
CCE 动态调度插件说明
组件介绍
CCE Dynamic Scheduler 是基于 Kubernetes 原生 Kube-scheduler Extender 机制实现的动态调度器插件,可基于节点 CPU/Memory 真实利用率进行 Pod 动态调度。在容器服务 CCE 集群中安装插件后,该插件利用 scheduler extender 机制向 Kube-Scheduler 注册 Filter、Prioritize 钩子,来干预默认调度器的调度行为,有效避免原生调度器基于 Request 和 Limit 调度机制带来的节点负载不均问题。该组件需要借助于 Prometheus 监控组件及相应的预聚合规则设置才能正常运行。因此,您可以参照本文的 依赖部署 部分进行操作,以免遇到插件不能正常工作的问题。
功能介绍
Kubernetes 自带的调度器 kube-scheduler 的作用是将新出现的 Pod 绑定到某一个最佳的节点。为了实现这一功能,调度器会需要进行一系列的筛选和打分(预选和优选策略),进行一次性的调度。然而,这种调度存在局限:不具备根据 Node 当前和过去一段时间的真实负载情况进行相关调度的决策,因此可能出现调度不合理的情况。 社区版本调度器中提供的节点利用率相关的策略(如 LowNodeUtilization、HighNodeUtilization)是利用 Pod 的 Reqeust 和 Limit 数据,而不是节点的真实利用率,如:集群内部分节点的剩余可调度资源较多(根据节点上运行的 Pod 的 Reqeust 和 Limit 计算出的值),但真实负载却比较高,而另外节点的剩余可调度资源比较少但真实负载却比较低,此时 Kube-scheduler 会优先将 Pod 调度到剩余资源比较多的节点上(根据 LeastRequestedPriority 策略)。
CCE Dynamic Scheduler 新增了 “基于节点真实负载” 的动态调度策略,用户在集群中安装该组件后,组件会根据从 Prometheus 采集的节点指标和用户设置的节点负载阈值对 Pod 实现动态调度。
使用场景
集群资源动态变化:
- 集群节点资源利用率时刻发生改变,需要 CCE Dynamic Scheduler 进行动态调度
限制说明
- 集群版本在 1.18.9 及以上, 仅支持独立集群
- 集群已经通过 Prometheus 实现指标采集
- 如果需要升级 Kubernetes master 版本,master 版本升级会重置 master 上所有组件的配置,从而影响到 Dynamic Scheduler 插件作为 Scheduler Extender 的配置,因此 Dynamic Scheduler 插件需要卸载后再重新安装
安装组件
依赖部署
CCE Dynamic Scheduler 组件依赖于 Node 当前和过去一段时间的真实负载情况来进行动态调度,需通过 Prometheus 等监控组件获取系统 Node 真实负载信息。在使用 CCE Dynamic Scheduler 组件之前,您需要完成 Prometheus 监控配置。
配置 Prometheus 采集规则
- 使用自建 Prometheus 作为监控数据源的情况下,用户需要自行部署两个组件,可参考下面组件官方文档完成部署:
- 在完成组件部署后,用户需要在 Prometheus 添加对 cAdvisor 和 NodeExporter 的监控指标采任务以及指标聚合规则的配置,具体配置可参考:
1crape_configs:
2 - job_name: "kubernetes-cadvisor"
3 # Default to scraping over https. If required, just disable this or change to
4 # `http`.
5 scheme: https
6
7 # Starting Kubernetes 1.7.3 the cAdvisor metrics are under /metrics/cadvisor.
8 # Kubernetes CIS Benchmark recommends against enabling the insecure HTTP
9 # servers of Kubernetes, therefore the cAdvisor metrics on the secure handler
10 # are used.
11 metrics_path: /metrics/cadvisor
12
13 # This TLS & authorization config is used to connect to the actual scrape
14 # endpoints for cluster components. This is separate to discovery auth
15 # configuration because discovery & scraping are two separate concerns in
16 # Prometheus. The discovery auth config is automatic if Prometheus runs inside
17 # the cluster. Otherwise, more config options have to be provided within the
18 # <kubernetes_sd_config>.
19 tls_config:
20 ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
21 # If your node certificates are self-signed or use a different CA to the
22 # master CA, then disable certificate verification below. Note that
23 # certificate verification is an integral part of a secure infrastructure
24 # so this should only be disabled in a controlled environment. You can
25 # disable certificate verification by uncommenting the line below.
26 #
27 insecure_skip_verify: true
28 authorization:
29 credentials_file: /var/run/secrets/kubernetes.io/serviceaccount/token
30
31 kubernetes_sd_configs:
32 - role: node
33
34 relabel_configs:
35 - action: labelmap
36 regex: __meta_kubernetes_node_label_(.+)
37
38 - job_name: 'node-exporter'
39 kubernetes_sd_configs:
40 - role: pod
41 relabel_configs:
42 - source_labels: [__meta_kubernetes_pod_name]
43 regex: 'node-exporter-(.+)'
44 action: keep-
在使用自建 Prometheus 的情况下,配置指标聚合规则和使用托管集群类似,区别在于规则中不需要考虑 clusterID 维度,该维度由托管 Prometheus 添加。因此,聚合规则可参考:
该规则实现了对 CCE Dynamic Scheduler 依赖的 machine_cpu_usage_5m和machine_memory_usage_5m等指标的自动汇聚计算。
1spec:
2 groups:
3 - name: machine_cpu_mem_usage_active
4 interval: 30s
5 rules:
6 - record: machine_memory_usage_active
7 expr: 100*(1-node_memory_MemAvailable_bytes/node_memory_MemTotal_bytes)
8 - name: machine_memory_usage_1m
9 interval: 1m
10 rules:
11 - record: machine_memory_usage_5m
12 expr: 'avg_over_time(machine_memory_usage_active[5m])'
13 - name: machine_cpu_usage_1m
14 interval: 1m
15 rules:
16 - record: machine_cpu_usage_5m
17 expr: >-
18 100 - (avg by (instance)
19 (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)Helm 安装 CCE Dynamic Scheduler
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的 Helm > Helm 模版。
- 在 Helm 模版 页面中,单击 百度智能云模版 进入模版管理页面。
- 在模版管理页面中选择模版名称 cce-dynamic-scheduler,然后单击 安装。
- 在 安装模版 页面中完成相关配置填写,点击 确定 按钮完成组件的安装。
- 登陆 Master Node,配置 Kube-Scheduler 启动项,使组件生效。
操作步骤
- 用户需单击左侧导航栏中的 Helm > Helm 模版, 在 Helm 模版 页面中,单击 百度智能云模版 进入模版管理页面,找到组件 cce-dynamic-scheduler,然后单击 安装,流程如下图:
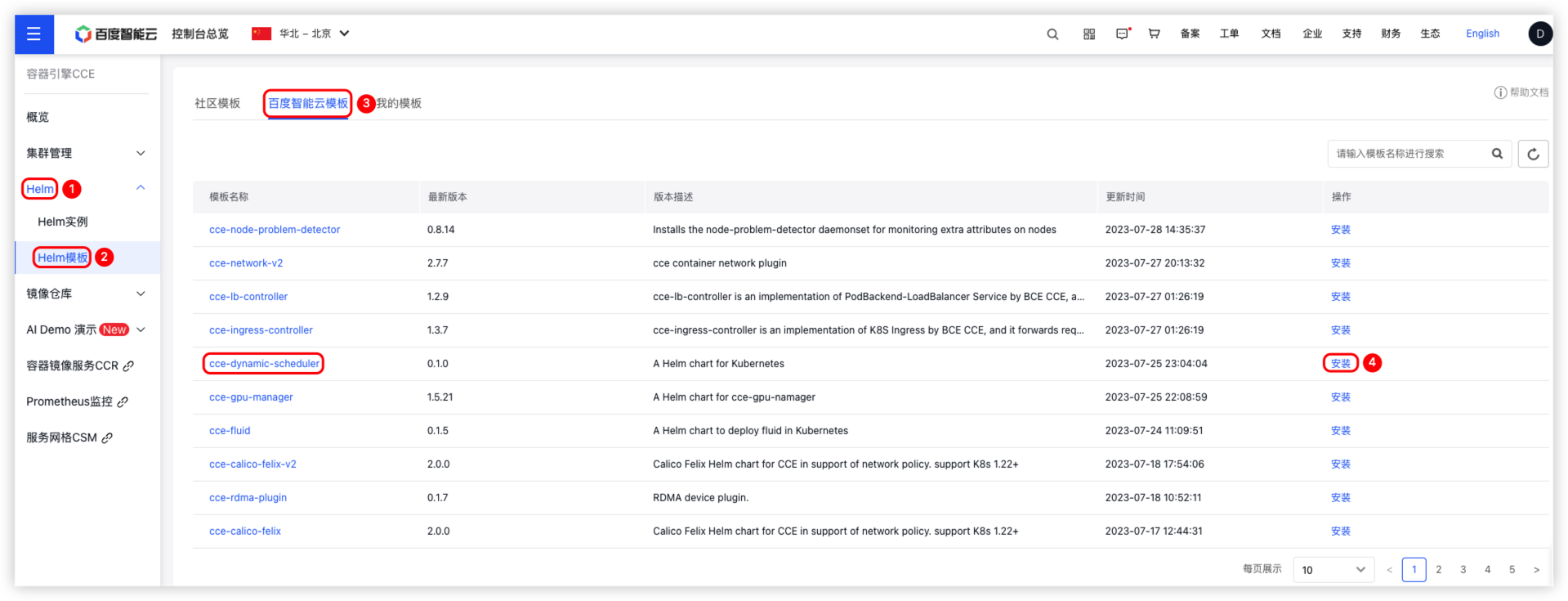
- 在安装模版界面中,需填写【实例名称】、【部署集群】、【命名空间】、【Prometheus 地址】和【cpu/memory 阈值】,单机 确认 完成组件部署。
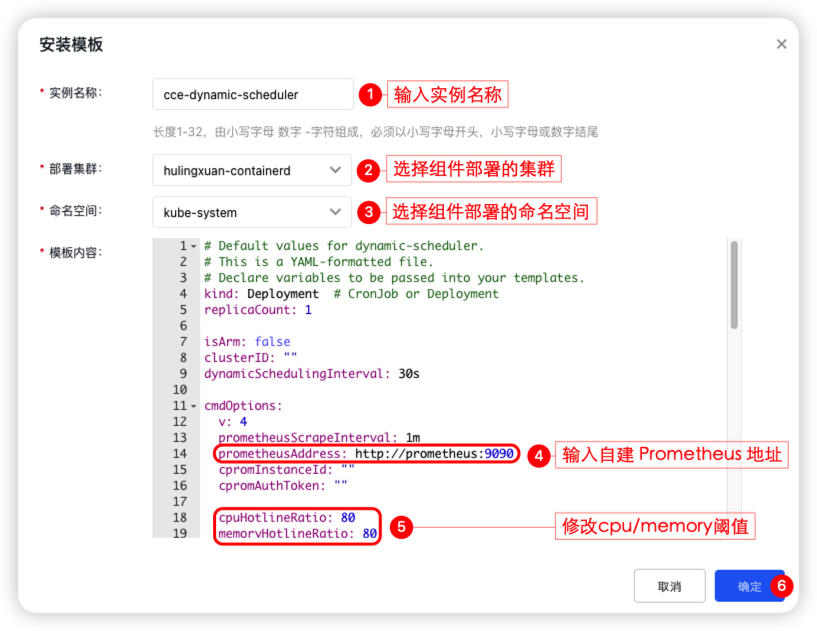
- 登陆 Master Node,配置 Kube-Scheduler 启动项
- 输入命令
cd /etc/kubernetes/ && vim scheduler-extender.yaml,创建scheduler-extender.yaml,scheduler-extender.yaml内容如下:
1apiVersion: kubescheduler.config.k8s.io/v1beta2
2kind: KubeSchedulerConfiguration
3clientConnection:
4 kubeconfig: "/etc/kubernetes/scheduler.conf"
5extenders:
6- urlPrefix: "http://dynamic-scheduler.svc/dynamic/extender" ## 实际 dynamic-scheduler的 svc 地址
7 filterVerb: "filter"
8 prioritizeVerb: "prioritize"
9 weight: 1
10 enableHTTPS: false
11 nodeCacheCapable: true
12 ignorable: true- 输入命令
cd manifests/ && vim kube-scheduler.yaml,修改Kube-Scheduler.yaml的配置文件,添加启动参数- --config=/etc/kubernetes/scheduler-extender.yaml,Kube-Scheduler.yaml内容如下:
1apiVersion: v1
2kind: Pod
3metadata:
4 annotations:
5 scheduler.alpha.kubernetes.io/critical-pod: ""
6 creationTimestamp: null
7 labels:
8 component: kube-scheduler
9 tier: control-plane
10 name: kube-scheduler
11 namespace: kube-system
12spec:
13 containers:
14 - command:
15 ## ...
16 - --config=/etc/kubernetes/scheduler-extender.yaml ## 修改kube-scheduler的配置文件,添加启动参数
17 使用案例
1. 热点规避的真实负载调度策略:
描述:当节点超过安全水位时,新部署的pod不会调度到超过阈值的 node 节点
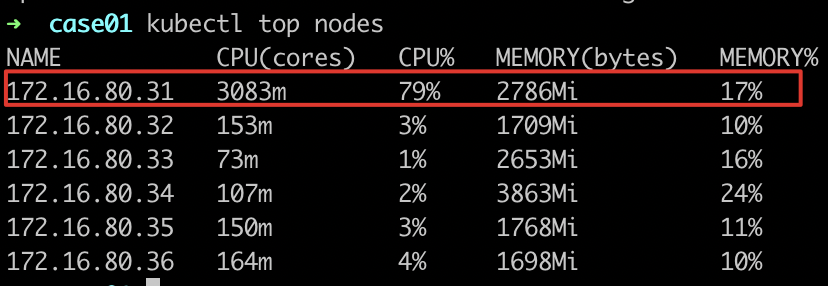
- 观察工作负载所在节点的负载情况
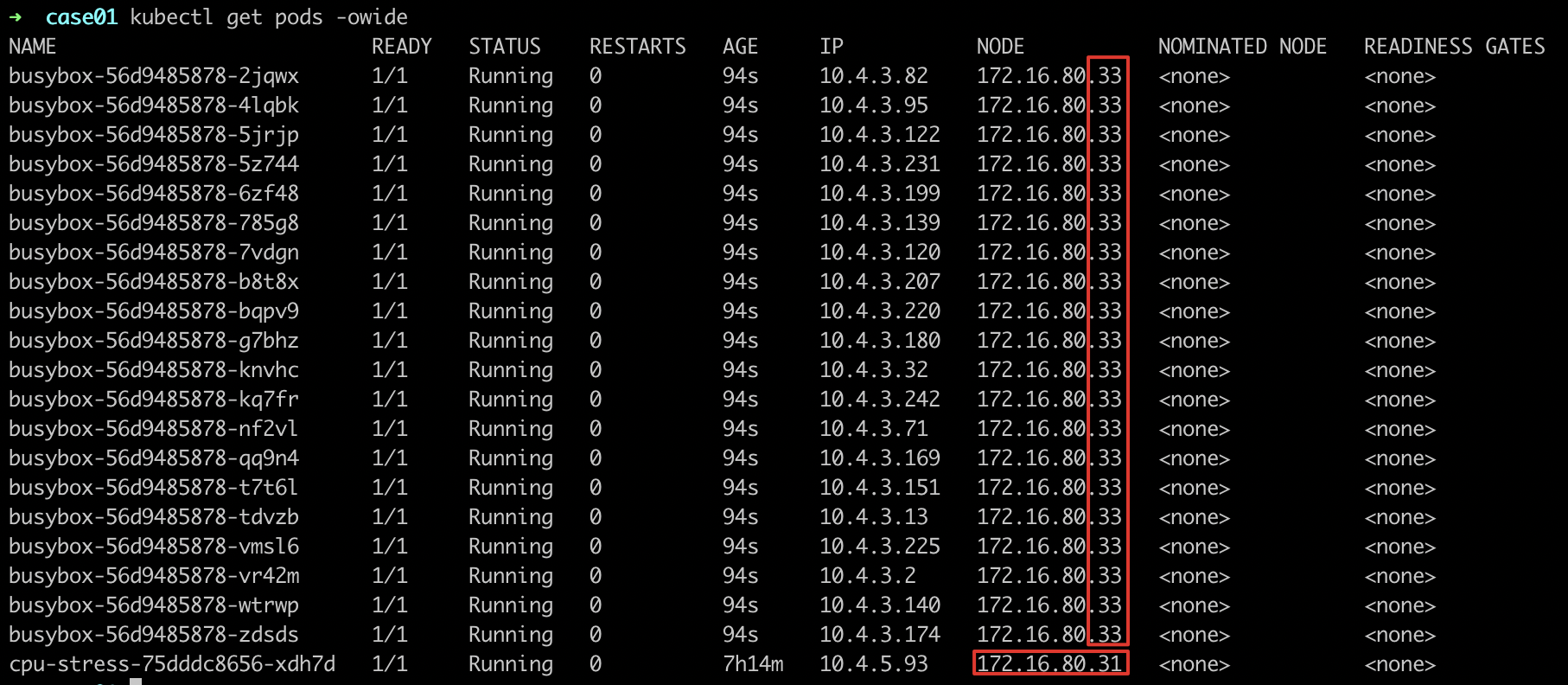
- 部署其他服务进行调度
- 观察服务调度部署情况,发现部署的服务不会调度到
node-172.16.80.31上
- 查看组件日志
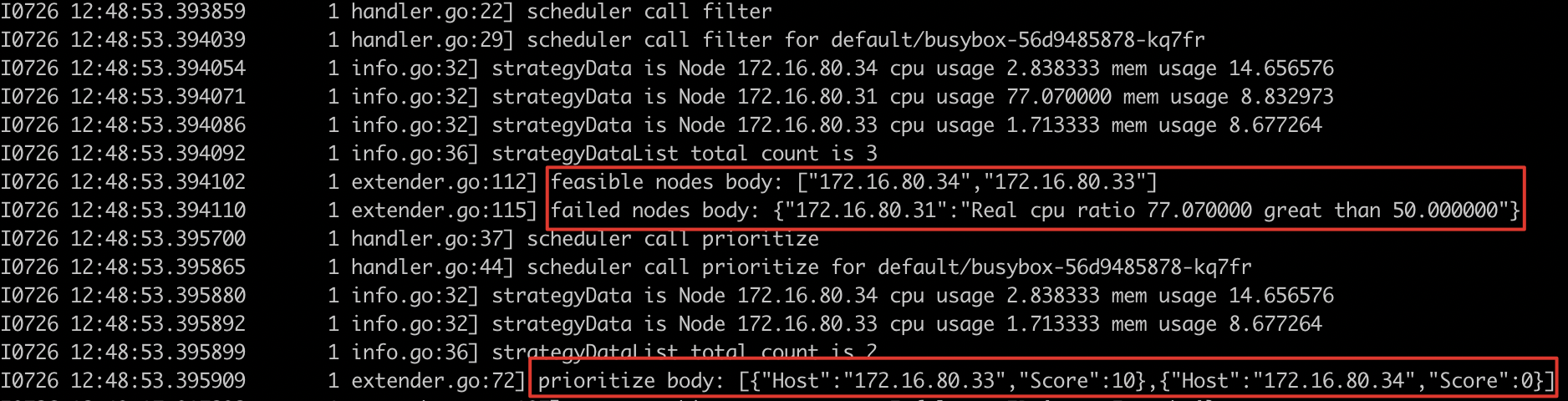
- 预期结果
- 负载超过阈值的 node 不会再部署其他服务,规避真实超过阈值的调度,调度结果符合预期,调度日志符合预期
2. 基于真实负载的调度策略:
描述:当节点超过安全水位时,新部署的pod会按照当前所有节点的真实负载最优的进行调度
- 观察工作负载所在节点的负载情况
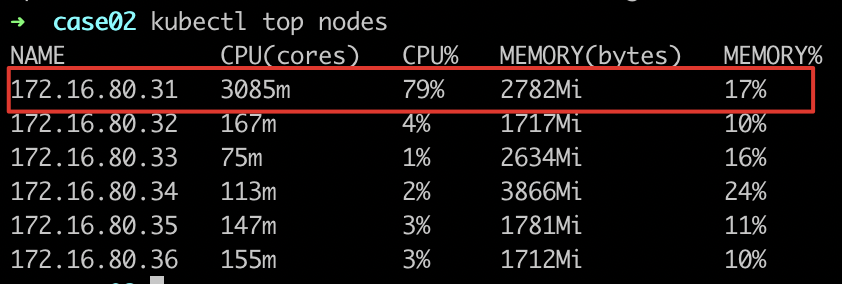
- 部署其他服务进行调度,并观察调度日志,发现node-172.16.80.33真实负载最低,得分最高
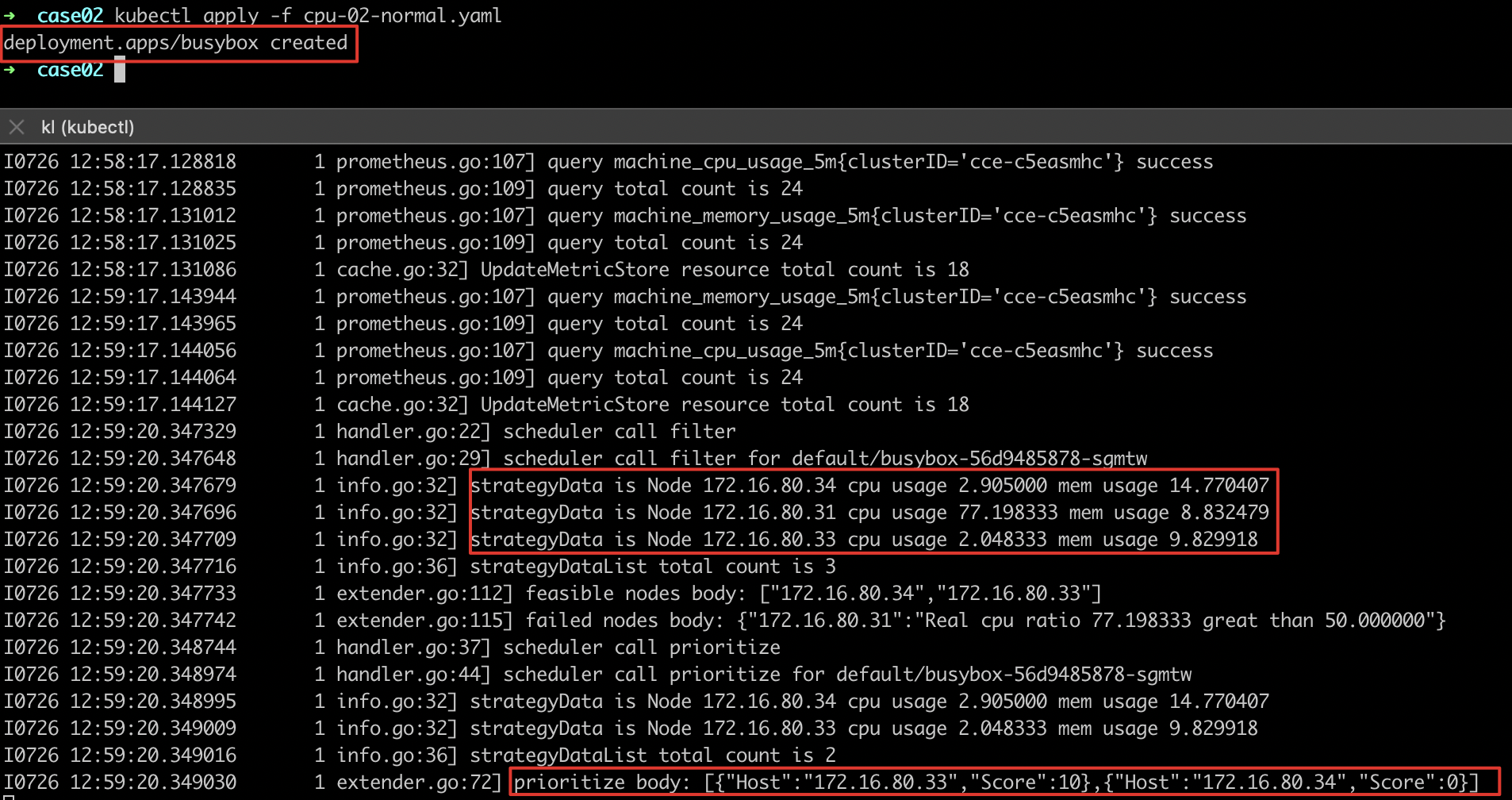
- 观察服务调度部署情况,发现部署的服务调度到负载最低(得分最高)的节点
node-172.16.80.33上

- 预期结果
- 负载超过阈值的node不会再部署其他服务,部署的服务会调度到真实负载最低的node-172.16.80.33上,调度结果符合预期