CCE GPU Manager 说明
组件介绍
一系列 GPU device plugin 的集合,结合配套的 scheduler 可以实现复杂场景下的 GPU 资源调度能力。CCE GPU Manager组件支持隔离最优型,可支持算力和显存的共享与隔离。
组件功能
- 拓扑分配:提供基于 GPU 拓扑分配功能,当用户分配超过1张 GPU 卡给 Pod 时,系统自动选择拓扑连接最快的方式分配 GPU 设备。
- GPU 共享:提供为节点上的 GPU 设备开启显存共享功能,支持将 GPU 卡按显存大小分配给多个 Pod。
- 显存和算力隔离:多 Pod 共享单张 GPU 卡时进行显存和算力级别的隔离。
- 精细化调度:开启精细化调度后,创建队列和任务时均支持选择具体的GPU型号。关闭精细化调度后创建队列和容器时仅支持输入配额,不支持选择具体的GPU型号。
- 编解码实例:提交编解码任务,使用GPU独立的编解码单元进行硬件编/解码。
- 组件详细使用说明请参照:GPU独占和共享说明
使用场景
在 CCE 集群中运行 GPU 应用时,可以解决 AI 训练等场景中独占整张卡造成资源浪费的情况,从而提高资源的使用率,降低成本。
限制说明
- 支持 v1.18 及以上版本的 Kubernetes 集群。
- 目前该组件依赖于 CCE AI Job Scheduler,若您需要请一同安装,否则可能导致组件功能不可用。
- GPU 共享虚拟化目前适配了以下主流的GPU CUDA和Driver版本,其中隔离最优型对操作系统内核版本等有额外的要求。如您有其他版本适配需求请提交工单。目前支持情况具体如下。
| 配置 |
版本 |
| 容器运行时 |
Docker、Containerd |
| GPU CUDA/Driver版本 |
GPU Driver 470.X,515.X,525.X
|
| 操作系统内核版本(仅隔离最优型) |
CentOS:
3.10.0-957.21.3.el7.x86_643.10.0-1160.41.1.el7.x86_643.10.0-1160.42.2.el7.x86_643.10.0-1160.45.1.el7.x86_643.10.0-1160.62.1.el7.x86_643.10.0-1160.71.1.el7.x86_643.10.0-1160.76.1.el7.x86_643.10.0-1160.80.1.el7.x86_643.10.0-1160.81.1.el7.x86_643.10.0-1160.83.1.el7.x86_643.10.0-1160.88.1.el7.x86_643.10.0-1160.90.1.el7.x86_644.17.11-1.el7.elrepo.x86_645.4.123-1.el7.elrepo.x86_64
Ubuntu:
4.4.0-150-generic4.15.0-140-generic5.4.0-72-generic5.4.0-139-generic |
安装组件
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的 集群管理 > 集群列表 。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击 运维与管理 > 组件管理 。
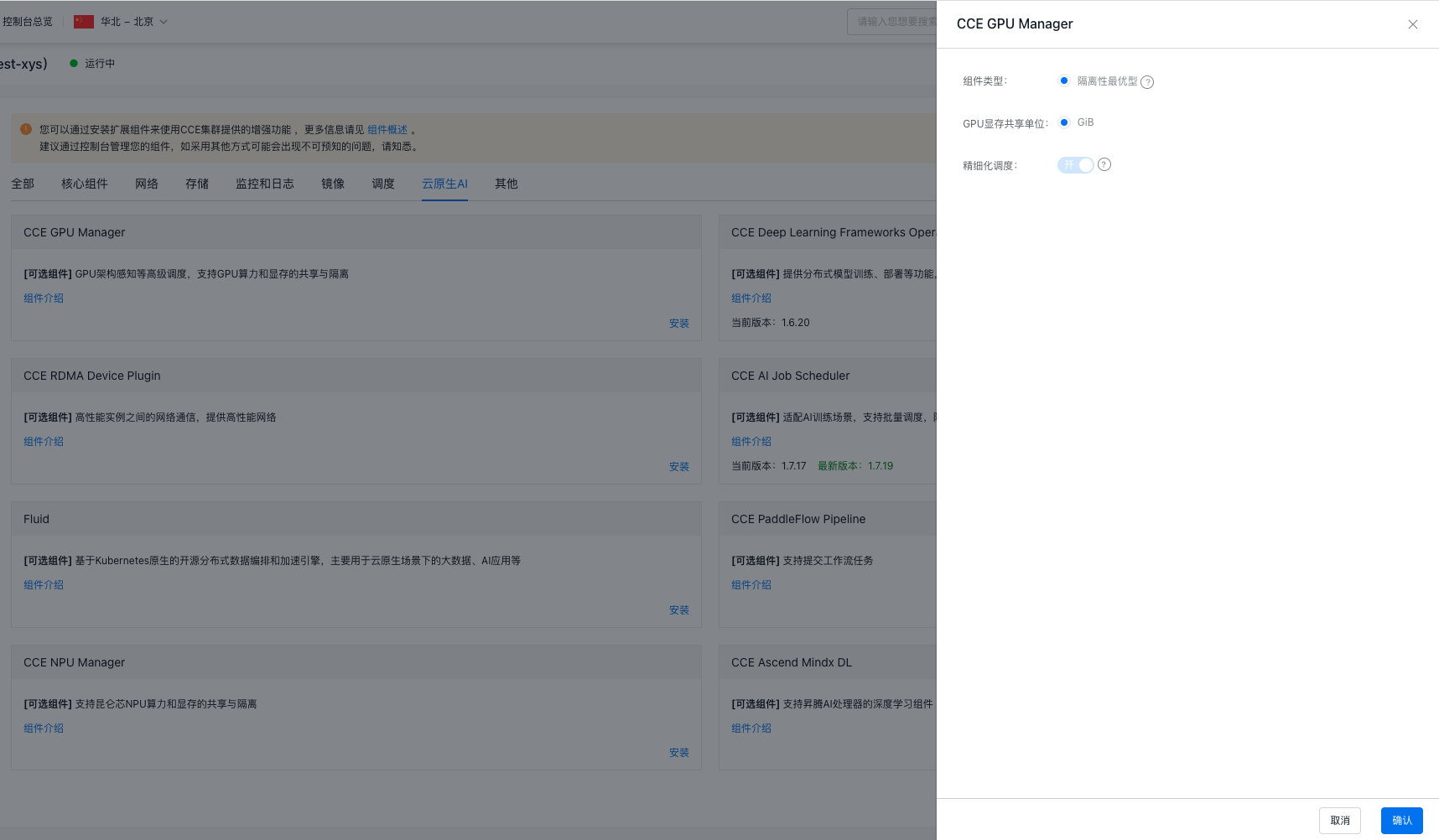
- 在组件管理列表中选择 CCE GPU Manager 组件单击"安装"。
- 在确认安装弹出框中默认选择隔离最优型。
- GPU显存共享单位默认选择GiB。
- 精细化调度默认开启。
- 点击“确认”按钮完成组件的安装。
版本记录
| 版本号 |
适配集群版本 |
更新时间 |
变更内容 |
影响 |
| 1.5.35 |
CCE v1.18+ |
2024.07.05 |
新功能:
Pod申请虚拟化资源用法调整,支持仅申请虚拟化资源描述符,去除baidu.com/xx_xx_cgpu描述符约束
优化:
RDAM机型的BCC套餐适配,支持NCCL通信库自动感知单机GPU和网卡的拓扑关系
适配H芯片调度器分卡,获取设备信息的依赖由cuda改变为nvml
缺陷修复:
【影响业务】修复PaddleJob的数据备份功能,修复备份概率失败问题 |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.34 |
CCE v1.18+ |
2024.06.24 |
优化:
container-runtime 适配 VPC-ENI 网络模式下宿主机网络容器的 nccl 环境变量注入
缺陷修复:
因影响通信性能 dcgm-exporter 默认不采集 FP16/FP32/FP64 指标; |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.33 |
CCE v1.18+ |
2024.05.31 |
新功能:
新增多调度器GPU分卡信息识别服务,识别默认调度器等其他调度器分配的 GPU 卡号信息,避免节点被多种调度器混调;
IB环境默认开启自适应路由;
优化:
虚拟化webhook支持高可用; |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.32 |
CCE v1.18+ |
2024.05.15 |
新功能:
支持集群内两种虚拟化模式共存;
支持BCC RDMA拓扑文件的自动注入;
优化:
GPU虚拟化的隔离性最优型中容器优化残留问题; |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.31 |
CCE v1.18+ |
2024.05.06 |
新功能:
新增GFD模块
支持GPU节点驱动&Cuda等环境信息上报至节点;
隔离最优型GPU虚拟化支持L20芯片;
支持 eks 模式的 hook 注入 |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.30 |
CCE v1.18+ |
2024.03.26 |
新功能:
适配bcc H800机型识别rdma拓扑
修复:
一组镜像漏洞修复; |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.29 |
CCE v1.18+ |
2024.01.19 |
新功能:
dcgm-exporter 新增nvlink带宽、sm利用率、FP64/32/16计算利用率指标 |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.28 |
CCE v1.18+ |
2023.12.15 |
新功能:
支持NCCL环境变量适配不同的GPU卡类型,A100/A800使用NCCL_IB_QPS_PER_CONNECTION=8、NCCL_IB_ADAPTIVE_ROUTING=0,H800使用NCCL_IB_QPS_PER_CONNECTION=1、NCCL_IB_ADAPTIVE_ROUTING=1
优化:
dp健康检查端口设置为可修改的参数,且取消GPU虚拟化之隔离性最优型的dp健康检查 |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.27 |
CCE v1.18+ |
2023.12.1 |
优化:
GPU虚拟化增加内核日志,打印GPU虚拟化显存OOM显存统计信息
GPU虚拟化容器残留优化,提高GPU虚拟化的容器清理的效率,容器侧兼容容器创建/容器残留等多场景,内核模块增加GPU虚拟化清理
GPU虚拟化的容器残留增加指标,体现GPU虚拟化残留 |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.26 |
CCE v1.18+ |
2023.11.17 |
新功能:
适配 Kubernetes 1.26
适配 Ubuntu 22.04 操作系统
优化:增加了 GPU虚拟化 支持内核版本的补全dp组件增加健康检查,兼容kubelet重启/访问apiserver失败等场景
缺陷修复:【影响业务】修复由于节点同时安装 docker 和 containerd 造成的 dcgm exporter 和 gpu exporter 无容器信息上报问题
【影响业务】修复由于 systemd 路径解析错误造成的 container-runtime 分配 GPU 卡和 RDMA 配置无效的错误
【影响业务】修复由于 systemd 路径解析错误造成的 gpu exporter 无法获取容器信息的错误 |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.25 |
CCE v1.18+ |
2023.11.03 |
新功能:
支持GPU 虚拟化内核态 535 驱动
支持4090芯片的独占卡/共享卡模式
优化:
GPU虚拟化之隔离性最优型 初始化优化:
增加对节点的 sgpu.ko 内核前置检查:增加残留模块版本校验以及残留无效模块删除重装
增加了 GPU虚拟化 容器的 GC 模块,实现了残留的残留的 GPU虚拟化 配置清理
优化 container-runtime-sgpu-hook prestart/poststop 的异常流程,修改流程为配置失败时,返回错误信息
缺陷修复:
【影响业务】修复由于 container-runtime 没有区分 container 获取 pod 的 resource 导致单 Pod 多容器分配错卡的问题
【影响业务】修复由于组件升级过程中,install.sh 进程退到了内核态导致的 DCGM pod 一直处于 Terminating 状态,不能删除
【影响业务】修复由于 runtime 默认 lib-path 在操作系统Ubuntu 20中不生效造成的任务启动报错
【影响业务】修复 CUDA Driver 525 驱动环境下,性能最优型GPU虚拟化 共享卡的 libcuda.so 劫持无效的问题
限制:
不支持创建使用 性能最优型GPU虚拟化 共享卡以 NCCL 进行通信的 DDP 训练任务 |
GPU内核态虚拟化业务不支持热升级,升级方式为排空节点升级 |
| 1.5.24 |
CCE v1.18+ |
2023.09.22 |
新功能:支持单容器使用多共享卡功能
缺陷修复: 解决虚拟化场景监控指标获取失败问题
使用限制:当前版本为1.5.14及以下时,若开启性能最优型GPU虚拟化能力,需要停止虚拟化任务,升级组件 当前版本为1.5.13及以下时,若开启隔离最优型GPU虚拟化能力,需要停止虚拟化任务,升级组件 |
|
| 1.5.23 |
CCE v1.18+ |
2023.08.29 |
优化: 默认配置NCCL_DEBUG日志必要的子系统,NCCL_DEBUG_SUBSYS由ENV改为INIT,ENV,GRAPH
使用限制:当前版本为1.5.14及以下时,若开启性能最优型GPU虚拟化能力,需要停止虚拟化任务,升级组件 当前版本为1.5.13及以下时,若开启隔离最优型GPU虚拟化能力,需要停止虚拟化任务,升级组件 |
|
| 1.5.22 |
CCE v1.18+ |
2023.08.10 |
缺陷修复:修正并发创建虚拟化容器时,偶发虚拟化显存和算力资源的分配错误问题
使用限制:当前版本为1.5.14及以下时,若开启性能最优型GPU虚拟化能力,需要停止虚拟化任务,升级组件当前版本为1.5.13及以下时,若开启隔离最优型GPU虚拟化能力,需要停止虚拟化任务,升级组件 |
|
![]()
