
使用 AIAK-Training 部署分布式训练任务
更新时间:2025-08-21
前提条件
- 已经开通CCE云原生AI服务。
- CUDA 11.2,Pytorch 1.8.1,TensorFlow 2.5.0,MxNet 1.8.0,如果AI应用是其他的版本,请提交工单。
操作流程
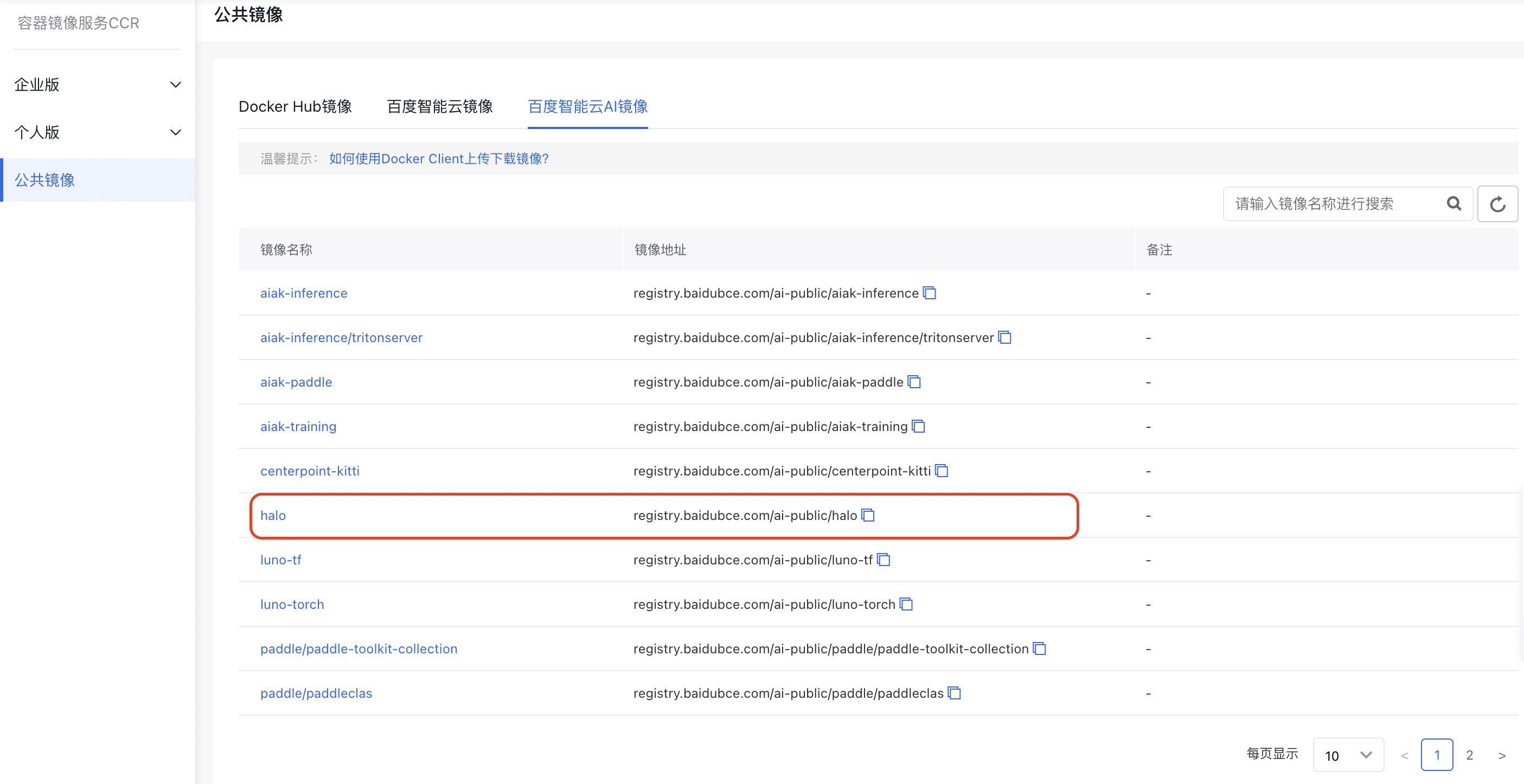
1.选择训练镜像
在CCR公共镜像的“百度智能云AI镜像” 中选择“Halo”加速镜像,作为训练基础镜像,该镜像内已安装了 CUDA、Python 3、PyTorch、Tensorflow、MxNet和AIAK-Training加速软件等。
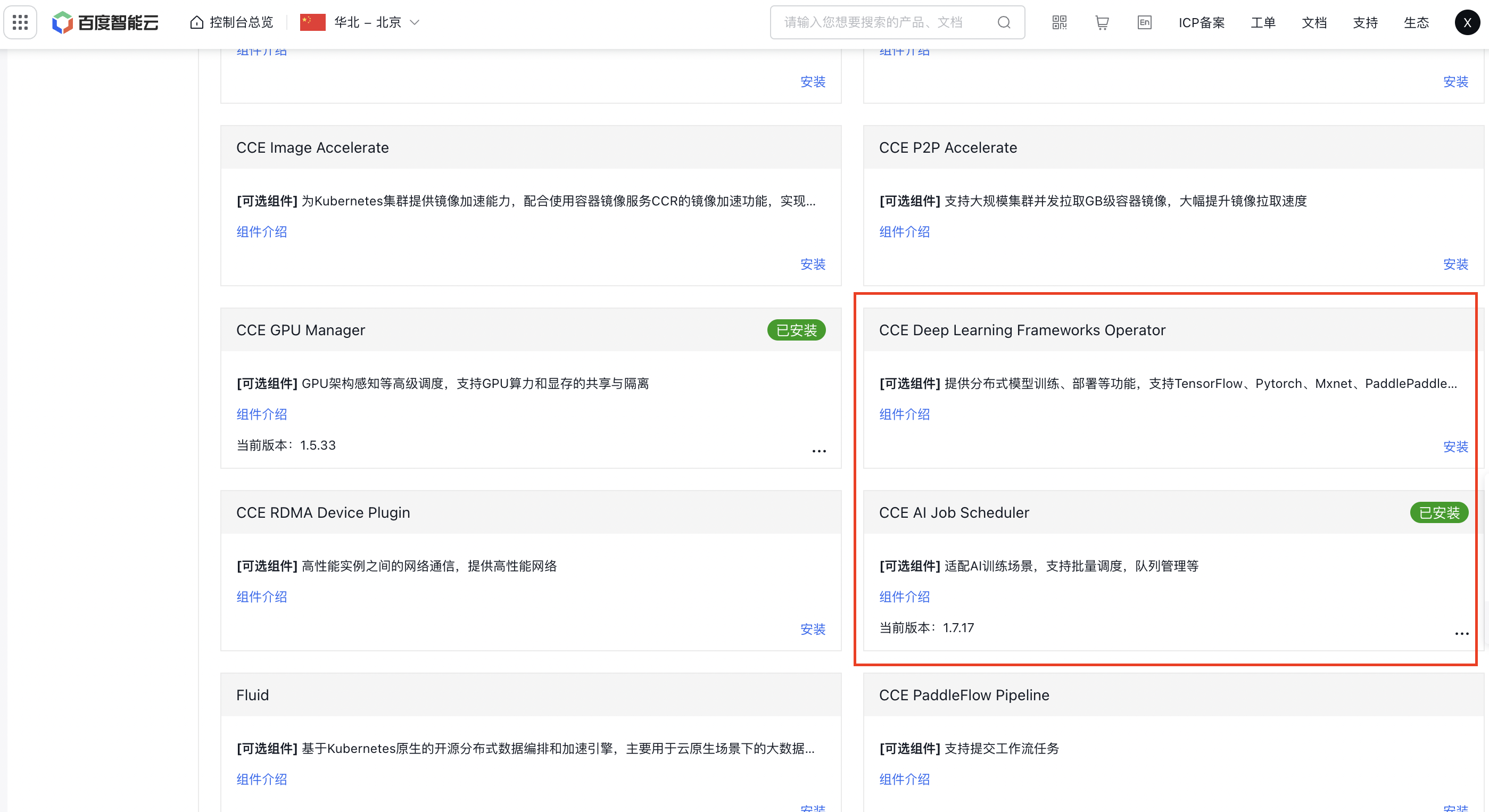
2.组件安装
点击集群名称进入,点击组件管理->云原生AI,点击安装CCE Deep Learning Frameworks Operator组件和CCE AI Job Scheduler,点击确定。
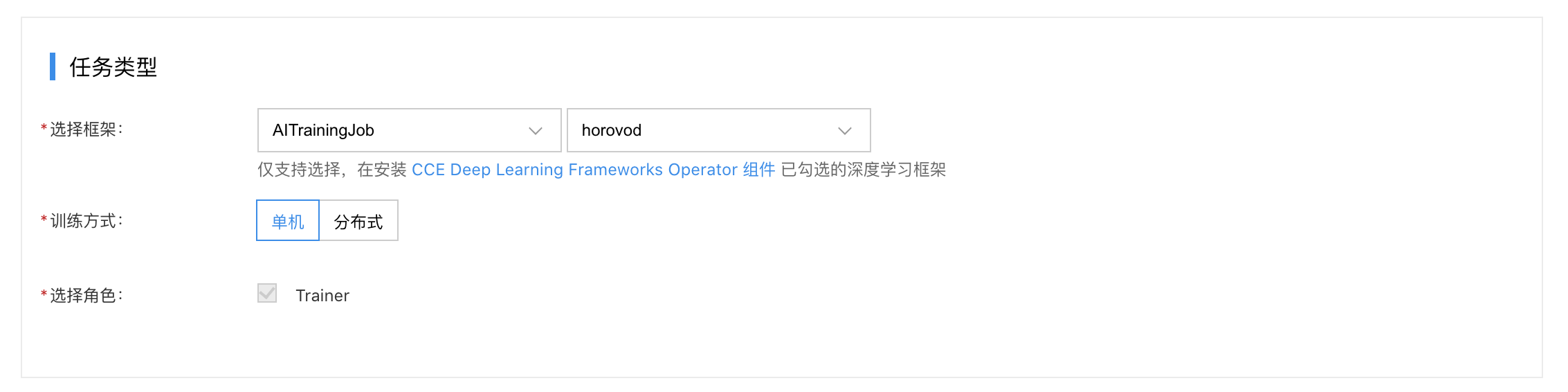
3.任务提交
云原生AI->任务管理->新建任务
- 选择框架AITrainingJob,horovod。
- 选择训练方式:分布式。
- 选择角色:选择“Launcher”,同时需要指定pod的弹性范围。
- 容器组配置->生命周期->启动命令中配置如下需要的内容。
启用优化版分层Allreduce
Plain Text
1 horovodrun --nccl-hierarchical-allreduce [other-horovod-args] python [executable] [app-args]horovodrun命令行通过传递 --nccl-hierarchical-allreduce 参数使能。
启用DGC稀疏化通信压缩算法
Plain Text
1horovodrun --dgc \
2 --compress-ratio 0.001 \
3 --sample-ratio 0.01 \
4 --clip-grad-func norm/value\
5 --clip-grad-func-params 0.01 \
6 ... ...
7 [other-horovod-args] python [executable] [app-args]其中,可配置DGC相关的参数有:
| 参数 | 说明 | 必填项 |
|---|---|---|
| compress_ratio | 压缩率,float,默认0.001,值越小,梯度的通信量越少;(推荐手动配置) | 是 |
| sample_ratio | 样本采集比率,float,默认0.01 | 否 |
| strided_sample:bool | 默认True,是否按照步幅采集样本 |
否 |
| compress_upper_bound | 压缩上限,默认1.3 | 否 |
| compress_lower_bound | 压缩下限,默认0.8 | 否 |
| max_adaptation_iters | 最大自适应次数 | 否 |
| resample | bool,默认True,是否重新采样 | 否 |
| fp16_values | bool,默认False,梯度中的元素值是否转成fp16 | 否 |
| int32_indices | bool,默认False,梯度中元素索引是否转成int32 | 否 |
| warmup_epochs | 预训练epoch数 | 否 |
| warmup_coeff | 模型预训练阶段的压缩率列表,若有多个值则命令行中以空格间隔,比如warmup_epochs=3,warmup_coeff=[0.5,0.6,0.7],表示预热阶段的第一个step选择50%的梯度进行通信,第二个step选择60%的梯度进行通信,第三个step选择70%的梯度进行通信 | 否 |
| clip_grad_func | 梯度裁剪,可选norm或value,分别对应Pytorch中的 clip_grad_norm_和 clip_grad_value_ |
否 |
| clip_grad_func_params | 梯度裁剪方法的参数 | 否 |
| momentum_masking | bool,默认True,动量隐藏,避免梯度过时更新问题 | 否 |
注:DGC压缩算法目前仅支持SGD优化器。
启用参数更新和梯度通信重叠
用户使能参数更新和梯度通信重叠功能,只需在horovodrun命令行里进行如下配置即可。
Plain Text
1horovodrun --overlap-backward-and-step \
2 --clip-grad-func norm/value\
3 --clip-grad-func-params 0.01 \
4 ... ...
5 [other-horovod-args] python [executable] [app-args]- 若用户在参数更新之前,需要进行梯度裁剪操作,可以通过设置clip_grad_func和 clip_grad_func_params两个参数来指定,此时用户在代码中的梯度裁剪调用需要移除。
- 若用户同时开启了DGC和参数更新和梯度通信重叠功能,并且指定了梯度裁剪方法,则梯度裁剪操作会在DGC中进行, 重叠过程中不进行梯度裁剪。
- 如果用户不开启参数更新和梯度通信重叠,无需指定梯度裁剪相关参数,指定也不会生效。
启用FusedOptimizer
用户使能优化器融合功能,只需在horovodrun命令行里进行如下配置即可。
Plain Text
1horovodrun --fuse-optimizer
2 ... ...
3 [other-horovod-args] python [executable] [app-args]注:目前fused optimizer与参数更新和梯度通信重叠两个功能暂不兼容。