
文本智能标注介绍及原理说明
欢迎您使用「文本智能标注」。您可以通过提供少量人工标注数据和大量无标注数据,通过文本智能标注能力进行自动标注,并将需要人工优先复审的样本筛选出来,辅助您快速完成数据标注工作。您可以获得大规模的智能标注数据,并将数据用于模型的训练。本文将介绍说明如何利用「文本智能标注」获得智能标注数据,以及智能标注与后续如何使用智能标注数据训练模型。
详细使用「文本智能标注」的流程如下:
一、启动智能标注获得智能标注数据
Step1 启动智能标注任务前的准备工作
智能标注任务,是对一个数据集中的未标注数据进行智能标注。请您先在「数据管理/标注」模块,创建数据集,并上传一定量的已标注数据和未标注数据。具体数据量的要求,请见下文「创建文本智能标注任务」。
Step2 创建文本智能标注任务
您可以在「智能标注」功能页面下,选中「自然语言」查看文本智能标注的流程概述和说明。
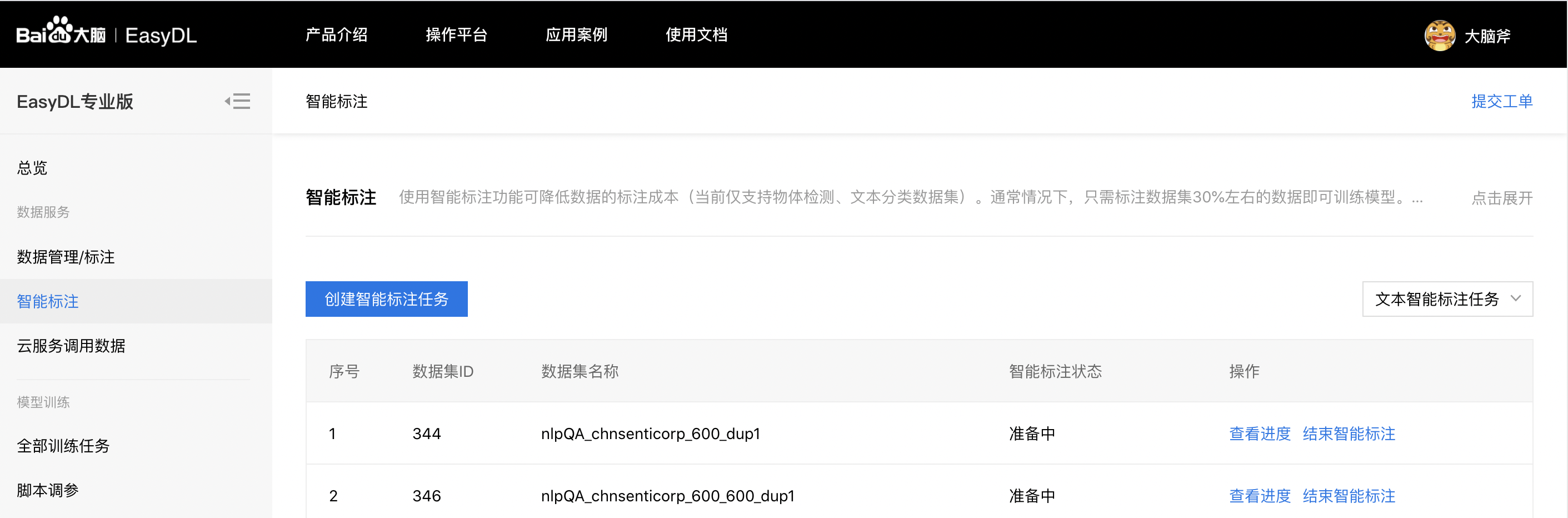
在页面上,通过点击「创建智能标注任务」来选择对应操作的数据集。选择「文本分类」任务,数据集选择您想智能标注的数据集。
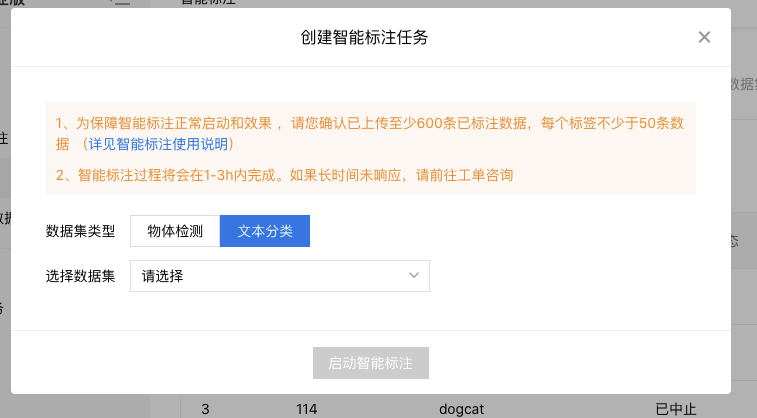
注意,请先检验所选择的数据集是否满足以下条件:
- 数据集中已标注数据量超过600条
- 每个标注标签的数据量超过50条
- 未标注数据的数据量超过600条
选择好数据集后,点击「启动智能标注」,平台将对您提交的数据集进行启动前的校验,并可在下方的任务栏中,查看到新建的智能标注任务,任务状态处于「数据校验中」。
Step3 智能标注过程
当数据校验无误后,系统将自动启动智能标注,页面将显示当前智能标注所处的流程状态。 如页面图中所示,智能标注过程分为三个部分,第四个部分为「前往模型训练」的说明,后文将详细说明。
下面,将对智能标注所涉及的三个阶段进行说明:
阶段一:智能标注预学习阶段
在本阶段,系统将使用您提交的已标注数据进行机器学习。预学习阶段预计耗时约40-60分钟不等,根据您的数据集中已标注数据的量而定。如果您需要中止预学习阶段,您可以点击「关闭智能标注」,则系统将重置已完成的智能学习状态。此时您的数据集中「已标注」和「未标注」的数据不会产生变化。
阶段二:智能标注阶段
完成智能标注预学习阶段,系统将自动进入智能标注阶段。此时系统将对您提交数据集下的「未标注」数据进行智能标注,智能标注过程的耗时跟您提交的未标注数据量正相关,即数据量越大,耗时将越长。您可以根据需要,也可「关闭智能标注」。此时注意,关闭智能标注后,已经完成的智能标注的数据,将被恢复为未标注数据。
Tips:按照我们的估算,预计5w条未标注数据,将消耗2小时进行智能标注。
阶段三:完成智能标注,查看智能标注数据
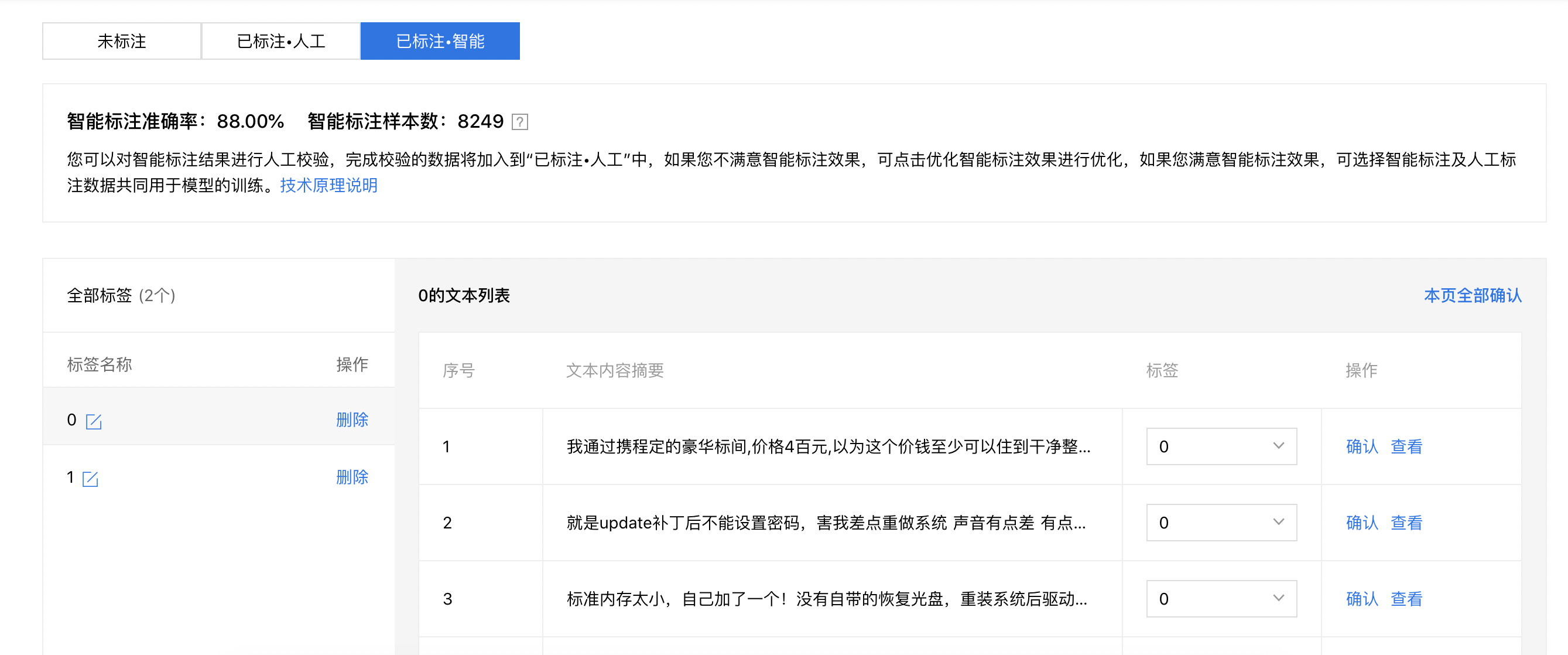
当完成智能标注后,您可前往您的数据集查看。此时数据集将被分为「未标注」、「已标注(人工)」和「已标注(智能)」三个标签。完成智能标注的数据,将放置在「已标注(智能)」中, 您可以对智能标注数据进行人工校验,完成校验的数据,将被转移到「已标注(人工)」,代表此样本确认无误,后文将详细说明智能标注的原理。智能标注前的「已标注」数据将放入「已标注(人工)」中,且数据不发生变化。
您也可以在「已标注(智能)」中,查看本次智能标注的准确率,以及智能标注数据的总样本数。 如果您对智能标注的准确率不满意,可以点击「优化智能标注效果」,来对全部的智能标注数据进行优化。
二、使用智能标注数据训练模型
如果您对智能标注的数据质量满意,您可以直接使用「已标注(人工)」和「已标注(智能)」下的数据,对模型进行训练。后文有详细介绍此步骤的原理。
您在配置任务时,在选择数据集的过程中,可以在「选择数据集-可选项」下,勾选「使用智能标注数据」,如果此数据集下有智能标注数据,训练任务时将会使用「已标注(智能)」的数据。

三、启动智能标注数据优化流程
如果您对数据质量不满意,可以在「已标注(智能)」页面中,通过点击「优化智能标注」进入优化流程。

进入后,平台将为您提供至多300条的优先校验样本,优先校验样本是平台挑选的机器较难确认的样本,同时也是对提升智能标注准确率最有帮助的样本。此部分样本将按照优先级从高到底排序,建议您按顺序逐一校验。
在优化流程的页面中,您将发现已完成校验的数量,当前的智能标注准确率情况。当您完成100条以上的样本校验后,「启动效果提升」按钮将置亮,您可以点击并启动优化智能标注的能力。
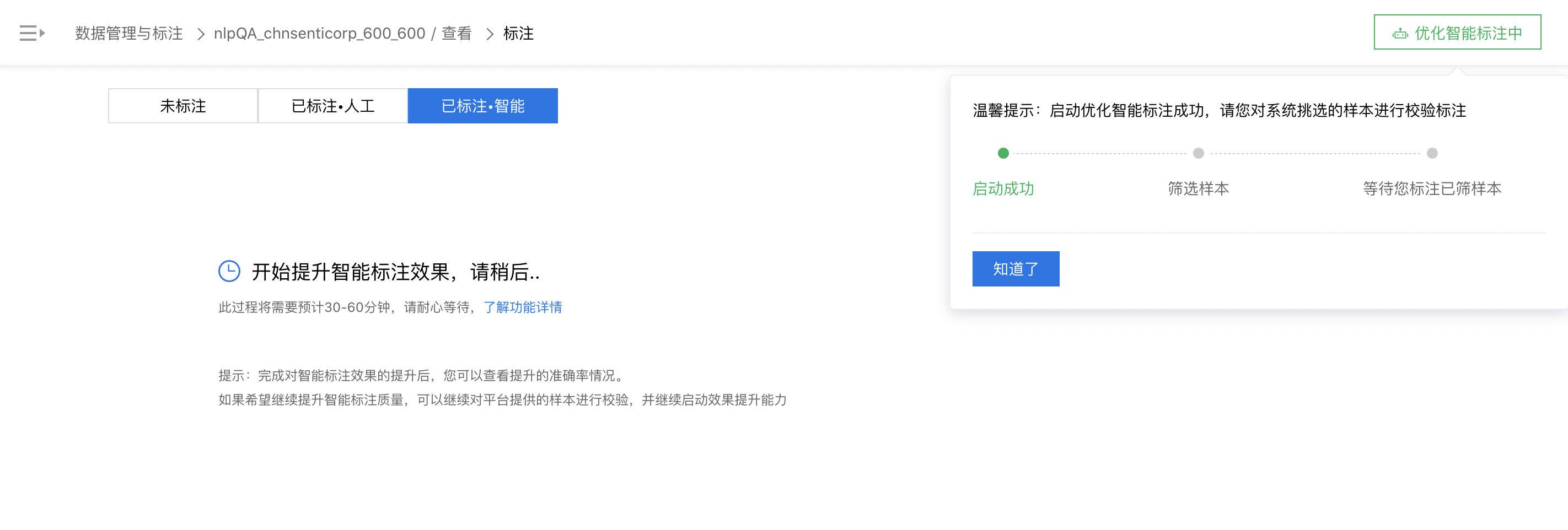
此过程将对您完成校验的样本重新学习,并对剩余智能标注数据进行重新标注。此过程不可关闭,请您耐心等待。完成优化后,将为您展示智能标注准确率的提升状况,并同时为您再次筛选出优先标注样本进行再次的校验和提升。通常情况下,此过程将持续3次,即您完成3次的样本校验。您也可以根据智能标注优化的效果,选择退出优化流程。
Tips:您也可以在启动优化智能标注前增加「未标注」数据,在优化智能标注过程中,也将把新提交的「未标注」数据进行智能标注。
如果您点击「退出优化效果」或您点击进入到了其他页面中,您在优化流程中的进度将会保存。下次返回后,将可以继续进行。
对样本的校验过程,将和文本的标注过程类似。当您发现样本的智能标注有误时,您可以点击选择正确的标签,点击「确认」后,样本将被放入到「已标注(人工)」中。
如果您对当前页的所有样本都判断为正确,则可以点击「本页全部确认」将全部样本添加到「已标注(人工)」中。
四、再次启动智能标注
如果您新建了一个文本智能标注任务,并且完成过一次智能标注。此时,您可以继续在此数据集下,增加「未标注」数据,并对新增的「未标注」数据进行智能标注。

Tips:您在再次启动智能标注前,建议先完成至少一次「优化智能标注」的过程。此时,智能标注的数据将比「优化智能标注」前质量更高。
五、文本智能标注原理说明
训练模型过程中,通常需要经历数据集准备(标注)、任务网络配置开发、模型的训练和部署等重要过程。很多时候,模型训练在数据准备阶段遇到数据量不足的问题,使模型开发过程迟迟不能启动。
平台推出的文本智能标注功能,目标是通过少量的已标注数据样本,来获得大规模的智能标注数据,通过减少人工逐一校验的工作,使用智能标注数据来训练小型网络模型,以获得效果和性能更优的模型预测服务。使用文本智能标注数据来训练模型的原理,即当前较为流行的「模型蒸馏」。
下面,将为您简要描述智能标注和模型蒸馏的原理。
平台智能标注原理
平台提供的文本智能标注,是使用了当前中文模型效果最好的预训练模型ERNIE2.0。完成对少量人工标注数据学习后,可以对未标注数据进行预测,从而获得智能标注数据。由于预测的数据质量,与您提供的人工标注数据的质量强相关。建议您完成智能标注后,查看数据标注的质量效果,然后根据数据情况来判断是否进入到优化智能标注的流程中。
优化智能标注的过程中,系统根据算法挑选出优先标注样本。您完成对优先校验样本的人工校验后,系统将使用此部分样本重新训练模型,从而获得更精准的智能标注数据。
智能标注数据训练模型
ERNIE完成对人工标注数据学习后,生成的模型称之为「教师模型」,通过预测的大规模无监督语料,把「教师模型」的泛化能力通过模型训练教给「学生模型」。如下图所示:
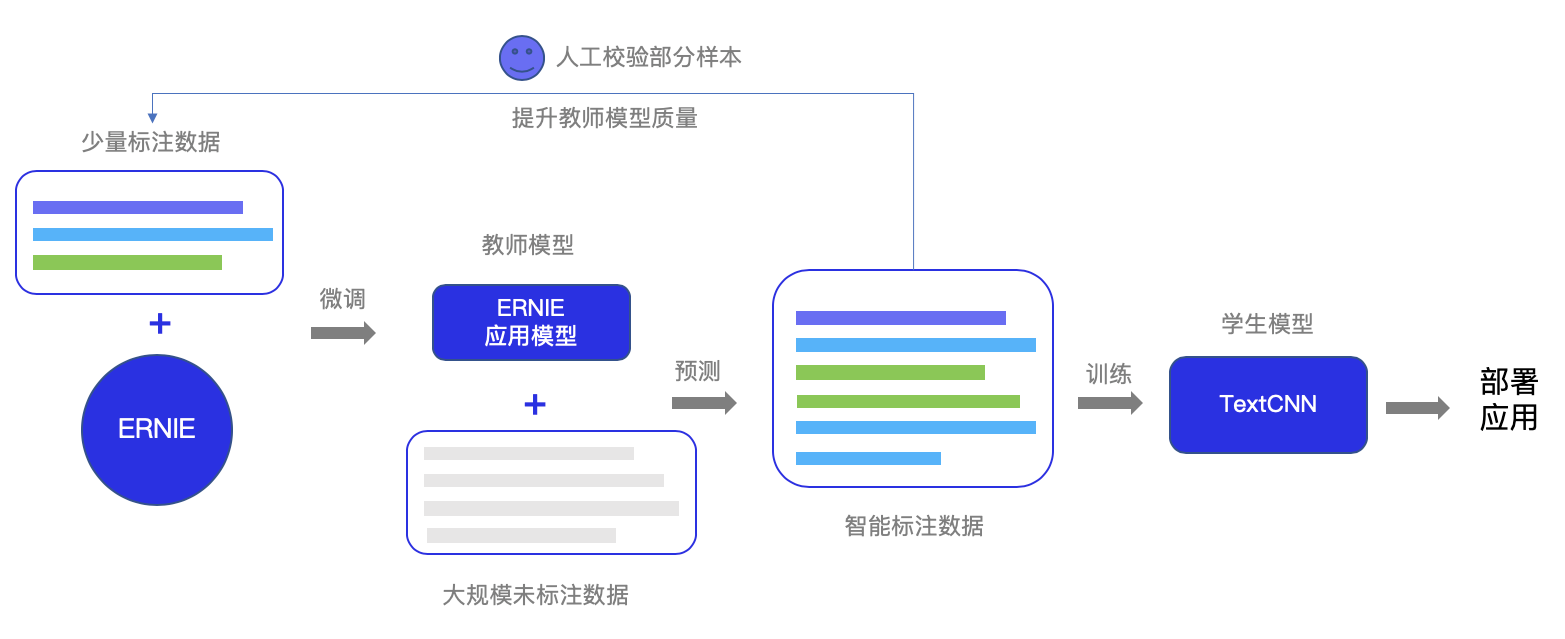
所以,您可以使用智能标注数据,在训练任务配置中,不使用ERNIE预训练模型。通过选择小型的网络,即可训练出效果逼近教师模型ERNIE Large的模型。且此模型的也保留了小网络的预测性能,可以在您的业务中达到具体业务使用的目标。
六、文本智能标注常见问题
问:智能标注可以支持哪几种类型的数据?
答:目前平台提供的文本智能标注,仅支持「单文本-单标签」的数据类型。
问:我是否能够对智能标注数据进行删除操作?
答:可以,您可以处理所有智能标注数据。通常情况下,您可以根据后续模型训练所需,对某些样本进行删除,以减少模型训练过程中的干扰。
问:为什么效果没有提升到一定程度,就提示已经完成优化智能标注?
答:因为您的智能标注数据过少,通过人工标注即可更好的完成校验;
问:为什么我使用智能标注数据训练模型效果不佳。不如只使用人工已标注的数据训练的效果?
答:您可以先进入「优化智能标注」过程,平台将为您挑选提升效果最佳的样本,将您的智能标注数据进行优化。同时您也需要查看数据集的数据分布是否与验证集的分布保持一致。
问:我将优化流程中的样本,都删除了,没法启动优化智能标注了,改怎么办?
答:您可以对此数据集增加「未标注」数据,然后返回到「智能标注」任务页面下,找到此数据集对应的智能标注任务,点击「再次启动」。系统将重新启动智能标注过程,并重置「优化流程」
问:完成智能标注后,我是否能在数据集新增带有新标签的标注数据?
答:您可以上传标注数据。但请注意,如果您上传的已标注数据带有新的标签(或您在已经完成智能标注任务的数据集上新增标签),将会影响智能标注质量。如果您需要使用带有新标签的数据,建议您新建数据集,并将全部人工标注数据导入后,再根据智能标注启动条件来启动新的智能标注任务。
问:为什么启动智能标注任务,或启动优化任务时,有时会不成功?
答:目前平台集中公测阶段,因算力限制,仅提供给一种任务的使用。即如果您已经启动了智能标注任务,则无法在另一个智能标注任务中启动优化任务。如果您有业务中的需求,可加入技术交流群,联系工作人员;
问:非中文语种的数据,可以使用智能标注吗?
答:目前平台仅支持中文的智能标注。不支持其他语种的智能标注任务。
问:为什么我使用智能标注数据训练模型,效果无明显提升?
答:不同场景和行业的数据集,使用智能标注数据提升效果不同。建议您针对智能标注数据进行优化流程,在优化流程中将有优先校验样本进行人工校验。完成至少一次优化流程,然后再使用智能标注数据进行模型训练。