
视觉任务EdgeBoard(VMX)专用SDK集成文档
简介
本文档旨在介绍 EasyDL在EdgeBoard USB加速卡VMX(以下简称VMX加速卡或加速卡)上的专用软件的使用流程。 EdgeBoard系列硬件适用于项目研发与部署,具有高性能、易携带、通用性强、开发简单等四大优点。 您可在AI市场了解EdgeBoard相关系列产品,同时可以在软硬一体方案了解性能数据。
注意:本型号主要面向产品集成和企业项目,未同时售卖散热片和外壳,部分情况下芯片温度较高,开发过程中,请勿用手触摸,谨防烫伤
硬件介绍
VMX加速卡,采用Intel® Movidus™ 视觉 MyriadX处理器芯片,通过 USB3.0 通讯type-c接口方式,配合外围电路即可将该模组嵌入到第三方智能化产品中,采用标准 USB通讯协议,对接简单,开发速度快,具有强大的深度学习计算功能。可通过OpenVINO™和OpenCV软件库工具链移植算法,兼容百度PaddlePaddle支持Paddle2onnx和PaddleHub并集成EasyDL,使产品应用范围广,性能更稳定,增强用户体验。
VMX加速卡适用于深度学习加速,能够解决复杂的人工智能软硬件设计挑战,它可以集成基于视觉的加速器和推理引擎来实现深度边缘学习的解决方案。(3D/2D人脸识别、人头检测、人脸属性分析(性别、年龄)、人脸特征比对、手势及姿态识别、物体检测及分类、算法移植等功能。)
硬件配置与说明
核心板模块: Intel® Movidus™ MyriadX,内置内存LP-DDR4 4GBit。
- 硬件指标
CPU
o Intel® Movidius Myriad X MA2485 Vision Processing Unit
o Total performance of over 4 trillion operations per second (TOPS)
o Over 1 TOPS performance on neural network inference w/ NCE accelerator
o 16 Programmable 128-bit VLIW Vector Processors
o 16 Configurable MIPI Lanes w/ enhanced Vision Accelerators
o 2.5 MB of Homogenous On-Chip Memory w/ 4Gbit LPDDR4
Size
o 38mm x 38mm
Interface o USB TYPE C(USB3.0)辅助接口精简设计
Boot o USB 启动模式 - 内置 switch 缺省模式设置
Power o 平均功耗0.5W~2.2W
Security o 支持 eFuse 加密
运行说明
VMX加速卡包含独立的AI运算芯片,采用 USB Type-C通讯方式,通讯协议简单可靠,可连接不同芯片架构主机,包括 X86、单片机、ARM SOC等。加速卡运行需要通过TypeC接口连接宿主机执行,宿主机目前支持的软硬件环境包括:
- Linux: x86-64, aarch64, armv7hf
- Windows: x86-64, Windows 10
使用过程中,请尽量避免直接触碰板卡元器件;或者使用防静电锡纸包裹板卡。
快速开始 Linux
开发者从EasyDL训练模型之后,下载的软件部署包中,包含了简单易用的SDK和Demo。只需简单的几个步骤,即可快速部署运行。
Release Notes
Python SDK
| 时间 | 版本 | 说明 |
|---|---|---|
| 2020.12.18 | 1.2.0 | 性能优化;接口优化升级;推理引擎升级 |
| 2020.09.17 | 1.1.19 | 支持更多模型与平台 |
Python SDK适用于Linux x86-64和Windows平台。
2020-12-18: 【接口升级】 Python SDK序列号配置接口从1.2.0版本开始已升级为新接口,以前的方式被置为deprecated,并将在未来的版本中移除。请尽快考虑升级为新的接口方式,具体使用方式可以参考下文介绍以及demo工程示例,谢谢。
C++ SDK
| 时间 | 版本 | 说明 |
|---|---|---|
| 2021.06.29 | 1.3.1 | 视频流解析支持分辨率调整 |
| 2021.05.14 | 1.3.0 | 新增视频流接入支持;展示已发布模型性能评估报告 |
| 2020.12.18 | 1.0.0 | 性能优化;接口优化升级;推理引擎升级 |
| 2020.09.17 | 0.5.6 | 新增C++ SDK,支持Linux aarch64和Linux armv7hf(树莓派)架构的硬件接入VMX预测 |
C++ SDK适用于Linux x86-64、Linux aarch64和Linux armv7hf平台。
2020-12-18: 【接口升级】 参数配置接口从1.0.0版本开始已升级为新接口,以前的方式被置为deprecated,并将在未来的版本中移除。请尽快考虑升级为新的接口方式,具体使用方式可以参考下文介绍以及demo工程示例,谢谢。
将加速卡连接宿主机
请使用质量合规的usb线连接。连接之后,检查设备是否被操作系统识别:
Linux 通过lsusb -v 命令检查是否有 Myriad设备:
1> sudo lsusb -v | grep -C 5 Myriad
2 bMaxPacketSize0 64
3 idVendor 0x03e7
4 idProduct 0x2485
5 bcdDevice 0.01
6 iManufacturer 1 Movidius Ltd.
7 iProduct 2 Movidius MyriadX
8 iSerial 3 03e72485Windows 可以在设备管理器中查询。
如果使用 VirtualBox 之类的虚拟机,请在虚拟机加入 03e7:24 和 03e7:f63b 两个 usb 设备。
获取并安装依赖
1) 安装依赖
宿主机与sdk为以下情况: 1⃣️ Windows x86-64 2⃣️ Linux x86-64且使用Python SDK时必须: 请参考 OpenVINO toolkit 文档安装 2020.3.1LTS 版本, 安装时可忽略Configure the Model Optimizer及后续部分。
安装完毕,运行之前,请按照OpenVino的文档 设置环境变量
1source /opt/intel/openvino/bin/setupvars.sh2) 从EasyDL 控制台获取SDK 在任意位置解压缩。
获取序列号
更换序列号、更换设备时,首次使用需要联网激活。激活成功之后,有效期内可离线使用。
请确保激活设备时使用的 操作系统账号与后续使用时运行的账号一致,否则会造成验证失败
Python SDK
- 安装wheel包
1 pip3 install -U BaiduAI_EasyEdge_SDK-{版本号}-cp37-cp37m-linux_x86_64.whl注意,请根据python的版本选择对应的whl文件,其中,
1.2.0是SDK版本号,cp37表示是python3.7版本
--
注意,pip安装时请添加
-U参数
- 将步骤2中获得的序列号 填入
demo.py
1pred = edge.Program()
2pred.set_auth_license_key("这里填写序列号")- 测试demo.py
1 python3 demo.py {模型资源文件夹RES路径} {待识别的图片路径} 生成的样例结果图片如下:

使用流程
1import BaiduAI.EasyEdge as edge
2
3pred = edge.Program()
4pred.set_auth_license_key("这里填写序列号")
5pred.init(model_dir={RES文件夹路径}, device=edge.Device.MOVIDIUS, engine=edge.Engine.OPENVINO)
6pred.infer_image({numpy.ndarray的图片})
7pred.close()接口的详细说明请主要参考 SDK 中的接口注释
接口说明
Program
- 初始化
1def init(self,
2 model_dir,
3 device=Device.CPU,
4 engine=Engine.NCSDK,
5 config_file='conf.json',
6 preprocess_file='preprocess_args.json',
7 model_file='model',
8 params_file='params',
9 graph_file='graph.ncsmodel',
10 label_file='label_list.txt',
11 device_id=0,
12 **kwargs
13 ):
14 """
15 Args:
16 model_dir: str
17 device: BaiduAI.EasyEdge.Device
18 engine: BaiduAI.EasyEdge.Engine
19 preprocess_file: str
20 model_file: str
21 params_file: str
22 graph_file: str ncs的模型文件 或 PaddleV2的模型文件
23 label_file: str
24 device_id: int 设备ID
25 thread_num: int CPU的线程数
26
27 Raises:
28 RuntimeError, IOError
29 Returns:
30 bool: True if success
31
32 """- 预测单张图像
1 def infer_image(self, img, threshold=None,
2 channel_order='HWC',
3 color_format='BGR',
4 data_type='numpy'
5 ):
6 """
7
8 Args:
9
10 img: np.ndarray or bytes
11 channel_order(string):
12 channel order: HWC or CHW
13 color_format(string):
14 color format order: RGB or BGR
15 threshold(float):
16 only return result with confidence larger than threshold
17 data_type(string): 仅在图像分割时有意义。 'numpy' or 'string'
18 'numpy': 返回已解析的mask
19 'string': 返回未解析的mask游程编码
20 Returns:
21 list
22
23 """- 返回格式:
[dict1, dict2, ...]
| 字段 | 类型 | 取值 | 说明 |
|---|---|---|---|
| confidence | float | 0~1 | 分类或检测的置信度 |
| label | string | 分类或检测的类别 | |
| index | number | 分类或检测的类别 | |
| x1, y1 | float | 0~1 | 物体检测,矩形的左上角坐标 (相对长宽的比例值) |
| x2, y2 | float | 0~1 | 物体检测,矩形的右下角坐标(相对长宽的比例值) |
| mask | string/numpy.ndarray | 图像分割的mask |
关于矩形坐标
x1 * 图片宽度 = 检测框的左上角的横坐标
y1 * 图片高度 = 检测框的左上角的纵坐标
x2 * 图片宽度 = 检测框的右下角的横坐标
y2 * 图片高度 = 检测框的右下角的纵坐标
可以参考 demo 文件中使用 opencv 绘制矩形的逻辑。
结果示例
- i) 图像分类
1{
2 "index": 736,
3 "label": "table",
4 "confidence": 0.9
5}- ii) 物体检测
1{
2 "y2": 0.91211,
3 "label": "cat",
4 "confidence": 1.0,
5 "x2": 0.91504,
6 "index": 8,
7 "y1": 0.12671,
8 "x1": 0.21289
9}- iii) 图像分割
1{
2 "name": "cat",
3 "score": 1.0,
4 "location": {
5 "left": ...,
6 "top": ...,
7 "width": ...,
8 "height": ...,
9 },
10 "mask": ...
11}mask字段中,data_type为numpy时,返回图像掩码的二维数组
1{
2 {0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
3 {0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
4 {0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
5 {0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
6 {0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
7 {0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
8}
9其中1代表为目标区域,0代表非目标区域data_type为string时,mask的游程编码,解析方式可参考 demo
C++ SDK
使用说明
模型资源文件默认已经打包在开发者下载的SDK包中。 请先将SDK包整体拷贝到具体运行的宿主机设备中,再解压缩编译;
在编译或运行demo程序前执行以下命令:
source ${cpp_kit位置路径}/thirdparty/openvino/bin/setupvars.sh
如果openvino预测引擎找不到设备需要执行以下命令:
1sudo cp ${cpp_kit位置路径}/thirdparty/openvino/deployment_tools/inference_engine/external/97-myriad-usbboot.rules /etc/udev/rules.d/
2sudo udevadm control --reload-rules
3sudo udevadm trigger
4sudo ldconfig ```使用流程
1 // step 1: 配置运行参数
2 EdgePredictorConfig config;
3 config.set_config(easyedge::params::PREDICTOR_KEY_SERIAL_NUM, "this-is-serial-num"); // 设置序列号
4 config.model_dir = {模型文件目录};
5
6 // step 2: 创建并初始化Predictor
7 auto predictor = global_controller()->CreateEdgePredictor(config);
8 if (predictor->init() != EDGE_OK) {
9 exit(-1);
10 }
11
12 // step 3-1: 预测图像
13 auto img = cv::imread({图片路径});
14 std::vector<EdgeResultData> results;
15 predictor->infer(img, results);
16
17 // step 3-2: 预测视频
18 std::vector<EdgeResultData> results;
19 FrameTensor frame_tensor;
20 VideoConfig video_config;
21 video_config.source_type = static_cast<SourceType>(video_type); // source_type 定义参考头文件 easyedge_video.h
22 video_config.source_value = video_src;
23 /*
24 ... more video_configs, 根据需要配置video_config的各选项
25 */
26 auto video_decoding = CreateVideoDecoding(video_config);
27 while (video_decoding->next(frame_tensor) == EDGE_OK) {
28 results.clear();
29 if (frame_tensor.is_needed) {
30 predictor->infer(frame_tensor.frame, results);
31 render(frame_tensor.frame, results, predictor->model_info().kind);
32 }
33 //video_decoding->display(frame_tensor); // 显示当前frame,需在video_config中开启配置
34 //video_decoding->save(frame_tensor); // 存储当前frame到视频,需在video_config中开启配置
35 }运行参数配置
运行参数的配置通过结构体EdgePredictorConfig完成,其定义如下所示:
1struct EdgePredictorConfig {
2 /**
3 * @brief 模型资源文件夹路径
4 */
5 std::string model_dir;
6
7 std::map<std::string, std::string> conf;
8
9 EdgePredictorConfig();
10
11 template<typename T>
12 T get_config(const std::string &key, const T &default_value);
13
14 template<typename T = std::string>
15 T get_config(const std::string &key);
16
17 template<typename T>
18 const T *get_config(const std::string &key, const T *default_value);
19
20 template<typename T>
21 void set_config(const std::string &key, const T &value);
22
23 template<typename T>
24 void set_config(const std::string &key, const T *value);
25
26 static EdgePredictorConfig default_config();
27};运行参数选项的配置以key、value的方式存储在类型为std::map的conf中,并且键值对的设置和获取可以通过EdgePredictorConfig的set_config和get_config函数完成。同时部分参数也支持以环境变量的方式设置键值对。
EdgePredictorConfig的具体使用方法可以参考开发工具包中的demo工程。
具体支持的运行参数可以参考开发工具包中的头文件。
初始化
- 接口
1auto predictor = global_controller()->CreateEdgePredictor(config);
2predictor->init();若返回非0,请查看输出日志排查错误原因。
预测图像
- 接口
1 /**
2 * @brief
3 * 通用接口
4 * @param image: must be BGR , HWC format (opencv default)
5 * @param result
6 * @return
7 */
8 virtual int infer(
9 cv::Mat& image, std::vector<EdgeResultData>& result
10 ) = 0;图片的格式务必为opencv默认的BGR, HWC格式。
- 返回格式
EdgeResultData中可以获取对应的分类信息、位置信息。
1struct EdgeResultData {
2 int index; // 分类结果的index
3 std::string label; // 分类结果的label
4 float prob; // 置信度
5
6 // 物体检测活图像分割时才有
7 float x1, y1, x2, y2; // (x1, y1): 左上角, (x2, y2): 右下角; 均为0~1的长宽比例值。
8
9 // 图像分割时才有
10 cv::Mat mask; // 0, 1 的mask
11 std::string mask_rle; // Run Length Encoding,游程编码的mask
12};关于矩形坐标
x1 * 图片宽度 = 检测框的左上角的横坐标
y1 * 图片高度 = 检测框的左上角的纵坐标
x2 * 图片宽度 = 检测框的右下角的横坐标
y2 * 图片高度 = 检测框的右下角的纵坐标
关于图像分割mask
1cv::Mat mask为图像掩码的二维数组
2{
3 {0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
4 {0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
5 {0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
6 {0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
7 {0, 0, 0, 1, 1, 1, 0, 0, 0, 0},
8 {0, 0, 0, 0, 0, 0, 0, 0, 0, 0},
9}
10其中1代表为目标区域,0代表非目标区域关于图像分割mask_rle
该字段返回了mask的游程编码,解析方式可参考 http demo
以上字段可以参考demo文件中使用opencv绘制的逻辑进行解析
预测视频
SDK 提供了支持摄像头读取、视频文件和网络视频流的解析工具类VideoDecoding,此类提供了获取视频帧数据的便利函数。通过VideoConfig结构体可以控制视频/摄像头的解析策略、抽帧策略、分辨率调整、结果视频存储等功能。对于抽取到的视频帧可以直接作为SDK infer 接口的参数进行预测。
- 接口
classVideoDecoding:
1 /**
2 * @brief 获取输入源的下一帧
3 * @param frame_tensor
4 * @return
5 */
6 virtual int next(FrameTensor &frame_tensor) = 0;
7
8 /**
9 * @brief 显示当前frame_tensor中的视频帧
10 * @param frame_tensor
11 * @return
12 */
13 virtual int display(const FrameTensor &frame_tensor) = 0;
14
15 /**
16 * @brief 将当前frame_tensor中的视频帧写为本地视频文件
17 * @param frame_tensor
18 * @return
19 */
20 virtual int save(FrameTensor &frame_tensor) = 0;
21
22 /**
23 * @brief 获取视频的fps属性
24 * @return
25 */
26 virtual int get_fps() = 0;
27 /**
28 * @brief 获取视频的width属性
29 * @return
30 */
31 virtual int get_width() = 0;
32
33 /**
34 * @brief 获取视频的height属性
35 * @return
36 */
37 virtual int get_height() = 0;struct VideoConfig
1/**
2 * @brief 视频源、抽帧策略、存储策略的设置选项
3 */
4struct VideoConfig {
5 SourceType source_type; // 输入源类型
6 std::string source_value; // 输入源地址,如视频文件路径、摄像头index、网络流地址
7 int skip_frames{0}; // 设置跳帧,每隔skip_frames帧抽取一帧,并把该抽取帧的is_needed置为true
8 int retrieve_all{false}; // 是否抽取所有frame以便于作为显示和存储,对于不满足skip_frames策略的frame,把所抽取帧的is_needed置为false
9 int input_fps{0}; // 在采取抽帧之前设置视频的fps
10 Resolution resolution{Resolution::kAuto}; // 采样分辨率,只对camera有效
11
12 bool enable_display{false};
13 std::string window_name{"EasyEdge"};
14 bool display_all{false}; // 是否显示所有frame,若为false,仅显示根据skip_frames抽取的frame
15
16 bool enable_save{false};
17 std::string save_path; // frame存储为视频文件的路径
18 bool save_all{false}; // 是否存储所有frame,若为false,仅存储根据skip_frames抽取的frame
19
20 std::map::string, std::string> conf;
21};source_type:输入源类型,支持视频文件、摄像头、网络视频流三种,值分别为1、2、3。
source_value: 若source_type为视频文件,该值为指向视频文件的完整路径;若source_type为摄像头,该值为摄像头的index,如对于/dev/video0的摄像头,则index为0;若source_type为网络视频流,则为该视频流的完整地址。
skip_frames:设置跳帧,每隔skip_frames帧抽取一帧,并把该抽取帧的is_needed置为true,标记为is_needed的帧是用来做预测的帧。反之,直接跳过该帧,不经过预测。
retrieve_all:若置该项为true,则无论是否设置跳帧,所有的帧都会被抽取返回,以作为显示或存储用。
input_fps:用于抽帧前设置fps。
resolution:设置摄像头采样的分辨率,其值请参考easyedge_video.h中的定义,注意该分辨率调整仅对输入源为摄像头时有效。
conf:高级选项。部分配置会通过该map来设置。
注意:
- 如果使用
VideoConfig的display功能,需要自行编译带有GTK选项的opencv,默认打包的opencv不包含此项。 - 使用摄像头抽帧时,如果通过
resolution设置了分辨率调整,但是不起作用,请添加如下选项:
1video_config.conf["backend"] = "2";3.部分设备上的CSI摄像头尚未兼容,如遇到问题,可以通过工单、QQ交流群或微信交流群反馈。
具体接口调用流程,可以参考SDK中的demo_video_inference。
设置序列号
请在网页控制台中申请序列号,并在init初始化前设置。 LinuxSDK 首次使用需联网授权。
1EdgePredictorConfig config;
2config.set_config(easyedge::params::PREDICTOR_KEY_SERIAL_NUM, "this-is-serial-num");日志配置
设置 EdgeLogConfig 的相关参数。具体含义参考文件中的注释说明。
1EdgeLogConfig log_config;
2log_config.enable_debug = true;
3global_controller()->set_log_config(log_config);http服务
-
- 开启http服务
http服务的启动参考
demo_serving.cpp文件。
- 开启http服务
http服务的启动参考
1 /**
2 * @brief 开启一个简单的demo http服务。
3 * 该方法会block直到收到sigint/sigterm。
4 * http服务里,图片的解码运行在cpu之上,可能会降低推理速度。
5 * @tparam ConfigT
6 * @param config
7 * @param host
8 * @param port
9 * @param service_id service_id user parameter, uri '/get/service_id' will respond this value with 'text/plain'
10 * @param instance_num 实例数量,根据内存/显存/时延要求调整
11 * @return
12 */
13 template<typename ConfigT>
14 int start_http_server(
15 const ConfigT &config,
16 const std::string &host,
17 int port,
18 const std::string &service_id,
19 int instance_num = 1);-
- 请求http服务
开发者可以打开浏览器,
http://{设备ip}:24401,选择图片来进行测试。
URL中的get参数:
| 参数 | 说明 | 默认值 |
|---|---|---|
| threshold | 阈值过滤, 0~1 | 如不提供,则会使用模型的推荐阈值 |
HTTP POST Body即为图片的二进制内容(无需base64, 无需json)
Python请求示例
1import requests
2
3with open('./1.jpg', 'rb') as f:
4 img = f.read()
5 result = requests.post(
6 'http://127.0.0.1:24401/',
7 params={'threshold': 0.1},
8 data=img).json()- http 返回数据
| 字段 | 类型说明 | 其他 |
|---|---|---|
| error_code | Number | 0为成功,非0参考message获得具体错误信息 |
| results | Array | 内容为具体的识别结果。其中字段的具体含义请参考预测图像-返回格式一节 |
| cost_ms | Number | 预测耗时ms,不含网络交互时间 |
返回示例
1{
2 "cost_ms": 52,
3 "error_code": 0,
4 "results": [
5 {
6 "confidence": 0.94482421875,
7 "index": 1,
8 "label": "IronMan",
9 "x1": 0.059185408055782318,
10 "x2": 0.18795496225357056,
11 "y1": 0.14762254059314728,
12 "y2": 0.52510076761245728
13 },
14 {
15 "confidence": 0.94091796875,
16 "index": 1,
17 "label": "IronMan",
18 "x1": 0.79151463508605957,
19 "x2": 0.92310667037963867,
20 "y1": 0.045728668570518494,
21 "y2": 0.42920106649398804
22 }
23 ]
24}其他配置
-
- 日志名称、HTTP 网页标题设置
通过global_controller的set_config方法设置:
1global_controller()->set_config(easyedge::params::KEY_LOG_BRAND, "MY_BRAND");效果如下:
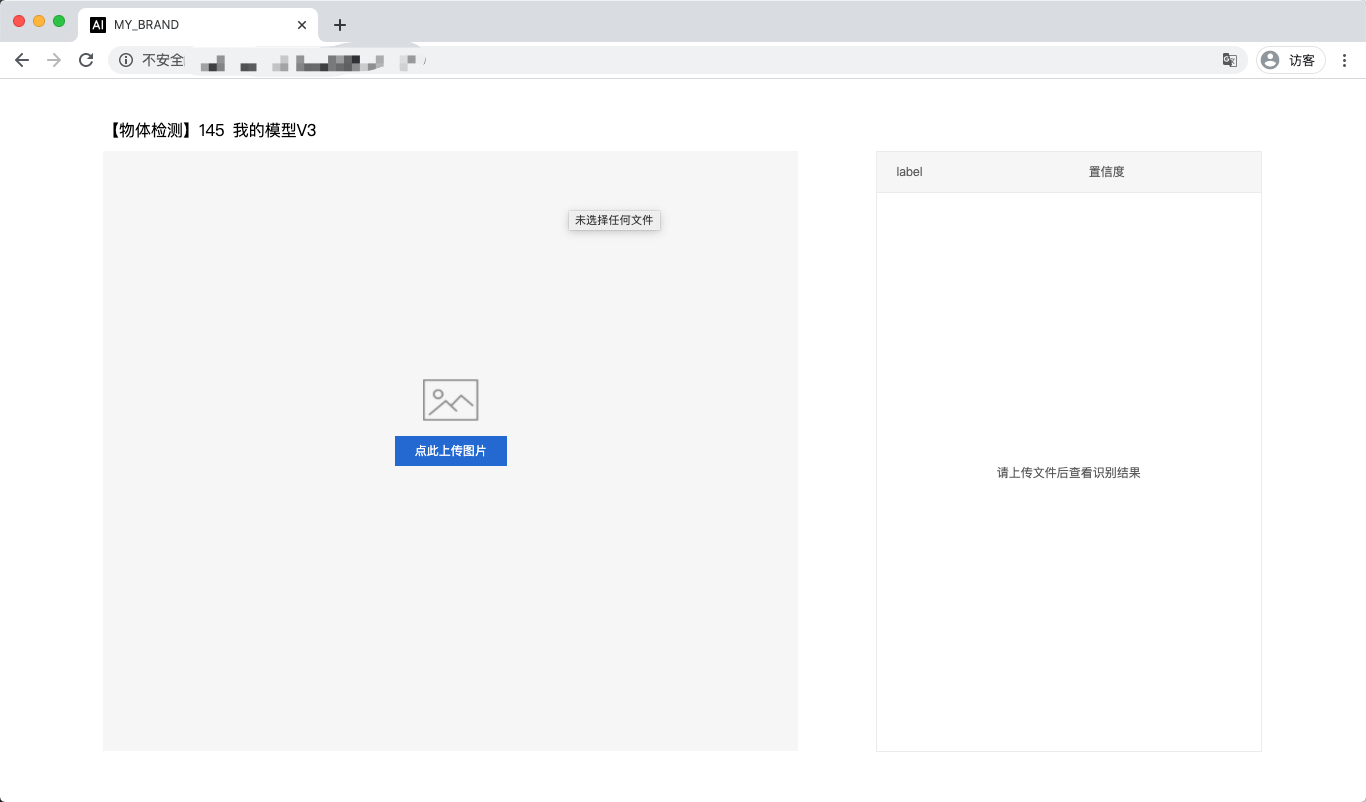
Linux FAQ
1. EasyDL 离线 SDK 与云服务效果不一致,如何处理?
我们会逐渐消除这部分差异,如果开发者发现差异较大,可通过工单、论坛联系我们协助处理。
2. 硬件出现问题或者出现故障怎么办? 软件使用有问题怎么处理?
- 如果持续在静电较多的环境中使用,建议使用防静电锡纸包裹板卡
- 如果硬件无法启动等故障,您可以通过商品页联系供应商处理;其它硬件问题,您可以邮件 edgeboard-vmx.com ,我们将在0-2日内处理您的问题。为加快处理进度,您在邮件中,尽量描述清楚问题或者需求细节,避免来回沟通。
- 软件使用问题,请尽量通过工单、论坛联系我们协助处理。
3. 运行时报错:NC_ERROR
1Can not init Myriad device: NC_ERROR一般是硬件没有插上,请确保lsusb能够找到该硬件。或者等待几秒后再试。
快速开始 Windows
1. 安装依赖
将操作系统升级到Windows 10
安装.NET Framework4.5
1https://www.microsoft.com/zh-CN/download/details.aspx?id=42642Visual C++ Redistributable Packages for Visual Studio 2013
1https://www.microsoft.com/zh-cn/download/details.aspx?id=40784Visual C++ Redistributable Packages for Visual Studio 2015
1https://www.microsoft.com/zh-cn/download/details.aspx?id=48145注意事项
- 安装目录不能包含中文
- Windows Server 请自行开启,选择“我的电脑”——“属性”——“管理”——”添加角色和功能“——勾选”桌面体验“,点击安装,安装之后重启即可。
2. 运行离线SDK
解压下载好的SDK,打开EasyEdge.exe,输入Serial Num
 点击"启动服务",等待数秒即可启动成功,本地服务默认运行在
点击"启动服务",等待数秒即可启动成功,本地服务默认运行在
1http://127.0.0.1:24401/其他任何语言只需通过HTTP调用即可。
接口调用说明
Python 使用示例代码如下
1import requests
2
3with open('./1.jpg', 'rb') as f:
4 img = f.read()
5
6## params 为GET参数 data 为POST Body
7result = requests.post('http://127.0.0.1:24401/', params={'threshold': 0.1},
8 data=img).json()C## 使用示例代码如下
1FileStream fs = new FileStream("./img.jpg", FileMode.Open);
2BinaryReader br = new BinaryReader(fs);
3byte[] img = br.ReadBytes((int)fs.Length);
4br.Close();
5fs.Close();
6string url = "http://127.0.0.1:8402?threshold=0.1";
7HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create(url);
8request.Method = "POST";
9Stream stream = request.GetRequestStream();
10stream.Write(img, 0, img.Length);
11stream.Close();
12
13WebResponse response = request.GetResponse();
14StreamReader sr = new StreamReader(response.GetResponseStream());
15Console.WriteLine(sr.ReadToEnd());
16sr.Close();
17response.Close();请求参数
| 字段 | 类型 | 取值 | 说明 |
|---|---|---|---|
| threshold | float | 0 ~ 1 | 置信度阈值 |
HTTP POST Body直接发送图片二进制。
返回参数
| 字段 | 类型 | 取值 | 说明 |
|---|---|---|---|
| confidence | float | 0~1 | 分类或检测的置信度 |
| label | string | 分类或检测的类别 | |
| index | number | 分类或检测的类别 | |
| x1, y1 | float | 0~1 | 物体检测,矩形的左上角坐标 (相对长宽的比例值) |
| x2, y2 | float | 0~1 | 物体检测,矩形的右下角坐标(相对长宽的比例值) |
关于矩形坐标
x1 * 图片宽度 = 检测框的左上角的横坐标
y1 * 图片高度 = 检测框的左上角的纵坐标
x2 * 图片宽度 = 检测框的右下角的横坐标
y2 * 图片高度 = 检测框的右下角的纵坐标
Windows FAQ
1. 服务启动失败,怎么处理?
请确保相关依赖都安装正确,版本必须如下: .NET Framework 4.5 Visual C++ Redistributable Packages for Visual Studio 2013 * Visual C++ Redistributable Packages for Visual Studio 2015
2. 服务调用时返回为空,怎么处理?
调用输入的图片必须是RGB格式,请确认是否有alpha通道。
3. 多个模型怎么同时使用?
SDK设置运行不同的端口,点击运行即可。
4. JAVA、C#等其他语言怎么调用SDK?
参考 http://ai.baidu.com/forum/topic/show/943765
5. 启动失败,缺失DLL?
打开EasyEdge.log,查看日志错误,根据提示处理 缺失DLL,请使用 http://www.dependencywalker.com/ 查看相应模块依赖DLL缺失哪些,请自行下载安装
6. 启动失败,报错NotDecrypted?
Windows下使用,当前用户名不能为中文,否则无法正确加载模型。
7. 其他问题
如果无法解决,可到论坛发帖: http://ai.baidu.com/forum/topic/list/199 描述使用遇到的问题,我们将及时回复您的问题。