资源池管理简介
功能说明
BML全功能AI开发平台提供了公共资源池、专属资源池及用户资源池供您使用!您或者平台资源管理员相关角色可在资源管理模块进行管理。
公共资源池
公共资源池作为平台提供的默认资源池,可用于在训推场景提交CPU&GPU任务;支持按量后付费和资源包方式预付费购买;详见模型训练计费说明 公有云部署计费说明
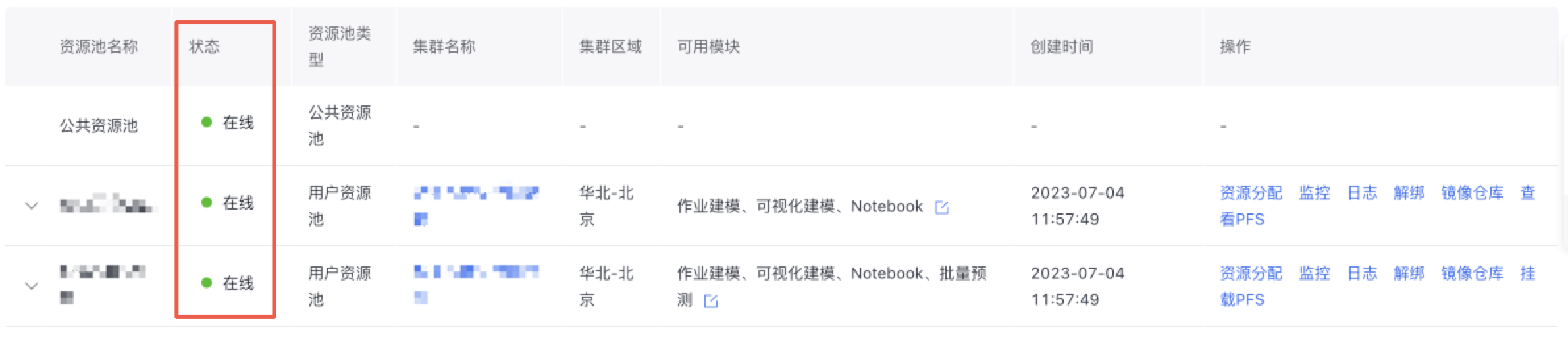
注:平台会为所有的用户提供一个公共资源池,以确保用户可以快速的上手和使用平台,公共资源池不可操作。
专属资源池
提供专属资源池,当您需要弹性、稳定且弱运维场景,可以在平台购买专属资源池供您使用,来确保训练资源的充足与可控。
专属资源池可支持在平台查看该资源池下资源利用率情况,可在创建好后通过列表操作-监控查看。
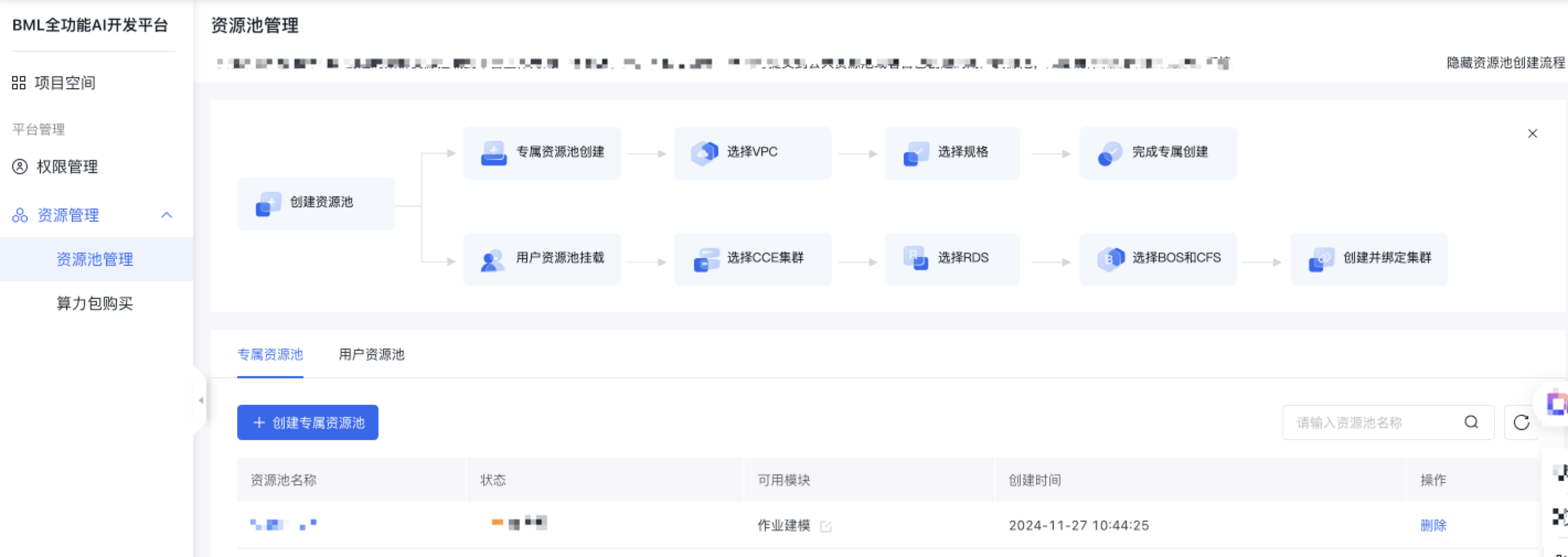
创建专属资源池
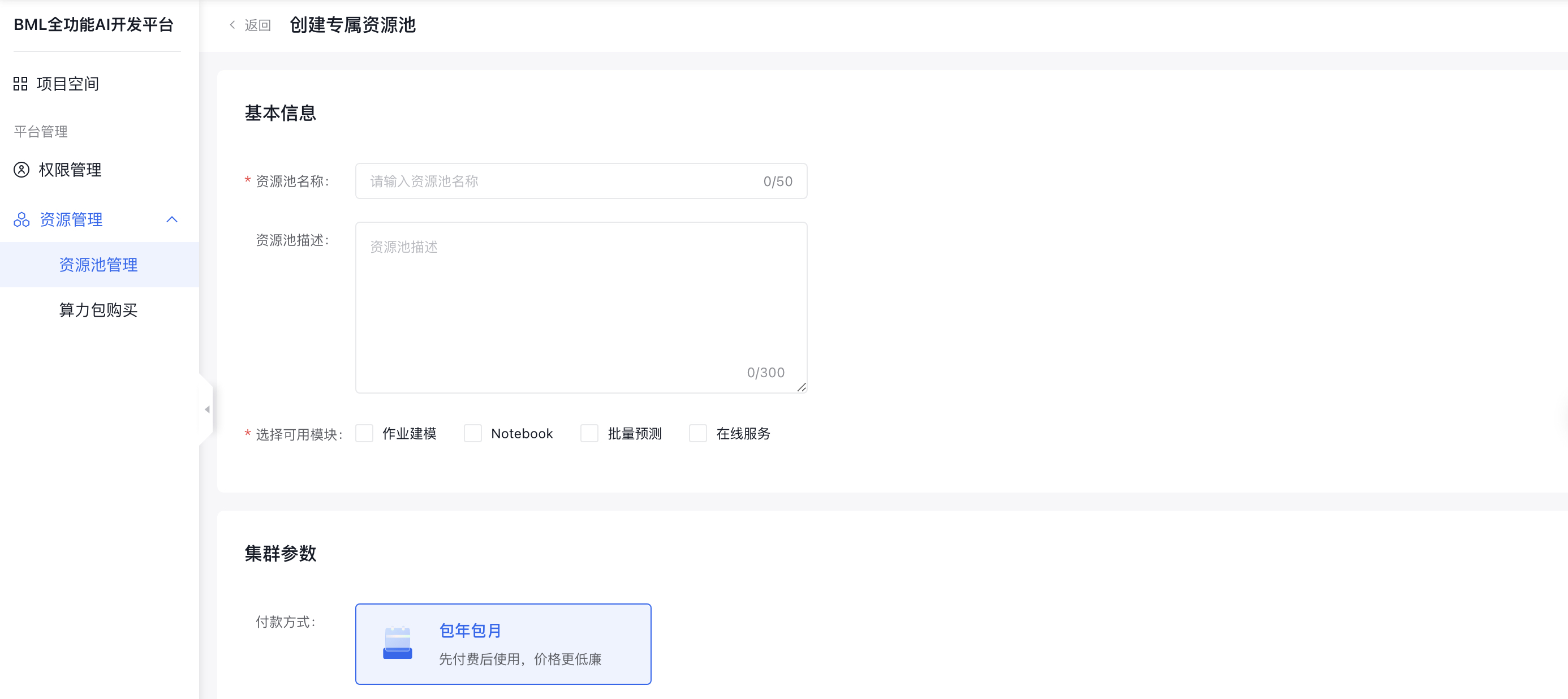
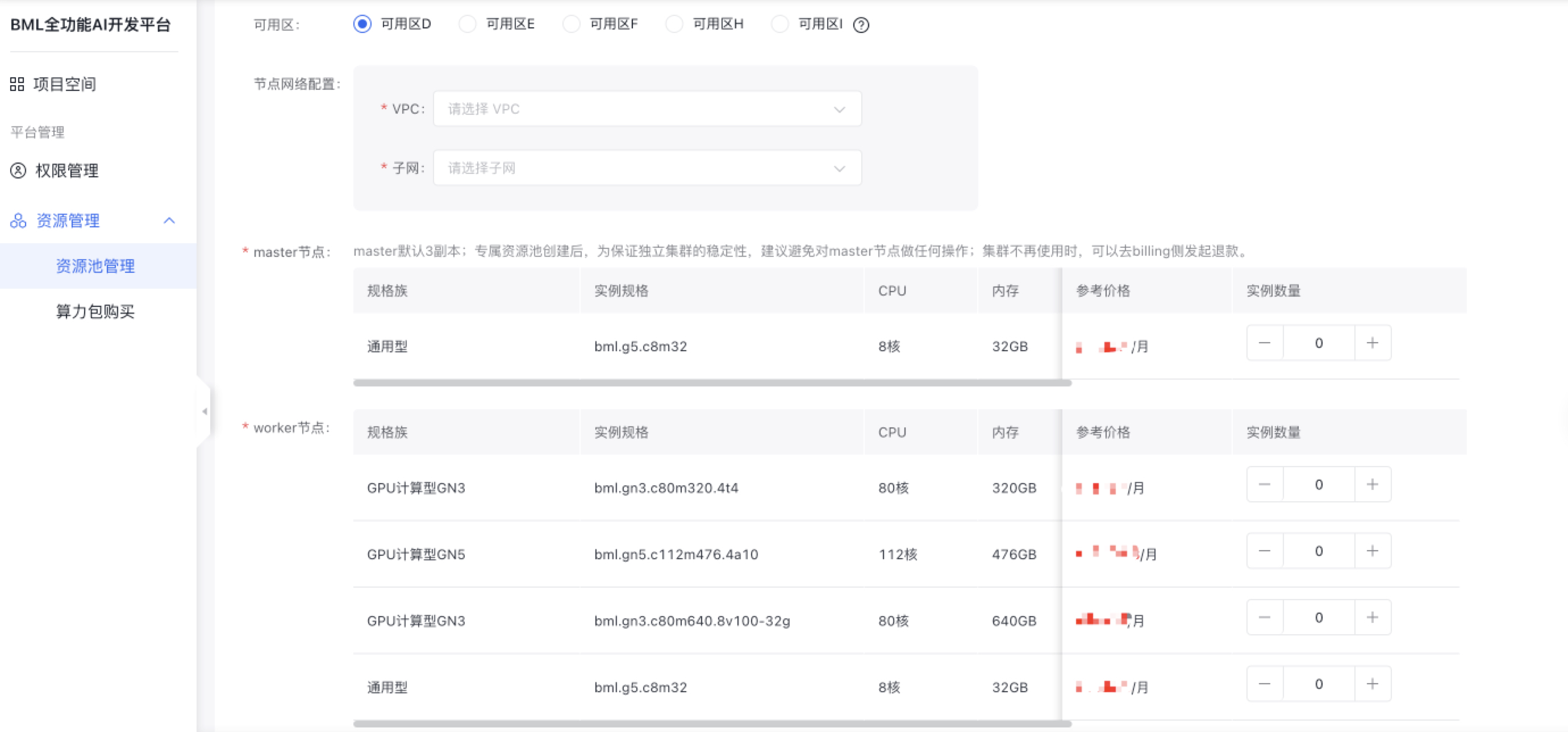
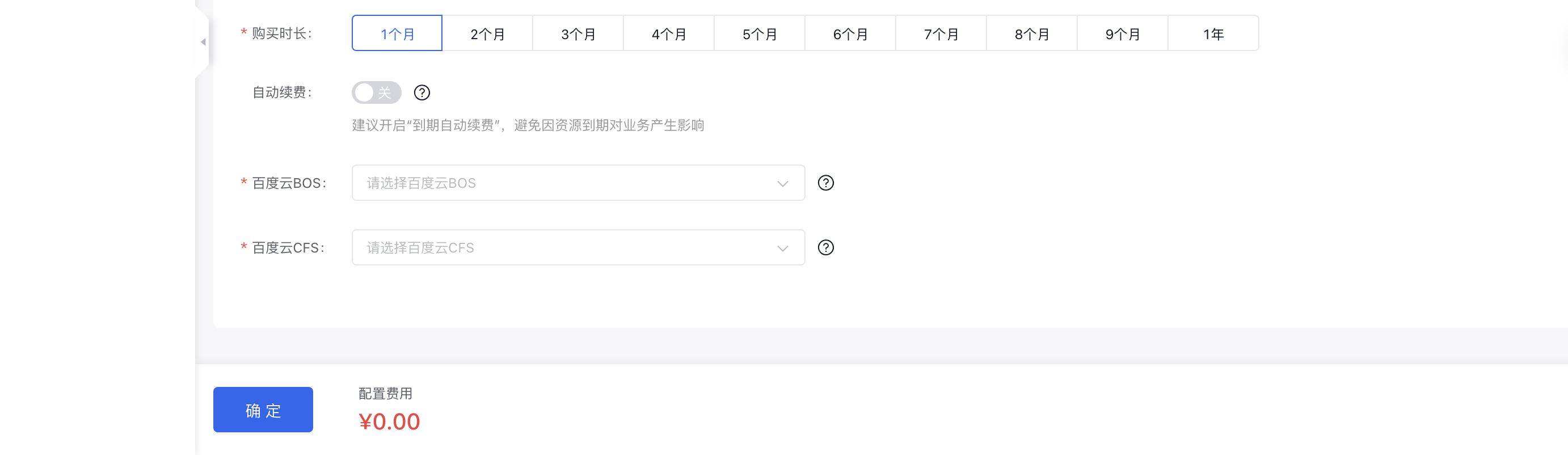
用户资源池
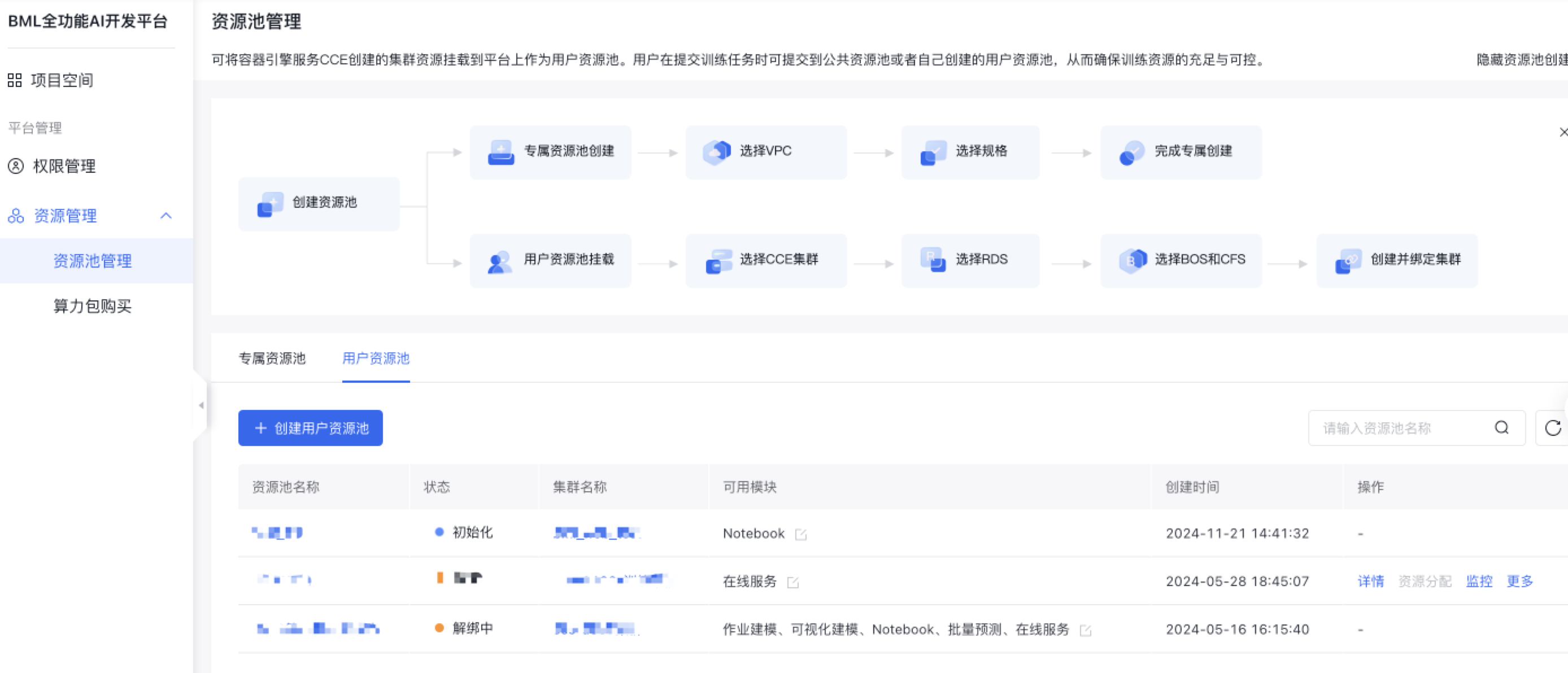
用户资源池是将您在容器引擎服务CCE创建的集群资源挂载到平台上,作为用户资源池。在提交训练任务时可以提交到自己创建的用户资源池。
相关依赖
资源池管理功能对一些相关的云产品有依赖,用户在使用之前需要事先准备好。
- 私有化VPC网络
私有网络VPC,是基于百度智能云构建的安全隔离的网络环境,支持用户可自定义网络地址空间、多VPC之间(同城、跨城)对等高速连接,通过VPN/专线的方式,与用户的数据中心构建安全、定制的混合云网络,实现原有业务轻松、安全的迁移到云端。
CCE集群对于VPC网络有依赖性,所以用户需要事先创建私有化VPC网络实例,才可使用CCE集群。
- 容器引擎CCE集群
容器引擎CCE集群可以提供Docker容器生命周期管理、大规模容器集群运维管理、业务应用一键式发布运行等功能,无缝衔接百度智能云其他产品。弹性、高可用的云端Kubernetes容器运行平台,助力系统架构微服务化、DevOps运维、AI应用深度学习容器化等场景。
资源池管理所使用的资源池即是由CCE所提供的,所以用户需要事先创建容器引擎CCE集群,才可使用资源池管理进行挂载。
注:CCE集群有地域之分,平台暂仅支持中国大陆的CCE集群。另外,CCE集群的地域需要与所使用的数据库等的地域保持一致,否则无法在平台上进行协同。且BML与CCE的协同当前仅支持Kubernetes的1.18.9版本。
- RDS云数据库
RDS云数据库提供专业的高性能、高可靠关系型云数据库服务,提供简易方便的 Web 界面管理、可靠的数据备份和恢复功能、完备的安全管理和监控等服务。
CCE集群在BML平台使用时需要的paddleflow组件对于RDS云数据库有依赖性,所以用户需要事先创建RDS云数据库,才可使用CCE集群。
- BOS对象存储
百度智能云对象存储BOS是一款稳定、安全、高效、高可拓展的云存储服务,支持标准、低频、冷和归档存储等多种存储类型满足多场景的存储需求。用户可以将任意数量和形式的非结构化数据存入BOS,并对数据进行管理和处理。
在挂载资源池后,用户在使用资源池时,所使用的数据集需要保存在BOS中进行调用,故而用户需要事先创建自己的BOS对象存储,才可以在平台上提交相关的训练任务。
注:BOS有地域之分,BOS所在的地域需要与所使用的CCE集群的地域保持一致,否则无法在平台上进行协同。
- CFS文件存储
文件存储CFS(Cloud File Storage)是百度智能云提供的安全、可扩展的文件存储服务。通过标准的文件访问协议,为云上的虚机、容器等计算资源提供无限扩展、高可靠、全球共享的文件存储能力。可用于内容管理及Web应用、大数据分析、泛娱乐和媒体应用等业务场景。
用户在使用资源池时,平台会将训练过程中的中间文件存储在CFS文件存储中,故而用户需要事先创建自己的CFS文件存储,才可以在平台上提交相关的训练任务。
- 百度云账户
由于 VPC、CCE、RDS、BOS、CFS 均需要注册百度云账户才可使用。另外,如果用户希望多人使用,需要在百度云中创建子账号,子账号也可在 BML 平台上使用主账号所拥有的资产。
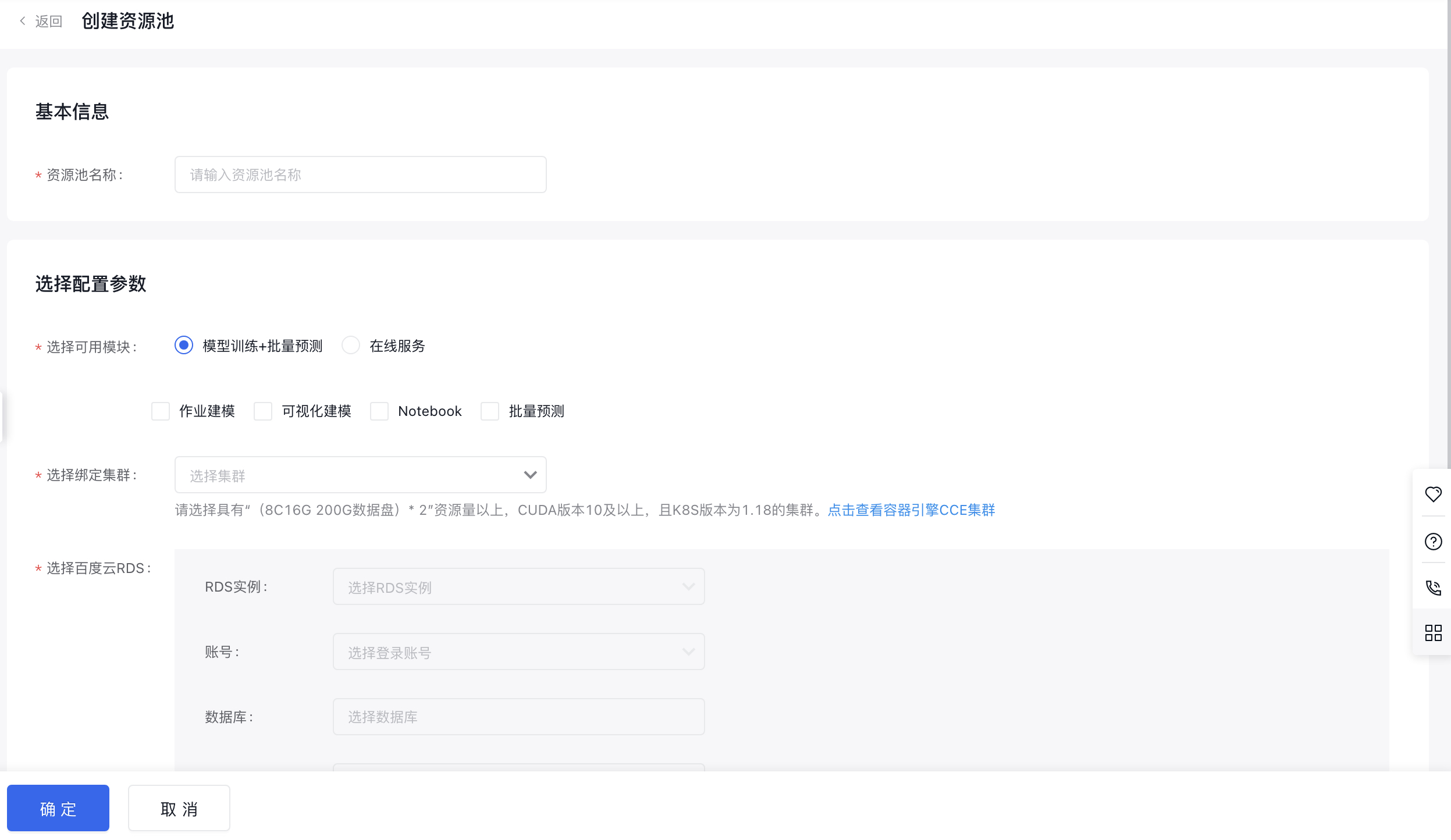
创建资源池
点击创建资源池,进入创建流程。

填写相关信息,并点击创建。
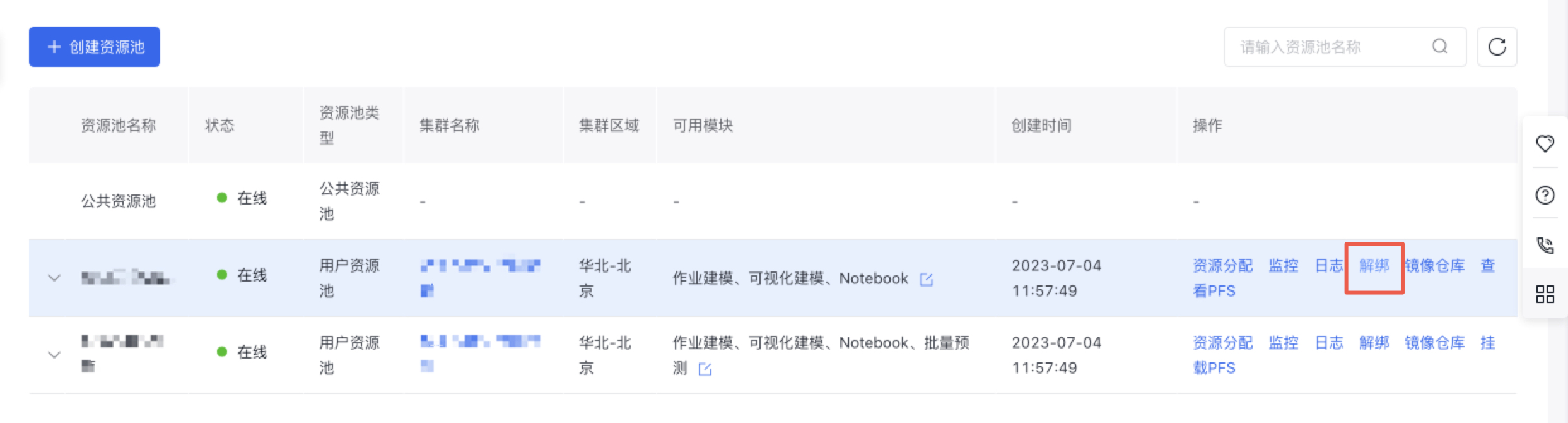
解绑资源池
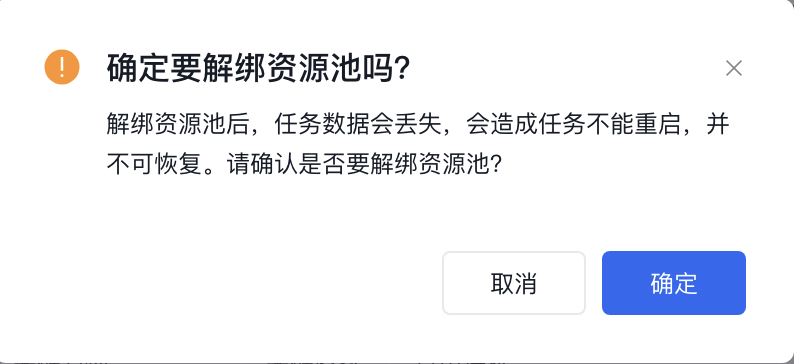
点击即可解绑资源池。
状态说明
创建资源池后可能会出现如下的状态:
- 初始化:点击创建后,平台将根据用户所填写的信息进行初始化,这个过程会持续几分钟或者十几分钟,请稍事等待。
- 在线:资源池已经创建成功,用户可以正常使用。
- 异常:资源池创建过程中出现异常,或者资源池使用过程中出现异常,原因可能是所依赖的 VPC、CCE、RDS、BOS、CFS 地域不一致,或者某一个服务中断等,由于此处发生异常的可能性比较多,如果出现异常状态,请用户提交工单找到我们的工程师协助进行排查。
- 解绑中:用户对某个资源池进行解绑操作后显示此状态。