
GPU运行环境检查
更新时间:2025-08-21
概述
本文档旨在指导如何对包含加速芯片(如GPU)的节点运行环境的集群检查。通过此检查,您可以确保这些节点在运行AI任务时具备必要的硬件和软件条件,从而提高任务的执行效率和成功率。
前置条件
- 已创建CCE集群。具体操作,请参见创建集群
- 包含加速芯片(如GPU)的节点已处于可用状态
注意事项
- 检查过程可能需要较长时间,请耐心等待。
- 检查期间,不建议进行其他对集群的操作,以免影响结果。
操作步骤
1.登录百度智能云管理控制台,进入“产品服务>云原生>容器引擎 CCE”,点击“集群管理>集群列表”,进入集群列表页面。
2.单击目标集群名称,然后在左侧导航栏“巡检与检查”,选择“集群检查”。
3.在集群检查>GPU运行环境检查页面,点击“立即检查”
4.在弹出的对话框中,配置检查项范围,然后选择需要检查的节点。
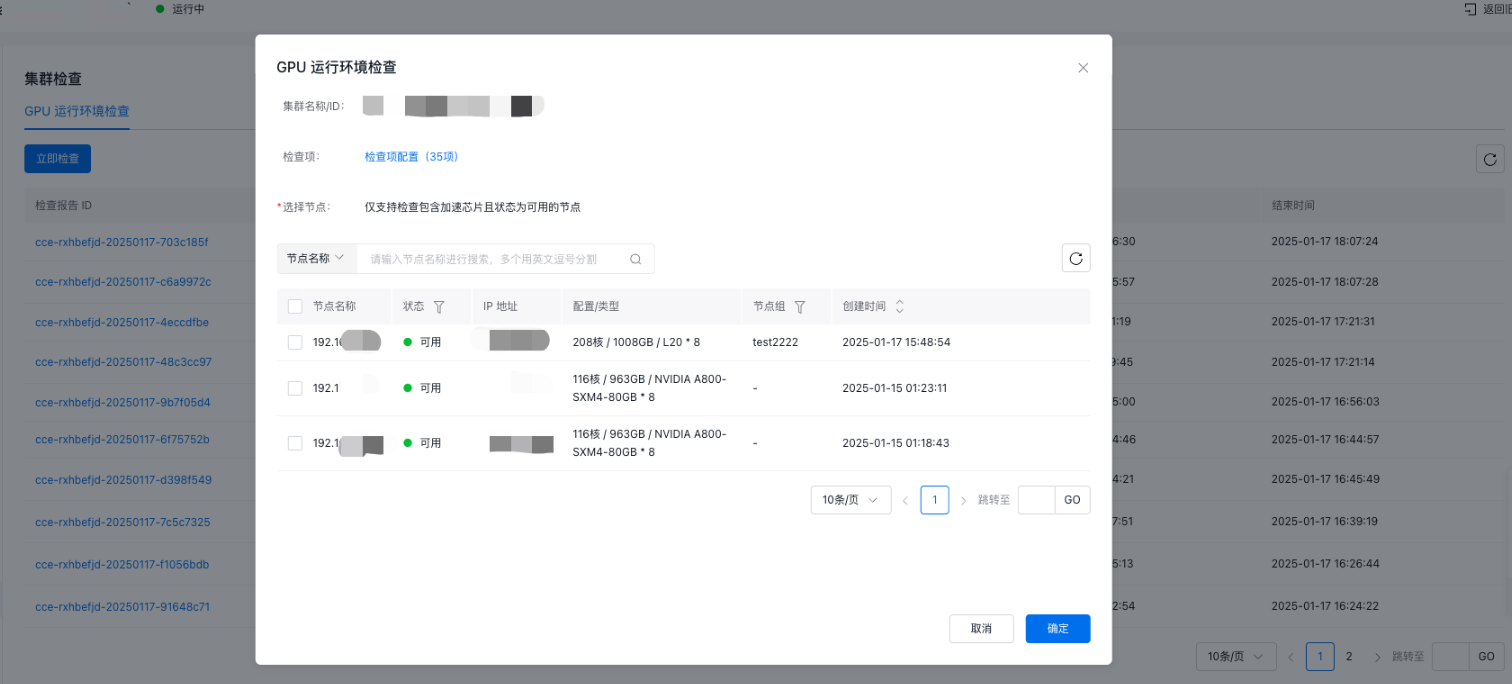
5.点击“开始检查”以启动检查流程。
6.检查完成后,系统将生成检查报告,用户可查看检查结果和建议。
GPU运行检查项说明
| 一级分类 | 二级分类 | 检查项描述 |
|---|---|---|
| 计算机软件故障 | Has agent健康性检查 | 检查Has agent的运行情况,Has正常运行才能提供硬件故障上报能力 |
| Has agent版本检查 | 检查节点安装的Has agent版本是否过低,版本过低会影响故障上报最新功能的使用和准确性 | |
| Has agent 加速芯片检测开启检查 | 检查Has agent加速芯片故障检测能力是否开启 | |
| 网卡固件版本检查 | 检查多机间网卡固件版本是否一致 | |
| 加速芯片初始化状态检查 | 检查是否存在未正确初始化或存在问题的加速芯片节点。修订版本可能导致设备存在问题,不能正常工作 | |
| 加速芯片预期数量检查 | 检查节点中感知的加速芯片数量,并与预期数量进行比较确保设备正常工作 | |
| 加速芯片固件版本检查 | 检查多机间加速芯片固件版本是否一致 | |
| 持久化模式开启检查 | 检查加速芯片是否开启了持久化模式,未开启持久化会导致加速芯片功耗增加、性能下降 | |
| OS | OS & Kernel版本检查 | 检查节点间的OS和内核版本是否一致 |
| 内核参数检查 | 检查PFS-L1设置的内核参数是否正确,阈值设置错误会影响存储设备性能 | |
| sGPU内核依赖检查 | 检查节点内核版本是否支持开启GPU虚拟化功能,较低的内核版本会导致虚拟化失败 | |
| 图形界面关闭检查 | 检查图形界面是否关闭,图形界面未关闭会导致节点死机问题 | |
| Kubelet资源预留检查 | 检查Kubelet资源预留情况,如果预留资源过少会导致节点负载过高时节点假死 | |
| home盘挂载检查 | 检查home盘挂载情况,home盘未正确挂载会导致数据盘不识别等存储问题 | |
| 镜像目录、根目录资源预留检查 | 检查镜像目录、根目录资源大小,如果过小,会导致镜像拉取失败,集群无法创建任务 | |
| 驱动 | nouveau驱动禁用检查 | 检查nouveau驱动禁用情况,该驱动不禁用会导致与加速芯片驱动冲突,影响节点运行和创建任务 |
| 网卡驱动检查 | 检查网卡驱动版本,如果存在异常版本会导致集群通信出现故障 | |
| fabric-manager安装检查 | 检查fabric-manager组件安装情况,该组件异常会导致无法正常提交训练任务 | |
| link_status健康状态检查 | 检查link_status健康状态,该状态异常会导致多机间通信失败和多机任务无法运行 | |
| peermem配置检查 | 检查加速芯片peermem包安装情况,该配置未安装会导致显存管理异常,引起任务性能下降 | |
| hALT配置检查 | 检查hALT配置情况,hALT未配置会导致物理机发生重启掉电 | |
| 网卡抖动参数配置 | 检查网卡抖动参数是否配置,抖动参数未配置会导致网络性能下降 | |
| FW版本检查 | 检查多机间FW版本检查是否一致 | |
| BMC版本检查 | 检查多机间BMC版本检查是否一致 | |
| ECC Correctable计数检查 | 检查ECC Correctable计数是否大于阈值,该数值异常说明存储可能存在硬件错误 | |
| 网卡 | MTU配置检查 | 检查MTU参数配置,该配置不正确会导致网络降速 |
| RDMA网卡mac地址小写检查 | 检查RDMA网卡mac地址是否为小写 | |
| GID index一致性检查 | 检查所有ROCE网卡v2 ipv4的GID index是否一致 | |
| 多网卡IP配置检查 | 检查所有网卡的IP配置,该配置不正确会导致RDMA网络不通 | |
| 多网卡IP rule配置检查 | 检查所有网卡的IP rule配置,该配置不正确会导致RDMA网络不通 | |
| 加速芯片NV Link状态检查 | 检查节点加速芯片的 NVLink 状态,包括活跃状态、数量和带宽 | |
| 加速芯片NV Link连接拓扑检查 | 检查多个节点加速芯片间是否有正确的NV Link连接 | |
| 集群组件&状态 | 节点状态 | 检查集群节点的运行情况,正常运行才能有效提交训练任务和部署推理服务 |
| 节点污点、封锁信息 | 检查节点的污点和封锁情况,保障信息正确以便更好使用训练任务的容忍能力 | |
| 组件部署状态 | 检查组件Pod的存活情况,正常运行才能有效提交训练任务和部署推理服务 |