
CCE Descheduler 说明
组件介绍
CCE Descheduler 是容器引擎 CCE 在 社区版 Descheduler 的基础上,新增实现了 “基于节点 CPU/Memory 真实利用率” 进行 Pod 重调度的组件。“节点真实资源利用率”依赖 Prometheus 进行节点资源利用率信息的采集,支持 用户自建 Prometheus 和 百度云托管 Prometheus 两种数据源。
功能介绍
在 Kubernetes 中,kube-scheduler 负责对 Pending 状态的 Pod 进行调度,将 Pod 和具体的 Node 绑定。调度器对某个 Pod 是否可以被调度的决策,是由一组可配置的策略决定,被称为 predicates 和 priorities。调度器的决策是受到待调度的 Pod 出现时的集群资源视图影响的,这种一次性的调度存在局限:Node 节点数量、标签、污点、容忍等的变动可能会导致已经被调度过的 Pod 不是最优调度。我们可能需要将某些已经处于运行状态的 Pod 迁移到其他节点上。
社区版本的 descheduler 中提供的节点利用率相关的策略(如 LowNodeUtilization、HighNodeUtilization)是利用 Pod 的 Reqeust 和 Limit 数据,而不是节点的真实利用率,例如内存型和计算型任务分配的资源一致,但是在运行过程中的实际消耗量有巨大差异。
CCE Descheduler 新增了 “基于节点真实利用率” 的重调度策略。通过 Prometheus 获取各节点的负载统计信息,并根据用户设置的阈值对高负载节点上的 Pod 发起驱逐。
使用场景
基于节点 CPU/Memory 真实利用率进行 Pod 重调度。
注意事项
- 默认不驱逐 关键 Pod(Critical Pods),即 priorityClassName 被配置为 system-cluster-critical 或者 system-node-critical;
- 不驱逐不受工作负载(Deployment、StatefulSet、Job 等)管理的 Pod,因为这类 Pod 被驱逐后不会被重调度;
- 默认不驱逐 DaemonSet 管理的 Pod;
- 默认不驱逐使用本地存储的 Pod;
- 默认不驱逐挂载 PVC 的 Pod;
- 默认不驱逐系统组件的 Pod;
- 可以使用 PodDisruptionBudget 保护 Pod 不被驱逐,例如用户可以配置控制工作负载下不可用副本的数量或比例,例如:
1apiVersion: policy/v1
2kind: PodDisruptionBudget
3metadata:
4 name: zk-pdb
5spec:
6 maxUnavailable: 1
7 selector:
8 matchLabels:
9 app: zookeeper- 驱逐属于高危操作,请注意节点亲和性、污点相关配置,以及 Pod 本身对节点的要求选择,防止出现驱逐后无节点可调度情况;
- 除以上限制条件外,默认全部 Pod 都可以被驱逐;
安装组件
依赖部署
CCE-Descheduler 组件依赖于 Node 当前和过去一段时间的真实负载情况来进行调度决策,需要通过 Prometheus 等监控组件获取系统 Node 真实负载信息。在使用 CCE-Descheduler 组件之前,您可以采用 百度云托管 Prometheus 或自建 Prometheus 监控。
使用百度云托管 Prometheus
使用百度云托管 Prometheus 作为监控数据源的情况下,需要开通 创建 Prometheus 实例、关联 CCE 集群、指标汇聚规则。相关操作可参考:
在完成托管 Prometheus 实例创建、关联 CCE 集群后,托管 Prometheus 会自动完成 “指标采集任务” 的配置,主要包含了对集群控制面组件(如 kube-apiserver、kube-scheduler 等)的监控,也包含了 Descheduler 依赖的对于 cAdvisor 和 NodeExporter 指标的采集。所以用户无需自行配置指标采集任务。
在配置指标汇聚规则阶段,用户要添加如下规则:
1spec:
2 groups:
3 - name: machine_cpu_mem_usage_active
4 interval: 30s
5 rules:
6 - record: machine_memory_usage_active
7 expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
8 - name: machine_memory_usage_1m
9 interval: 1m
10 rules:
11 - record: machine_memory_usage_5m
12 expr: 'avg_over_time(machine_memory_usage_active[5m])'
13 - name: machine_cpu_usage_1m
14 interval: 1m
15 rules:
16 - record: machine_cpu_usage_5m
17 expr: >-
18 100 - (avg by (instance, clusterID)
19 (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
20 - name: container_cpu_usage_10m
21 interval: 1m
22 rules:
23 - record: container_cpu_usage_total_5m
24 expr: >-
25 sum by(namespace, pod,
26 clusterID)(rate(container_cpu_usage_seconds_total{pod!='',image=''}[5m]))
27 * 1000
28 - name: container_memory_working_set_bytes_pod
29 interval: 1m
30 rules:
31 - record: container_memory_working_set_bytes_by_pod
32 expr: 'container_memory_working_set_bytes{pod!='''',image=''''}'该规则实现了对 CCE-Descheduler 依赖的 machine_cpu_usage_5m、machine_memory_usage_5m、container_cpu_usage_total_5m、 container_memory_working_set_bytes_by_pod 等指标的自动汇聚计算。
使用自建 Prometheus
使用自建 Prometheus 作为监控数据源的情况下,用户需要自行部署两个组件:
可以参考组件官方文档完成组件的部署。
在完成组件部署后,用户需要在 Prometheus 添加对 cAdvisor 和 NodeExporter 的监控指标采任务以及指标聚合规则的配置,具体配置可参考:
1scrape_configs:
2 - job_name: "kubernetes-cadvisor"
3 # Default to scraping over https. If required, just disable this or change to
4 # `http`.
5 scheme: https
6
7 # Starting Kubernetes 1.7.3 the cAdvisor metrics are under /metrics/cadvisor.
8 # Kubernetes CIS Benchmark recommends against enabling the insecure HTTP
9 # servers of Kubernetes, therefore the cAdvisor metrics on the secure handler
10 # are used.
11 metrics_path: /metrics/cadvisor
12
13 # This TLS & authorization config is used to connect to the actual scrape
14 # endpoints for cluster components. This is separate to discovery auth
15 # configuration because discovery & scraping are two separate concerns in
16 # Prometheus. The discovery auth config is automatic if Prometheus runs inside
17 # the cluster. Otherwise, more config options have to be provided within the
18 # <kubernetes_sd_config>.
19 tls_config:
20 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
21 # If your node certificates are self-signed or use a different CA to the
22 # master CA, then disable certificate verification below. Note that
23 # certificate verification is an integral part of a secure infrastructure
24 # so this should only be disabled in a controlled environment. You can
25 # disable certificate verification by uncommenting the line below.
26 #
27 insecure_skip_verify: true
28 authorization:
29 credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
30
31 kubernetes_sd_configs:
32 - role: node
33
34 relabel_configs:
35 - action: labelmap
36 regex: __meta_kubernetes_node_label_(.+)
37
38 - job_name: 'node-exporter'
39 kubernetes_sd_configs:
40 - role: pod
41 relabel_configs:
42 - source_labels: [__meta_kubernetes_pod_name]
43 regex: 'node-exporter-(.+)'
44 action: keep在使用自建 Prometheus 的情况下,配置指标聚合规则和使用托管集群类似,区别在于规则中不需要考虑 clusterID 维度,该维度由托管 Prometheus 添加。所以聚合规则可参考:
1spec:
2 groups:
3 - name: machine_cpu_mem_usage_active
4 interval: 30s
5 rules:
6 - record: machine_memory_usage_active
7 expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
8 - name: machine_memory_usage_1m
9 interval: 1m
10 rules:
11 - record: machine_memory_usage_5m
12 expr: 'avg_over_time(machine_memory_usage_active[5m])'
13 - name: machine_cpu_usage_1m
14 interval: 1m
15 rules:
16 - record: machine_cpu_usage_5m
17 expr: >-
18 100 - (avg by (instance)
19 (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
20 - name: container_cpu_usage_10m
21 interval: 1m
22 rules:
23 - record: container_cpu_usage_total_5m
24 expr: >-
25 sum by(namespace, pod)(rate(container_cpu_usage_seconds_total{pod!='',image=''}[5m])) * 1000
26 - name: container_memory_working_set_bytes_pod
27 interval: 1m
28 rules:
29 - record: container_memory_working_set_bytes_by_pod
30 expr: 'container_memory_working_set_bytes{pod!='''',image=''''}'安装 CCE-Descheduler
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品导览>容器>容器引擎”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的“集群管理>集群列表”。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击“运维与管理>组件管理”。
- 在组件管理列表中选择 CCE Descheduler 组件单击“安装”。
- 在组件配置页面中完成数据源选择及重调度策略配置,点击“确定”按钮完成组件的安装。
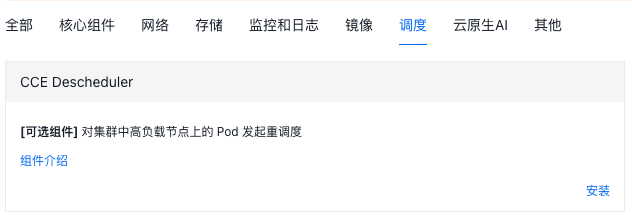
用户可以根据需求,选择 托管 Prometheus 或 自建 Prometheus 作为数据源。 当选择托管 Promehteus 时,用户可以在下拉框选择集群所关联的 Prometheus 实例:
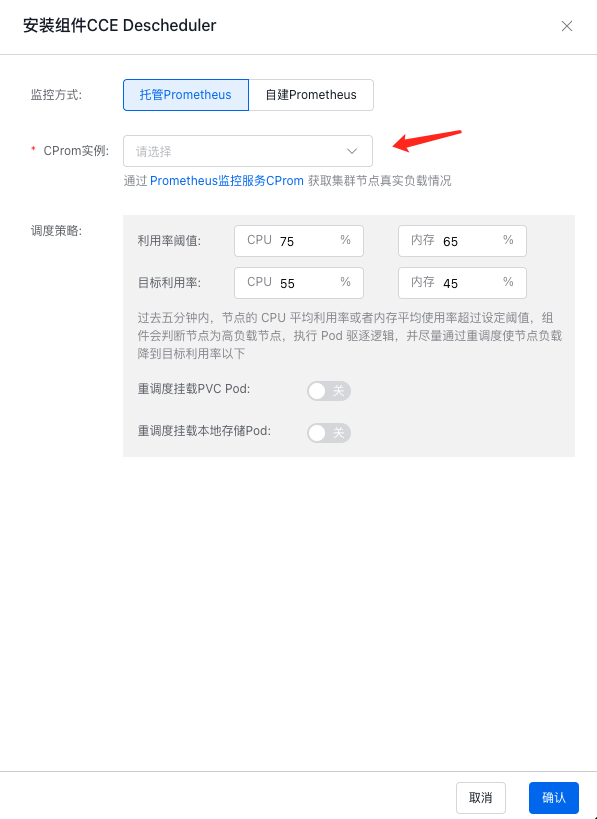
当选择自建 Prometheus 时,用户需要手动输入在集群内可访问的地址:
-
其他参数包括:
- 利用率阈值:当节点的 CPU 或 内存 利用率达到该阈值时,将发起对节点上 Pod 的驱逐;
- 目标利用率:当发起对节点上 Pod 驱逐后,当达到目标利用率后,停止对 Pod 的驱逐;
- 重调度挂载 PVC Pod:默认不会对挂载 PVC 的 Pod 发起驱逐
- 重调度挂载本地存储的 Pod:默认不会对挂载本地存储的 Pod 发起驱逐
- 完成参数配置后,点击 “确认”,即可完成组件安装。
版本记录
| 版本号 | 适配集群版本 | 更新时间 | 更新内容 | 影响 |
|---|---|---|---|---|
| 0.24.2 | CCE/v1.16+ | 2023.06.21 | 首次上线 | - |
| 0.24.3 | CCE/v1.16+ | 2023.12.15 | 修复内存泄漏问题 | - |