
CCE AI Job Scheduler 说明
更新时间:2025-08-21
组件介绍
任务调度组件,支持调度管理各种AI任务,结合 CCE Deep Leaning Frameworks Operator,可实现直接在 CCE 上进行深度学习模型训练。
组件功能
- 支持丰富的调度策略和增强型的 Job 管理能力。
- 调度策略支持 spread和binpack两种策略。binpack 表示多个 Pod 会优先集中共享使用同一 GPU 卡,适用于需要提高 GPU 资源利用率的场景,spread 表示多个 Pod 会尽量分散使用不同的 GPU 卡,使用于 GPU 高可用场景。
- 抢占模式支持队列内优先级抢占和队列间超发抢占。队列内优先级抢占指同一队列中,优先级高的任务可抢占优先级低任务的资源,保障高优先级任务的运行;队列间超发抢占是指A队列资源用满B队列有空闲资源时,此时若A队列上提交了新任务,将调度到B队列上运行,当B队列上有新任务提交发现资源不足时,将Kill超发任务保障B队列任务运行。
抢占功能使用可参考队列管理和任务管理中相关说明。
使用场景
您可以直接在 CCE 集群上运行深度学习任务,提高 AI 工程效率。
限制说明
- 仅支持v1.18及以上版本的 Kubernetes 集群。
安装组件
- 登录百度智能云官网,并进入管理控制台。
- 选择“产品服务 > 云原生 > 容器引擎 CCE”,单击进入容器引擎管理控制台。
- 单击左侧导航栏中的 集群管理 > 集群列表 。
- 在集群列表页面中,单击目标集群名称进入集群管理页面。
- 在集群管理页面单击 组件管理 。
- 在组件管理列表中选择 CCE AI Job Scheduler 组件单击“安装。
- 在组件配置页面中完成深度学习框架配置。
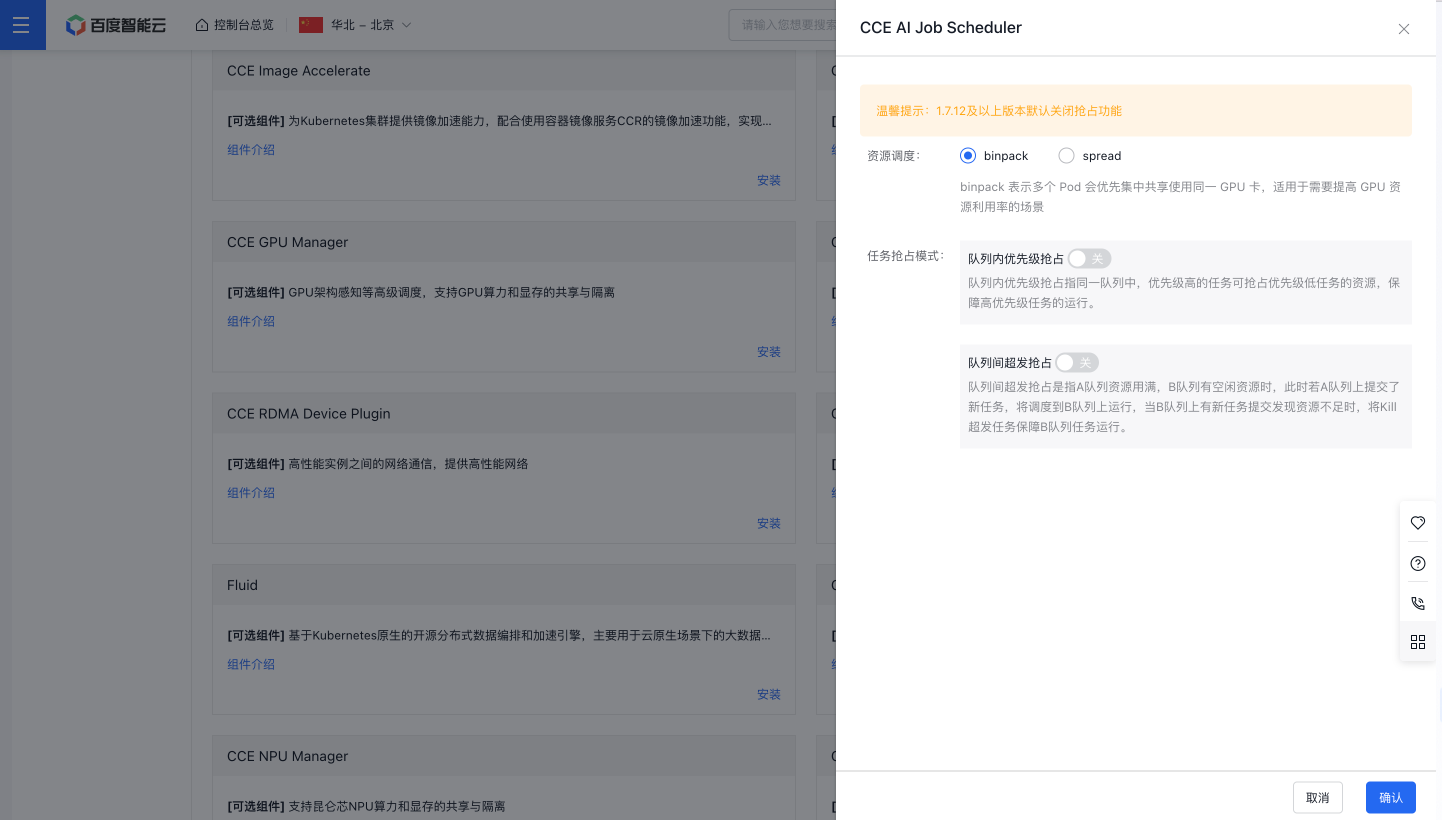
- 调度策略支持 spread 和 binpack 两种,binpack 表示多个 Pod 会优先集中共享使用同一 GPU 卡,适用于需要提高 GPU 资源利用率的场景,spread 表示多个 Pod 会尽量分散使用不同的 GPU 卡,使用于 GPU 高可用场景。
- 抢占模式支持队列内优先级抢占和队列间超发抢占。队列内优先级抢占指同一队列中,优先级高的任务可抢占优先级低任务的资源,保障高优先级任务的运行;队列间超发抢占是指A队列资源用满B队列有空闲资源时,此时若A队列上提交了新任务,将调度到B队列上运行,当B队列上有新任务提交发现资源不足时,将Kill超发任务保障B队列任务运行。
- 点击“确认”按钮完成组件的安装。
版本记录
| 版本号 | 适配集群版本 | 变更时间 | 变更内容 | 影响 |
|---|---|---|---|---|
| 1.7.25 | CCE v1.18+ | 2024.11.07 | 新功能: 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.24 | CCE v1.18+ | 2024.09.30 | 新功能: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.23 | CCE v1.18+ | 2024.09.27 | 新功能: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.22 | CCE v1.18+ | 2024.09.03 | 新功能: 优化: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.21 | CCE v1.18+ | 2024.08.14 | 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.20 | CCE v1.18+ | 2024.07.22 | 新功能: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.19 | CCE v1.18+ | 2024.07.05 | 新功能: 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.18 | CCE v1.18+ | 2024.06.26 | 新功能: 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.17 | CCE v1.18+ | 2024.06.02 | 新功能: 优化: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.16 | CCE v1.18+ | 2024.05.23 | 新功能: 优化: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.15 | CCE v1.18+ | 2024.05.17 | 新功能: 优化: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.14 | CCE v1.18+ | 2024.05.09 | 新功能: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 v1.7.13以下版本请联系百度云协助升级。 |
| 1.7.13 | CCE v1.18+ | 2024.04.15 | 新功能: 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.12 | CCE v1.18+ | 2024.03.28 | 新功能 优化 a. 默认关闭在离线混部功能 b. 默认关闭队列内/队列间抢占功能 c. 默认关闭VPC TOR亲和性调度功能 d. 支持SLA 策略开关,支持特定客户的使用场景 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.11 | CCE v1.18+ | 2024.01.31 | 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.10 | CCE v1.18+ | 2023.12.21 | 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.9 | CCE v1.18+ | 2023.11.28 | 新功能: 优化: 缺陷修复: - 修复调度器重启后,因视图同步延迟造成的视图错误 |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.8 | CCE v1.18+ | 2023.10.30 | 新功能: 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.7 | CCE v1.18+ | 2023.10.11 | 新功能: 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.6 | CCE v1.18+ | 2023.09.22 | 新功能: 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.4 | CCE v1.18+ | 2023.06.14 | 新功能: 优化: 缺陷修复: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.3 | CCE v1.18+ | 2023.05.06 | 新功能: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.2 | CCE v1.18+ | 2023.04.24 | 新功能: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |
| 1.7.0 | CCE v1.18+ | 2023.04.14 | 新功能: |
此次升级不会对业务造成影响。 不支持 1.5.8 以下版本升级至该版本。 |