
Connect spark-sql
1 BMR spark sql
1.1 Spark-tsdb-connector
TSDB and spark sql connection is achieved through org.apache.spark.rdd.RDD (i.e. Resilient Distributed Dataset) and some related interfaces, helping users to query TSDB data through spark.
Jar download address: http://tsdb-bos.gz.bcebos.com/spark-tsdb-connector-all.jar
If it's a local spark cluster, download jar to a local address; and if you use bmr, upload it to bos or use the address bos://iot-tsdb/spark-tsdb-connector-all.jar.
Supporting versions: spark 2.1.0 and jdk 1.7.
1.2 Work Program
1.2.1 Query tsdb's Common Work Program
Main class:
package com.baidu.cloud.bmr.spark;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
public class TsdbSparkSql {
public static void main(String[] args) {
if (args.length != 6) {
System.err.println("usage: spark-submit com.baidu.cloud.bmr.spark.TsdbSparkSql <endpoint> <ak> <sk> "
+ "<metric> <sql> <output>");
System.exit(1);
}
String endpoint = args[0];
String ak = args[1];
String sk = args[2];
String metric = args[3];
String sql = args[4];
String output = args[5];
SparkConf conf = new SparkConf().setAppName("TsdbSparkSql");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
Dataset<Row> dataset = sqlContext.read()
.format("tsdb") // set as a tsdb source
.option("endpoint", endpoint) // endpoint of tsdb instance
.option("access_key", ak) // AK
.option("secret_key", sk) // SK
.option("metric_name", metric) // corresponding metric
.load();
dataset.registerTempTable(metric);
sqlContext.sql(sql).rdd().saveAsTextFile(output); // execute sql and store into output
}
}Dependency:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>2.1.2</version>
</dependency>You need to package the program as a jar file and put it in bos, and you need to use the bos path of the file when configuring the work.
1.2.2 Work Program of More Parameters
Main class:
package com.baidu.cloud.bmr.spark;
import static org.apache.spark.sql.types.DataTypes.DoubleType;
import static org.apache.spark.sql.types.DataTypes.LongType;
import static org.apache.spark.sql.types.DataTypes.StringType;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class TsdbSparkSqlMoreOptions {
public static void main(String[] args) {
if (args.length != 6) {
System.err.println("usage: spark-submit com.baidu.cloud.bmr.spark.TsdbSparkSqlMoreOptions <endpoint> <ak> <sk> "
+ "<metric> <sql> <output>");
System.exit(1);
}
String endpoint = args[0];
String ak = args[1];
String sk = args[2];
String metric = args[3];
String sql = args[4];
String output = args[5];
SparkConf conf = new SparkConf().setAppName("TsdbSparkSqlMoreOptions");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
StructType schema = new StructType(new StructField[] {
new StructField("time", LongType, false, Metadata.empty()), // set time column as long
new StructField("value", DoubleType, false, Metadata.empty()), // set value column as double
new StructField("city", StringType, false, Metadata.empty()) // set city column as string
});
Dataset<Row> dataset = sqlContext.read()
.format("tsdb") // set as a tsdb source
.schema(schema) // set a custom schema
.option("endpoint", endpoint) // endpoint of tsdb instance
.option("access_key", ak) // AK
.option("secret_key", sk) // SK
.option("metric_name", metric) // corresponding metric
.option("field_names", "value") // a column name that belongs to the field in schema, splitting by a comma, such as "field1, field2", indicating two fields, namely, field1 and field2
.option("tag_names", "city") // specify a tag name, splitting by a comma, such as "city, latitude", indicating two tags, namely, city and latitude
.option("split_number", "10") // set the number of split to be close to the split number when splitting the data.
.load();
dataset.registerTempTable(metric);
sqlContext.sql(sql).rdd().saveAsTextFile(output);
}
}Dependency:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>2.1.2</version>
</dependency>1.3 Create bmr spark Cluster
Strongly recommend to read the BMR documentation first when you use BMR.
Select BMR1.1.0 version and select spark 2.1.0.

1.4 Create Work
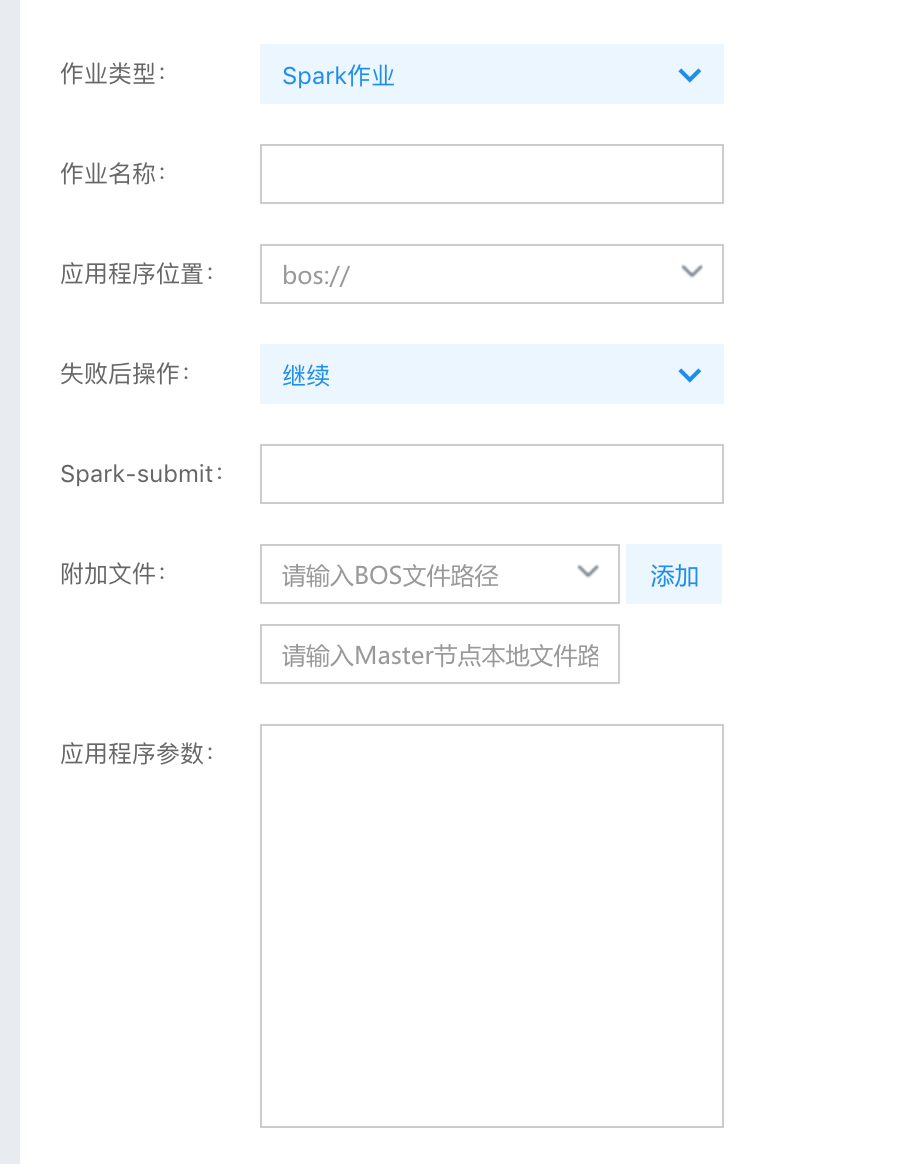
Work configuration is as follows:
Application address: bos://<tsdb-spark-sql-sample>.jar
Spark-submit:--class com.baidu.cloud.bmr.spark.TsdbSparkSql --jars bos://<to>/spark-tsdb-connector-all.jar
Application parameters: <databaseName>.<databaseId>.tsdb.iot.gz.baidubce.com <AK> <SK> <metric> "select count(1) from <metric>" "bos://<to>/output/data"It should be noted that:
- The application configuration is related to the work program in 2.1. Configure it according to your own work program;
- Remember that the last "--jars" parameter cannot be omitted in Spark-submit, and should be designated as the tsdb connector in 1.1.
1.5 Scenario Example
1.5.1 Calculation of Wind Speed
The wind speed data is regularly uploaded by the sensor to tsdb and contains two fields, namely, x and y, representing the wind speed in the direction of x-axis and y-axis. As shown in the following, the total wind speed is calculated by the wind speed in the two vertical directions.
Main class:
package com.baidu.cloud.bmr.spark;
import static org.apache.spark.sql.types.DataTypes.DoubleType;
import static org.apache.spark.sql.types.DataTypes.LongType;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class WindSpeed {
public static void main(String[] args) {
String endpoint = "<endpoint>";
String ak = "<AK>";
String sk = "<SK>";
String metric = "WindSpeed";
String output = "bos://<to>/output/data";
SparkConf conf = new SparkConf().setAppName("TsdbSparkSqlMoreOptions");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
StructType schema = new StructType(new StructField[] {
new StructField("time", LongType, false, Metadata.empty()), // set time column as long
new StructField("x", DoubleType, false, Metadata.empty()), // set x column as double
new StructField("y", DoubleType, false, Metadata.empty()) // set y column as double
});
Dataset<Row> dataset = sqlContext.read()
.format("tsdb") // set as a tsdb source
.schema(schema) // set a custom schema
.option("endpoint", endpoint) // endpoint of tsdb instance
.option("access_key", ak) // AK
.option("secret_key", sk) // SK
.option("metric_name", metric) // corresponding metric
.option("field_names", "x,y") // a column name that belongs to the field in schema
.load();
dataset.registerTempTable(metric);
sqlContext.sql("select time, sqrt(pow(x, 2) + pow(y, 2)) as speed from WindSpeed")
.rdd()
.saveAsTextFile(output);
}
}Dependency:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>2.1.2</version>
</dependency>Raw data:
metric:WindSpeed
| time | field : x | field : y |
|---|---|---|
| 1512086400000 | 3.0 | 4.0 |
| 1512086410000 | 1.0 | 2.0 |
| 1512086420000 | 2.0 | 3.0 |
Result:
The result is output to the specified bos folder, and an example is shown as follows
[1512086400000,5.000]
[1512086410000,2.236]
[1512086420000,3.606]1.5.2 Calculate Time Usage by Vehicle
The vehicle is timed (every 10 seconds) during moving, the data is uploaded to tsdb, and the data contains the speed of the vehicle. Three kinds of time need to be counted:
(1) Stop time: For a period of time the car has reported data, but the reported speed is 0, which indicates that the car is waiting at red lights.
(2) Running time: For a period of time the car has reported data, and the reported speed is greater than 0, which indicates that the car is moving.
(3) Off-line time: For a period of time the car has not reported data, which indicates that the car has stopped and the engine is shut off.
Main class:
package com.baidu.cloud.bmr.spark;
import static org.apache.spark.sql.types.DataTypes.LongType;
import static org.apache.spark.sql.types.DataTypes.StringType;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.types.Metadata;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;
public class VehicleSpeed {
public static void main(String[] args) {
String endpoint = "<endpoint>";
String ak = "<AK>";
String sk = "<SK>";
String metric = "vehicle";
String output = "bos://<to>/output/data";
SparkConf conf = new SparkConf().setAppName("TsdbSparkSqlMoreOptions");
JavaSparkContext sc = new JavaSparkContext(conf);
SQLContext sqlContext = new SQLContext(sc);
StructType schema = new StructType(new StructField[] {
new StructField("time", LongType, false, Metadata.empty()), // set time column as long
new StructField("speed", LongType, false, Metadata.empty()), // set speed column as long
new StructField("carId", StringType, false, Metadata.empty()) // set carId column as string
});
Dataset<Row> dataset = sqlContext.read()
.format("tsdb") // set a tsdb source
.schema(schema) // set a custom schema
.option("endpoint", endpoint) // endpoint of tsdb instance
.option("access_key", ak) // AK
.option("secret_key", sk) // SK
.option("metric_name", metric) // corresponding metric
.option("field_names", "speed") // a column name that belongs to the field in schema
.option("tag_names", "cardId") // specify a tag name
.load();
dataset.registerTempTable(metric);
sqlContext.sql("select floor((time - 1512057600000) / 86400000) + 1 as day, count(*) * 10 as stop_seconds"
+ " from vehicle where carId='123' and time >= 1512057600000 and time < 1514736000000 and speed = 0"
+ " group by floor((time - 1512057600000) / 86400000)")
.rdd()
.saveAsTextFile(output + "/stopSeconds");
sqlContext.sql("select floor((time - 1512057600000) / 86400000) + 1 as day, count(*) * 10 as run_seconds"
+ " from vehicle where carId='123' and time >= 1512057600000 and time < 1514736000000 and speed > 0"
+ " group by floor((time - 1512057600000) / 86400000)")
.rdd()
.saveAsTextFile(output + "/runSeconds");
sqlContext.sql("select floor((time - 1512057600000) / 86400000) + 1 as day, 2678400 - count(*) * 10 as"
+ " offline_seconds from vehicle where carId='123' and time >= 1512057600000 and time < 1514736000000"
+ " group by floor((time - 1512057600000) / 86400000)")
.rdd()
.saveAsTextFile(output + "/offlineSeconds");
}
}Dependency:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>2.1.2</version>
</dependency>Raw data
metric : vehicle
| time | field : speed | tag |
|---|---|---|
| 1512057600000 | 40 | carId=123 |
| 1512057610000 | 60 | carId=123 |
| 1512057620000 | 50 | carId=123 |
| ... ... | ... | carId=123 |
| 1514721600000 | 10 | carId=123 |
Result
The result is output to the specified bos folder, and an example is shown as follows:
[1,3612]
[2,3401]
...
[31,3013]
[1,17976]
[2,17968]
...
[31,17377]
[1,64812]
[2,65031]
...
[31,66010]