Codelab Notebook自定义环境部署最佳实践
由于 Codelab Notebook 具备很强的开发灵活性,用户可能在 Codelab Notebook 开发各种各样的模型,为了保障用户自定义的模型可以顺利部署, Codelab Notebook 提供了自定义环境部署的功能。
注意:自定义环境部署功能仅支持通用型 Notebook 开发的模型,并且该流程仅支持公有云服务部署的方式。
本文介绍了从创建 Notebook 任务到训练模型,再到保存模型、部署模型的全流程。
从【飞桨精选案例】创建项目
1、在 BML 左侧导航栏中点击『飞桨精选案例』,注意查看开发语言和AI框架版本,后面需要选择对应的训练环境。
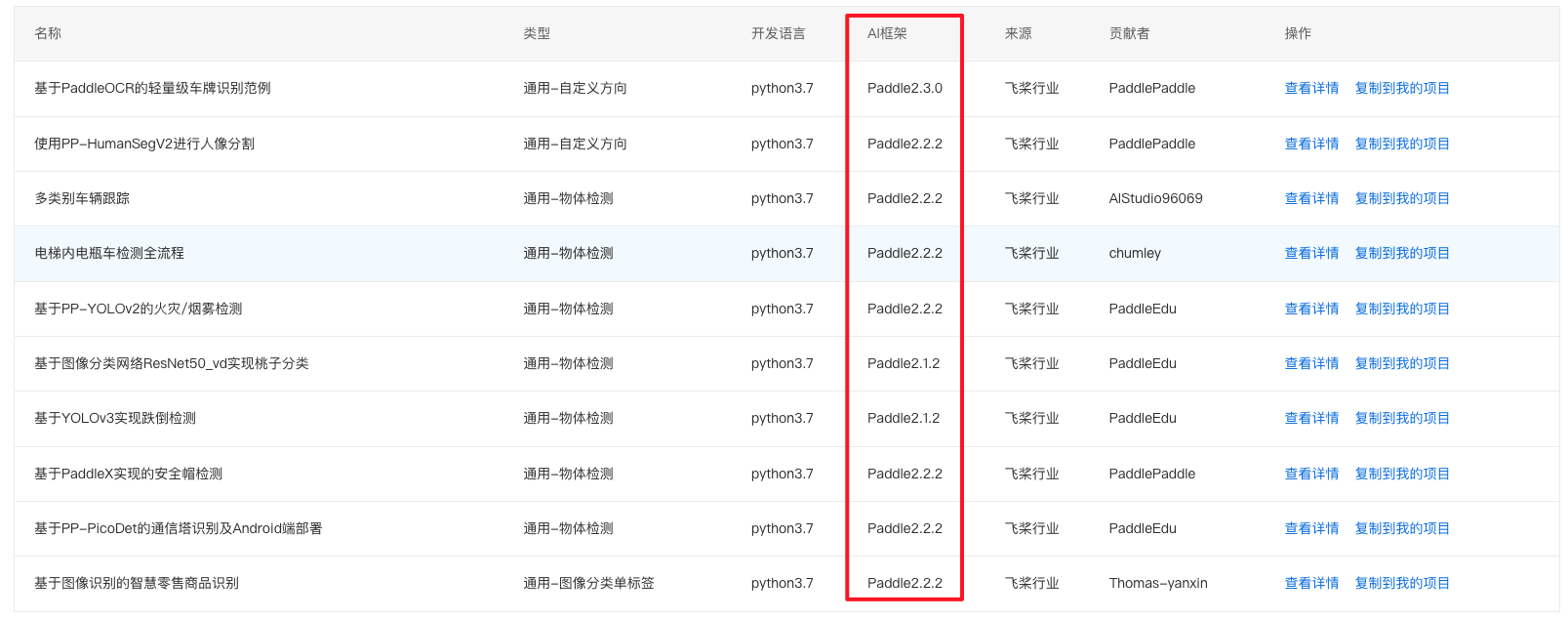
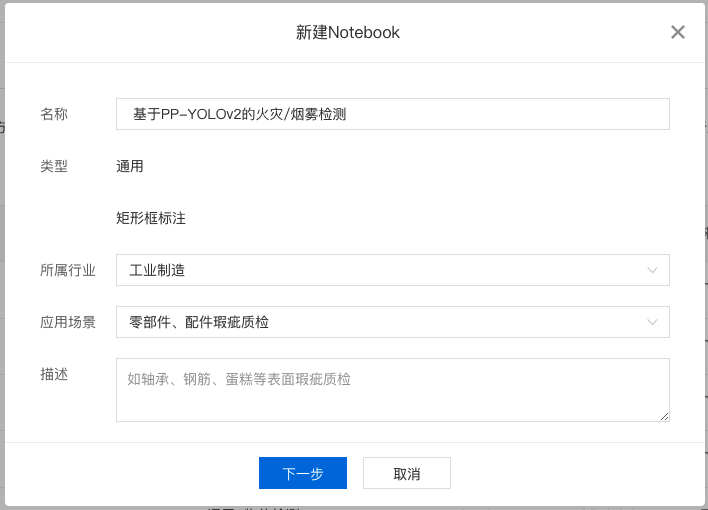
2、在『飞桨精选案例』中选中某一个感兴趣的项目,点击复制到我的项目,示例如下:
3、完成填写后点击下一步即可配置项目资源,支持选择训练环境和资源规格:
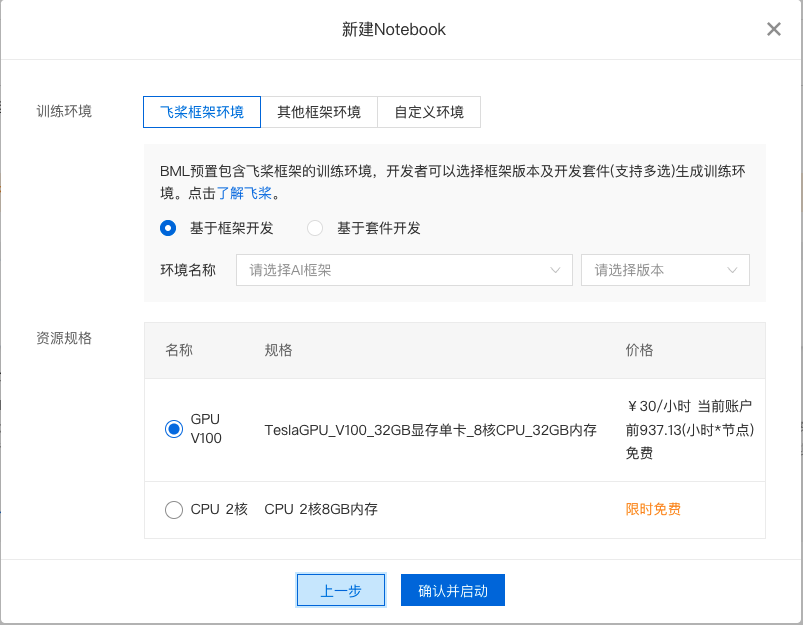
4、完成配置后点击确认并启动即可。
训练模型
1、点击进入项目查看案例内容。
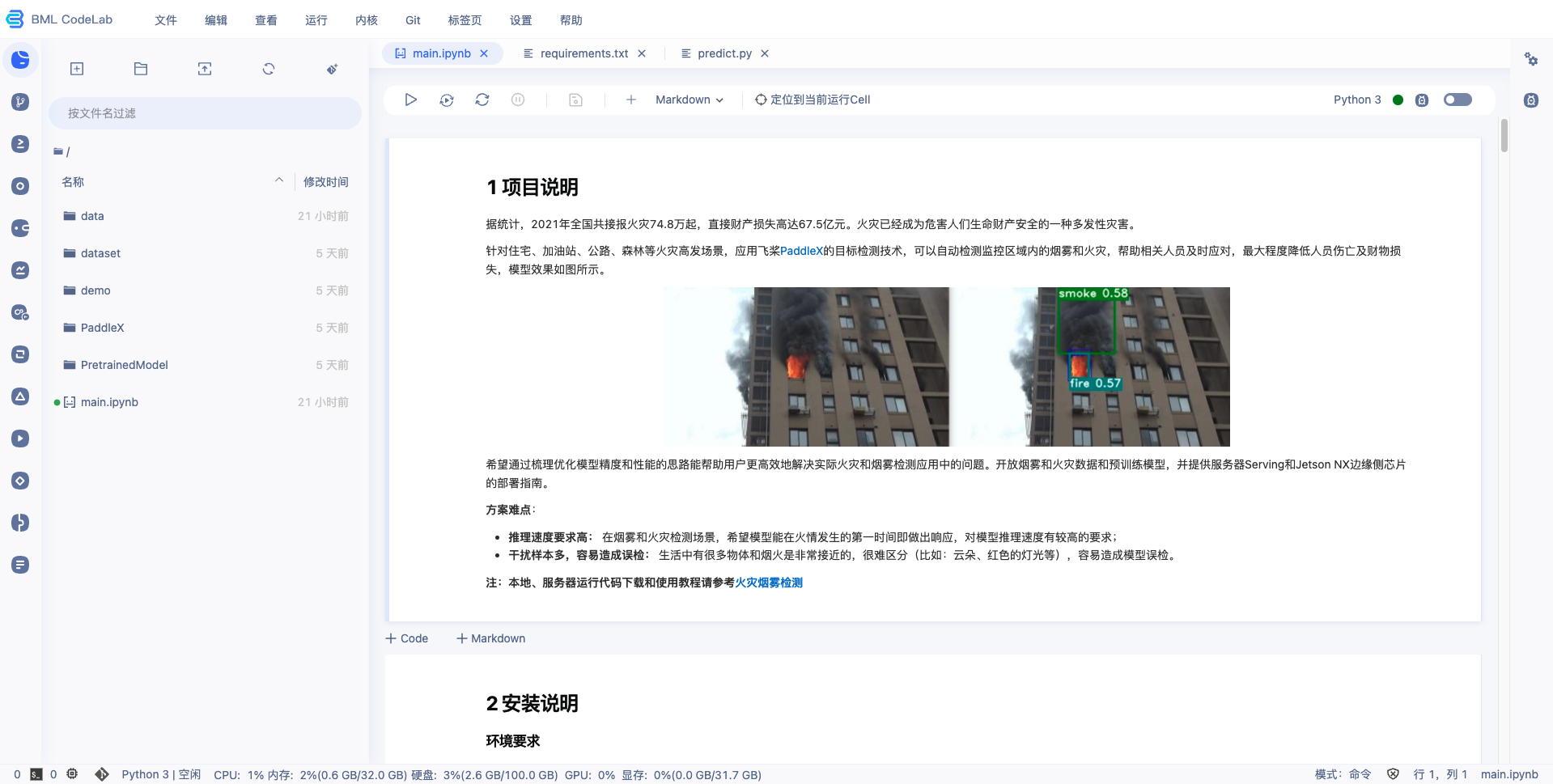
2、案例中提供了配置依赖和下载数据集的链接,并且提供了训练代码,逐个 cell 点击运行即可完成整个案例的运行,并且可以得到训练出来的模型。
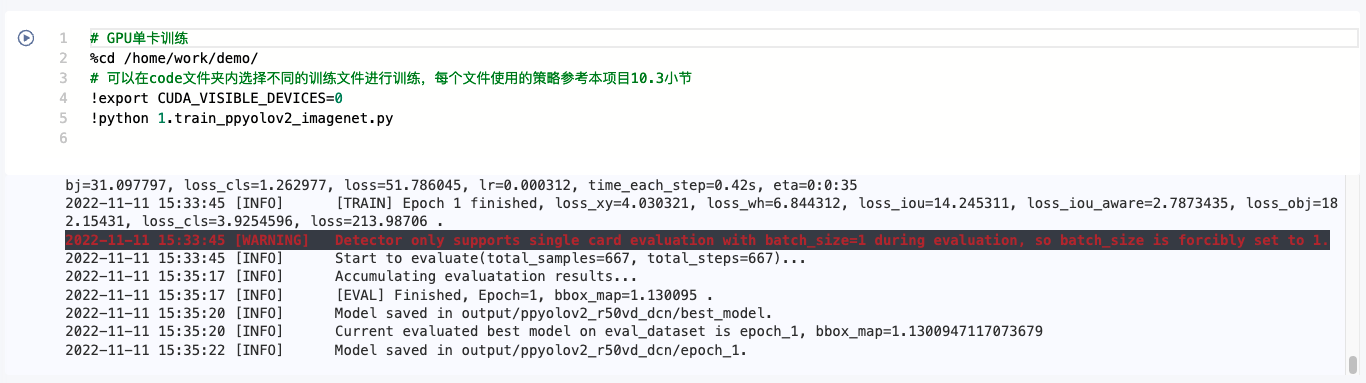
保存模型
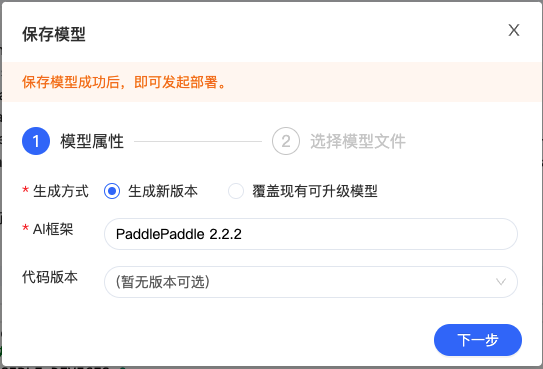
1、进入到保存模型的路径(在训练的输出信息里面会显示模型保存的路径),将模型移动到下图中的 pretrainedmodel 文件夹下。

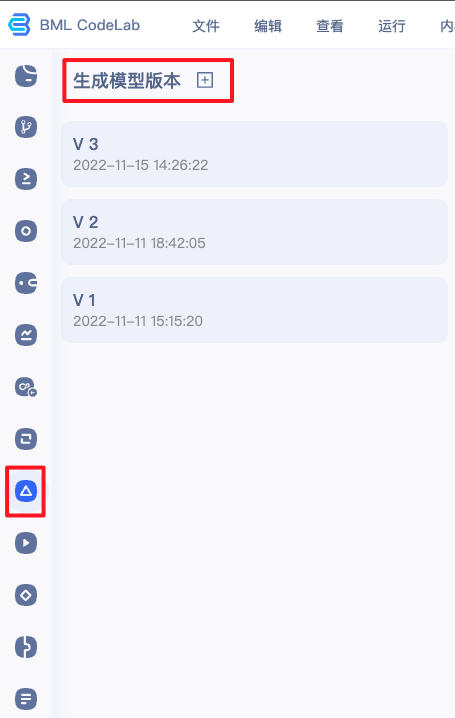
2、点击生成模型版本。
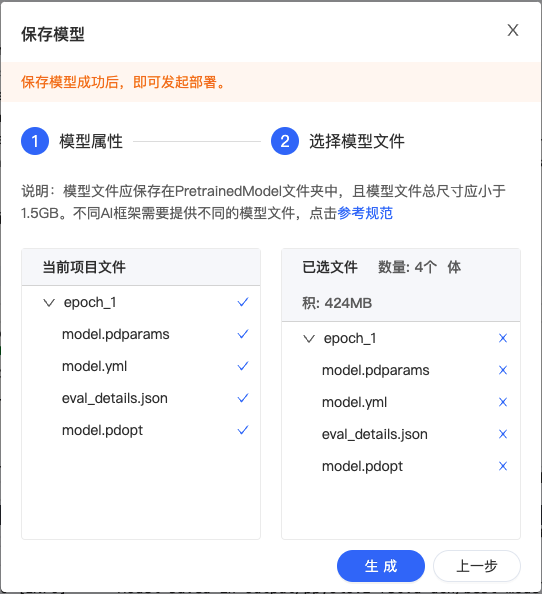
3、填写相关信息并选中模型文件。
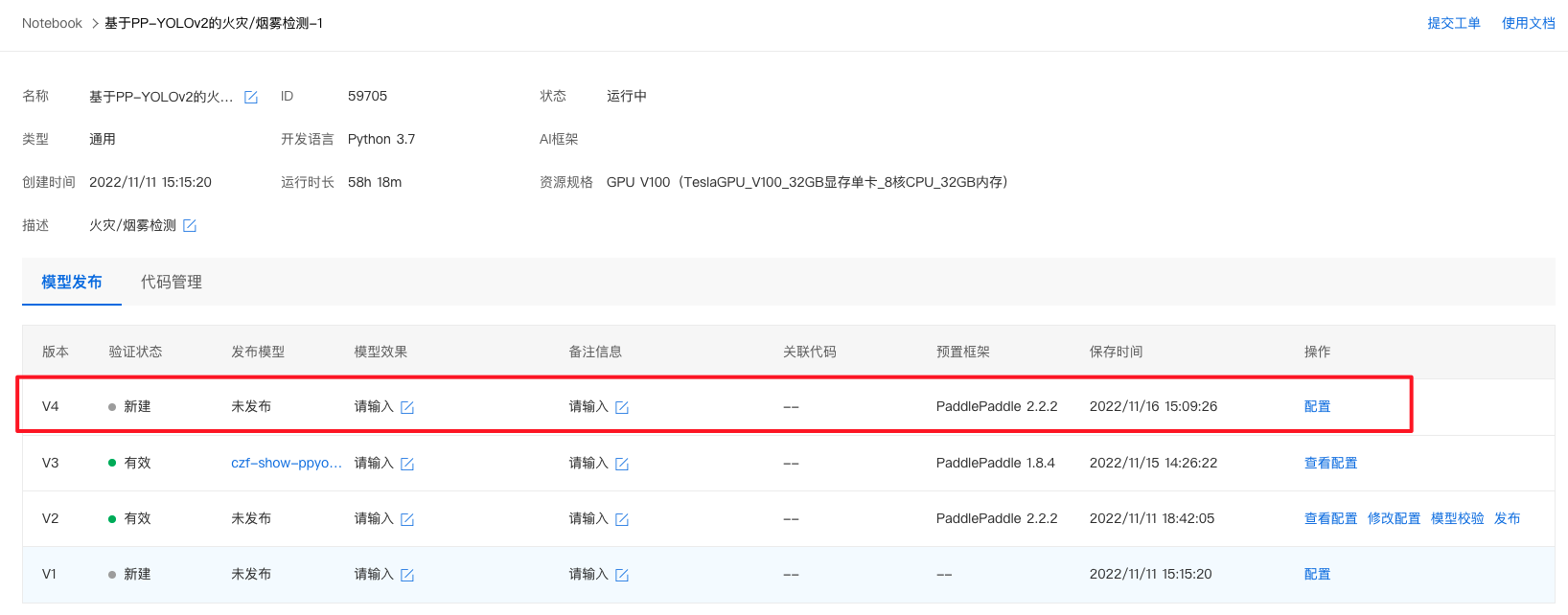
4、生成的模型版本将会在『模型列表』中出现。
制作自定义环境
由于在模型的训练过程中安装了一系列依赖,所以需要在平台环境的基础上安装这些依赖制作自定义环境才可进行后续的部署动作。
1、点击左侧导航栏的『环境管理』,并且进入『自定义环境』,点击新建环境。
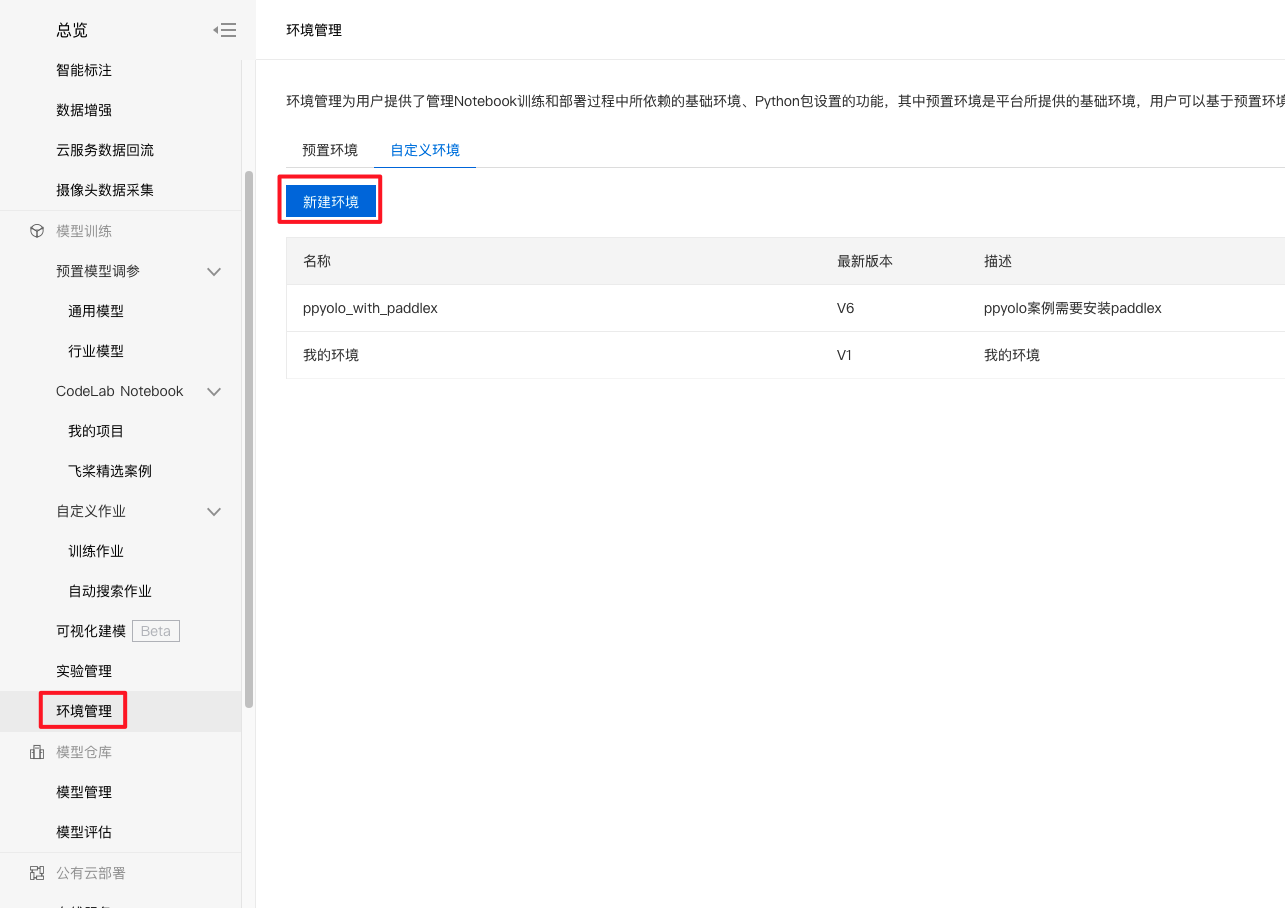
2、填写环境名称和描述。
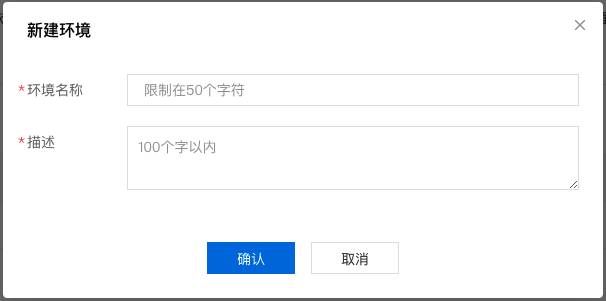
3、点击新建版本。

4、选择基础环境,这里注意选择对应框架版本的CPU环境。由于本最佳实践所使用的是paddle2.2.2环境,所以选择paddle2.2.2的CPU环境即可。
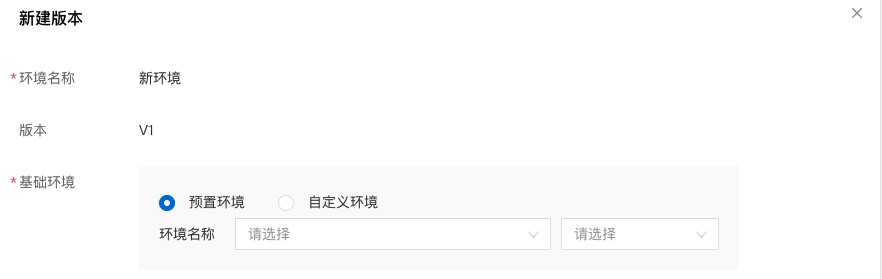
5、填写环境内容,这里主要是填写该模型运行所需要的依赖项,依赖项可以查看原项目中的内容。
如下图,该项目中主要依赖requirements中的内容和filelock。

找到requirements中的内容加以复制,添加进环境内容中。(注意,环境内容的原理是和requirements文件一样的,在自定义环境的过程中,平台会依据环境内容通过pip install安装在这里列出的所有组件。)
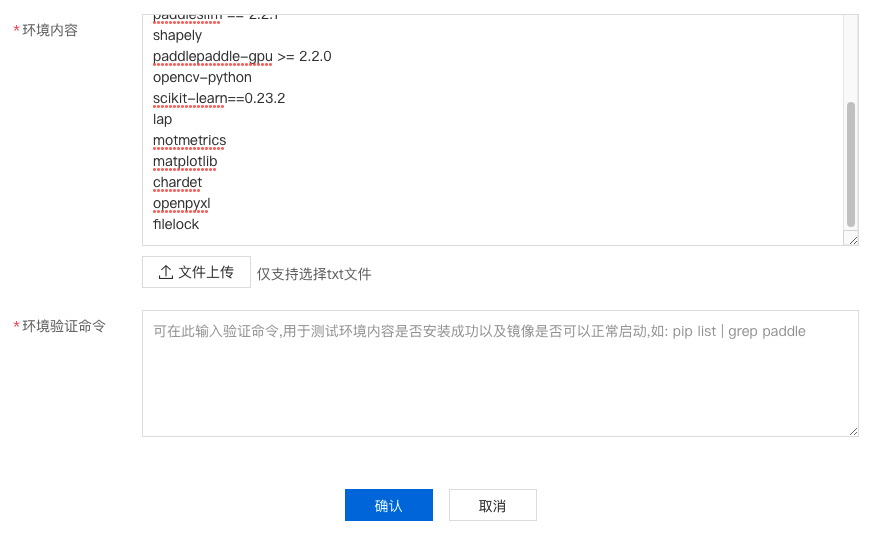
本项目的示例依赖:
1paddlex==2.1.0
2tqdm
3scipy
4colorama
5cython
6pycocotools
7visualdl >= 2.1.1
8paddleslim == 2.2.1
9shapely
10paddlepaddle-gpu >= 2.2.0
11opencv-python
12lap
13scikit-learn==0.23.2
14motmetrics
15matplotlib
16chardet
17openpyxl
18filelock6、填写环境验证命令,此处的原理是根据用户需要,填入一些命令来验证一些关键的包是否安装成功,可以按照示例填写也可以按需填写。点击确认即可进入构建流程。


7、构建和验证的过程时间较长,验证成功后即可开始使用。

配置模型
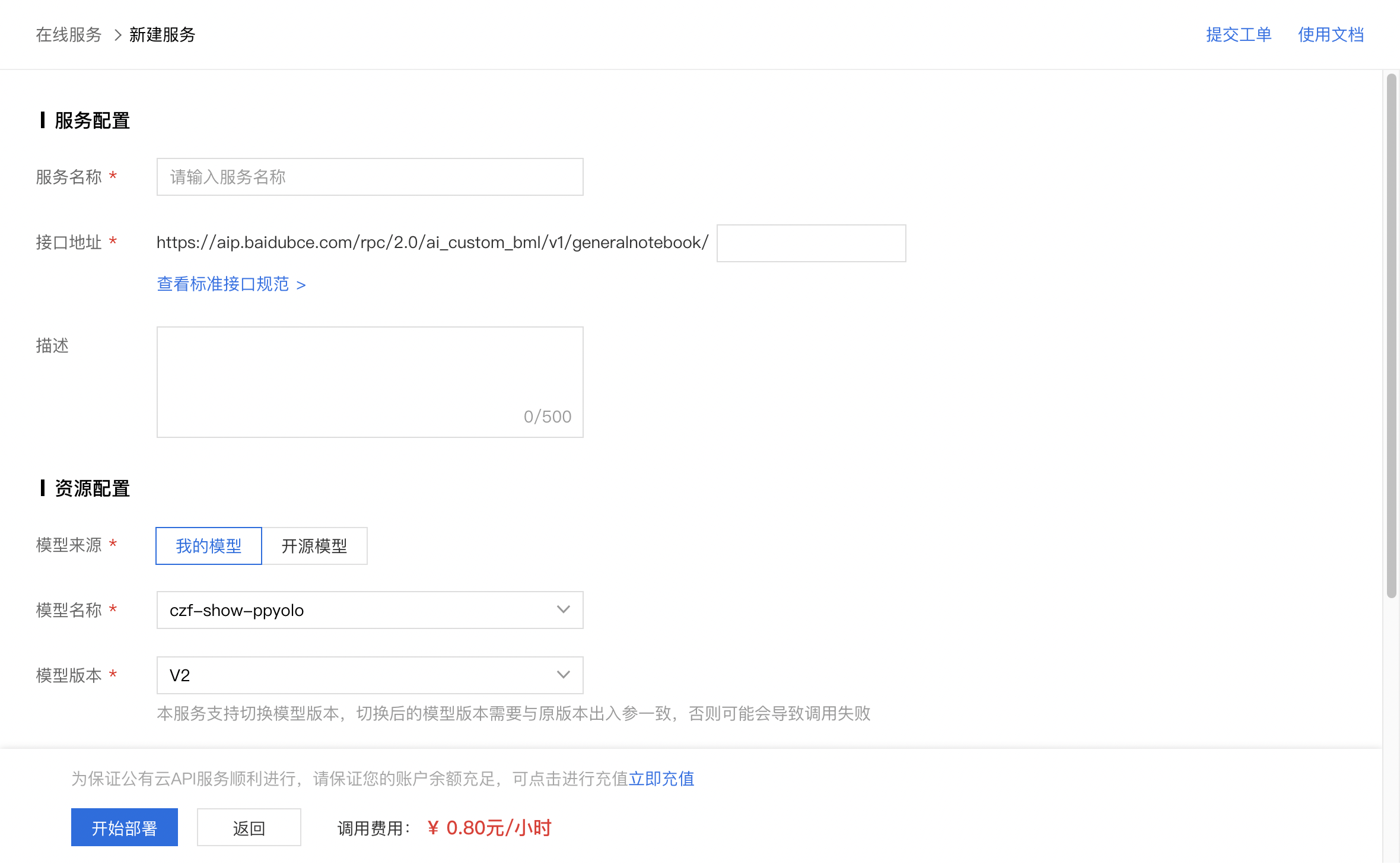
1、在 BML 左侧导航栏中点击『Codelab Notebook』,进入对应项目的『模型列表』。

2、找到对应的模型进行配置。
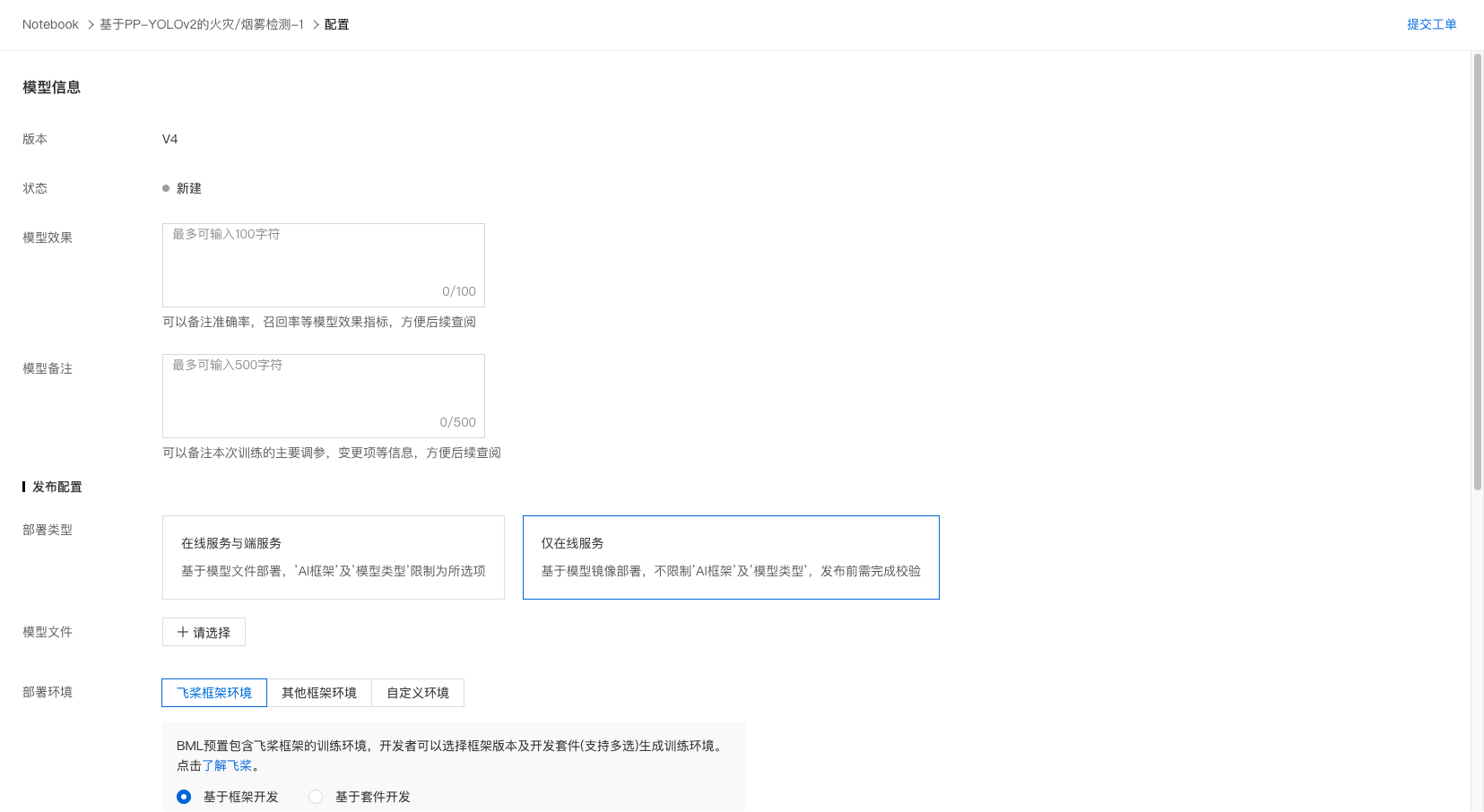
3、选择『仅在线服务』,选择对应的模型文件以及自定义的环境。
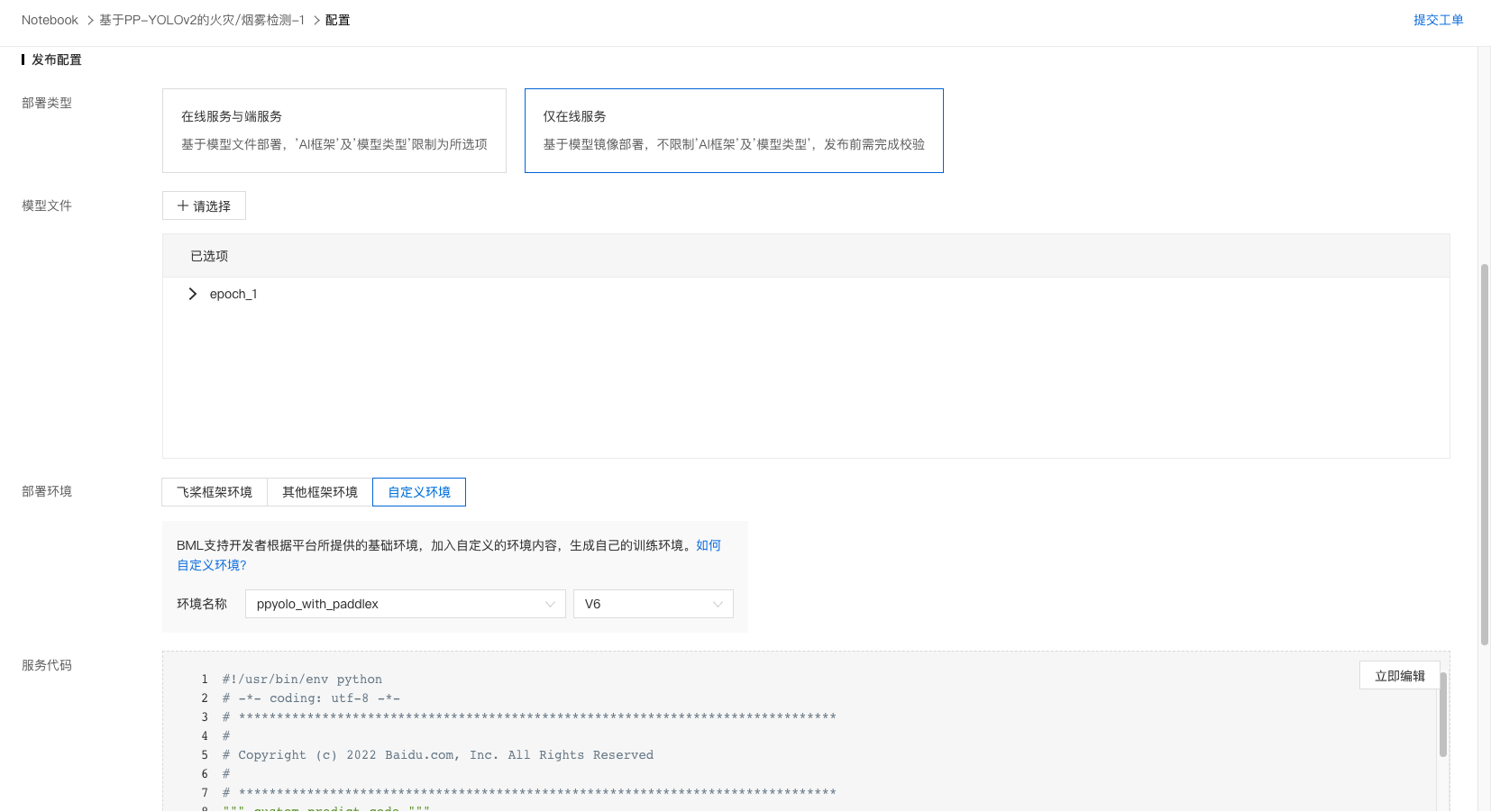
4、编辑服务代码,此处主要是加载模型和构造一个请求体(此处的请求体会影响后续部署为公有云服务后的调用代码,需要根据自身情况撰写),可以参考项目中的predict代码。
本项目的示例代码:
1#!/usr/bin/env python
2# -*- coding: utf-8 -*-
3# *******************************************************************************
4#
5# Copyright (c) 2022 Baidu.com, Inc. All Rights Reserved
6#
7# *******************************************************************************
8""" custom predict code """
9import base64
10import numpy as np
11import cv2
12class PyModel(object):
13 """ 模型服务预测封装类,支持用户实现自定义的服务请求数据处理和模型推理逻辑。"""
14 def __init__(self, model_path, *args, **kwargs):
15 """
16 根据`model_path`初始化`PyModel`类,如加载标签文件、预处理参数、加载模型 等等
17 :param model_path: 该目录下存放了在页面上选择的模型版本中包含的所有文件,并保留原有的目录结构;
18 :param *args/**kwargs: 其他信息(预留字段,不可以删除),系统可能会在未来传入一些其他参数
19 """
20 # 加载模型
21 import paddlex as pdx
22 self._model = pdx.load_model(model_path + "/epoch_1/")
23 def predict(self, request_body):
24 """
25 自定义对请求体的处理,包括请求处理、模型预测、预测结果封装等
26 :param request_body: 调用接口的请求体json字典
27 :return:
28 response_body: 请求的处理结果,需要能够被json序列化
29 """
30 # 请求解析、模型推理、推理结果封装
31 # 请求入参: {"image": image base64字符串}
32 image = request_body["image"]
33 image_bin = base64.b64decode(image)
34 # 图像解码
35 image = np.frombuffer(image_bin, dtype='uint8')
36 image = cv2.imdecode(image, 1)
37 # 模型推理计算,参考 https://github.com/PaddlePaddle/PaddleX/blob/develop/docs/apis/models/detection.md#predict
38 result = self._model.predict(image)
39 format_result = []
40 for target in result:
41 format_result.append({
42 "label_index": target["category_id"],
43 "name": target["category"],
44 "score": target["score"],
45 "location": {
46 "left": target["bbox"][0],
47 "top": target["bbox"][1],
48 "width": target["bbox"][2],
49 "height": target["bbox"][3]
50 }
51 })
52 return {"results": format_result}
53
54class CustomException(RuntimeError):
55 """
56 进行模型验证和部署服务必需的异常类,缺少该类在代码验证时将会失败
57 在处理异常数据或者请求时,推荐在`PyModel`中的自定义推理predict函数中抛出`CustomException`异常,
58 并为`message`指定准确可读的错误信息,以便在服务响应包中的`error_msg`参数中返回。
59 """
60 def __init__(self, error_code, message, orig_error=None):
61 """ init with error_code, message and origin exception """
62 super(CustomException, self).__init__(message)
63 self.error_code = error_code
64 self.orig_error = orig_error5、点击保存和提交。
模型校验
1、配置完成的模型处于待校验状态,点击进行模型校验。
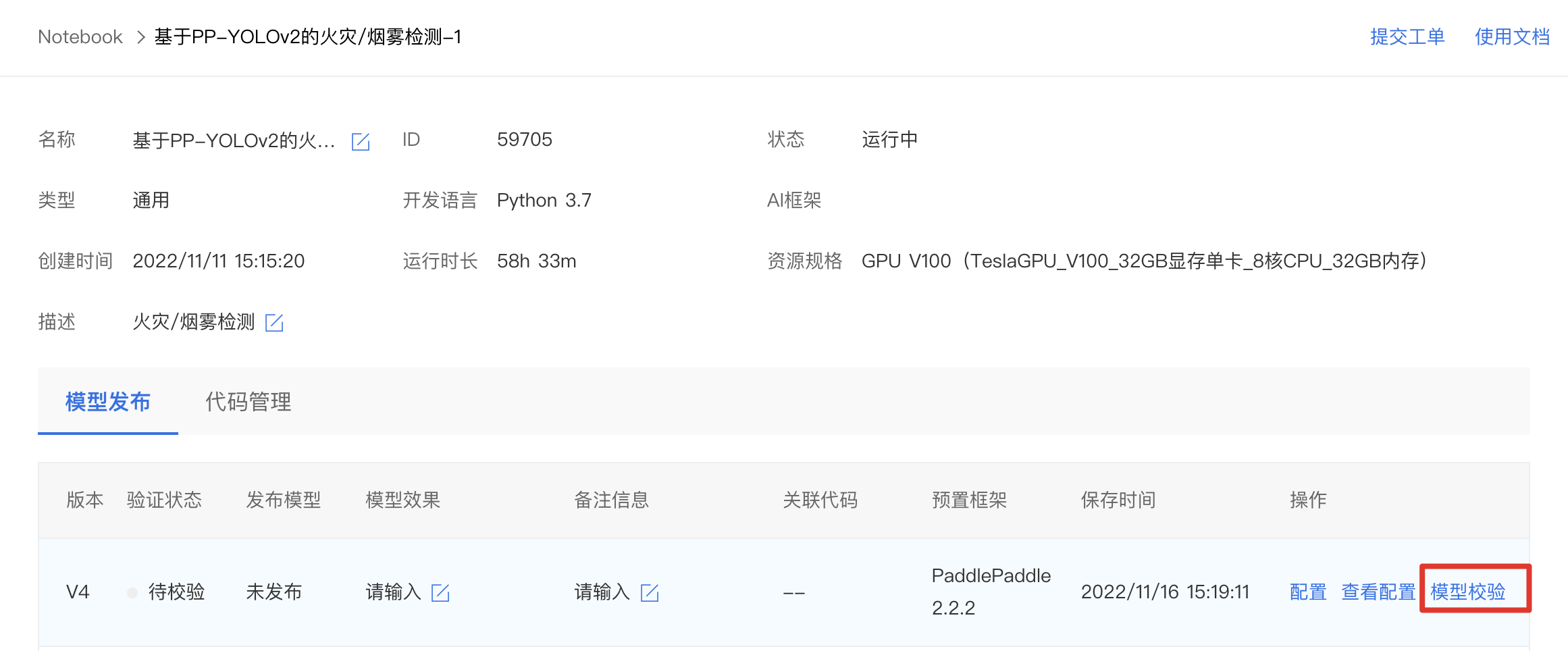
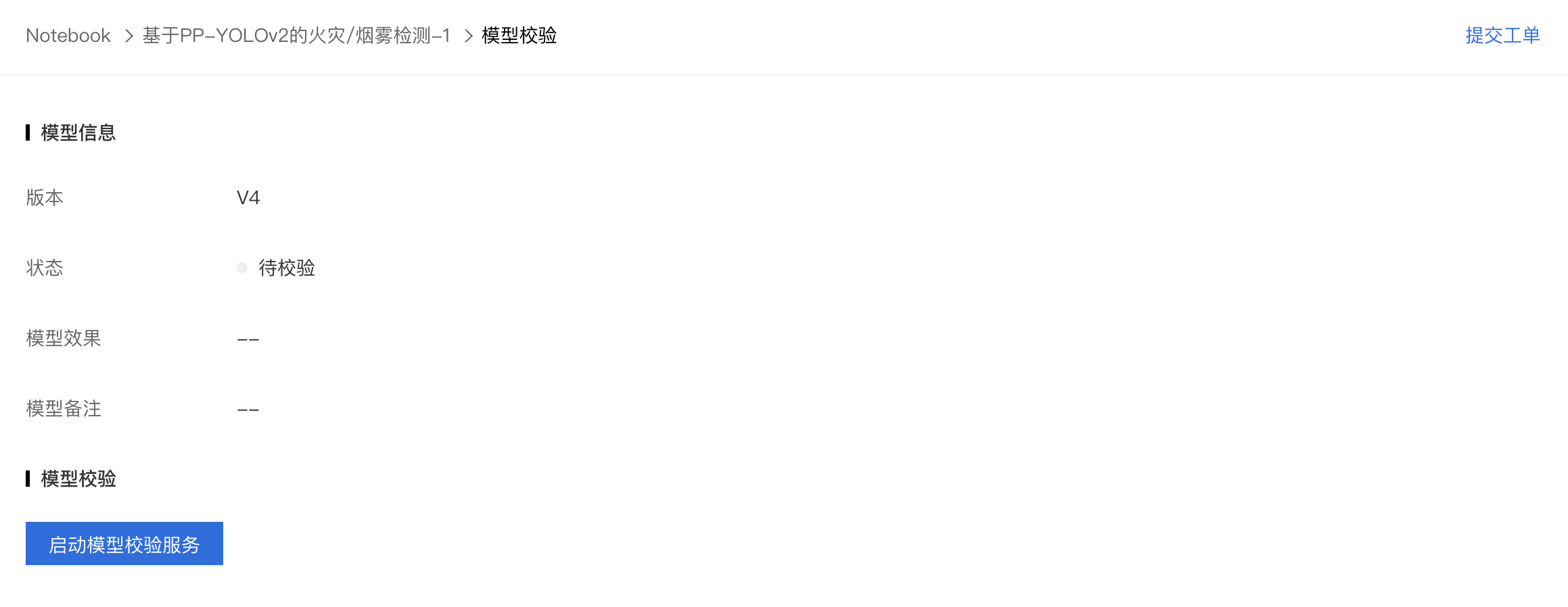
2、模型校验支持传入测试数据的base64格式的json(由于用户可能传入多种格式的数据,所以采用json格式传入更具有适配性)。
本项目中将对应的测试图片通过代码转换为了base64的json格式。
1import numpy as np
2import cv2
3image_bin = open("/home/work/dataset/images/fire_000001.jpg", "rb").read()
4import base64
5print(base64.b64encode(image_bin))示例:
| 数据类型 | json格式 |
|---|---|
| 图片 | {"image": "xx(此处粘贴转写为base64后的内容)"} |
3、点击发起校验,即可查看预测结果,如果与预期一致,点击发布即可。
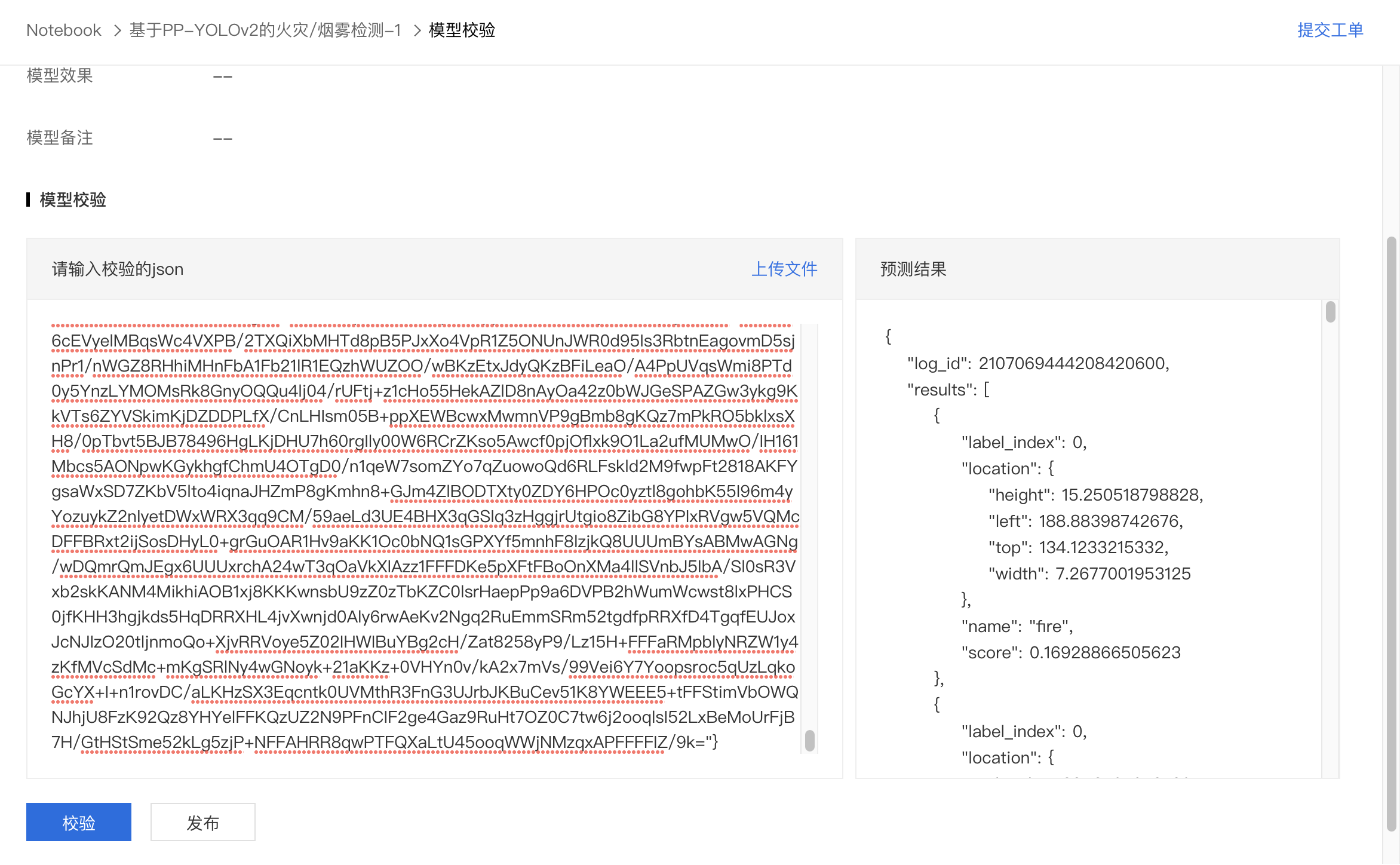
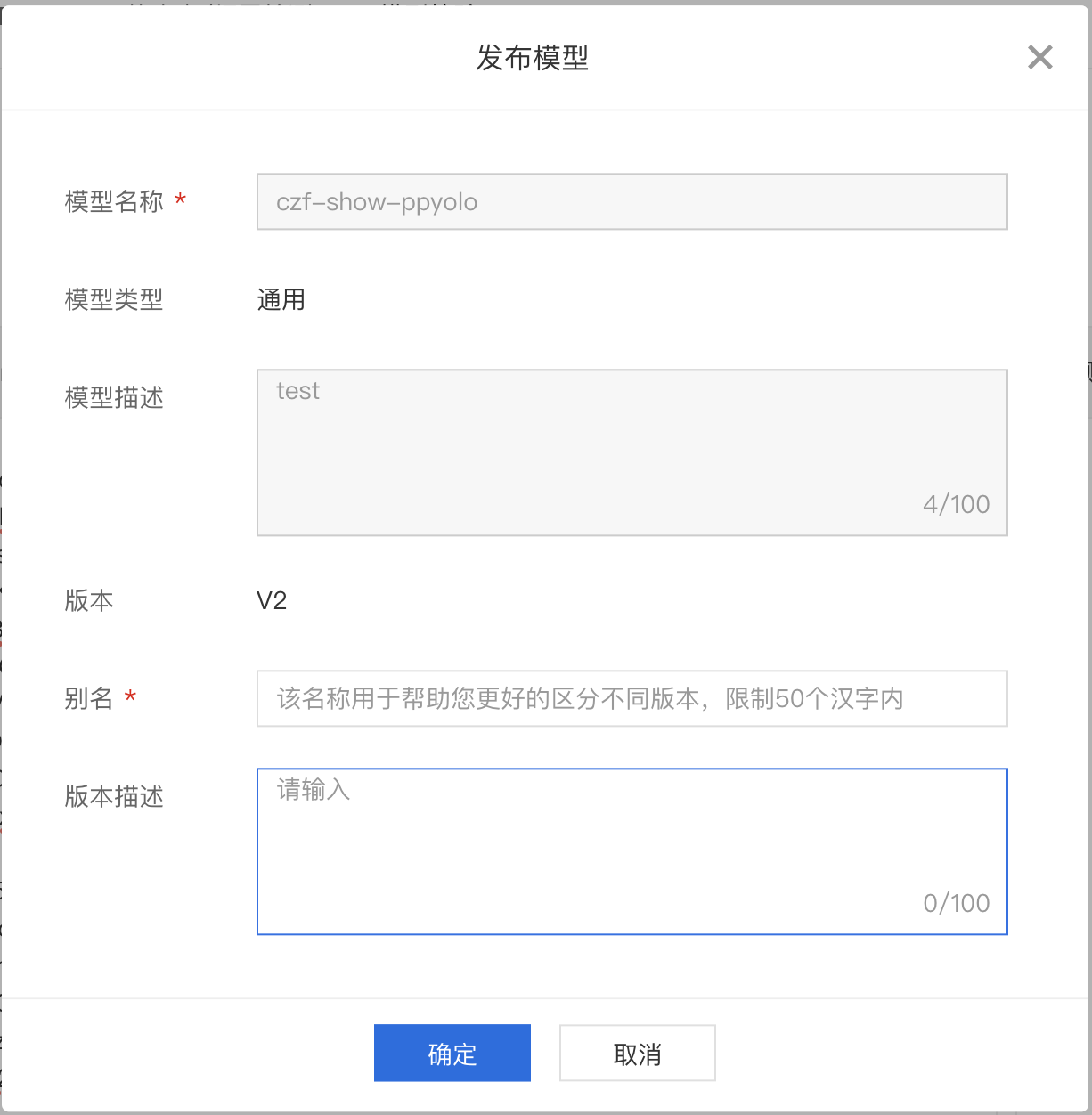
4、发布完成将会在模型管理中新增一行记录。
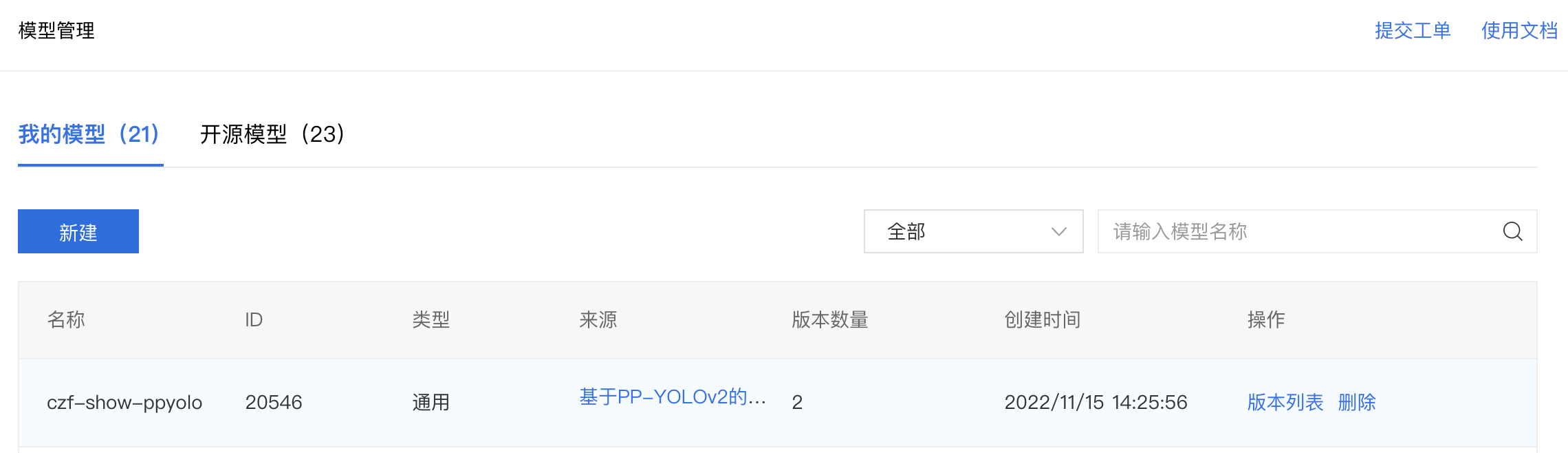
模型部署
1、点击即可进入部署阶段。
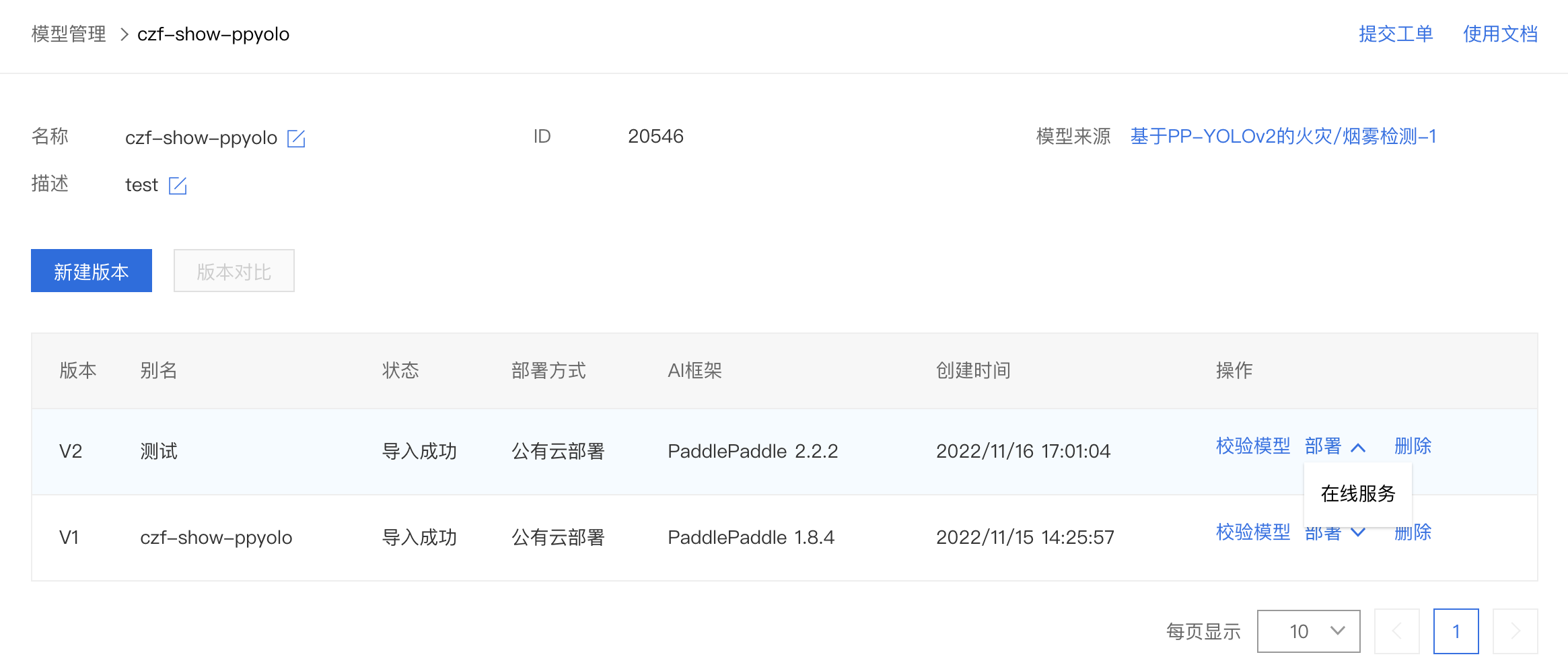
2、填写相关信息即可完成部署。