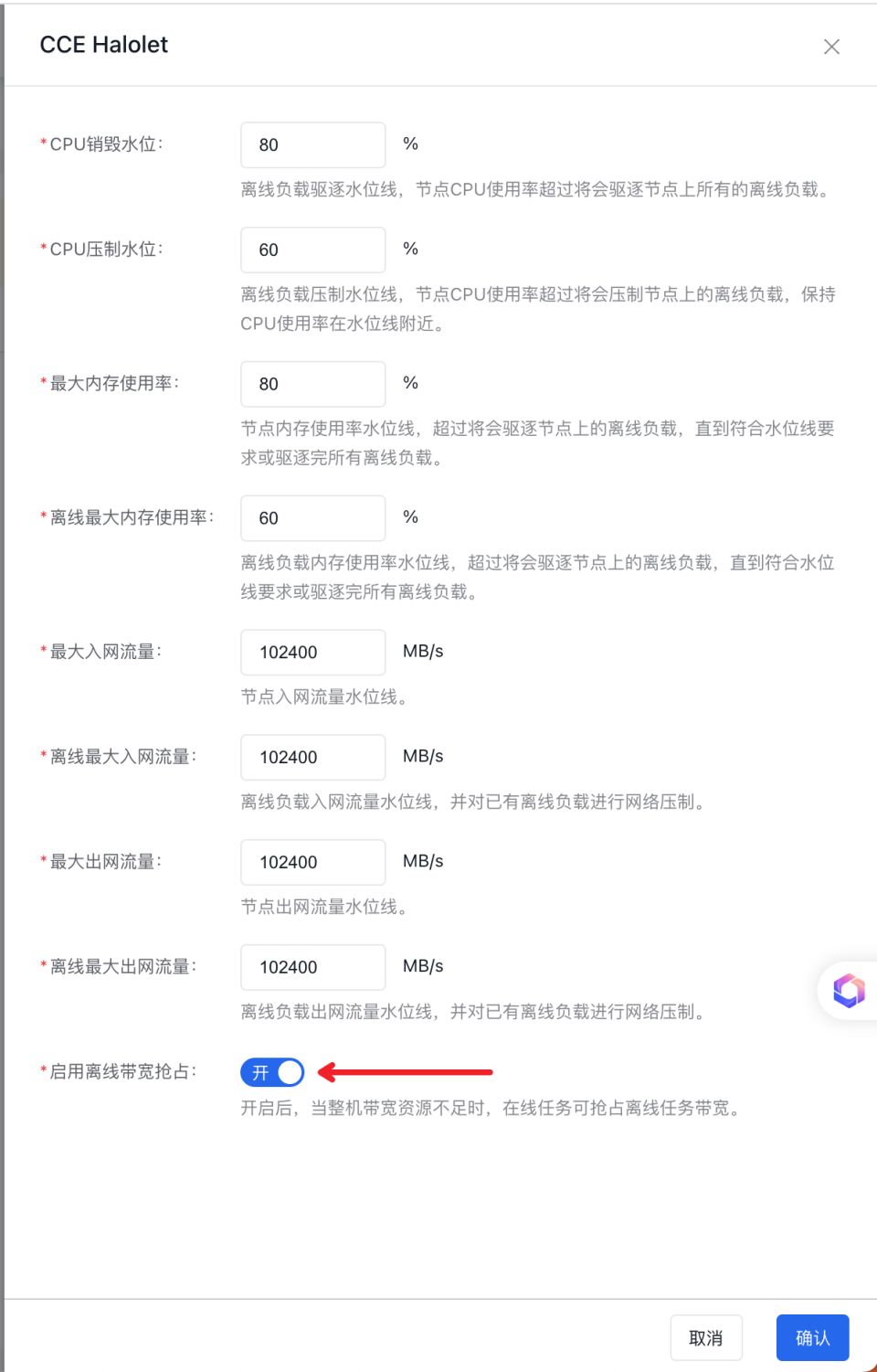
- 是否开启网络带宽抢占:当整机带宽不足时,在线任务将抢占离线任务带宽,默认关闭;
使资源水位对节点生效
完成 cce-qos-agent 组件的安装后,需要为节点添加标签(label)cce.baidu.com/sla-pool="default",使资源水位对节点生效。
以节点 10.0.3.13 为例,在终端执行以下命令:
Shell
1kubectl label node 10.0.3.13 cce.baidu.com/sla-pool="default"配置 Pod QoS
用户在安装了单机引擎之后,可以通过 Pod 的 label 扩展Pod的增强隔离加固能力。 支持的 配置项如下表:
| 能力 | 能力描述 | Pod Label | 参数说明 | 单位 | 默认值 |
|---|---|---|---|---|---|
| CPU 优先级 | 配置 CPU 优先级。 | cpu.priority | 支持将 Pod 配置为在线、离线任务 | - | 无 |
| 设置memcg背景回收能力 | 背景回收能力:控制Pod级别的异步回收cache动作,当Pod的cache触发到高水位线(memory.high_wmark_distance)时,会开始回收cache,直到cache达到低水位线(memory.low_wmark_distance) | memory.background_reclaim | 是否开启内存背景回收 | bool | 0 |
| memory.low_wmark_distance | 内存背景回收低水位线 | byte | 0 | ||
| memory.high_wmark_distance | 内存背景回收高水位线 | byte | 0 | ||
| 设置OOM时,Pod被kill的优先级值 | 该功能在进行OOM操作时,会首先判定cgroup的优先级,选择低优先级的cgroup进行OOM操作,cgroup的优先级值(memory.oom_kill_prioirty)越大,优先级越低。 | memory.oom_kill_priority | 设置oom kill优先级,优先级越高优先杀死 | int | 5000 |
| 控制发生OOM时,cgroup内的进程组的kill模式 | 控制发生OOM时,cgroup内的进程组的kill模式:0: 不杀死进程组内所有的进程 1: 杀死进程组内所有的进程 | memory.kill_mode | 控制OOM kill模式,是否杀死进程组所有进程。 | bool | 0 |
| 设置网络优先级 | 设置 Pod 网络优先级 | net.priority | 可选值: besteffort | bool | 0 |
配置 CPU QoS
支持的 CPU 优先级及与 Kubernetes QoS 的对应关系如下:
| CPU 优先级 | K8S QoS | 说明 |
|---|---|---|
| sensitive | Guaranteed | 绑核,CPU 必须是 1000m 的整数倍 |
| stable | Guaranteed/Burstable | 实现更好的资源弹性和更灵活的资源调整能力,要求至少需要填写 requests |
| batch | BestEffort | 离线任务;相对 BestEffort,CPU 使用比例是 BE 的两倍 |
| besteffort | BestEffort | 离线任务 |
场景一:离线任务支持多级 CPU 优先级,通过 CPU 比例划分,无抢占关系
场景描述:
- 部署两个离线 CPU 任务,CPU 优先级分别为 batch 和 besteffort。
- 优先级为 batch 的任务的 CPU 运行时间约为优先级为 besteffort 任务的两倍。
操作步骤:
- 部署 离线 CPU 任务,以下yaml 包含两个 cpu stress 任务,分别配置优先级为 batch 和 besteffort
YAML
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: stress-batch
5spec:
6 selector:
7 matchLabels:
8 app: stress-batch
9 template:
10 metadata:
11 labels:
12 app: stress-batch
13 cpu.priority: batch
14 spec:
15 nodeSelector:
16 kubernetes.io/hostname: 10.0.3.13
17 containers:
18 - name: stress
19 image: registry.baidubce.com/public-tools/stress-ng:latest
20 command:
21 - "stress-ng"
22 args:
23 - --cpu
24 - "0"
25 - --cpu-method
26 - all
27 - -t
28 - 1h
29---
30apiVersion: apps/v1
31kind: Deployment
32metadata:
33 name: stress-besteffort
34spec:
35 selector:
36 matchLabels:
37 app: stress-besteffort
38 template:
39 metadata:
40 labels:
41 app: stress-besteffort
42 cpu.priority: besteffort
43 spec:
44 nodeSelector:
45 kubernetes.io/hostname: 10.0.3.13
46 containers:
47 - name: stress
48 image: registry.baidubce.com/public-tools/stress-ng:latest
49 command:
50 - "stress-ng"
51 args:
52 - --cpu
53 - "0"
54 - --cpu-method
55 - all
56 - -t
57 - 1h- 部署后在 Pod 所在节点节点计算两个容器在过去 1s 的运行时间
Shell
1#!/bin/bash
2batchPodID="eccb11ba-b875-4614-ac07-2e811397239a"
3batchContainerID="6e677ceb30c28438bf32d1191d74e7fa0131124ea08fe8647950e07c7a34bef5"
4
5bePodID="8339d083-5aae-48bd-a2cf-9c91a777dc53"
6beContainerID="6c10640a79479f8d6606d3823a4666cffb225913990b6aab1bfdf8bcf3a6cf47"
7
8batch_start=`cat /sys/fs/cgroup/cpu/kubepods/besteffort/pod${batchPodID}/${batchContainerID}/cpuacct.bt_usage`
9be_start=`cat /sys/fs/cgroup/cpu/kubepods/besteffort/pod${bePodID}/${beContainerID}/cpuacct.bt_usage`
10sleep 1
11batch_end=`cat /sys/fs/cgroup/cpu/kubepods/besteffort/pod${batchPodID}/${batchContainerID}/cpuacct.bt_usage`
12be_end=`cat /sys/fs/cgroup/cpu/kubepods/besteffort/pod${bePodID}/${beContainerID}/cpuacct.bt_usage`
13
14expr "${batch_end}" - "${batch_start}"
15expr "${be_end}" - "${be_start}"得到计算结果:

可以看到 batch 优先级任务所占用的 CPU 时间约为 besteffort 优先级任务的两倍。
场景二:离线任务支持多级 CPU 优先级,通过 CPU 比例划分,无抢占关系
场景描述:
- 在 case1 的部署离线任务的基础上,部署在线任务
- 在线任务完成对离线任务的 CPU 抢占。
操作步骤:
- 部署在线 CPU 任务,优先级配置为 stable
YAML
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: stress-stable
5spec:
6 selector:
7 matchLabels:
8 app: stress-stable
9 template:
10 metadata:
11 labels:
12 app: stress-stable
13 cpu.priority: stable
14 spec:
15 nodeSelector:
16 kubernetes.io/hostname: 10.0.3.13
17 containers:
18 - name: stress
19 image: registry.baidubce.com/public-tools/stress-ng:latest
20 command:
21 - "stress-ng"
22 args:
23 - --cpu
24 - "0"
25 - --cpu-method
26 - all
27 - -t
28 - 1h
29 resources:
30 requests:
31 cpu: 1
32 memory: 2Gi- 再次执行 case 1 中的脚本,发现离线任务几乎未执行

可以看到,在线任务可以实现对离线任务的绝对抢占,当整机资源不足时,将保证在线任务的运行,而离线任务将无法执行。
场景三:部署在线 CPU 任务,sensitive 优先级实现 CPU 绑核
场景描述:
- 部署 CPU 优先级为 sensitive 的任务,实现 cpu 绑核
操作步骤:
- 部署任务,配置 CPU 优先级为 sensitive
YAML
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: stress-sensitive
5spec:
6 selector:
7 matchLabels:
8 app: stress-sensitive
9 template:
10 metadata:
11 labels:
12 app: stress-sensitive
13 cpu.priority: sensitive
14 spec:
15 nodeSelector:
16 kubernetes.io/hostname: 10.0.3.13
17 containers:
18 - name: stress
19 image: registry.baidubce.com/public-tools/stress-ng:latest
20 command:
21 - "stress-ng"
22 args:
23 - --cpu
24 - "0"
25 - --cpu-method
26 - all
27 - -t
28 - 1h
29 resources:
30 requests:
31 cpu: 1
32 memory: 2Gi
33 limits:
34 cpu: 1
35 memory: 2Gi- 通过 cgroups 查看绑核结果,在 pod 所在节点执行如下脚本
Shell
1#!/bin/bash
2sensitivePodID="f203ffd5-8618-4568-8547-836db6a906f2"
3sensitiveContainerID="2c551bfde9d0f5e9f46f049ac8acf856567bd9441dbdedac5fec1151f8a93721"
4
5cat /sys/fs/cgroup/cpuset/kubepods/pod${sensitivePodID}/${sensitiveContainerID}得到结果:

可以看到,该容器已经绑定了 7 号 cpu。
配置网络 QoS
开启网络优先级功能
在组件中心,修改单机隔离引擎配置,开启“网络优先级功能”
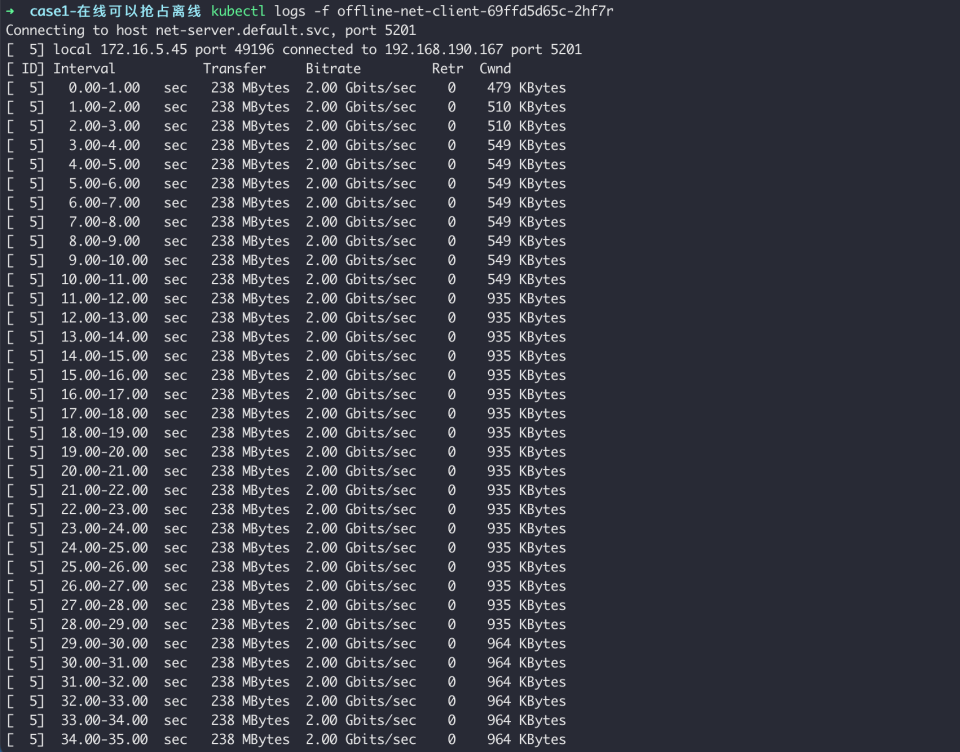
场景一:在线可以抢占离线带宽
场景描述:
- 在同一节点,先后部署低网络优先级任务,和默认网络优先级任务,观察任务的带宽变化,预期低网络优先级的任务的带宽可以被抢占
操作步骤:
- 部署 server 服务
YAML
1 apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: net-server-1
5 labels:
6 app: net-server-1
7spec:
8 replicas: 1
9 selector:
10 matchLabels:
11 app: net-server-1
12 template:
13 metadata:
14 labels:
15 app: net-server-1
16 spec:
17 nodeSelector:
18 kubernetes.io/hostname: 10.0.3.14
19 containers:
20 - name: server
21 image: registry.baidubce.com/public-tools/iperf3:latest
22 args: [ "-s", "-p", "5201"]
23 ports:
24 - name: http
25 containerPort: 5201
26 hostPort: 5201
27 protocol: TCP
28 resources:
29 limits:
30 cpu: 4
31 memory: 2Gi
32 requests:
33 cpu: 4
34---
35apiVersion: v1
36kind: Service
37metadata:
38 name: net-server-1
39spec:
40 selector:
41 app: net-server-1
42 ports:
43 - port: 5201
44 targetPort: 5201
45
46---
47apiVersion: apps/v1
48kind: Deployment
49metadata:
50 name: net-server-2
51 labels:
52 app: net-server-2
53spec:
54 replicas: 1
55 selector:
56 matchLabels:
57 app: net-server-2
58 template:
59 metadata:
60 labels:
61 app: net-server-2
62 spec:
63 nodeSelector:
64 kubernetes.io/hostname: 10.0.3.15
65 containers:
66 - name: server
67 image: registry.baidubce.com/public-tools/iperf3:latest
68 args: [ "-s", "-p", "5201"]
69 ports:
70 - name: http
71 containerPort: 5201
72 hostPort: 5201
73 protocol: TCP
74 resources:
75 limits:
76 cpu: 4
77 memory: 2Gi
78 requests:
79 cpu: 4
80---
81apiVersion: v1
82kind: Service
83metadata:
84 name: net-server-2
85spec:
86 selector:
87 app: net-server-2
88 ports:
89 - port: 5201
90 targetPort: 5201- 部署任务,配置网络优先级为 besteffort
YAML
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: offline-net-client
5 labels:
6 app: offline-net-client
7spec:
8 replicas: 1
9 selector:
10 matchLabels:
11 app: offline-net-client
12 template:
13 metadata:
14 labels:
15 app: offline-net-client
16 net.priority: besteffort
17 spec:
18 nodeSelector:
19 kubernetes.io/hostname: 10.0.3.13
20 containers:
21 - name: main
22 image: registry.baidubce.com/public-tools/iperf3:latest
23 args: [ "-c", "net-server-1.default.svc", "-p", "5201", "-b", "2000Mb" ,"-t","3600"]观察任务带宽:
- 部署网络优先级为在线的任务,观察在线和离线任务带宽
YAML
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 name: online-net-client
5 labels:
6 app: online-net-client
7spec:
8 replicas: 1
9 selector:
10 matchLabels:
11 app: online-net-client
12 template:
13 metadata:
14 labels:
15 app: online-net-client
16 spec:
17 nodeSelector:
18 kubernetes.io/hostname: 10.0.3.13
19 containers:
20 - name: main
21 image: registry.baidubce.com/public-tools/iperf3:latest
22 args: [ "-c", "net-server-2.default.svc", "-p", "5201", "-b", "2000Mb" ,"-t","3600"]观察在线任务带宽:
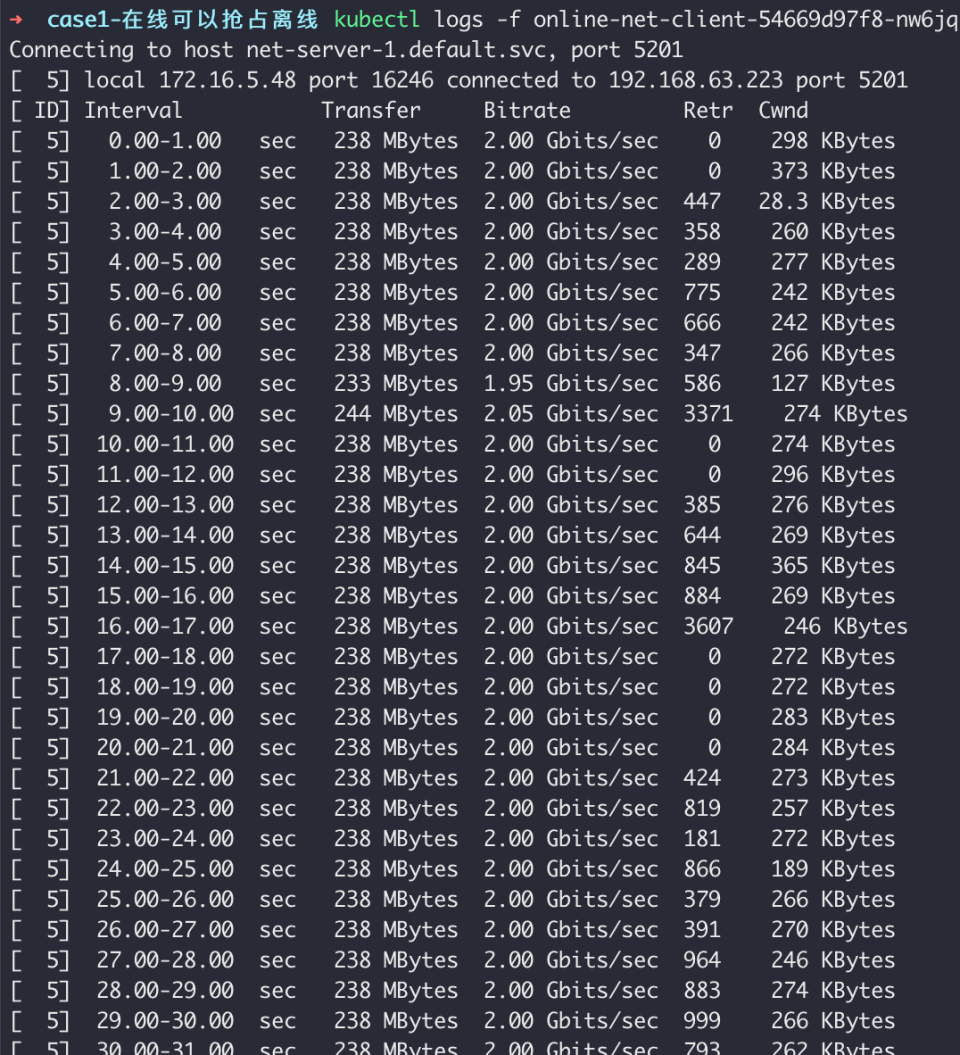
观察离线任务带宽:
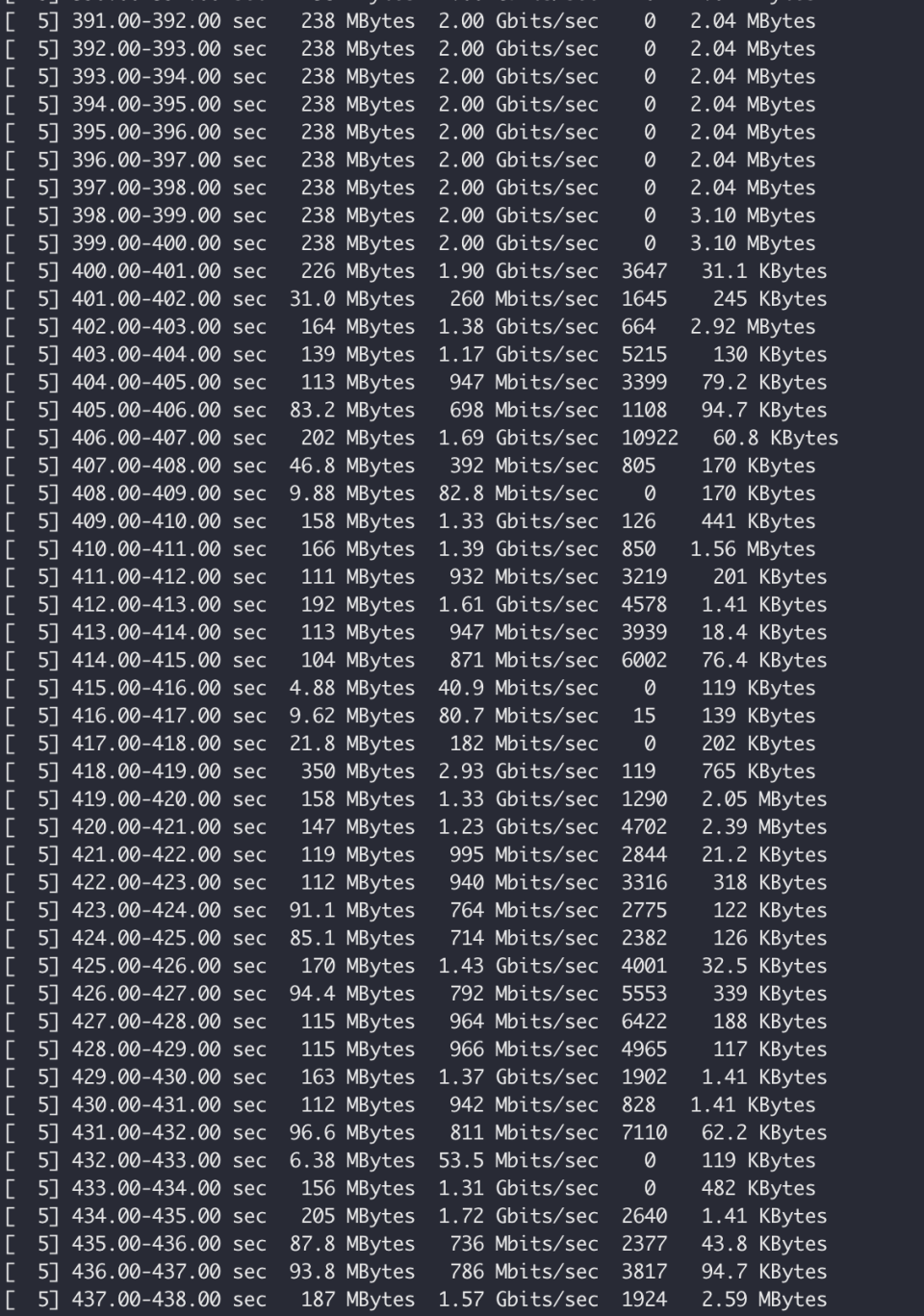
可以看到,当整机带宽不足时,将优先保证在线任务使用带宽,离线任务的带宽将被抢占。
版本记录
| 版本号 | 适配集群版本 | 更新时间 | 更新内容 | 影响 |
|---|---|---|---|---|
| 0.1.0 | v1.18+ | 2023.09.13 | CPU QoS 增强:支持 CPU 优先级配置,可以通过对工作负载设置优先级,保证高优先级业务在发生资源竞争时的资源供给量,并压制低优先级业务。 内存 QoS 增强:支持内存背景回收、OOMKill 优先级等,提升整体内存性能. 网络 QoS 增强:支持网络带宽优先级配置,出入方向限速等,灵活限制容器对网络的使用。 |
无 |