
神经网络训练搜索
了解神经网络训练搜索
1 概述
神经网络训练搜索又名神经网络结构搜索 (Neural Architecture Search, NAS),是自动机器学习 (Automated Machine Learning, AutoML) 的子领域。
神经网络训练搜索NAS本质上是优化问题,其目的是不通过人工,实现最优网络模型设计和选择自动化。使用者不需要具备丰富的专家经验,降低了网络模型设计难度和人力成本,有效保证业务应用效果的时延。
2 主要构成
NAS有三个基本要素:搜索空间、搜索策略和性能评估策略。
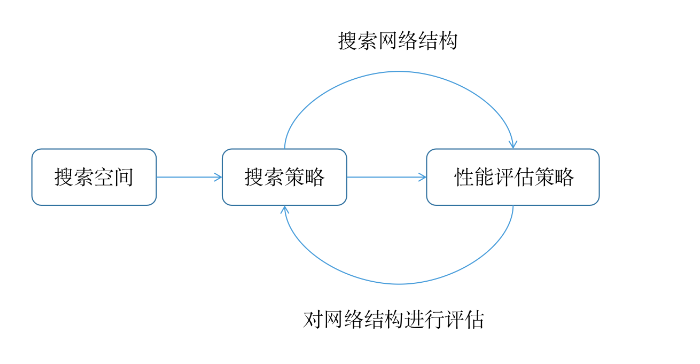
给定一个称为搜索空间的候选神经网络结构集合,用某种搜索策略从中搜索出最优网络结构。
神经网络结构的性能用某些指标如验证精度、计算开销等来度量,称为性能评估。
2.1 搜索空间
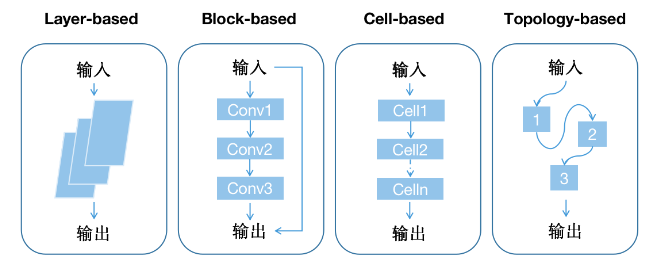
搜索空间可以看成是一个集合,集合中的每个元素代表一种候选网络结构。根据搜索空间的颗粒度不同,可以大概分成以下四类:
- Layer-based:关注的是每一层怎么设计。
- Block-based:关注的是每一块怎么设计,每个块中包含多个层,块里面每个层的设计是不一样的。
- Cell-based:关注的是每个cell怎么设计,每个cell中包含多个块,每个块的设计是不一样的。
- Topology-based:关注的是基本单元如何连接。
2.2 搜索策略
搜索策略主要包括强化学习(Reinforcement Learning)方法,梯度下降 (Gradient Descent) 方法,进化计算(Evolution Computation ) 方法等。
- 强化学习:基于强化学习方法,在搜索空间中采样后组成网络,对性能进行评估。
- 梯度下降:基于梯度下降的方法,关注基本单元的连接方式,将搜索问题建模为分类问题并进行梯度求解。
- 进化计算:基于进化计算的方法,让神经网络结构的集合基于适应度不断地被训练和突变(mutate),从而达到更好的验证指标。
2.3 性能评估策略
性能评估策略和搜索策略循环迭代,搜索策略搜索一次之后,由性能评估策略评估结果反馈给搜索策略,决定下一步往哪个方向搜索。
3 NAS的使用

平台中对NAS的使用分为四个步骤:
(1)创建神经网络搜索任务 确保已经准备好神经网络搜索训练数据,或前往“数据集管理”中标注数据完成数据准备,之后创建神经网络搜索任务。 (2)新建神经网络搜索运行 配置训练阶段和搜索阶段的参数,可以使用平台的默认参数,也可以手动配置,训练自己的神经网络子网模型。 首次创建任务时仅支持共同选择训练和搜索阶段,已训练出超网后可支持选择仅搜索阶段。
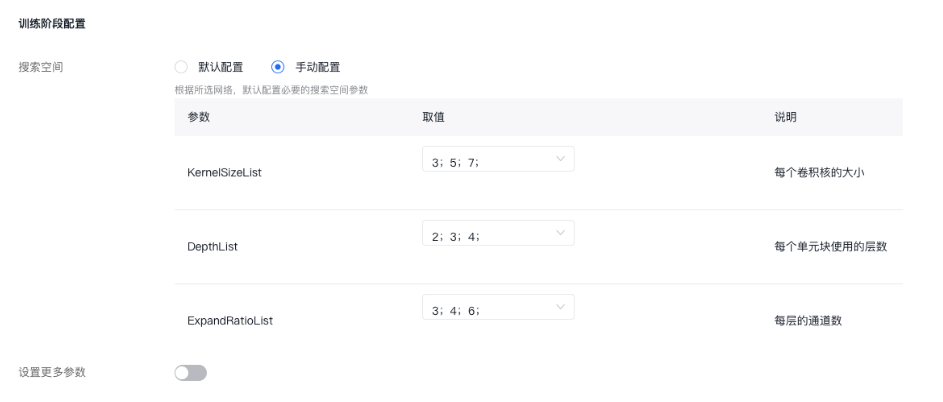
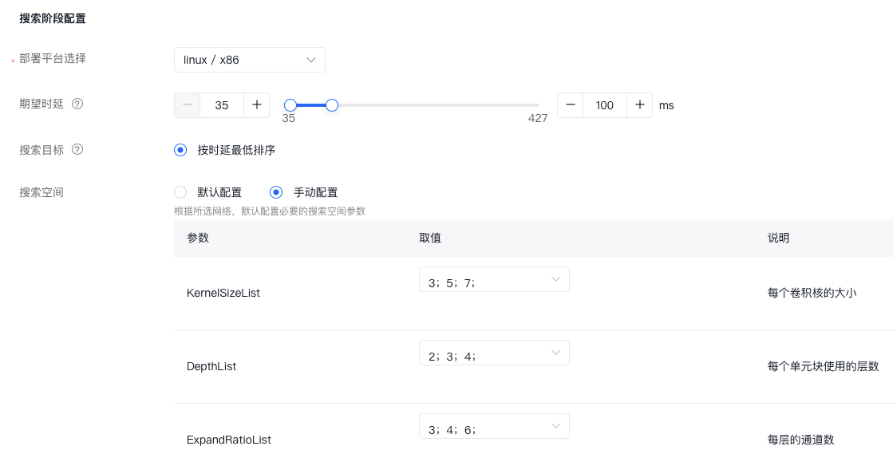
(3)通用模型使用子网模型 在通用模型创建训练任务,网络配置方式选择神经网络搜索,并选择已经训练好的子网模型。
(4)发布模型 完成训练后,可以发布训练好的模型到模型仓库。