014-自然语言处理组件
自然语言处理组件
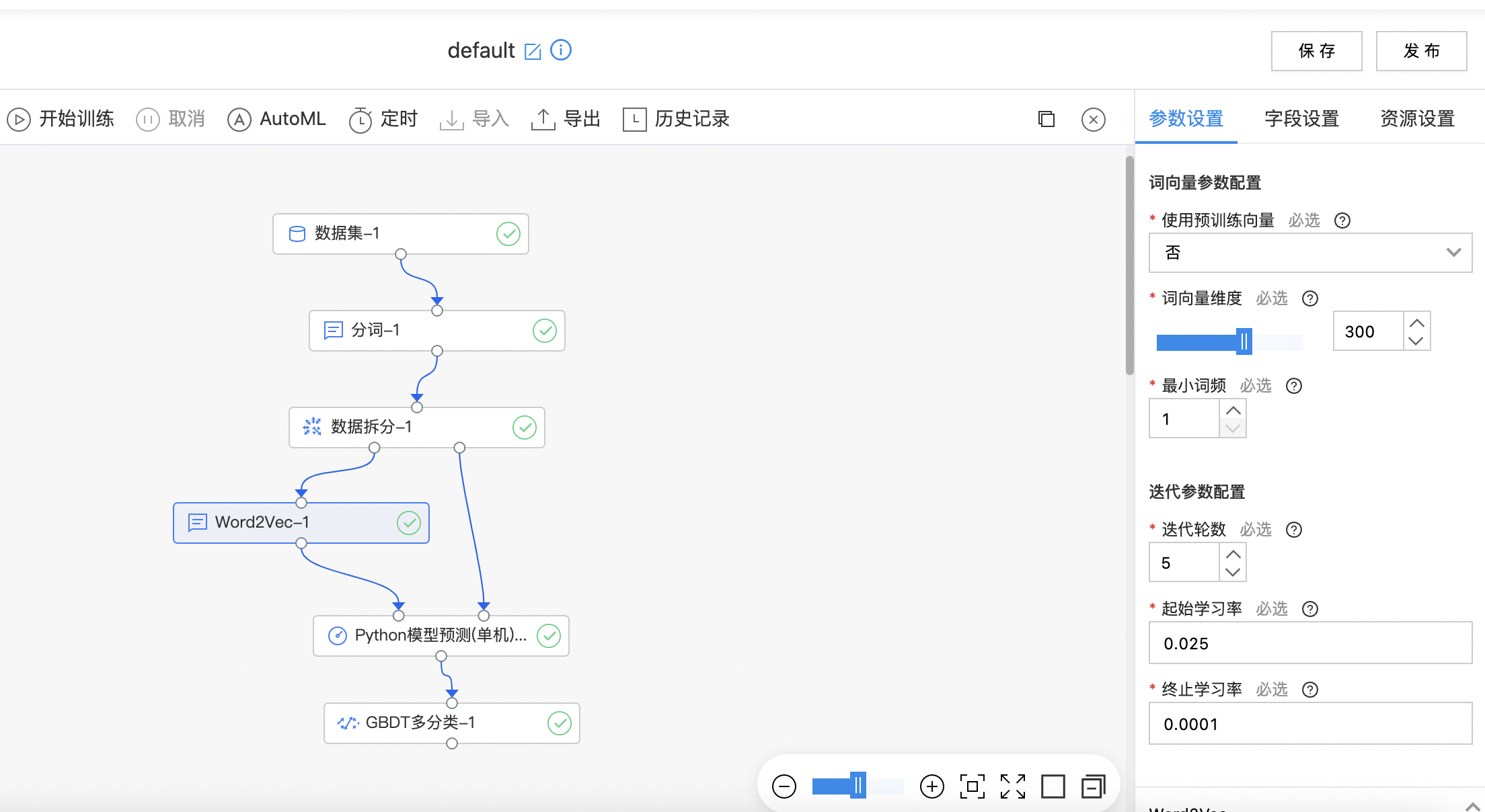
Word2Vec
Word2Vec 是一种经典的词向量算法,能够从大量文本中学习出各个词语的向量表示,其利用神经网络,可以通过训练,将词映射到 K 维度空间向量,甚至对于表示词的向量进行操作还能和语义相对应,由于其简单和高效引起了很多人的关注。
输入
- 输入一个数据集,输入列是分词的结果,用这个数据集训练词向量。
输出
- 输出python模型,可用于将输入的list string列转化成vector列。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 词向量参数配置 | 是 | 是否使用预置的词向量。若开启,词向量维度会设为300,词向量会优先使用预训练词库中的值,预训练词库中没有的词才会训练词向量。 | 否 |
| 词向量维度 | 是 | 训练出的词向量的维度 范围:[5, 500]。 | 300 |
| 最小词频 | 是 | 训练样本中词频小于此值的词不计算词向量 范围:[1, inf)。 | 1 |
| 迭代轮数 | 是 | 算法运行的 epoch 数,迭代几轮训练集 范围:[1, inf)。 | 5 |
| 起始学习率 | 是 | 训练开始时的学习率 范围:[0.00025, 0.1]。 | 0.025 |
| 终止学习率 | 是 | 训练过程中,学习率会线性地下降到终止学习率 范围:[1e-05, 0.001]。 | 0.0001 |
| 训练算法 | 是 | 选择训练算法: CBOW skip-gram |
CBOW |
| softmax优化 | 是 | 计算 softmax 时的优化算法: hierarchical softmax |
negative sampling |
| 负采样词数 | 是 | 负采样选择的词数设置成 0 则不使用负采样。对于小数据集,一般选择 5-20;对于大数据集,一般选择 2-5 个即可 范围:[0, 30]。 | 5 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 输入列 | 是 | 必须是字符串列表类型,分词后的结果。 | 无 |
使用示例
构建算子结构,配置参数,完成训练。
自动摘要
自动摘要是自动将文本转换生成简短摘要的信息压缩技术,要求有足够的信息量、较低的冗余度、较高的可读性。
输入
- 输入文本数据集,用户需要选择要做自动摘要的一列。
- 输入列的类型需要是(文本)字符串。
输出
-
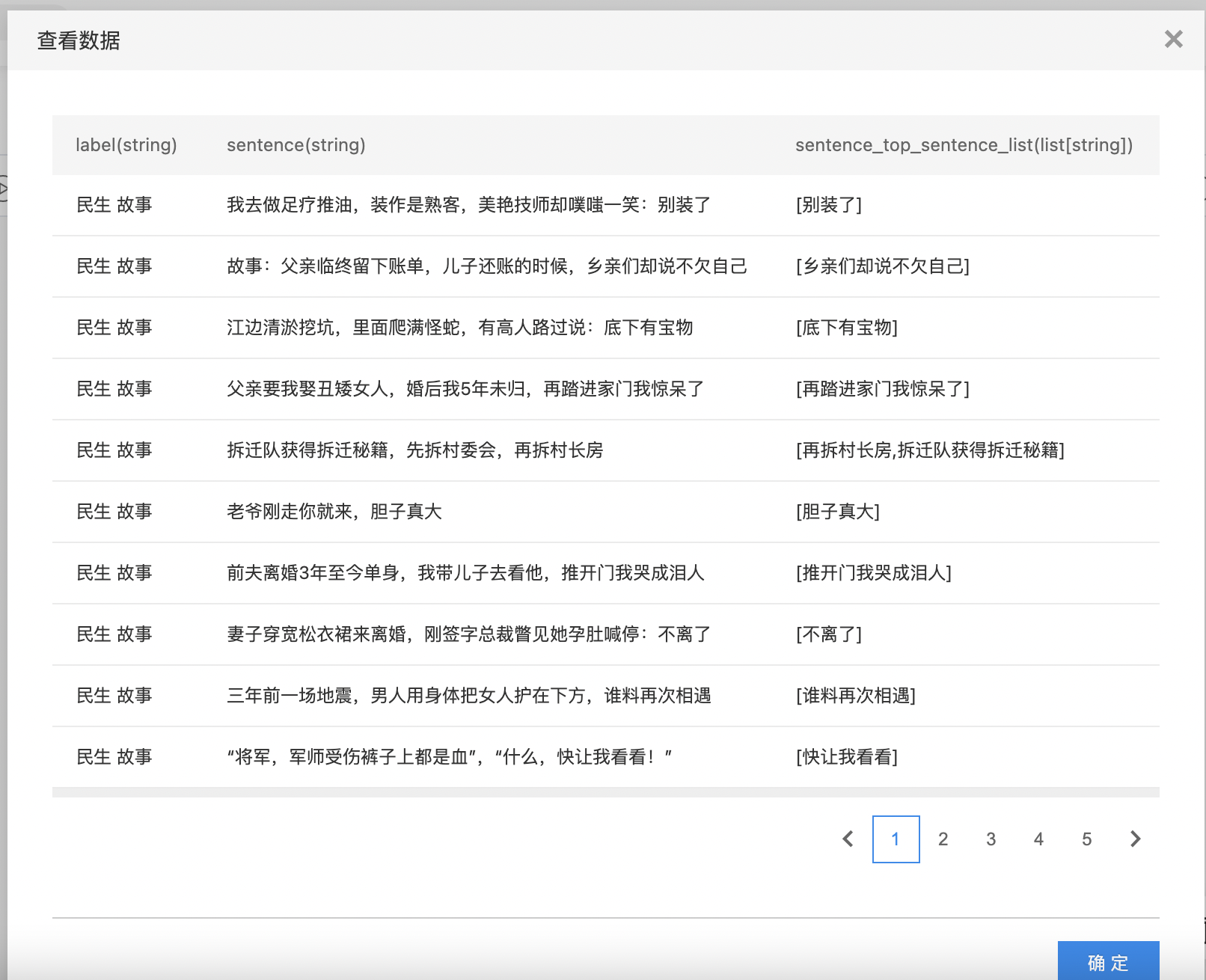
输出自动摘要结果数据集,关键句模式与摘要模式的输出列名不同。
- 关键句模式:在输入数据集的基础上添加了"原始列名top_sentence_list"列,列的类型是字符串数组。
- 摘要模式:在输入数据集的基础上添加了"原始列名_summary"列,列的类型是字符串。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
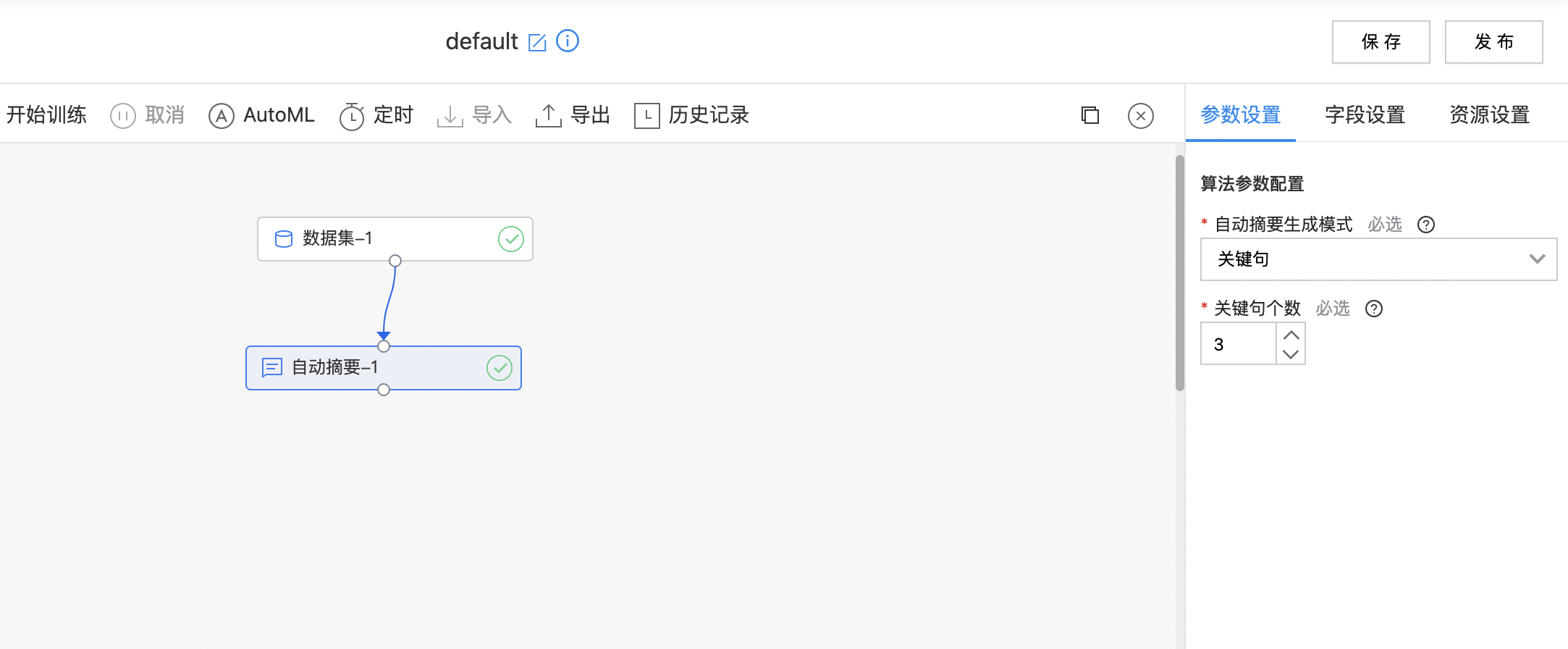
| 自动摘要生成模式 | 是 | 提供两种自动摘要生成模式:关键句、摘要 | 关键句 |
| 关键句个数 | 是 | 需要的关键句的个数。若设置的个数大于生成的关键句列表的总长度,则返回整个关键句列表。 范围:[1, 30] | 3 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 文本列 | 是 | 待处理的文本列,类型为str。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看自动摘要结果。
依存句法分析
句法分析是自然语言处理中的关键技术之一,其基本任务是确定句子的句法结构或者句子中词汇之间的依存关系。主要包括两方面的内容,一是确定语言的语法体系,即对语言中合法的句子的语法结构给与形式化的定义;另一方面是句法分析技术,即根据给定的语法体系,自动推导出句子的句法结构,分析句子所包含的句法单位和这些句法单位之间的关系。 输入
- 输入文本数据集,用户需要选择要做依存句法分析的一列。
- 输入列的类型需要是(文本)字符串类型。
输出
- 输出依存句法分析结果数据集,在输入数据集的基础上添加了"原始列名_parse_dependency"列,列的类型是字符串数组。
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 文本列 | 是 | 待处理的文本列,类型为str。 | 无 |
使用示例
- 构建算子结构,配置参数,完成训练。
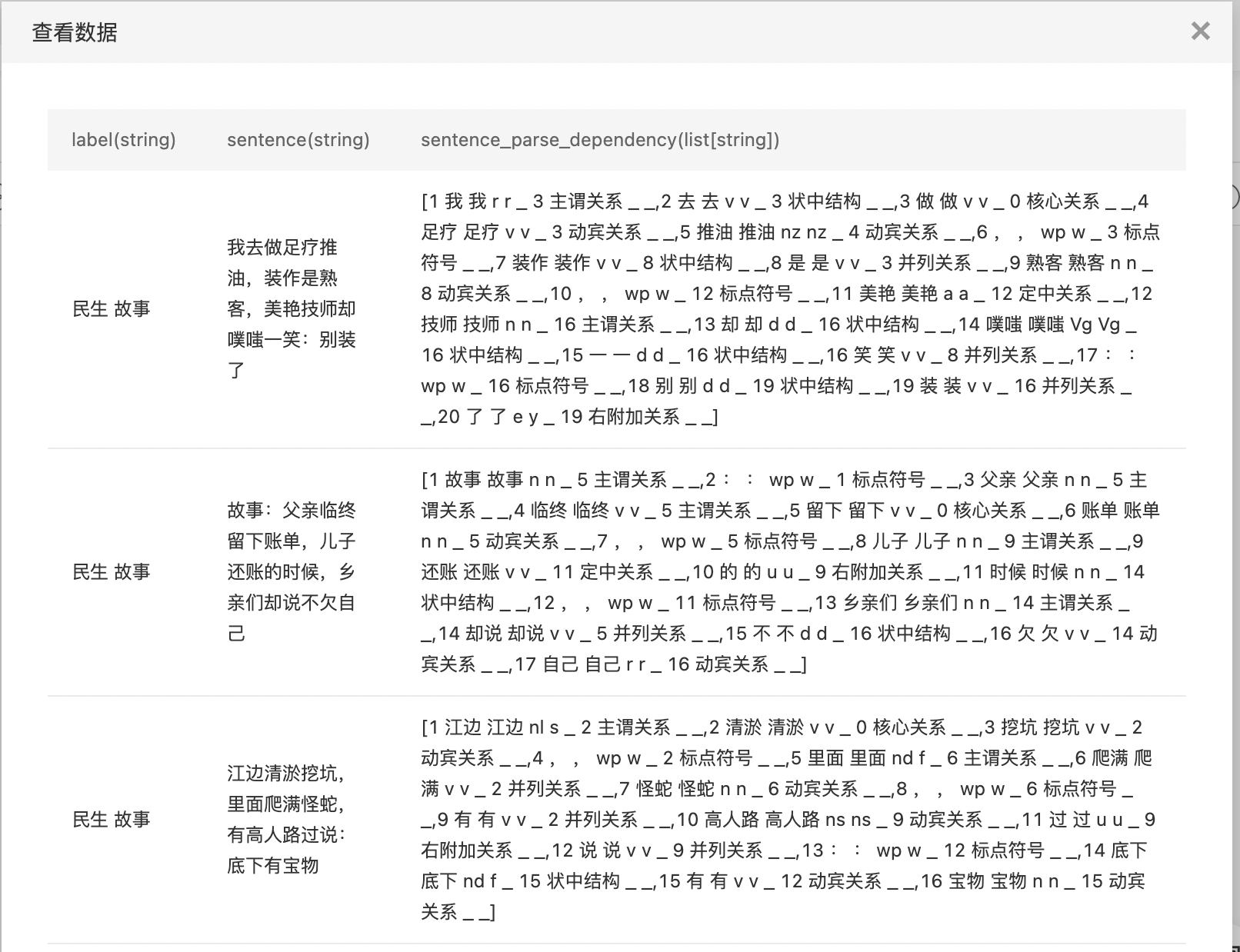
- 查看依存句法分析结果。
分词
分词就是将连续的字序列按照一定的规范重新组合成词序列的过程。组件目前支持两种分词方式:精准分词、新词发现。
输入
- 输入数据集,选择需要进行分词的列。
输出
- 输出数据集新增分词结果列。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 分词器 | 是 | 选择分词器,目前支持精准分词和新词发现。精准分词是比较稳定的分词器,新词发现带有新词发现的功能。 | 精准分词 |
| 人名识别 | 是 | 是否开启人名识别。 | 开启 |
| 数字识别 | 是 | 是否开启数字识别,开启后[五十八]会被分成一个数字。 | 开启 |
| 量词合并 | 是 | 是否把数字和量词合并,开启数字识别后有效,开启后[8号]会被识别成一个词。 | 开启 |
| 词性标注 | 是 | 是否标注词性。 | 关闭 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 输入列 | 是 | 需要分词的列,需要是字符串类型。 | 无 |
| 保留原始列 | 是 | 是否保留原始列。如果保留,则输出结果在原始列名前添加[splitted_]前缀如果不保留,则替换原始列。 | 开启 |
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看分词结果。

TF-IDF
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索和文本挖掘的常用加权技术。 TF-IDF 是一种统计方法,用以评估一个字词对于一个文件集或一份文件对于一个语料库的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。 TF-IDF 加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
输入
- 输入数据集中选一列,list[string]格式的feature(也就是分词或词典过滤的结果)。
输出
- 输出数据集中新增TF-IDF结果列,类型是稀疏向量。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 哈希特征数 | 是 | 对词进行哈希计算时的分桶数。建议要远大于词典长度,以防哈希碰撞 范围:[128, inf) | 1048576 |
| 词语最少出现次数 | 是 | 在不同文档中出现次数少于这个数字的词语在计算IDF时会被忽略 范围:[0, inf) | 0 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 输入列 | 是 | 需要做TF-IDF的列,类型需要是字符串数组 | 无 |
计算逻辑
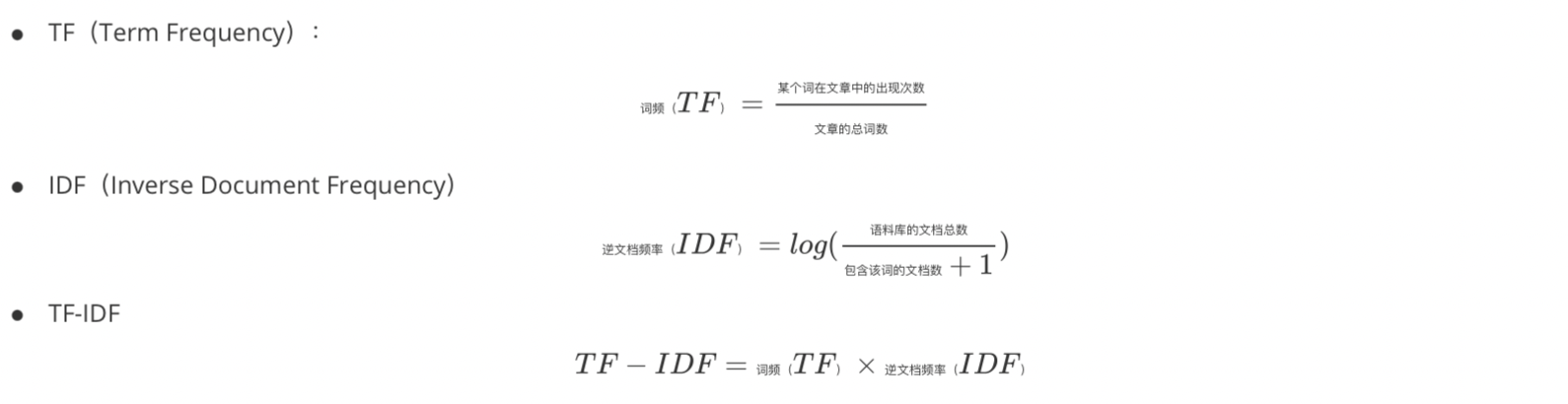
使用示例
- 构建算子结构,配置参数,完成训练。
- 查看TF-IDF处理结果。
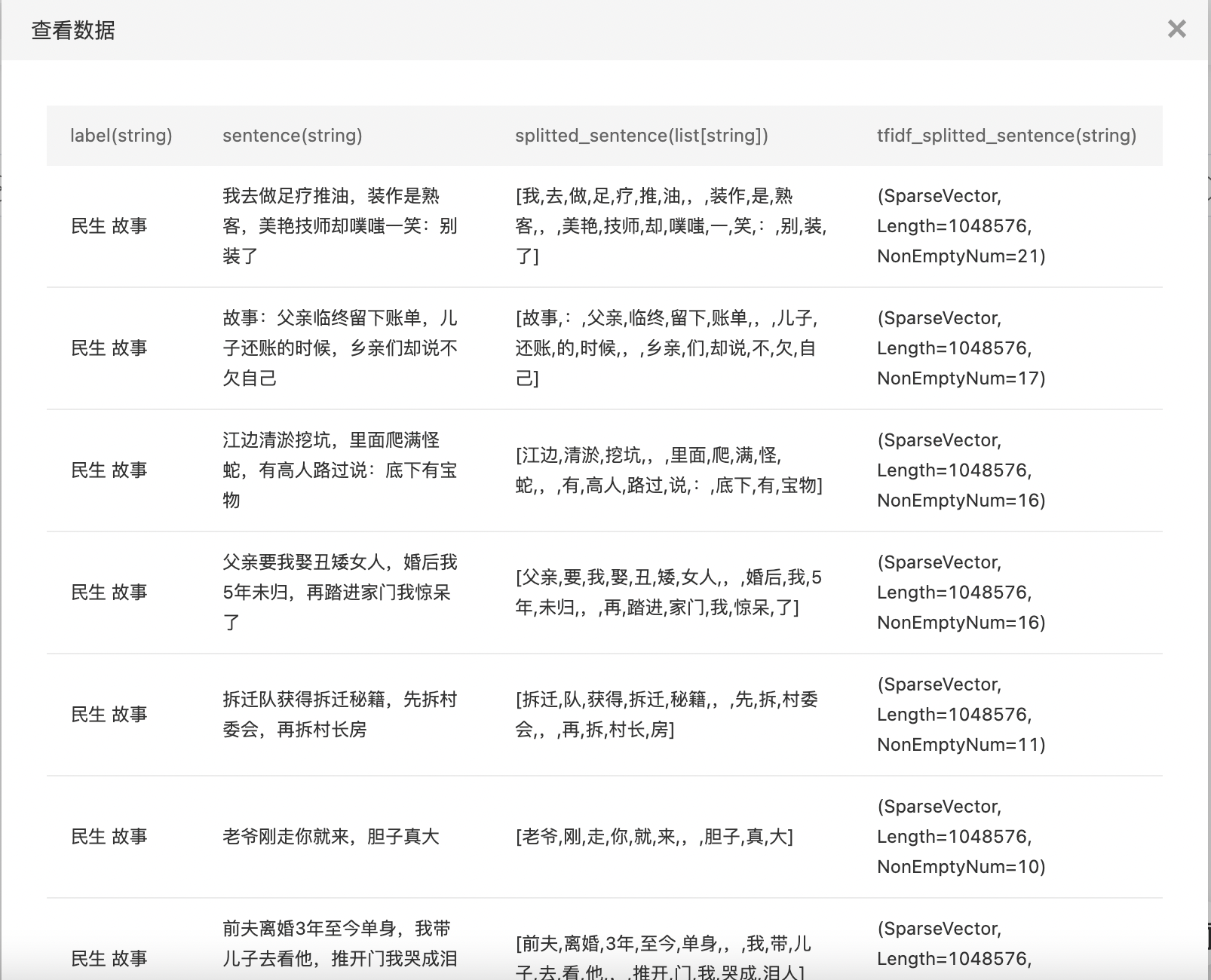
词典过滤
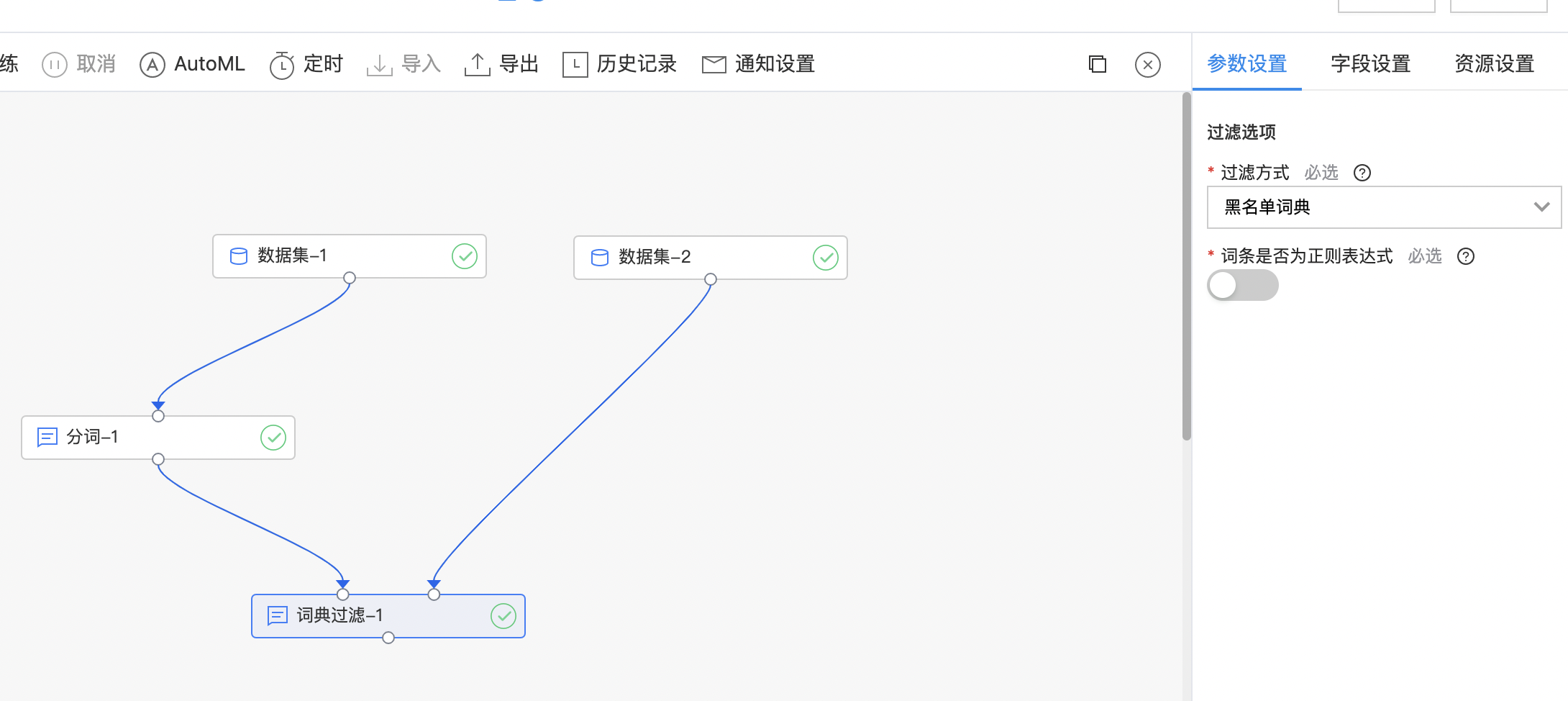
输入
- 选择两个输入数据集,第一个是需要过滤的数据集,第二个是词典数据集,根据选择的词典对待过滤数据集中的数据进行过滤
-
当前词典支持的过滤方式有:
- 白名单词典 结果集中只保留包含词典中的词
- 黑名单词典 结果集中去除包含词典中的词即保留词典中未出现的词
-
可选择是否保留原始列,默认为不保存
- 如果保留,则输出结果在原始列名前添加filtered_前缀如果不保留,则替换原始列
-
词条是否为正则表达式进行过滤
- 开启后,词典按正则表达式识别,例如“.*/v”可匹配所有结尾是/v的词。开启后过滤速度会减慢,请谨慎开启
输出
- 词典过滤处理后的数据集。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 过滤方式 | 是 | 选择白名单词典,结果中只保留词典中的词;选择黑名单词典,结果中去除词典中的词 | 黑名单词典 |
| 词条是否为正则表达式 | 是 | 开启后,词典按正则表达式识别,例如“.*/v”可匹配所有结尾是/v的词。开启后过滤速度会减慢,请谨慎开启。 | 关闭 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 输入列 | 是 | 输入数据集中需要过滤的列,列的类型需要是字符串数组。 | 无 |
| 保留原始列 | 是 | 是否保留原始列。如果保留,则输出结果在原始列名前添加[filtered_]前缀如果不保留,则替换原始列 | 关闭 |
| 词典列 | 是 | 词典数据集中的词典列,每行一个词,列的类型需要是字符串。 | 无 |
使用示例
命名实体识别预处理
输入
- 第一个输入为文本数据集,需要选择处理特征列。
- 第二个输入是用户字典,可根据需要选择用户字典的词语列和词性列(非必选)。
输出
- 输出命名实体识别预处理。
算子参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 是否删除重复行 | 是 | 是否删除文本数据集中的重复行。 | 关闭 |
| 是否使用lac模型 | 是 | 否使用lac模型,lac模型链接可参考https://github.com/baidu/lac | 关闭 |
字段参数
| 参数名称 | 是否必选 | 参数描述 | 默认值 |
|---|---|---|---|
| 文本列 | 是 | 待处理的文本列,类型为str。 | 无 |
| 词语列 | 否 | 用户词典的词语列,类型为str。 | 无 |
| 词性列 | 否 | 词性标签集合可参考https://github.com/baidu/lac,类型为str。 | 无 |
使用示例
查看命名实体识别预处理结果。