
CCE 集群节点自动伸缩
更新时间:2025-08-21
自动伸缩概述
CCE 的运行基于一组百度智能云服务器组成的集群,集群为用户的容器运行提供必要的基础资源,如CPU、内存和磁盘等。通常集群的规模在创建 CCE 服务的时候由用户定义,在使用 CCE 过程中也可以随时对集群进行扩容或者缩容。但是当用户的服务增长速度超过预期或者出现波动峰值时,集群提供的资源可能会不足以支撑服务所需,导致服务运行变慢。
通过开启 CCE 的自动伸缩功能,集群将在资源不足时自动创建新的节点,当资源富余时自动释放多余的节点,从而保障集群资源始终足以支撑业务负载,同时最大化节约成本。用户在开启自动伸缩功能时,还可以设置扩缩容的最大最小节点数,从而确保扩缩容在预期的范围内进行。
概念解释
| 概念 | 说明 |
|---|---|
| 伸缩组 | 指具有相同配置的节点的集合,基于该组的机器配置进行自动扩容、自动缩容 |
| 伸缩组 min | 伸缩组符合缩容条件时,保证缩容后的伸缩组节点数目不低于该值 |
| 伸缩组 max | 伸缩组符合扩容条件时,保证扩容后的伸缩组节点数目不高于该值 |
| 缩容阈值 | 伸缩组内节点资源(cpu、mem)的请求资源(Request)与资源容量(Capacity)的比值均低于设定阈值时,集群可能会触发自动缩容。 |
| 缩容触发时延 | 在配置的缩容触发时延内,节点资源利用率持续低于缩容阈值,集群可能会触发自动缩容。 |
| 最大并发缩容数 | 该值为整数,表示并发缩容资源利用率为0的节点数目。 |
| 扩容后缩容启动间隔 | 该值为整数,单位分钟,扩容出来的节点经过此间隔后开始评估是否可以被缩容。 |
| 使用本地存储的pod | 缩容时可选择跳过包含本地存储 pod的节点 |
| kube-system命名空间下的pod | 缩容时可选择跳过kube-system命名空间下的非DaemonSet pod的节点 |
| 多伸缩组扩容选择策略 | random:从满足扩容条件的伸缩组中随机选择一个伸缩组。least-waste:在满足pod的需求的同时,选择剩余最少资源的伸缩组。 most-pods:在扩容时选择能够调度最多pod的伸缩组 |
集群操作指导(集群 ID cce-开头)
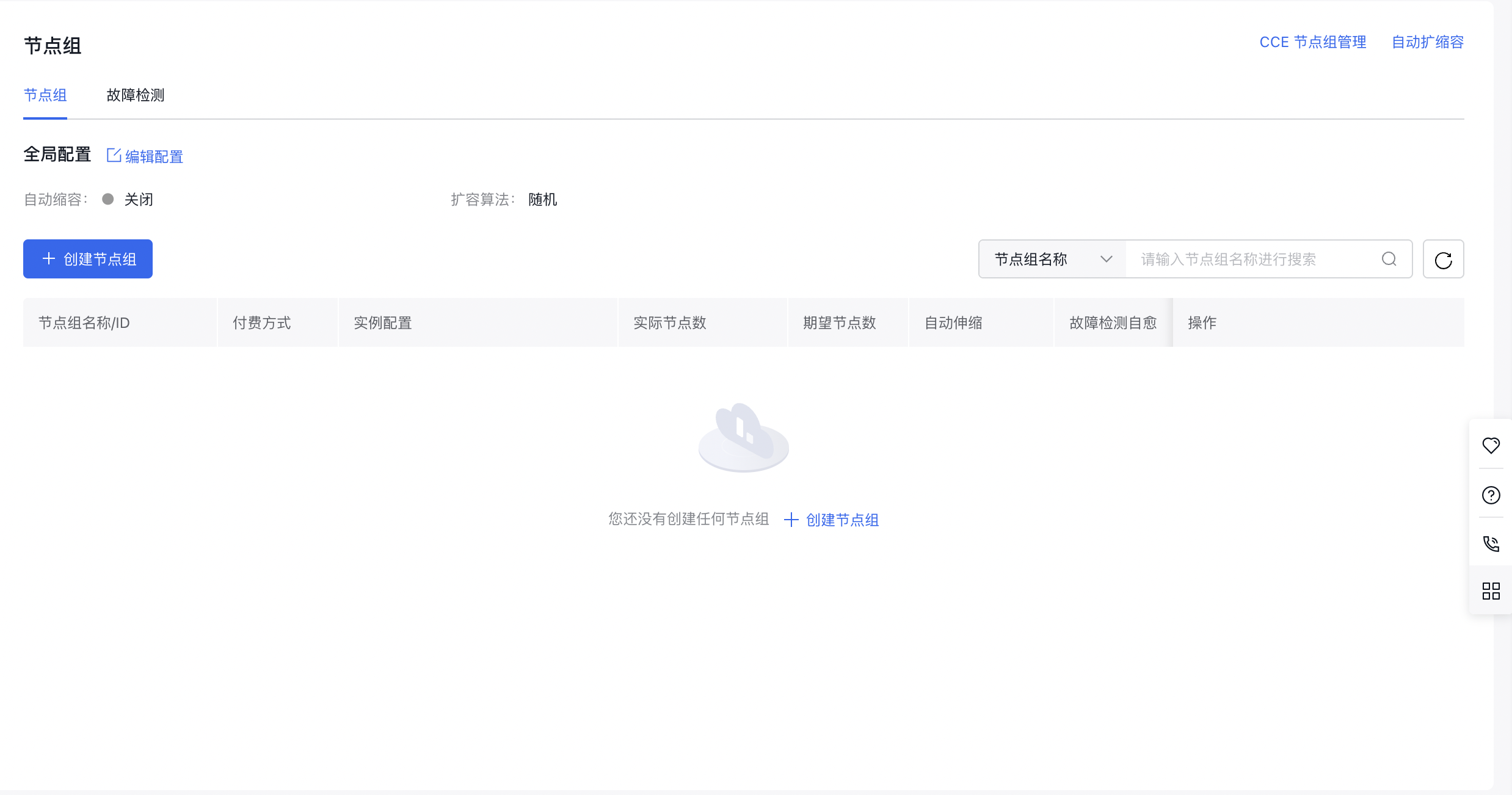
新建节点组
登录百度智能云管理控制台,进入 "产品服务->云原生->容器引擎 CCE",在左侧导航栏,点击 "节点管理->节点组",进入节点组页面,新建节点组。
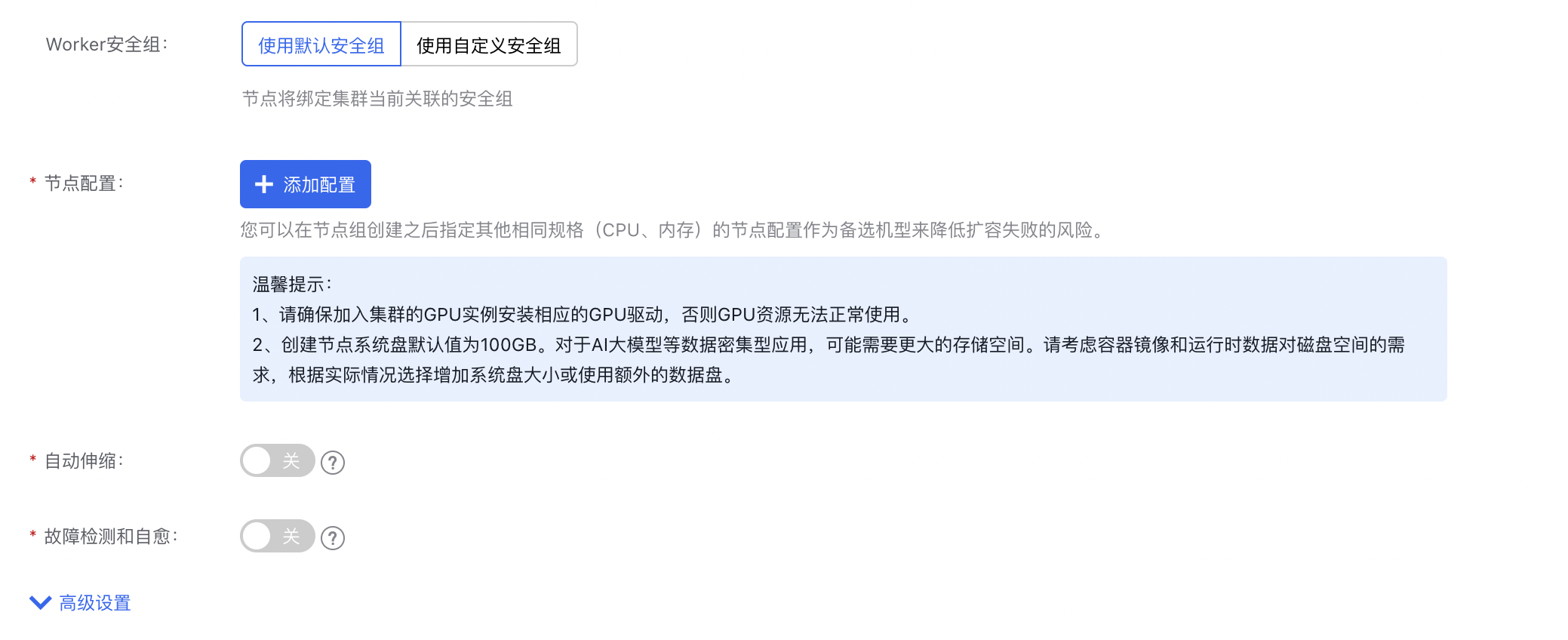
开启自动扩缩容
创建节点组页面中,点击"自动伸容"。
集群操作指导(集群 ID cce-开头)
配置集群的自动伸缩
- 登录百度智能云管理控制台,进入 "产品服务->云原生->容器引擎 CCE",在左侧导航栏,点击 "节点管理->节点组",进入节点组页面进行配置。
- 进入节点组页面。 新集群首次配置,需要在节点组配置中“点击授权”,开通集群自动伸缩功能并进行配置。
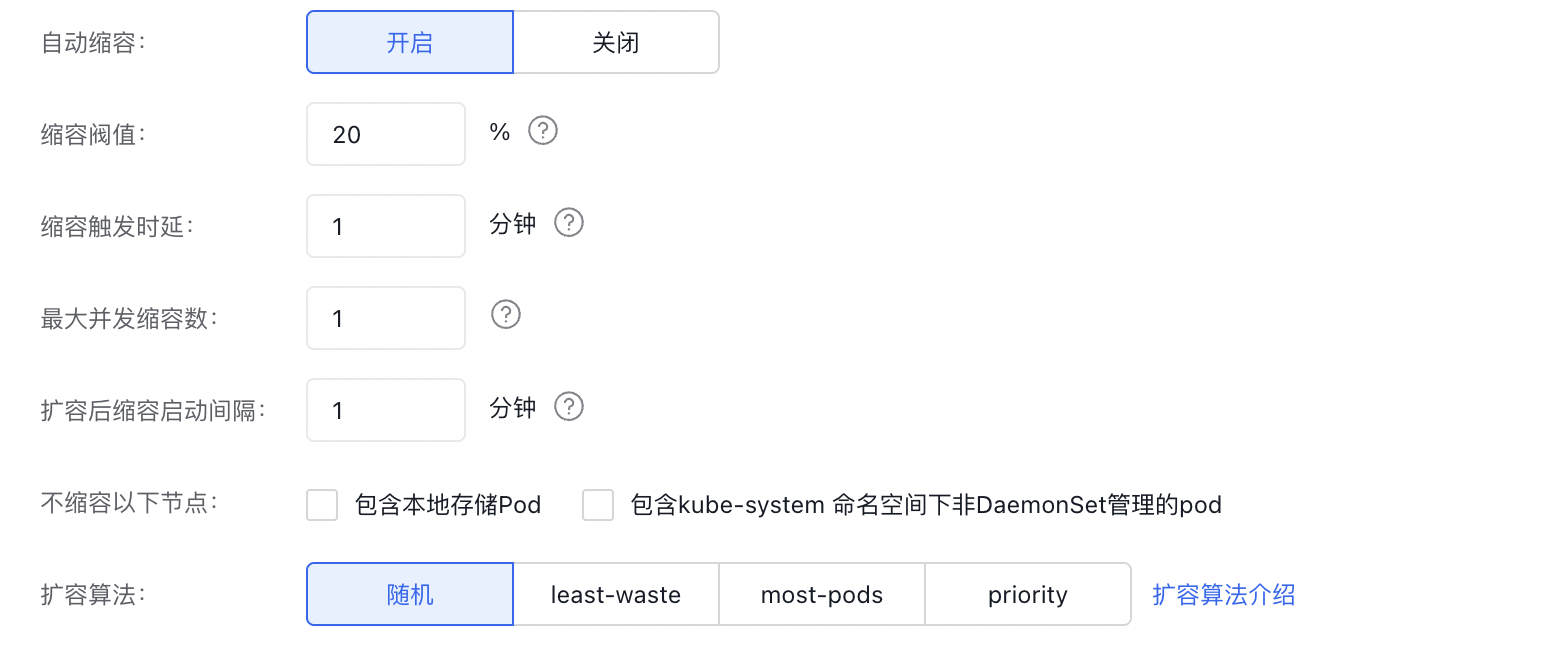
上图中扩容算法各选项说明:
- 随机:当有多个伸缩组可选时,随机选择一个伸缩组进行扩容
- least-waste:当有多个伸缩组可选时,选择部署完 pending pods 后空闲 CPU 最少的伸缩组
- most-pods:当有多个伸缩组可选时,选择能够部署最多 pods 的伸缩组
- priority:当有多个伸缩组可选时,选择优先级最高的伸缩组进行扩容,优先级数值越大越优先
更详情说明可参考:https://github.com/kubernetes/autoscaler/blob/master/cluster-autoscaler/FAQ.md#what-are-expanders
自动缩容常见问题
- 什么情况下触发扩容?
- 集群中存在因为资源(cpu、内存)不足而处于pending的pod
- 伸缩组的节点未达到max值
- 为什么有时候伸缩组内节点无法缩容至0?
- 每次修改配置,伸缩组件都会删除、重启,伸缩组组件被调度到伸缩组内的节点时,伸缩组内的该节点不会被缩容。(见问题5)
- 为什么刚扩容出来的机器满足条件不会被缩容?
- 刚扩容出的机器会有10分钟的保护时间,过了十分钟后,才会考虑缩容。
- 为什么修改配置后没有立刻生效?
- 修改配置(组配置、缩容配置)后伸缩组件会重启,伸缩组内已经存在的节点会被标识成刚扩容出来的节点,重新等待10分钟(时间可调节)后,节点才会匹配缩容条件。
- 为什么符合缩容阈值与缩容时间机器没有被缩容?
- 首先判断组内的节点数是否达到设定的min
- 该机器上的pod是否可以调度到其他节点,不能,该机器也不会被缩容
- 是否设置了该节点为不可缩容("cluster-autoscaler.kubernetes.io/scale-down-disabled": "true")
- 这个节点是否是刚扩容出来的节点(-scale-down-delay-after-add,默认设置10分钟,意思是刚扩容出来的节点10分钟内不会被判定缩容)
- 这个组过去3分钟是否出现过扩容失败(--scale-down-delay-after-failure,该参数可设置)
- 是否设置了--scale-down-delay-after-delete(相邻两次缩容的间隔) 和 --scan-interval(扫描间隔)这两个参数
- 如何在集群内查看伸缩组件的状态
- 查看configMap ->
kubectl get configmap cluster-autoscaler-status -n kube-system -o yaml - 查看自动伸缩log ->
kubectl logs $(kubectl get pods -n kube-system | grep cluster-autoscaler | awk '{print $1}') -n kube-system -f
- 为什么伸缩组件显示的使用率跟我计算的不一样?
- CCE会对机器资源进行一定的保留,伸缩组件计算的CPU核数与内存数是用户可分配的资源数
- 如何调度pod到指定伸缩组?
- 创建伸缩组时指定伸缩组的label,该伸缩组内的所有节点都有该label,可以通过nodeSelector或者node Affinity调度pod
- 如何使用GPU伸缩组?
- 创建GPU类型的伸缩组,在创建pod时指定requests、limits nvidia.com/gpu: 1 ,指定pod需要的GPU卡数。这里卡数只能是整数。
注意事项
- 如果服务无法容忍中断,则不建议使用自动扩缩。因为某些 Pod在缩容时可能在其他节点上重启,可能会导致短暂的中断。
- 不要直接修改属于伸缩组的节点,处于同一个伸缩组的节点应该具有相同的机器配置(cpu、内存..),相同的label,相同的系统pod。
- 判断您的账户支持机器实例数是否在符合设置伸缩组的min/max。
- 创建pod时,指定request字段。
- 限制伸缩组组件的使用MEM与CPU资源,伸缩组件默认需求内存300m,CPU 0.1 Core, 且未设置资源限制。为保护您的机器资源,如果您的集群规模较大可以带入如下公式,计算伸缩组件配额。
MEM = job_num*10KB + pod_num*25KB + 22MB + node_num * 200KB ;CPU = 0.5 Core ~ 1 Core这里计算的是理想状态下最小需求,当集群有大量pod pending、扩容、缩容时可能会额外需求更多CPU、MEM资源。