
序列标注数据导入
更新时间:2025-08-21
创建数据集
您可以在BML中,选择“数据管理/标注”并点击按钮“创建数据集”,对话框中选择数据类型为“文本”,标注类型选择“序列标注”,同时您需要根据您的标注数据,选择此序列标注数据集的标注体系(详见文档《序列标注标注说明》)。注意:当前序列标注数据集不支持在线标注功能,您在序列标注数据集中仅能上传标注数据。当您为此数据集选择标注体系后,标注体系不可修改,也不能导入其他标注体系的数据。
导入已标注数据
- 通过下图的”导入“进入到新创建的序列标注数据集的导入页面

- 在数据集的导入数据部分,您可以选择导入数据的方式,目前平台支持本地上传数据和在线导入已有数据集
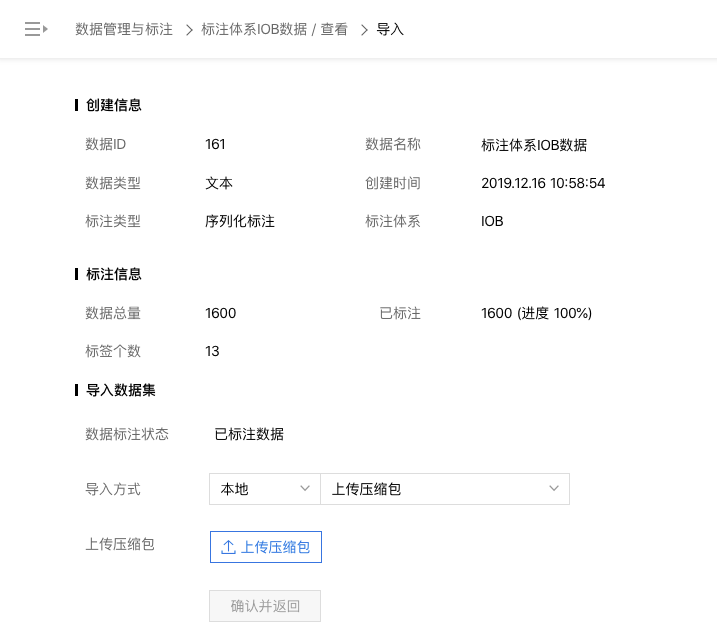
- 本地上传数据,需要以压缩包的形式上传,压缩包内需要包括标注文本文件(utf-8,txt或tsv格式),标注标签的映射文件(utf-8,JSON格式;文件名必须为”label_map.json“),一个压缩包里可以有多个标注文本文件,但都需要对应一个JSON映射文件。如下图示意:
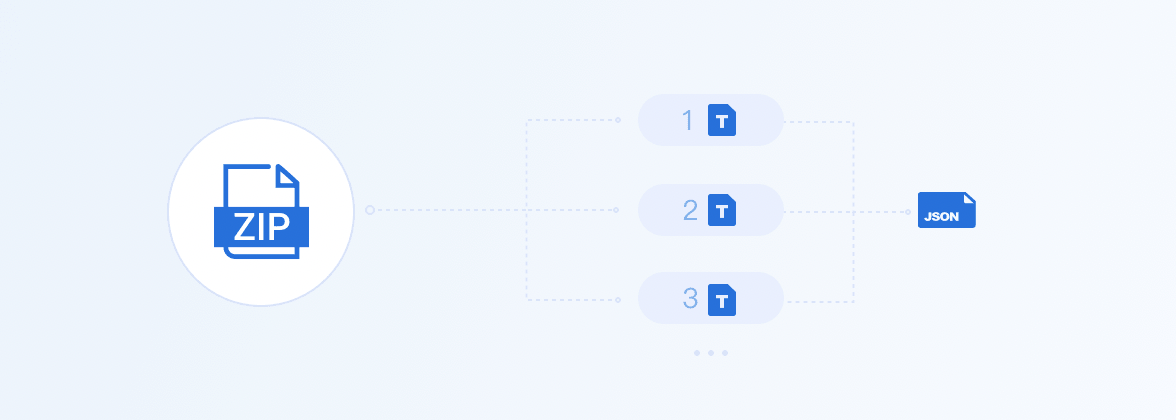
-
对于上传的数据文件的要求,请注意:
- 请上传对应标注体系的标注数据,避免数据上传失败
- 标注数据格式要求为“文本内容\t标注结果\n”文本内容和标注结果都需要按字切分,每一行表示一组数据,每组数据的字符数建议不超过512个
- 标签映射文件名须为”label_map.json“,标签映射文件的格式为:{"key":"value"}
- 上传压缩包文件支持zip格式,单个压缩包限制5G以内。压缩包内需包含txt或tsv格式的文本文件和标注为json格式的标签映射文件,编码仅支持UTF-8,单个文件最大可支持40MB。样本数据详见Demo数据
- 平台限免阶段每个账户最多支持100万条样本数据,超出后会被平台忽略
二次导入已标注数据
平台支持用户对于已有的数据集,进行二次导入数据。请注意,再次导入的已标注数据,标注标签需要完全一致。注意,二次导入过程不校验json文件。只对标注文本进行校验,与第一次上传的json文件里不一致的标签和标注数据,平台将过滤掉。