
CCE Node Problem Detector 说明
更新时间:2025-08-21
组件介绍
在 Kubernetes 集群的实际使用过程中,节点可能由于各种原因出现异常,导致影响服务的整体可用性。另外,由于 Kubernetes 的控制面在默认情况下,无法及时感知节点异常,导致在调度的过程中,将实例调度到不可用的节点上;而作为集群的使用者,用户往往也无法及时感知到集群中节点或实例的故障,导致不能及时进行止损处理。当遇到节点或实例故障时,用户期望平台能实现自动的故障恢复,例如自动迁移故障节点上的实例等。
Node-Problem-Detector 是为集群提供节点故障检测的扩展能力,用户在集群中安装该组件后,会以 DaemonSet 形式运行,来实时检测节点上的各种异常情况,并将检测结果报告给上游的 Kube-APIServer。
组件功能
- 提供节点故障检测能力
-
支持的故障上报方式包括
- NodeCondition(节点状况):可能造成 Pod 无法在这个节点运行
- Event(事件):影响节点的临时性问题,但是它对于系统诊断是有意义的
- Metrics:以上两种情况,会同时生成 Prometheus 指标,可供采集和展示
限制说明
- 集群版本在 1.18.9 以上
安装组件
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的 集群管理 > 集群列表 。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击 组件管理 。
- 在组件管理列表中选择 CCE Node Problem Detector 组件单击“安装”。
- 点击“确定”按钮完成组件的安装。
查看集群健康检查状态
安装组件后,可以在节点健康检查界面查看故障情况。
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的 集群管理 > 集群列表 。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
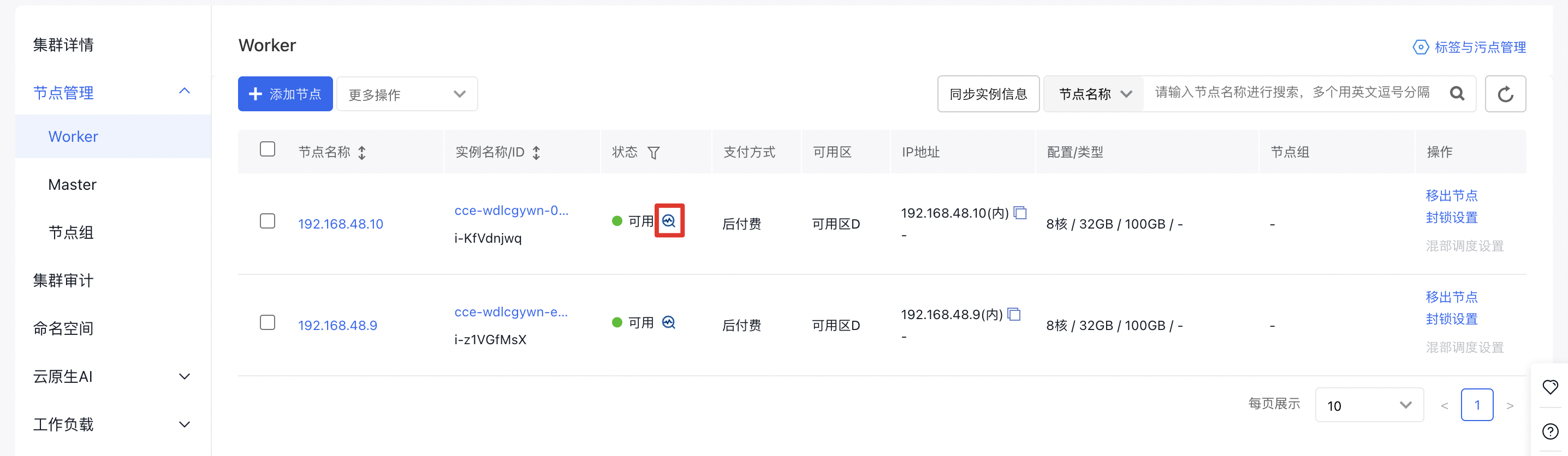
- 在集群管理页面单击 节点管理 > Worker , 进入节点管理界面。
- 点击 健康检查 图标即可展示节点的健康检查状态:
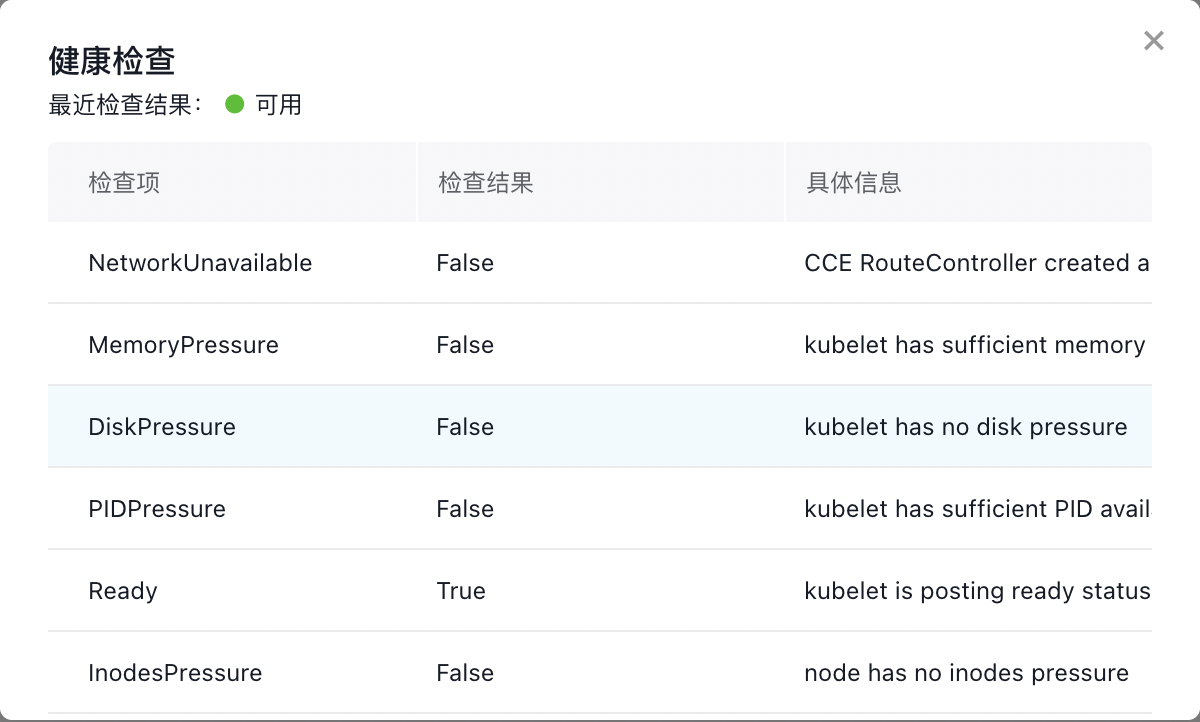
- 查看健康检查状态。目前,仅 NetworkUnavailable 和 Ready 会影响节点是否可用。
故障状态
Node Conditions
安装 CCE-Node-Problem-Detector 后,会在节点中添加以下 Conditions:
| Condition Type | 默认值 | 说明 | 影响 |
|---|---|---|---|
| FrequentKubeletRestart | False | Kubelet是否在20Min内重启超过5次 | 影响容器创建 |
| FrequentContainerRuntimeRestart | False | Docker或Containerd是否在20Min内重启超过5次 | 影响容器创建 |
| ContainerRuntimeUnhealthy | False | 节点容器运行时是否可用 | 影响容器创建 |
| CorruptDockerOverlay2 | False | Docker Overlay2文件系统错误 | 影响 Docker 容器运行时正常运行 |
| InodesPressure | False | 节点Inodes使用是否大于80% | 影响目录/文件的创建 |
| KernelDeadlock | False | 内核是否存在死锁 | 可能影响容器的创建、删除和运行 |
| ReadonlyFilesystem | False | 文件系统是否只读 | 进程无法新建目录/文件,无法执行写操作 |
| GPUUnhealthy | False | 是否存在 GPU 故障(仅支持带有 GPU 设备的 EBC 机型) | 1. GPU 发生故障不可用 2. 可能导致 GPU 训练/推理任务中断 |
| NICUnhealthy | False | 是否存在网卡故障(仅支持带有 GPU 设备的 EBC 机型) | 1. 可能导致节点、Pod 间网络通信中断 2. 可能导致 GPU 训练/推理任务中断 |
| MemoryUnhealthy | False | 是否存在内存故障(仅支持EBC机型) | 内存不可用,任务中断 |
EBC 机型故障检测介绍
针对于EBC弹性裸金属服务器,Node-Problem-Detector对接百度云硬件感知组件HAS-agent,新增对GPU/RDMA网卡/CPU/内存等硬件健康检测能力。
前提
- 机器上已经安装百度云硬件感知组件HAS-agent。
GPU检测
| 检测维度 | 说明 | 处理方式 |
|---|---|---|
| GPU掉卡 | 掉卡,无法识别GPU场景 | 更新 Node Condition, GPUUnhealthy:True |
| GPU内存 | EccError、RemappedPending等场景 | 更新 Node Condition, GPUUnhealthy:True |
| GPU链路 | Nvlink故障,带宽异常等场景 | 更新 Node Condition, GPUUnhealthy:True |
| XID | Nvidia GPU 的 Xid 故障 | 根据XID不同,处理方式不同,具体如下: 1. XID 48、62、64、74、79、95、109、122、123、124 , 处理方式:更新 Node Condition, GPUUnhealthy:True 2. 除上述列出的XID列表以外的XID,处理方式:仅打印事件 |
| 其他故障 | 温度过高、功耗异常、驱动异常等场景 | 更新 Node Condition, GPUUnhealthy:True |
CPU/内存检测
| 检测维度 | 说明 | 处理方式 |
| CPU | 常见CPU Cache读写错误等场景 | 仅打印事件 |
| 内存 | 常见的不可恢复的ECC故障等场景 | 更新 Node Condition, MemoryUnhealthy:True |
| 可以恢复的ECC错误风暴、可隔离的故障场景 | 仅打印事件 |
网卡检测
| 检测维度 | 说明 | 处理方式 |
|---|---|---|
| RDMA 网卡up/down | RDMA网卡频繁up/down | 更新 Node Condition, NICUnhealthy:True |
| RDMA 网卡降速 | RDMA网卡pcie降速,未达到设计速度等场景 | 更新 Node Condition, NICUnhealthy:True |
利用监控指标实现故障报警
Node-Problem-Detector 指标介绍
Node-Problem-Detector 暴露 Prometheus 指标如下:
| 指标名 | 指标类型 | 指标说明 |
|---|---|---|
| problem_counter | counter | 当前时刻已经发生的故障数量 |
| problem_gauge | gauge | 当前时刻,是否存在某类型的故障 |
指标中包含的 LabelSet 如下:
- instance: 故障节点
- namespace: npd 实例部署的 namespace
- type:故障类型,对应 Node Condition Type
- reason:故障原因,对应 Node Condition Reason
- region:节点所在地域
用户可根据需要基于以上指标配置 Prometheus 监控和告警;
在 CProm 中添加对 Node-Problem-Detector 的指标采集任务
在 CProm 中添加对 Node-Problem-Detector 的指标采集规则之前,需要先为 CCE 集群关联 CProm 实例,并添加指标采集任务。 操作参考:
添加如下指标采集任务:
YAML
1job_name: node-problem-detector
2scrape_interval: 3s
3kubernetes_sd_configs:
4 - role: endpoints
5
6relabel_configs:
7 - source_labels: [ __meta_kubernetes_service_annotation_npd_prometheus_scrape ]
8 action: keep
9 regex: true
10 - source_labels: [ __meta_kubernetes_service_annotation_npd_prometheus_scheme ]
11 action: replace
12 target_label: __scheme__
13 regex: (https?)
14 - source_labels: [ __meta_kubernetes_service_annotation_npd_prometheus_path ]
15 action: replace
16 target_label: __metrics_path__
17 regex: (.+)
18 - source_labels: [ __address__, __meta_kubernetes_service_annotation_npd_prometheus_port ]
19 action: replace
20 target_label: __address__
21 regex: ([^:]+)(?::\d+)?;(\d+)
22 replacement: $1:$2
23 - source_labels: [ __meta_kubernetes_endpoint_node_name ]
24 action: replace
25 target_label: node
26 - source_labels: [ __meta_kubernetes_namespace ]
27 action: replace
28 target_label: namespace
29 - source_labels: [ __meta_kubernetes_service_name ]
30 action: replace
31 target_label: service
32 - source_labels: [ __meta_kubernetes_pod_name ]
33 action: replace
34 target_label: pod版本记录
| 版本号 | 适配集群版本 | 更新时间 | 更新内容 | 影响 |
|---|---|---|---|---|
| 0.8.25 | v1.18+ | 2024-03-21 | 组件新增对机器 gid 跳序的故障检测 | -- |
| 0.8.24 | v1.18+ | 2024-03-01 | 组件新增 Kubelet 故障检测 支持配置在 Metrics Labels 中禁用 bce-instance-id 优化组件配置 |
-- |
| 0.8.23 | v1.18+ | 2024-01-08 | 适配 ubuntu22.04 操作系统 更新基础镜像,减少镜像体积, 2G -> 278M 去除对 systemctl 命令的依赖 优化对容器运行时(docker、containerd)的依赖 |
-- |
| 0.8.22 | v1.18+ | 2023-12-28 | MPS故障检测性能优化,支持根据mps-server启动用户执行探测 提供MPS故障检测开关,默认关闭,可按需开启 已经使用mps检测的用户升级后需要重新开启mps探测 |
-- |
| 0.8.21 | v1.18+ | 2023-12-27 | 网卡故障检测信息源对接 has-agent 检测 GPU Xid 故障时,支持配置忽略期望的 Xid |
-- |
| 0.8.20 | v1.18+ | 2023-12-07 | 支持 MPS 故障检测和监控 | -- |
| 0.8.19 | v1.18+ | 2023-11-30 | 故障检测采集任务支持采集节点对应实例短ID | -- |
| 0.8.18 | v1.18+ | 2023-11-23 | 优化 NPD 部署亲和性配置&监控配置 | -- |
| 0.8.17 | v1.18+ | 2023-11-20 | 优化内存故障监控时的超时时间 修正非EBC节点被部署NPD,但无HAS服务时,访问 has-agent 报错的问题 |
-- |
| 0.8.16 | v1.18+ | 2023-10-17 | GPU Xid 故障检测信息源对接 has-agent,取消检索内核日志 GPU 故障检测中,不支持自定义忽略 xid |
-- |
| 0.8.15 | v1.18+ | 2023-08-11 | 支持 CPU、内存故障检测,仅支持 EBC 机型。新增故障类型:CPUUnhealthy、MemoryUnhealthy 优化 GPU Xid 故障检测逻辑 优化 RDMA 网卡故障检测逻辑 |
-- |
| 0.8.14 | v1.18+ | 2023-06-03 | 网卡故障检测逻辑 bugfix | -- |
| 0.8.13 | v1.18+ | 2023-04-08 | NPD 支持 GPU 故障检测、网卡故障检测,仅支持 EBC 机型。新增故障类型:GPUUnhealthy、NICUnhealthy 引入社区优化及 bugfix |
-- |
| 0.8.12 | v1.18+ | 2023-03-07 | NPD 通过组件中心发布。支持以下故障检测: 1. FrequentKubeletRestart 2. FrequentContainerRuntimeRestart 3. ContainerRuntimeUnhealthy 4. CorruptDockerOverlay2 5. InodesPressure 6. KernelDeadlock 7. ReadonlyFilesystem |
-- |