
CCE Resource Recommender 用户文档
组件介绍
-
Kubernetes 提升业务编排和资源利用率
- Kubernetes 可以有效的提升业务编排能力和资源利用率,但如果没有额外的能力支撑,提升的能力十分有限。
- Kubernetes 集群的资源利用率不高的主要原因是根据 Kubernetes 的资源调度逻辑,在创建 Kubernetes 工作负载时,通常需要为工作负载配置合适的资源 Request,表示对资源的占用和限制,其中对利用率影响最大的是 Request。
- 为防止自己的工作负载所用的资源被别的工作负载所占用,或者是为了应对高峰流量时的资源消耗诉求,用户习惯于为 Request 设置较大的数值。
- Request 和实际使用资源之间的差值,是不能被其它工作负载所使用的,因此造成了浪费。
- Request 数值设置不合理,造成了 Kubernetes 集群资源利用率低。
- 百度智能云 CCE 支持在集群中安装 CCE Resource Recommender 组件。CCE Resource Recommender 组件 可以为 Kubernetes 的 Workload 推荐容器级别资源的 Request 数值,减少资源浪费
部署在集群内的资源对象
安装 CCE Resource Recommender 组件 , 将在集群内部署以下 Kubernetes 对象:
| Kubernetes 对象名称 | 类型 | 所属 Namespaces |
|---|---|---|
| analytics.analysis.baidubce.com | CustomResourceDefinition | - |
| recommendations.analysis.baidubce.com | CustomResourceDefinition | - |
| analysis-default | Analytics | kube-system |
| recommendation-configuration | ConfigMap | kube-system |
| recommenderd | ClusterRole | - |
| recommenderd | ClusterRoleBinding | - |
| recommenderd | Service | kube-system |
| recommenderd | ClusterRoleBinding | kube-system |
| recommenderd | ServiceAccount | kube-system |
| recommenderd | Deployment | kube-system |
功能说明
支持为 Deployment、StatefulSet、DaemonSet 中的每一个 Container 智能推荐合适的资源 Request。 支持维持 Request 比例:推荐的 Request 会维持初始 Workload 中 Container 设置的 Reqeust 之间的比例。
CCE Resource Recommender 推荐原理
组件在 kube-system 命名空间下创建 Analytics CR 对象,覆盖所有集群中的所有 Kubernetes 原生工作负载(Deployment、DaemonSet、StatefulSet),会分析工作负载最长 14 天的监控数据数据,12 小时更新一次推荐值。 然后根据 Analytics 生成集群内每个工作负载的 Recommendation CR 对象,用于存储推荐的数据。 Recommendation CR 如果产生了推荐数据,就会把推荐数据写入到对应工作负载的 Annotation 里。
注意事项
环境要求
- Kubernetes 版本:1.18+
- 接入 Prometheus 监控服务(CProm 或 自建 Prometheus 数据源)
被控资源要求
- 支持 Deployment、StatefulSet、DaemonSet。
- 不支持 Job、CronJob,不支持不是由 Workload 管理的 Pod。
推荐计算
- 推荐最小值:单个容器推荐的 CPU 最小值是 0.125 核,即 125m;内存的最小值是 125Mi。
- 该组件会自动分析工作负载历史的监控数据,推荐合适的 Request 数值。
- 安装该组件非立即生效,为准确计算推荐值,需要分析该 Workload 的历史资源使用数据。
- 不同的 Workload 的计算时间长度可能不一致,集群中不同的 Workload 之间互相可能会有影响。
- 安装该组件后,对至少运行一天的 Workload 产生推荐数据。
- 对于安装组件后新建的 Workload,一般情况下,也需要一天的时间才会产生 Workload 的推荐数据。
- 建议工作负载稳定运行一段时间之后,再使用推荐值更新 Workload。
使用说明
安装组件
百度智能云官方 helm 模版安装。
安装流程
1、开启 CProm
- 登录CCE管理控制台,选择“监控日志 > Prometheus监控”,点击“接入实例”。
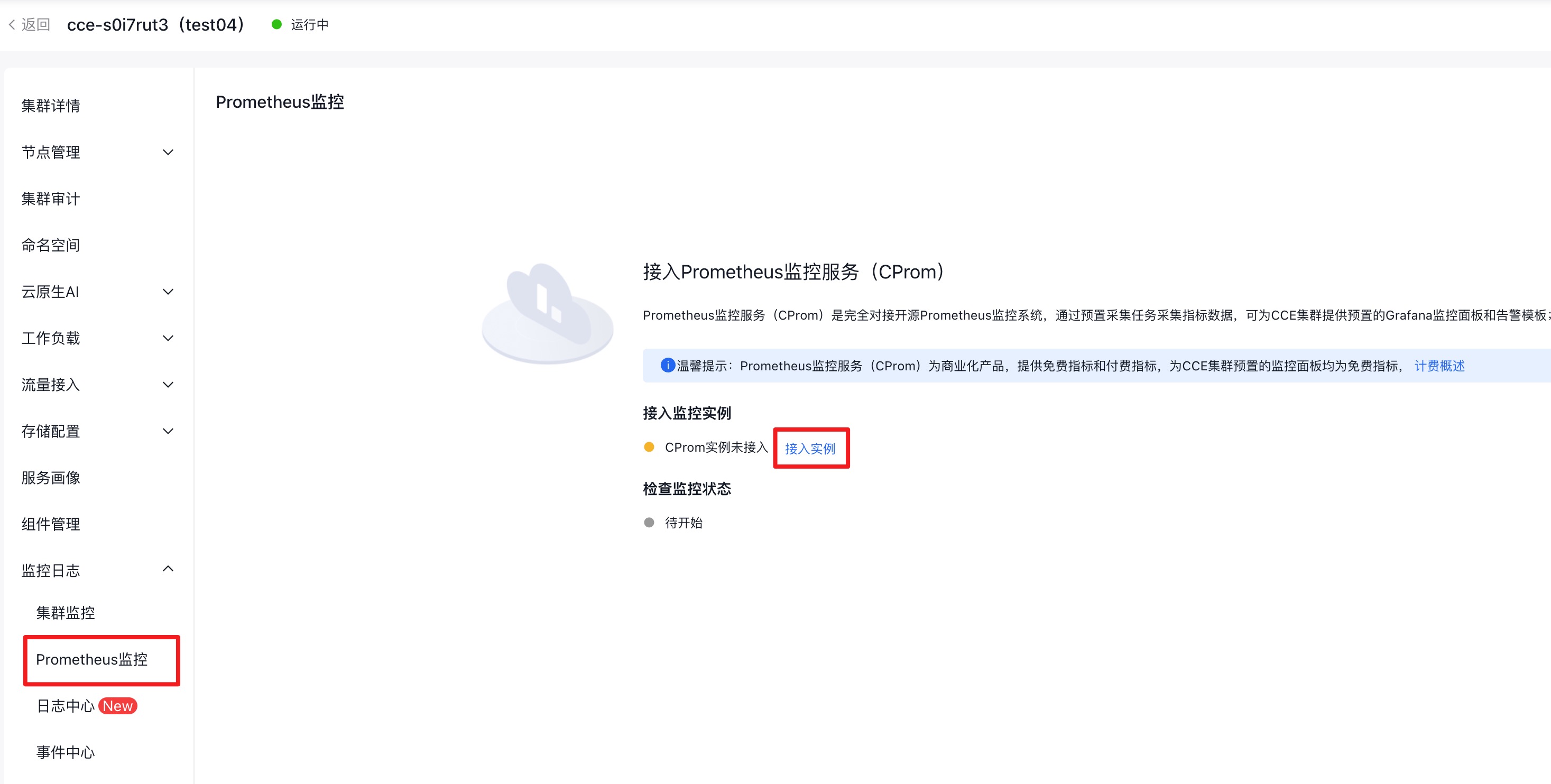
- 等待接入实例成功, 单击"跳转到Prometheus监控服务"。
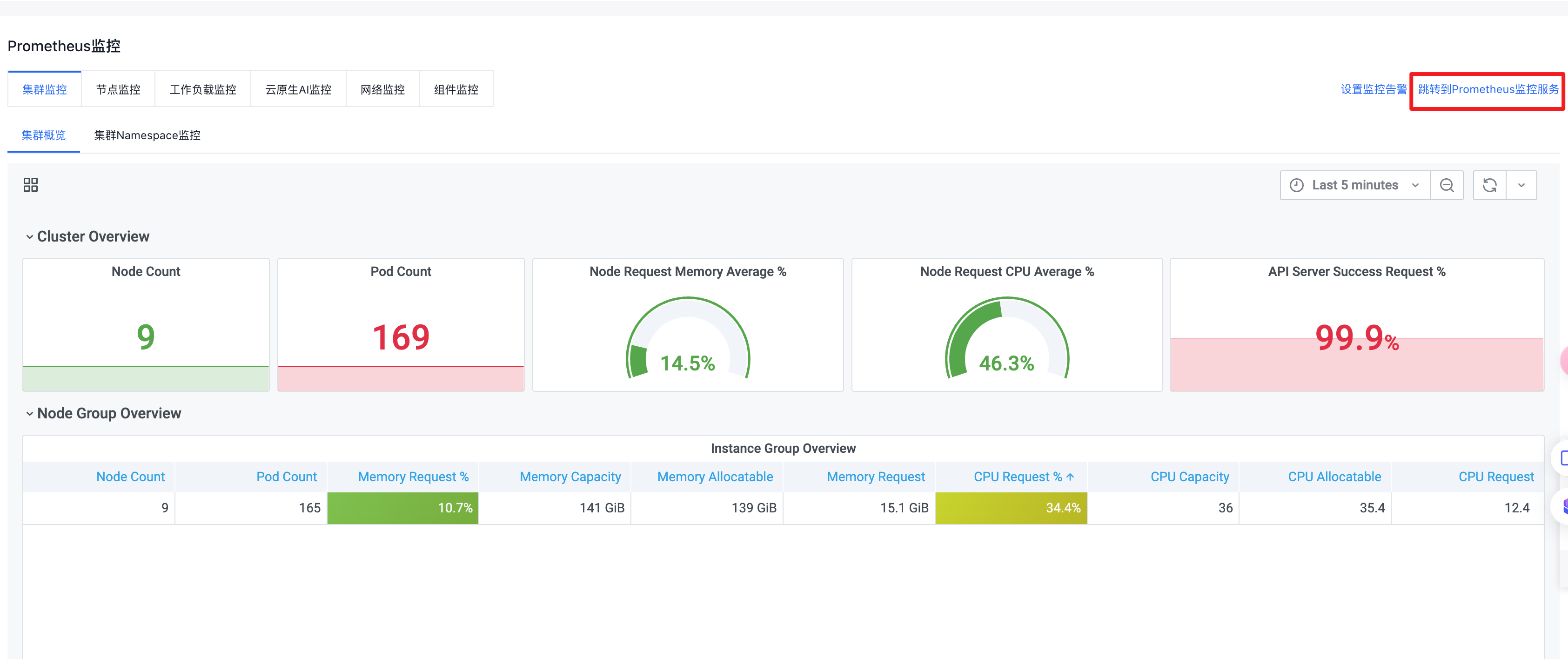
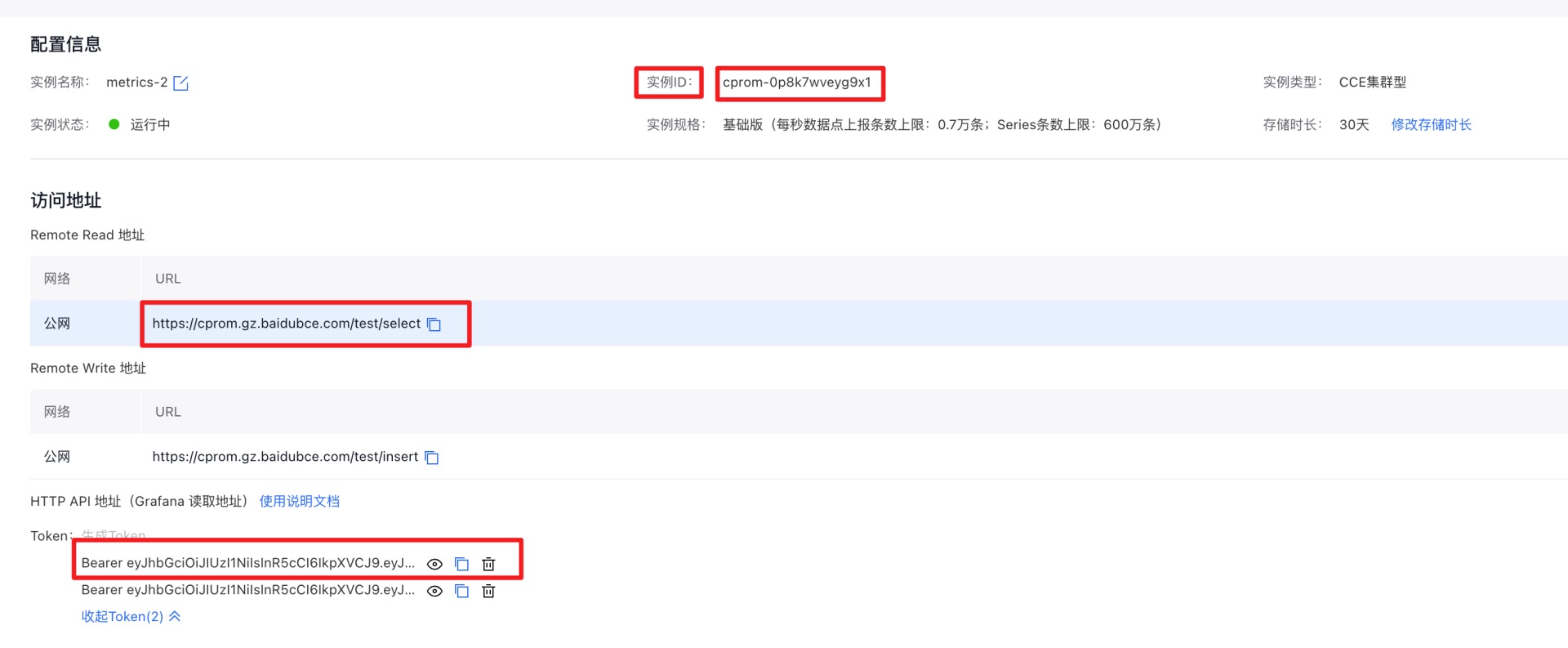
- 在监控实例页面复制 实例id 和 Remote Read 地址,且单击生成Token并复制。这些信息将用于下一步安装。
2、 安装 CCE Resource Recommender
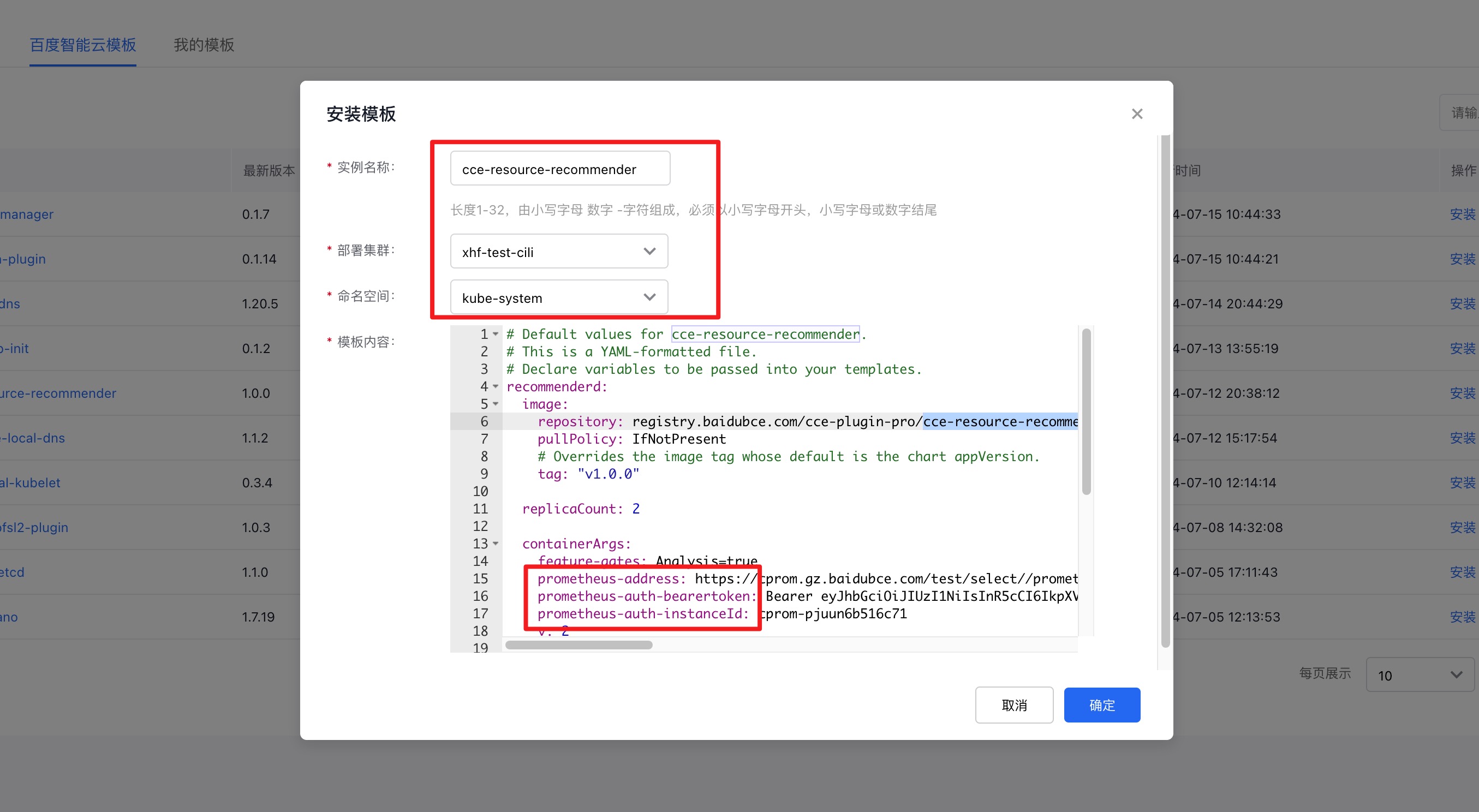
| 参数 | 描述 | 默认值 | 是否必填 |
|---|---|---|---|
| recommenderd.containerArgs.prometheus-address | recommenderd 的 Prometheus 地址 | 空(Cprom的地址后面需加 /prometheus ) | 是 |
| recommenderd.containerArgs.prometheus-auth-instanceId | recommenderd 的 CProm 实例ID | 空 | 是 |
| recommenderd.containerArgs.prometheus-auth-bearertoken | recommenderd 的 CProm Token信息 | 空 | 是 |
| analysisDefault.enable | 是否开启全局资源推荐默认配置 | ||
| 默认配置会 | true | 否 |
- 添加参数示例
1# Default values for cce-resource-recommender.
2# This is a YAML-formatted file.
3# Declare variables to be passed into your templates.
4recommenderd:
5 image:
6 repository: registry.baidubce.com/cce-plugin-pro/cce-resource-recommender
7 pullPolicy: IfNotPresent
8 # Overrides the image tag whose default is the chart appVersion.
9 tag: "v1.0.0"
10
11 replicaCount: 2
12
13 containerArgs:
14 feature-gates: Analysis=true
15 v: 2
16 prometheus-address: https://cprom.gz.baidubce.com/test/select/prometheus
17 prometheus-auth-instanceId: cprom-pjuun6b516c71
18 prometheus-auth-bearertoken: Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJuYW1lc3BhY2UiOiJjcHJvbS1wanV1bjZiNTE2YzcxIiwic2VjcmV0TmFtZSI6ImVjYTk3ZTE0OGNiNzRlOTY4M2Q3YjcyNDA4MjlkMWZmIiwiZXhwIjoxNzgzODUwMTkyLCJpc3MiOiJjcHJvbSJ9.U5VkXlKbSJvOqPHWW_gGOhaEJA-hDdvsOyIHgYijacA
19
20 podAnnotations: { }
21
22 resources: { }
23
24 nodeSelector: { }
25
26 tolerations: [ ]
27
28 affinity: { }
29
30analysisDefault:
31 enable: true3、 验证安装是否成功
使用如下命令检查安装的 Deployment 是否正常:
kubectl get deploy recommenderd -n kube-system
结果类似如下:
1NAME READY UP-TO-DATE AVAILABLE AGE
2recommenderd 2/2 2 2 37s卸载 CCE Resource Recommender
helm --kubeconfig {$kubeconfig} uninstall cce-resource-recommender -n kube-system
后台获取推荐数值
工作负载
CCE Resource Recommender 组件会将推荐值保存至对应工作负载的YAML文件中,您可以通过标准的 Kuberentes API 获取每个工作负载的推荐值,然后集成到业务的发布系统中。如下所示查看工作负载下每个容器的 Request 推荐量:
1apiVersion: apps/v1
2kind: Deployment
3metadata:
4 annotations:
5 analysis.baidubce.com/resource-recommendation: |
6 containers:
7 # 若一个 Pod 里有多个容器,每个容器都有 CPU 和 Memory 的 Request 的推荐值
8 - containerName: nginx
9 target:
10 cpu: 125m
11 memory: 125Mi #若这里缺少单位,显示的是字符串"58243235",省略的单位是byte
12 deployment.kubernetes.io/revision: "1"
13 creationTimestamp: "2024-06-11T03:15:57Z"
14 generation: 1
15 labels:
16 app: nginx
17 name: deployment-example
18 namespace: default
19 resourceVersion: "1118119"
20 uid: 8b6d54d9-c683-4e76-a95e-658e14a954b1
21spec:
22 progressDeadlineSeconds: 600
23 replicas: 1
24 revisionHistoryLimit: 10
25 selector:
26 matchLabels:
27 app: nginx
28 strategy:
29 rollingUpdate:
30 maxSurge: 25%
31 maxUnavailable: 25%
32 type: RollingUpdate
33 template:
34 metadata:
35 creationTimestamp: null
36 labels:
37 app: nginx
38 spec:
39 containers:
40 - image: hub.baidubce.com/cce/nginx-alpine-go:latest
41 imagePullPolicy: Always
42 livenessProbe:
43 failureThreshold: 3
44 httpGet:
45 path: /
46 port: 80
47 scheme: HTTP
48 initialDelaySeconds: 20
49 periodSeconds: 5
50 successThreshold: 1
51 timeoutSeconds: 5
52 name: nginx
53 ports:
54 - containerPort: 80
55 protocol: TCP
56 readinessProbe:
57 failureThreshold: 3
58 httpGet:
59 path: /
60 port: 80
61 scheme: HTTP
62 initialDelaySeconds: 5
63 periodSeconds: 5
64 successThreshold: 1
65 timeoutSeconds: 1
66 resources:
67 limits:
68 cpu: 250m
69 memory: 512Mi
70 requests:
71 cpu: 250m
72 memory: 512Mi
73 terminationMessagePath: /dev/termination-log
74 terminationMessagePolicy: File
75 dnsPolicy: ClusterFirst
76 restartPolicy: Always
77 schedulerName: default-scheduler
78 securityContext: {}
79 terminationGracePeriodSeconds: 30Recommendation CR
CCE Resource Recommender 组件会根据分析结果会生成集群内每个工作负载的 Recommendation CR 对象,用于存储推荐数据,同时也会将推荐值保存到工作负载的 YAML 中
1apiVersion: analysis.baidubce.com/v1alpha1
2kind: Recommendation
3metadata:
4 annotations:
5 analysis.baidubce.com/run-number: "1"
6 creationTimestamp: "2024-06-11T04:54:27Z"
7 generateName: analysis-default-resource-
8 generation: 2
9 labels:
10 analysis.baidubce.com/analytics-uid: 83cccfd5-b3c5-45aa-a92a-d9dd607dc75f
11 analysis.baidubce.com/recommendation-rule-name: analysis-default
12 analysis.baidubce.com/recommendation-rule-recommender: Resource
13 analysis.baidubce.com/recommendation-rule-uid: bce27929-64d6-4b5f-89e4-001cbed5ed64
14 analysis.baidubce.com/recommendation-target-kind: StatefulSet
15 analysis.baidubce.com/recommendation-target-name: agent-q7vl19h81
16 analysis.baidubce.com/recommendation-target-version: v1
17 app.kubernetes.io/component: vmagent
18 app.kubernetes.io/instance: agent-q7vl19h81
19 app.kubernetes.io/managed-by: Helm
20 app.kubernetes.io/name: monitor-agent
21 app.kubernetes.io/version: 0.2.0
22 helm.sh/chart: monitor-agent-0.3.6
23 name: analysis-default-resource-2gzjt
24 namespace: default
25 ownerReferences:
26 - apiVersion: analysis.baidubce.com/v1alpha1
27 blockOwnerDeletion: false
28 controller: false
29 kind: RecommendationRule
30 name: analysis-default
31 uid: bce27929-64d6-4b5f-89e4-001cbed5ed64
32 resourceVersion: "1118082"
33 uid: 4793159d-83b5-45db-8c34-c3443a7c45cd
34spec:
35 adoptionType: StatusAndAnnotation
36 completionStrategy:
37 completionStrategyType: Once
38 targetRef:
39 apiVersion: apps/v1
40 kind: StatefulSet
41 name: agent-q7vl19h81
42 namespace: cprom-system
43 type: Resource
44status:
45 action: Patch
46 conditions:
47 - lastTransitionTime: "2024-06-11T04:54:28Z"
48 message: Recommendation is ready
49 reason: RecommendationReady
50 status: "True"
51 type: Ready
52 currentInfo: '{"spec":{"template":{"spec":{"containers":[{"name":"sidecar","resources":{"requests":{"cpu":"100m","memory":"100Mi"}}},{"name":"vmagent","resources":{"requests":{"cpu":"100m","memory":"100Mi"}}}]}}}}'
53 lastUpdateTime: "2024-06-11T04:54:28Z"
54 recommendedInfo: '{"spec":{"template":{"spec":{"containers":[{"name":"sidecar","resources":{"requests":{"cpu":"125m","memory":"125Mi"}}},{"name":"vmagent","resources":{"requests":{"cpu":"125m","memory":"125Mi"}}}]}}}}'
55 recommendedValue: |
56 resourceRequest:
57 containers:
58 - containerName: sidecar
59 target:
60 cpu: 125m
61 memory: 125Mi
62 - containerName: vmagent
63 target:
64 cpu: 125m
65 memory: 125Mi
66 targetRef: {}在该示例中:
- 推荐的 TargetRef 指向 cprom-system 的 StatefulSet:agent-q7vl19h81
- 推荐类型为资源推荐
- adoptionType 是 StatusAndAnnotation,表示将推荐结果展示在 recommendation.status 和 Deployment 的 Annotation
- recommendedInfo 显示了推荐的资源配置,currentInfo 显示了当前的资源配置,格式是 Json ,可以通过 Kubectl Patch 将推荐结果更新到 TargetRef