
逻辑队列和物理队列使用说明
队列功能概述
队列是一个资源池中部分资源的集合,用于工作负载(训练任务、模型服务)的运行。用户可将资源池划分成若干个独立队列(逻辑队列、物理队列)来运行不同工作负载。资源池创建成功后会默认生成 default 队列。本文将介绍如何通过yaml模板创建、更新和使用队列。
前提条件
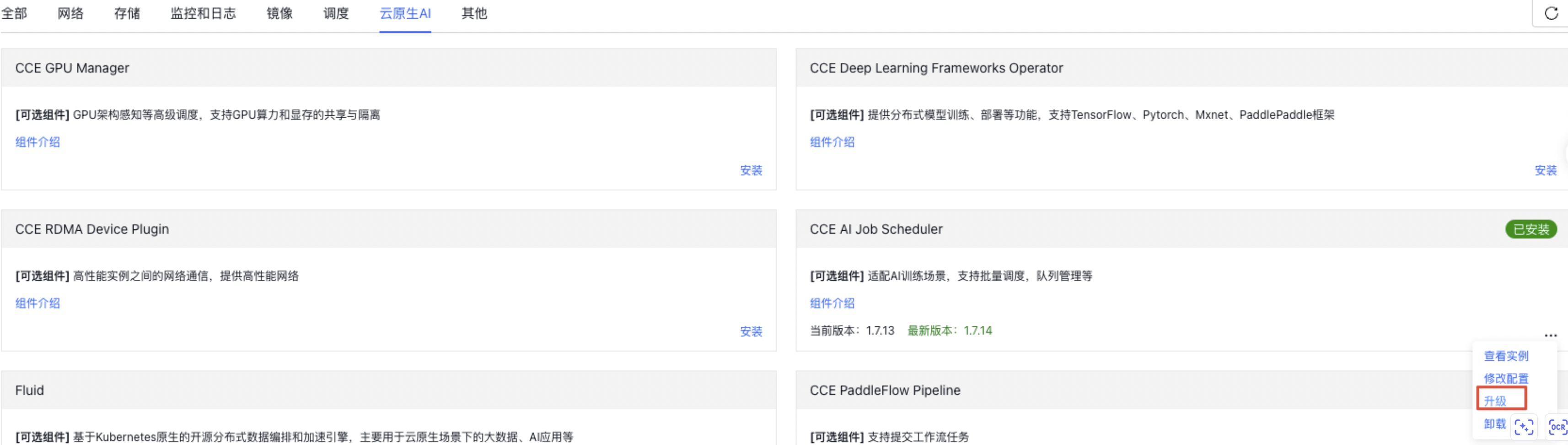
在 CCE 组件管理页面,选择云原生 AI 栏目,CCE AI Job Scheduler 组件版本按照下图升级到最新版本(1.7.14 以上),以使用相关队列功能。
逻辑队列
普通队列
普通队列通常是为不同业务部门分配资源配额最常见的队列形式,是将固定数量的配额资源分配给不同部门使用,实现基础的资源分配能力。
弹性队列
弹性队列是帮助平台型客户更高效为不同业务部门分配资源配额的队列形式。在弹性队列中允许队列闲置配额资源借出给其他队列使用,实现资源出借回收、任务超发抢占等能力,以提高GPU/NPU资源的利用率。具体的任务超发、抢占资源的策略见附录详情。
层级队列
层级队列是面向中大型客户,组织架构复杂,存在多层的资源配额管理场景,提供多层级、多队列资源配额管理能力。
物理队列
通过物理队列对GPU/NPU资源进行物理隔离,支持客户保障重点业务的资源供给,避免资源抢占。同时在物理队列下可以创建多个子逻辑队列。
队列功能说明
配额设置说明
弹性队列需要设置三类配额:预留配额、申请配额、上限配额。将计算资源分成独占型、共享型和抢占型,以更好地优化成本并提高GPU/NPU资源的利用率。
- 预留配额表示单独为该队列预留的资源量,任何情况都不会被其他队列借用。
- 申请配额表示该队列申请的资源量,一般为经过确认的预估使用量。开启队列间抢占功能时,其他队列可使用该队列中空闲的共享型资源。
- 上限配额表示该队列最大的可用资源量。
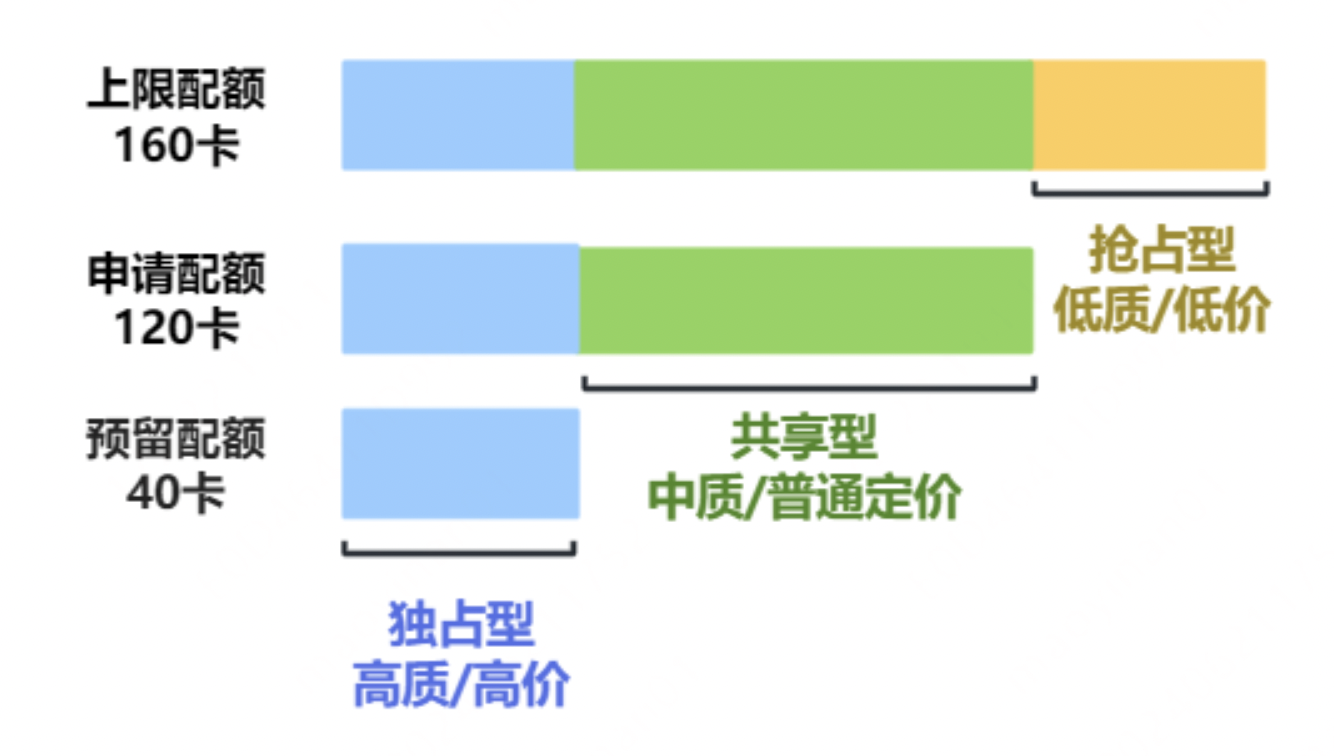
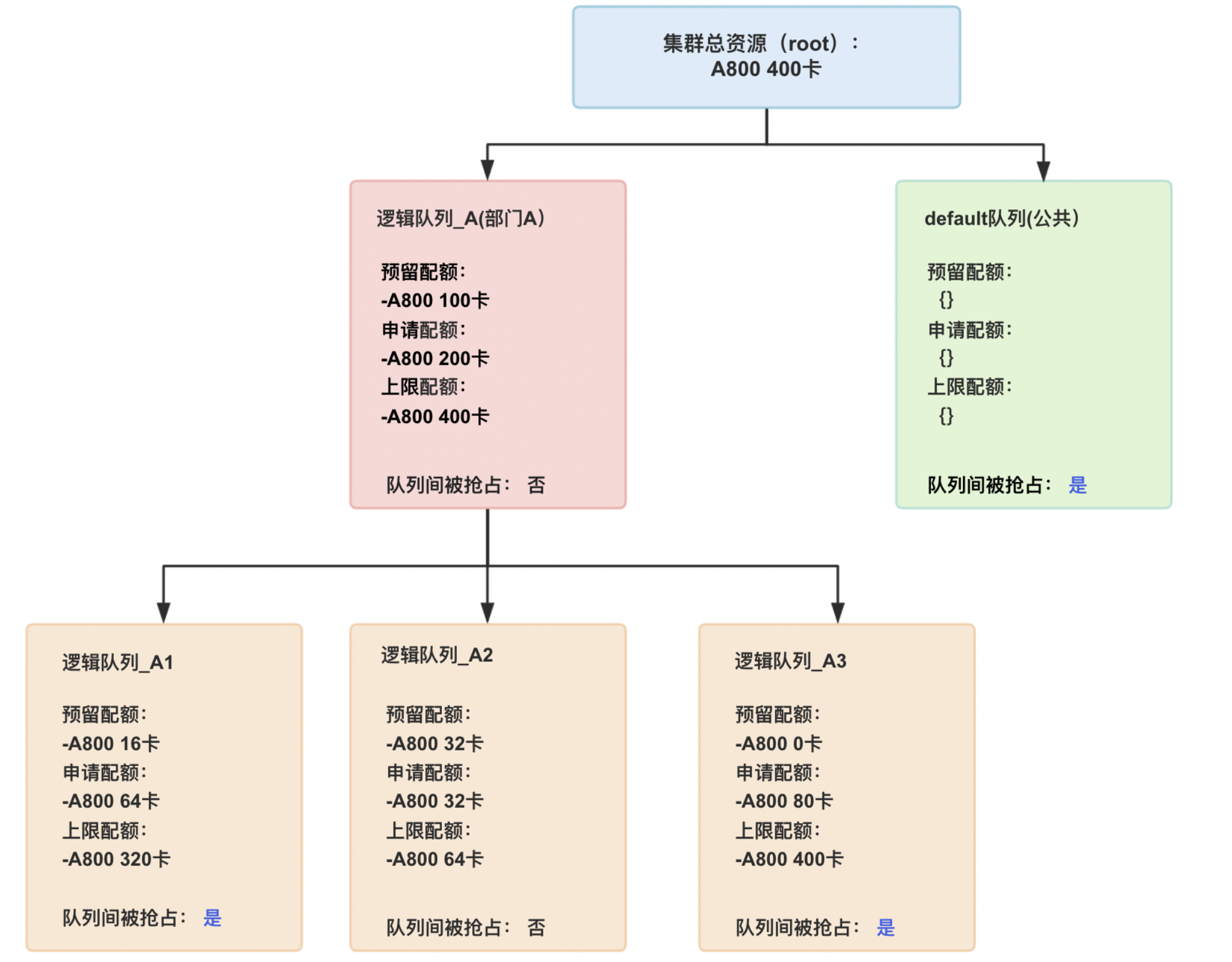
针对以上配额的概念,可参考以下示例便于理解:
队列参数项说明
| 参数 | 参数类型 | 说明 | |
|---|---|---|---|
| name | Metadata | 队列名称,新队列名称不允许为root | |
| labels | Metadata | 该队列所属的父队列名称,创建队列时禁止将 default队列 和 层级队列的第二层队列 配置为父队列 | |
| Guarantee | Spec | 预留资源,表示队列预留的资源量,即使未分配也不会借用,子队列预留资源之和<=父队列预留资源<=集群资源。默认不配置,可使用全集群空闲资源 | |
| Deserved | Spec | 申请资源,表示队列申请的资源量,子队列申请资源之和<=父队列申请资源<=集群资源。默认不配置,可使用全集群空闲资源 | |
| Capability | Spec | 最大可用资源,表示队列可用的最大资源量,子队列上限配额<=父队列上限配额<=集群资源。默认不配置 | |
| Reclaimable | Spec | 是否开启队列间抢占策略,借用的资源是否接受被抢占。默认开启 | |
| State | Status | 队列的状态,默认Open;支持配置Close关闭;队列关闭后,将拒绝新任务提交至队列 | |
| baidu.com/elastic-queue-is-parent | Annotations | 当前队列是否为父队列,默认为否,不支持直接向父队列提交任务,且当队列有任务运行时不允许创建子队列 | |
| baidu.com/elastic-queue-parent | Annotations | 可以指定父队列的名称,默认指向集群根队列 Root,不可指定为default队列、层级队列中的第二级队列以及正在运行任务的队列 |
队列注意事项说明
创建队列
- 系统根队列未初始化,则不允许创建/修改队列
- 不允许创建同名队列
- 未指定父队列,默认将 Root 队列设置为父队列
-
队列配额遵循以下的限制:
- 不允许申请负数配额
- 队列需保障 capability >= deserved >= guarantee 配置
- capability 申请配额不允许大于父队列 capability 配额
- 集群内同一级队列deserved 或 guarantee 之和不允许大于父队列
-
层级队列遵循以下限制:
- 指定父队列不允许不存在
- 指定default 队列为父队列
- 指定第二层队列为父队列
- 不允许向已存在运行任务的队列添加自队列
-
物理队列遵循以下限制:
- capability、deserved 和 guarantee 配置需相同
删除队列
- 层级队列中不允许直接删除父队列,需要先删除子队列后,再删除父队列;
- 有任务正在运行的队列不允许删除。
更新队列
- 物理队列不允许转换为普通队列
- 物理队列下的逻辑队列的物理队列绑定标签,不可修改
- capability 小于 allocated 已分配资源
-
修改父队列后
- capability 申请配额小于子队列 capability 配额
- 父队列小于子队列 deserved 或 guarantee 之和
- 违反了创建队列中的规则
yaml模板操作步骤
逻辑队列使用
创建弹性队列和层级队列
- 准备创建队列 yaml,样例如下
1apiVersion: scheduling.volcano.sh/v1beta1
2kind: Queue
3metadata:
4 name: demo-queue
5 labels:
6 baidu.com/queue-parent: xxxx
7spec:
8 capability:
9 baidu.com/a800_80g_cgpu: "6"
10 guarantee:
11 resource:
12 baidu.com/a800_80g_cgpu: "1"
13 deserved:
14 baidu.com/a800_80g_cgpu: "2"
15 reclaimable: false
16status:
17 allocated:
18 cpu: "0"
19 memory: "0"
20 reservation: {}
21 state: Open- 提交yaml在集群中创建队列
kubectl apply -f demo-queue.yaml
更新逻辑队列
运行如下命令修改配列配置:
kubectl edit queue demo-queue
提交任务到逻辑队列
通过YAML提交任务,验证队列效果。
1apiVersion: "kubeflow.org/v1"
2kind: PyTorchJob
3metadata:
4 name: training-task
5spec:
6 runPolicy:
7 schedulingPolicy:
8 queue: "queue-name" //指定队列
9 priorityClass: "normal"
10 pytorchReplicaSpecs:
11 Worker:
12 replicas: 2
13 template:
14 spec:
15 tolerations:
16 - key: "kwok.x-k8s.io/node"
17 operator: "Equal"
18 value: "fake"
19 effect: "NoSchedule"
20 containers:
21 - name: pytorch
22 image: demo-image:1.0
23 imagePullPolicy: IfNotPresent
24 resources:
25 limits:
26 nvidia.com/gpu: 4
27 schedulerName: volcano| 参数 | 参数类型 | 说明 |
|---|---|---|
| name | Meta | 任务名称 |
| runPolicy.schedulingPolicy.queue | Spec | 向指定的队列提交任务 |
| runPolicy.schedulingPolicy.priorityClass | Spec | 运行任务的优先级,支持高、中、低三种 |
| pytorchReplicaSpecs.Worker.replicas | Spec | 运行任务的副本数 |
物理队列使用
划分节点
将目标节点纳入到物理队列中,建议提前排空相关节点的任务,对于未排空的节点也可直接加入物理队列,但节点GPU资源需要等待任务运行完成后才能释放。
需要注意,物理队列资源申请量需要与加入物理队列的节点资源准确匹配。比如物理队列申请资源 16 卡,可以纳入两台 8 卡节点,多划分会造成资源浪费,少划分可能会导致调度失败。
划分方式分成两步:
- 添加污点:只影响后续新任务的调度,不影响当前正在运行的任务。
kubectl taint nodes targetNode aihc.baidu.com/dedicated-pool=queue-physical-name:NoSchedule
- 添加标签
kubectl label nodes targetNode aihc.baidu.com/dedicated-pool=queue-physical-name
1注意:添加标签和污点时将targetNode换成节点IP即可,多个IP中间用空格隔开。创建物理队列
按照下面yaml模板描述一个物理队列
1apiVersion: scheduling.volcano.sh/v1beta1
2kind: Queue
3metadata:
4 labels:
5 baidu.com/queue-is-physical-queue: "true"
6 name: queue-physical-name
7spec:
8 capability:
9 nvidia.com/gpu: "16"
10 deserved:
11 nvidia.com/gpu: "16"
12 guarantee:
13 resource:
14 nvidia.com/gpu: "16"
15 reclaimable: false
16 weight: 11注意:仅需修改name(队列名称)、capability、deserved、guarantee 4个参数值,且配额相关的capability、deserved、guarantee3个值需保持一致,对应物理队列申请的GPU卡数,其他参数保持不变。队列下创建逻辑队列(可选)
如果想对物理队列资源进行进一步划分,可以在物理队列下创建逻辑子队列,但与物理队列不同的是,子队列不再绑定节点,只保证配额。
1apiVersion: scheduling.volcano.sh/v1beta1
2kind: Queue
3metadata:
4 labels:
5 baidu.com/queue-parent: queue-physical-name
6 name: queue-logical-name
7spec:
8 deserved:
9 nvidia.com/gpu: "8"
10 guarantee:{}
11 reclaimable: false
12 weight: 1申请固定配额逻辑队列,可以参考上述例子,设置 deserved 即可,保证所有子队列 deserved 资源之和不大于物理队列的 deserved 值。
1注意,以下两种行为是不合法的:
2* 向有任务运行的物理队列下添加子队列
3* 在物理队列有子队列的情况下,向物理队列提交任务 修改物理队列
(1)修改物理队列配额
使用 kubectl edit queue queue-physical-name 修改物理队列配额,修改配额为纳管新节点后的总配额数
(2)纳入新节点
类似划分节点步骤,给新节点执行下面两个操作
- 添加污点
kubectl taint nodes targetNode aihc.baidu.com/dedicated-pool=queue-physical-name:NoSchedule
- 添加标签
kubectl label nodes targetNode aihc.baidu.com/dedicated-pool=queue-physical-name